


159
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享| 这个作业属于那个课程 | 自然语言处理 |
|---|---|
| 这个作业要求在哪里 | NLP作业02:课程设计报告 |
| 我在这个课程的目标是 | 用此次课程设计为毕业设计打基础 |
| 这个作业在那个具体方面帮助我实现目标 |
在情感分析(snowNLP库)方面有了了解, 可能可以让我在毕业设计时进行参考 |
| 参考文献 |
通过课程设计的练习,加深学生对所学自然语言处理的理论知识与操作技能的理解和掌握,使得学生能综合运用所学理论知识和操作技能进行实际工程项目的设计开发,让学生真正体会到自然语言处理算法在实际工程项目中的具体应用方法,为今后能够独立或协助工程师进行人工智能产品的开发设计工作奠定基础。通过综合应用项目的实施,培养学生团队协作沟通能力,培养学生运用现代工具分析和解决复杂工程问题的能力;引导学生深刻理解并自觉实践职业精神和职业规范;培养学生遵纪守法、爱岗敬业、诚实守信、开拓创新的职业品格和行为习惯。
3.1 实验仪器及设备
3.2 设计要求
课程设计的主要环节包括课程设计作品和课程设计报告的撰写。课程设计作品的完成主要包含方案设计、计算机编程实现、作品测试几个方面。课程设计报告主要是将课程设计的理论设计内容、实现的过程及测试结果进行全面的总结,把实践内容上升到理论高度。
根据实验项目一的实验方向(即做文本情感分析),我们可以不拘泥于老师所给的京东商品评论的范围,可以进行自主实验,比如B站弹幕爬取后的情感分析、网易云音乐热评爬取后的情感分析等等,而我选择豆瓣短评爬取后的情感分析,将更贴近于生活,让未观看该电影或电视剧的观众对电影或电视剧的口碑有个大概了解。实验的数据集使用的是爬取的评论,并生成一个txt文件,里面包含了所有的短评(page范围内),能够较为全面地反应评论者的情感与状态,与B站弹幕爬取相比,豆瓣短评爬取的优点在于它爬取的评论比弹幕的句子更长,更能分析积极和消极的感情,对于不同的电影、电视剧会有不同的情感,为此做一个电影电视剧的情感变化进行分析。本次实验主要用到了snownlp库进行文本情感分析,同时还用到了stylecloud库来体现评论的关键词以及做成词云,用到了requests、re等库实现爬虫,来反映评论者当时的观点与看法。
5.1 设计流程图
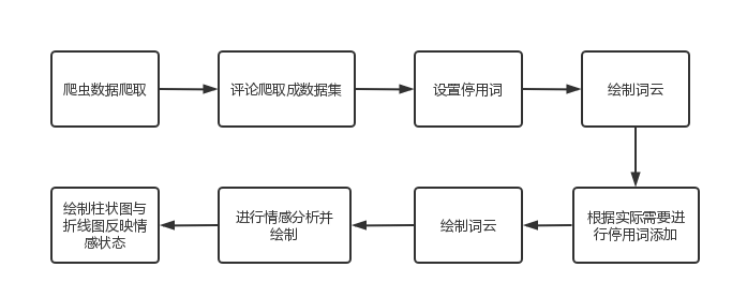
图1 豆瓣短评爬取及情感分析设计流程图
5.2 导入相关库和简介
import requests
from stylecloud import gen_stylecloud
import jieba
import re
这块代码来自“paqu.py”文件。
1.requests库简单来说就是用代码来模拟发送网络请求,并得到响应数据的一个第三方库。它的使用流程:导入import requests→模拟发送请求并获取响应,定义请求地址→发送get请求获取响应→获取响应的html内容。
2.stylecloud是wordcloud优化改良版,操作简单,直接调用。可用FontAwesome提供的免费图标更改词云的形状;通过palettable更改调色板以自定义风格,更改背景颜色;添加梯度使颜色按照特定方向流动。
3.jieba是做中文分词的,因为评论是一条长句子,需要用jieba库进行分词,并呈现在词云图上。
4.re是一个正则表达式的库,在实验中就用到了一个函数re.findall(),它的具体用法是re.findall(pattern, string, flags=0),功能是搜索字符串,返回全部匹配的子串,返回的是列表类型,如果没有找到匹配的,就返回一个空列表。
from snownlp import SnowNLP
import matplotlib.pyplot as plt
import numpy as np
这块代码来自其它3个py文件。
1.snownlp库是一个和textblob库相似的库,它们的区别在于textblob库是针对英文进行处理的,snownlp库是对中文进行处理的,它是以textblob库为基础写的库,都可以进行词性标注、情感分析、名词性成分提取等功能。
2.matplotlib库用来画图的,numpy库是做数组和矩阵运算的,在本实验中主要是与matplotlib函数一起使用,得到一定范围中的图形。
5.3 爬取过程
首先要找一个电影短评的网站url,此处以《人生大事》为例:
https://movie.douban.com/subject/35460157/comments?start=0&limit=20&status=P&sort=new_score
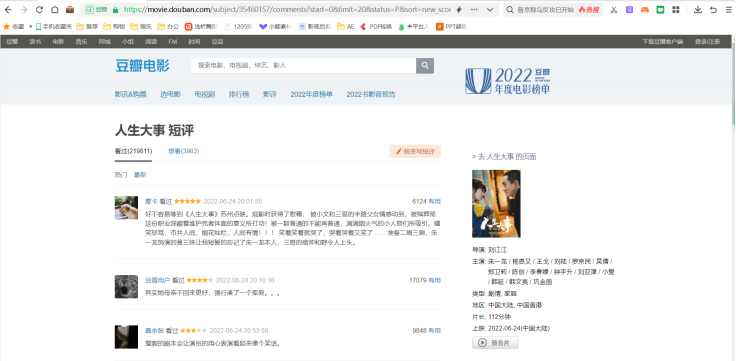
图2 《人生大事》豆瓣短评首页
这是短评第一页的网站,然后我们打开短评第二页的网站:https://movie.douban.com/subject/35460157/comments?start=20&limit=20&status=P&sort=new_score
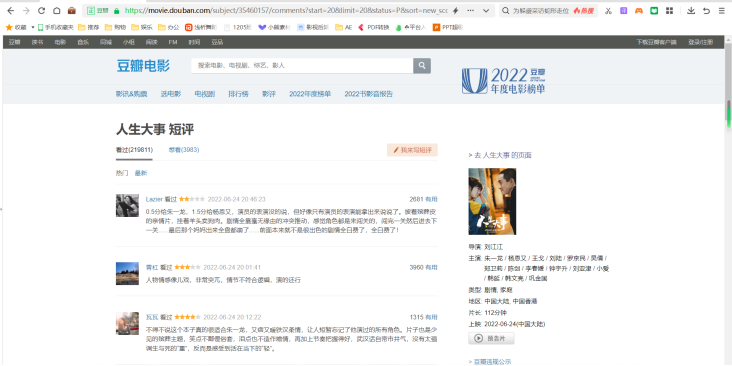
图3 《人生大事》豆瓣短评第二页
然后我们选择其它电影的短评(以《泰坦尼克号》为例)首页:
https://movie.douban.com/subject/1292722/comments?start=0&limit=20&status=P&sort=new_score
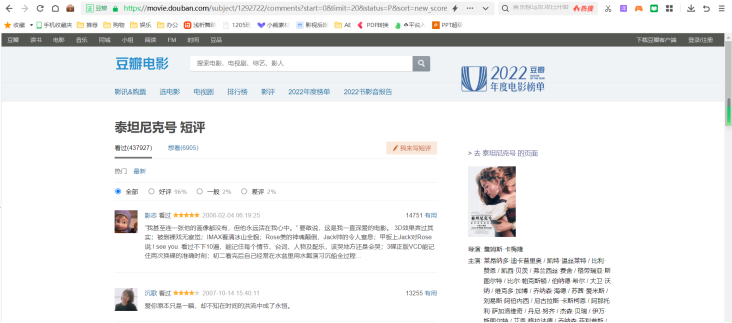
图4 《泰坦尼克号》豆瓣短评首页
我们可以发现,不同的电影id不同(《人生大事》:35460157,《泰坦尼克号》:1292722),start=0为短评首页,start=20为短评第二页,40为短评第三页,可以推出每翻一页start+20;limit=20是一直不变的,因为这是每页短评的数量。
写出代码:
url='https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P' \ % (movie_id, (i - 1) * 20)
在进行爬虫爬取数据之前,需要requests发出get的请求得到html内容进行爬取,所以我们还需要一个请求头,请求头需要去对应的浏览器找,我使用的是Firefox浏览器的请求头,如图:
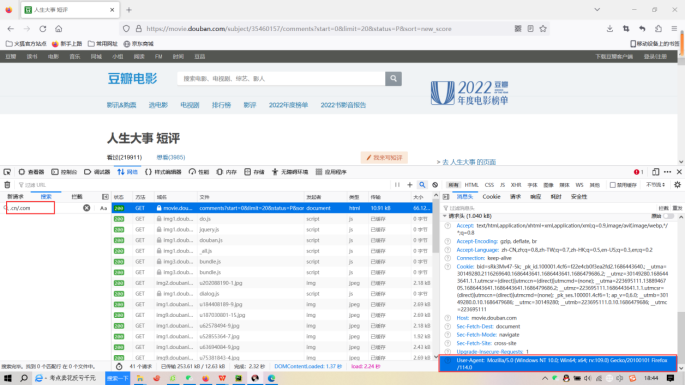
图5 搜索请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/114.0'
}
然后找一下短评对应的标签(这里以360浏览器为例,火狐截图不能把每一步都截下来)
图6 爬取页面1
图7 爬取页面2
在审查元素查看代码时,发现每个代码块能够对应网页上的内容,经过多次尝试找到了短评内容对应的代码块,并将它逐步打开,如下图

图8 爬取页面3(缩略图)
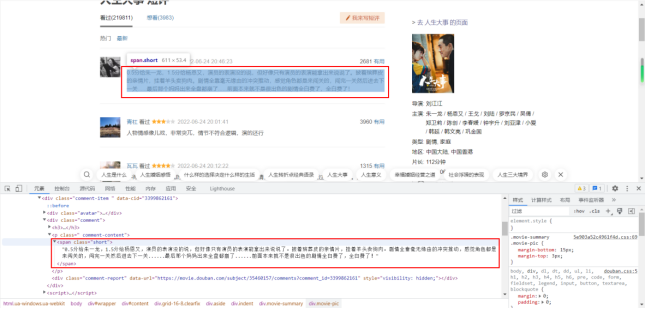
图9 爬取页面3(全屏图)
发现每条短评对应的标签是<span class="short">(.*)</span>,使用正则表达式提取短评内容,即代码为:
req = requests.get(url, headers=headers)
req.encoding = 'utf-8'
comments = re.findall('<span class="short">(.*)</span>', req.text)
这段代码的大致意思就是发送一个get请求,得到网页的html内容,然后用re.findall函数是从req.text这个字符串中匹配所有以'<span class="short">'开头、'</span>'结尾的字符串中包含任意字符的部分,并将其以列表的形式返回到comments变量中。
5.4 设置停用词并清洗词云
在第一次运行后,我发现在词云中出现了相当多的“的”“了”“也”等字,像这种没有实际意义的词我们就要把它删掉,否则这个词云图就不能更好地概括大家的评论关键点,如图10。

图10 未删除停用词的词云图(以《狂飙》为例)
所以我们需要添加停用词,但是手动添加停用词不仅不全面而且特别慢,最好的方法就是去网上复制。
图11 设置的停用词
以图11为例,这是我在网上复制的停用词,非常全面,从符号到中英文都有,运行后会有这样的词云图:

图12 改良后的词云图
经过复制的停用词删除后,效果好了很多,但是还是出现了“真的”,这个只能手动添加停用词了,最后运行出来的词云图是这样的,效果也比之前要好很多。

图13 最终的词云图
设置停用词代码如下:
stopwords_file = open('stopwords.txt', 'r', encoding='utf-8')
stopwords = [words.strip() for words in stopwords_file.readlines()]
这段代码的大概意思是打开了stopwords.txt的文件,并以只读模式读取该文件。encoding='utf-8'参数指定了该文件的编码格式为UTF-8,这样可以正确地读取文件中的中文字符。
第二行代码使用了列表推导式,将读取的每一行数据进行处理,去除其中的空格和换行符,并将处理后的结果添加到stopwords列表中。这里假设stopwords.txt中的每一行是一个需要移除的词语,因此stopwords列表中包含了所有需要移除的词语。
再在词云图这里加上这么一行代码,就能做到清洗掉stopwords文本中的内容了。
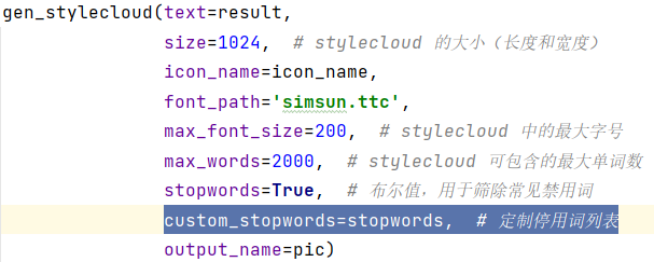
图14 清洗词云的部分代码图
5.5 stylecloud初体验
Stylecloud的参数:
text: 传入的字符串列表
file_path: 字符串的文本/ CSV的文件路径
gradient: 渐变方向 [「default:」 None]('horizontal')
size:stylecloud的大小(调大可提高图片清晰度)
icon_name: stylecloud形状的图标名称 [「default:」 fas fa-flag]
palette: 调色板 [「default:」 cartocolors.qualitative.Bold_5]
colors: 用作文本颜色的颜色 [「default:」 None]
background_color: 背景色(名称或十六进制)[「default:」 white]
max_font_size: stylecloud中的最大字体大小 [「default:」 200]
max_words: 要包含在stylecloud中的最大单词数 [「default:」 2000]
stopwords: 用于过滤掉常见的停用词 [「default:」 True]
custom_stopwords: list定制停用词列表 [「default:」 STOPWORDS, via word_cloud]
output_name: stylecloud的输出文件名 [「default:」 stylecloud.png]
font_path: 要在stylecloud中使用的字体的.ttf文件的路径 [「default:」 uses included Staatliches font]
random_state: 控制文字和颜色的随机状态 [「default:」 None]
collocations: 是否包括两个单词的搭配(二字组)。与基本word_cloud软件包的行为相同 [「default:」 True]
invert_mask: 是否反转图标掩码,因此单词填充除图标掩码以外的所有空格 [「default:」 False]
Stylecloud中的icon_name可以从https://fontawesome.dashgame.com/中复制代码,直接调用。
图15 Font Awesome网站截图
在这里搜索一个apple图标,可以复制后直接调用,无需从网上找图片。(实验中以twitter图标为例)

图16 Font Awesome搜索截图
如果是twitter、wechat这些企业品牌图标代码则是fab+复制的代码;如果是sun等这些实心图标,则用fas+复制的代码;如果是电脑上有的这些常规图标,则用far+复制的代码。

图17 词云图
5.6 情感分析与snowNLP库简介
情感分析的基本流程通常包括:
1.自定义爬虫抓取文本信息;
2.使用Jieba工具进行中文分词、词性标注;
3.定义情感词典提取每行文本的情感词;
4.通过情感词构建情感矩阵,并计算情感分数;
5.结果评估,包括将情感分数置于0.5到-0.5之间,并可视化显示。
snowNLP简介
SnowNLP是一个常用的Python文本分析库,是受到TextBlob启发而发明的。由于当前自然语言处理库基本都是针对英文的,而中文没有空格分割特征词,Python做中文文本挖掘较难,后续开发了一些针对中文处理的库,例如SnowNLP、Jieba、BosonNLP等。
Snownlp主要功能包括:
中文分词(算法是Character-Based Generative Model)
词性标注(原理是TnT、3-gram 隐马)
情感分析
文本分类(原理是朴素贝叶斯)
转换拼音、繁体转简体
提取文本关键词(原理是TextRank)
提取摘要(原理是TextRank)、分割句子
文本相似(原理是BM25)
安装和其他库一样,使用pip安装即可
pip install snownlp
1、snownlp 常见功能及用法:
# -*- coding: utf-8 -*-
from snownlp import SnowNLP
s = SnowNLP(u"这本书质量真不太好!")
print("1、中文分词:\n", s.words)
"""
中文分词:
这 本书 质量 真 不 太 好 !
"""
print("2、词性标注:\n", s.tags)
print("3、情感倾向分数:\n", s.sentiments)
"""
情感分数:
0.420002029202
"""
print("4、转换拼音:\n", s.pinyin)
print("5、输出前4个关键词:\n", s.keywords(4))
print("6、输出关键(中心)句:\n", s.summary(1))
print("7.1、输出tf:\n", s.tf)
print("7.2、输出idf:\n", s.idf)
n = SnowNLP('「繁體字」「繁體中文」的叫法在臺灣亦很常見。')
print("8、繁简体转换:\n", n.han)
"""
繁简体转换:
「繁体字」「繁体中文」的叫法在台湾亦很常见。
"""
2、统计各情感分数段出现的评率并绘制对应的柱状图
对txt文件逐行进行情感倾向值计算,代码如下:
# -*- coding: utf-8 -*-
from snownlp import SnowNLP
import codecs
import os
source = open("data.txt", "r", encoding='utf-8')
line = source.readlines()
sentimentslist = []
for i in line:
s = SnowNLP(i)
print(s.sentiments)
sentimentslist.append(s.sentiments)
import matplotlib.pyplot as plt
import numpy as np
plt.hist(sentimentslist, bins=np.arange(0, 1, 0.01), facecolor='g')
plt.xlabel('Sentiments Probability')
plt.ylabel('Quantity')
plt.title('Analysis of Sentiments')
plt.show()
3、利用新的数据训练情感分析模型
在实际的项目中,需要根据实际的数据重新训练情感分析的模型,大致分为如下的几个步骤:
准备正负样本,并分别保存,如正样本保存到pos.txt,负样本保存到neg.txt;
利用snownlp训练新的模型
保存好新的模型
重新训练情感分析的代码如下所示:
# coding:UTF-8
from snownlp import sentiment
if __name__ == "__main__":
# 重新训练模型
sentiment.train('./neg.txt', './pos.txt')
# 保存好新训练的模型
sentiment.save('sentiment.marshal')
使用训练后的模型需注意:
注意:若是想要利用新训练的模型进行情感分析,需要修改代码中的调用模型的位置。
data_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),'sentiment.marshal')
4、snownlp情感分析的源码解析
snownlp中情感分析的模块在sentiment文件夹中,其核心代码为__init__.py
如下是Sentiment类的代码:
class Sentiment(object):
def __init__(self):
self.classifier = Bayes() # 使用的是Bayes的模型
def save(self, fname, iszip=True):
self.classifier.save(fname, iszip) # 保存最终的模型
def load(self, fname=data_path, iszip=True):
self.classifier.load(fname, iszip) # 加载贝叶斯模型
# 分词以及去停用词的操作
def handle(self, doc):
words = seg.seg(doc) # 分词
words = normal.filter_stop(words) # 去停用词
return words # 返回分词后的结果
def train(self, neg_docs, pos_docs):
data = []
# 读入负样本
for sent in neg_docs:
data.append([self.handle(sent), 'neg'])
# 读入正样本
for sent in pos_docs:
data.append([self.handle(sent), 'pos'])
# 调用的是Bayes模型的训练方法
self.classifier.train(data)
def classify(self, sent):
# 1、调用sentiment类中的handle方法
# 2、调用Bayes类中的classify方法
ret, prob = self.classifier.classify(self.handle(sent)) # 调用贝叶斯中的classify方法
if ret == 'pos':
return prob
return 1 - probclass
Sentiment(object):
def __init__(self):
self.classifier = Bayes() # 使用的是Bayes的模型
def save(self, fname, iszip=True):
self.classifier.save(fname, iszip) # 保存最终的模型
def load(self, fname=data_path, iszip=True):
self.classifier.load(fname, iszip) # 加载贝叶斯模型
# 分词以及去停用词的操作
def handle(self, doc):
words = seg.seg(doc) # 分词
words = normal.filter_stop(words) # 去停用词
return words # 返回分词后的结果
def train(self, neg_docs, pos_docs):
data = []
# 读入负样本
for sent in neg_docs:
data.append([self.handle(sent), 'neg'])
# 读入正样本
for sent in pos_docs:
data.append([self.handle(sent), 'pos'])
# 调用的是Bayes模型的训练方法
self.classifier.train(data)
def classify(self, sent):
# 1、调用sentiment类中的handle方法
# 2、调用Bayes类中的classify方法
ret, prob = self.classifier.classify(self.handle(sent)) # 调用贝叶斯中的classify方法
if ret == 'pos':
return prob
return 1 - prob
从上述的代码中,classify函数和train函数是两个核心的函数,其中,train函数用于训练一个情感分类器,classify函数用于预测。在这两个函数中,都同时使用到的handle函数,handle函数的主要工作为:
1.对输入文本分词
2.去停用词
5.7 基于snowNLP进行情感分析
SnowNLP情感分析是基于情感词典实现的,其简单地将文本分为积极情绪和消极情绪,返回值为可能为该情绪的概率,也就是说,设定情感评分在[0,1]之间,越接近1,情感表现越积极,越接近0,情感表现越消极。对之前爬取到的《狂飙》短评数据集进行情感分析,并数据可视化绘制柱状图。
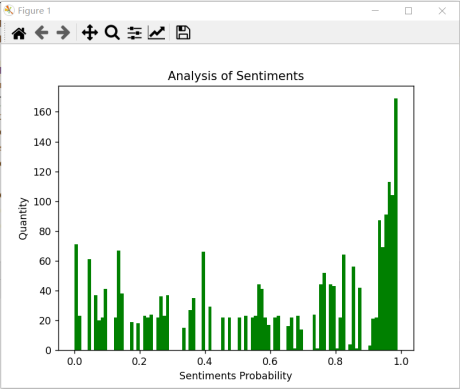
图18 情感分析柱状图

图19 部分情感倾向值
由图18、19可知,观众对于《狂飙》电视剧的短评基本上都是以积极情绪居多,不可能有任何一部电影或电视剧是0差评的,《狂飙》电视剧的消极评论主要集中在烂尾和嘴型对不上,这部电视剧还是值得我们大家去追一追的。
5.8 进一步做情感分析
以上的直方图并不能很好地让人一眼就知道评论的倾向情况,通过使用折线图可能可以从另一种情况反映出评论的倾向情况。
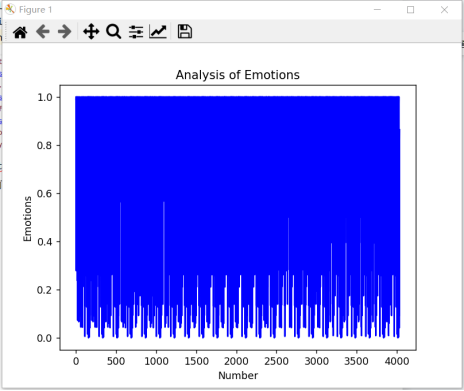
图20 情感分析曲线图1
将情感区间从[0, 1.0]转换为[-0.5, 0.5],这样的曲线更加直观,位于0以上的是积极评论,反之消极评论。
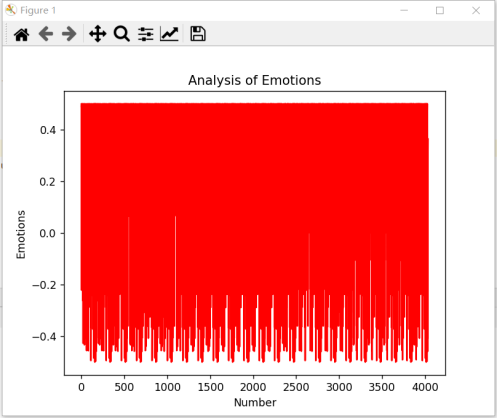
图21 情感分析曲线图2
由于《狂飙》的数据集实在是太大(4036条短评),所以为了让结果能够更加明显,我换了一部电影,但是通过看图20、21的密集程度,在上方的明显是更加的充实,红色填充得更多,在图接近最低面的方向有一些空缺,可以得出积极评论是更多的一方。另外的曲线图是以电影《人生大事》为案例做的,如图22、23。
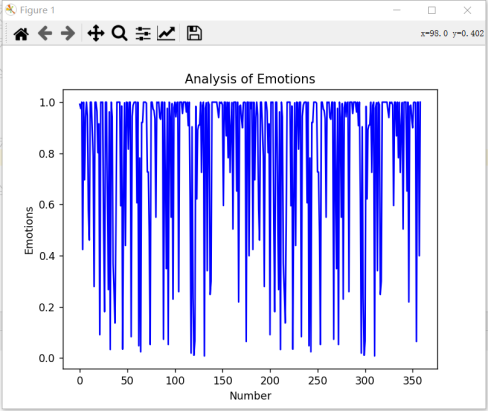
图22 情感分析曲线3
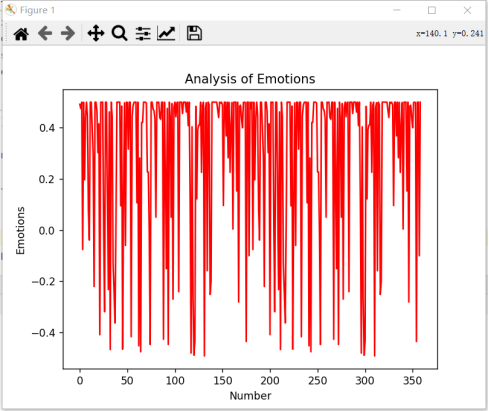
图23 情感分析曲线4
通过图22、23可以看到《人生大事》这部电影的积极评论也是明显的高于消极评论。
这是大学生涯的最后一次课程设计,我们接下来要面对的是毕业设计,在这一次课程设计中也是我最认真的一次课程设计,因为我想用这一次的课程设计给未来的毕业设计打下良好的基础,所以要搞清楚代码的意思和适合运用的场景非常重要。
基于中文的情感分析的运用场景很广,老师给出的示范代码是对京东商品的评论的分析,除了这个场景外还有网易云音乐评论、微博评论等,起初的想法是做微博评论或者网易云音乐评论,但是对于这两个网站实在是不太熟悉,一般都是用在手机app软件,所以最后还是做了豆瓣的短评,想抓抓一些电影的评论,也能供自己参考,这个项目也贴近于生活也对娱乐生活有益处,所以做这个项目我也非常有兴趣。
第一大块部分就是爬虫爬取数据、分词操作与构造词云图。爬虫爬取数据通过使用requests库模拟发送网页请求,最后得到一个html的网页内容,然后可以对html上的内容进行评论爬取,存在一个txt文件中。分词操作用到jieba库对短评句子进行分词并提取关键词,为stylecloud绘制词云图提供了基础。而在绘制词云图中,使用stylecloud库比wordcloud更方便更好用,它们的参数是差不多的,但是词云图的轮廓不需要我去网上找,直接选择网页上的即可。
第二大块部分就是情感分析。情感分析用到snowNLP库进行情感分析,它是对文本进行简单分类并返回一个概率值,由于返回的是概率值,所以可以根据这个数据进行直方图的绘制。
在实验的过程中也查阅了大量的资料,比如大家都用的是wordcloud,那个需要网上去找图片做词云图,而且图片的轮廓还不一定能够识别出来,有比较多的弊端,所以通过查阅资料后发现还有个stylecloud,这个库的功能和word cloud一样而且使用起来更方便,同时snowNLP情感预测模型的使用让这个实验结果更加完美。
这次实验让我印象深刻,我的毕业设计也会向情感分析的方向更进一步。

