


535
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享本节课主要由子豪大佬带来得语义分割基础知识和 MMSegmentation 算法库的介绍。
MMSegmentation算法库
MMSegmentation官方文档
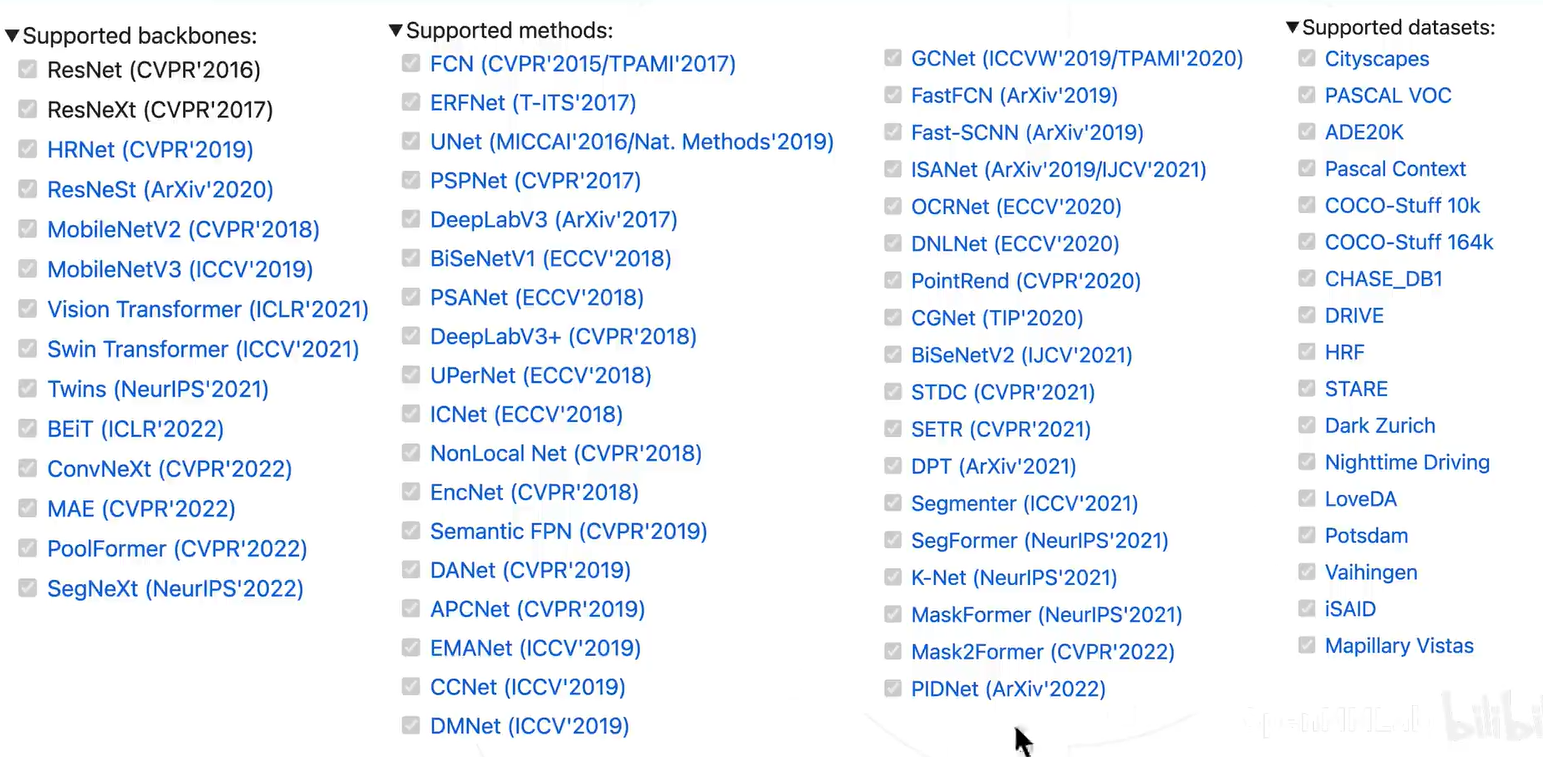
算法库支持的算法和数据集:
即将图像按照不同的类别分割成不同的区域,相当于对每个像素进行分类。

根据个人经验,这种底层的视觉任务更加适用于那些微观照片
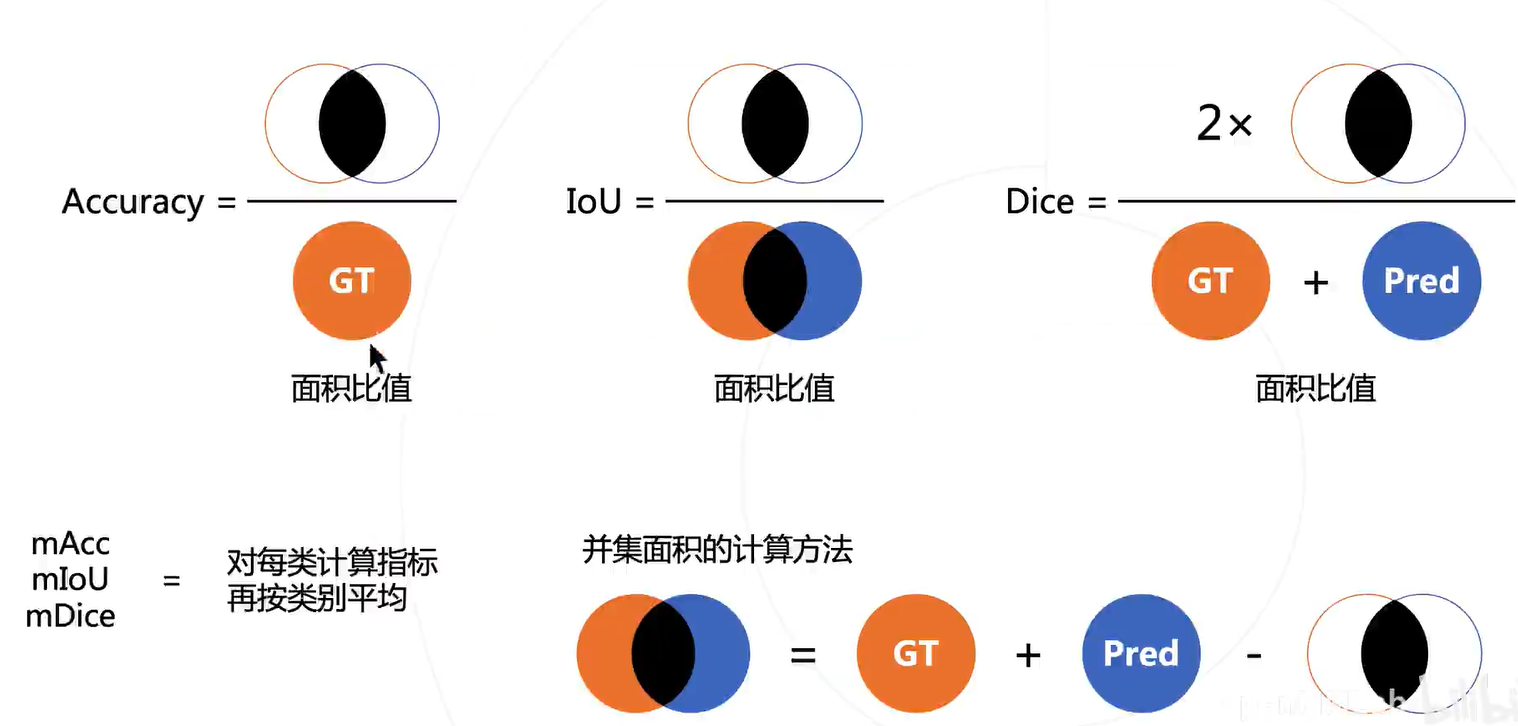
三者的难度越来越高。
先验知识:物体内部的颜色相近,边界的颜色变化
通过上面的先验知识就可以进行聚类,之前看过一篇 04 年的论文,差不多就是这个套路(只不过还有并查集等结构的引入),按颜色以及图结构进行语义分割:Efficient Graph-Based Image Segmentation
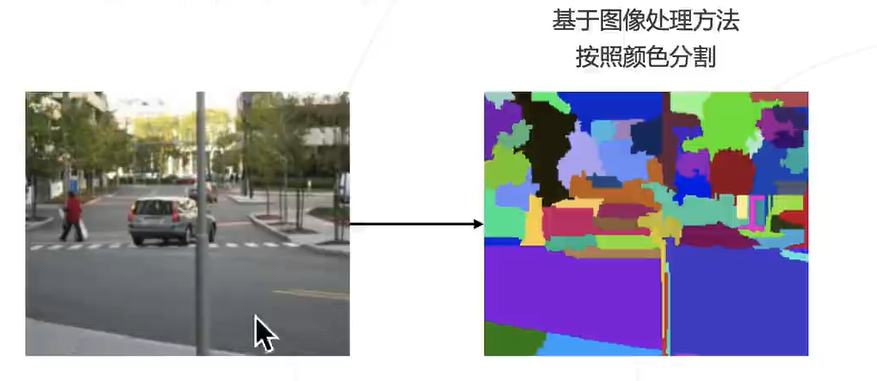
存在问题:
1. 先验知识不完全准确
2. 不同物体内部颜色可能相近,物体内也可能包含多个颜色

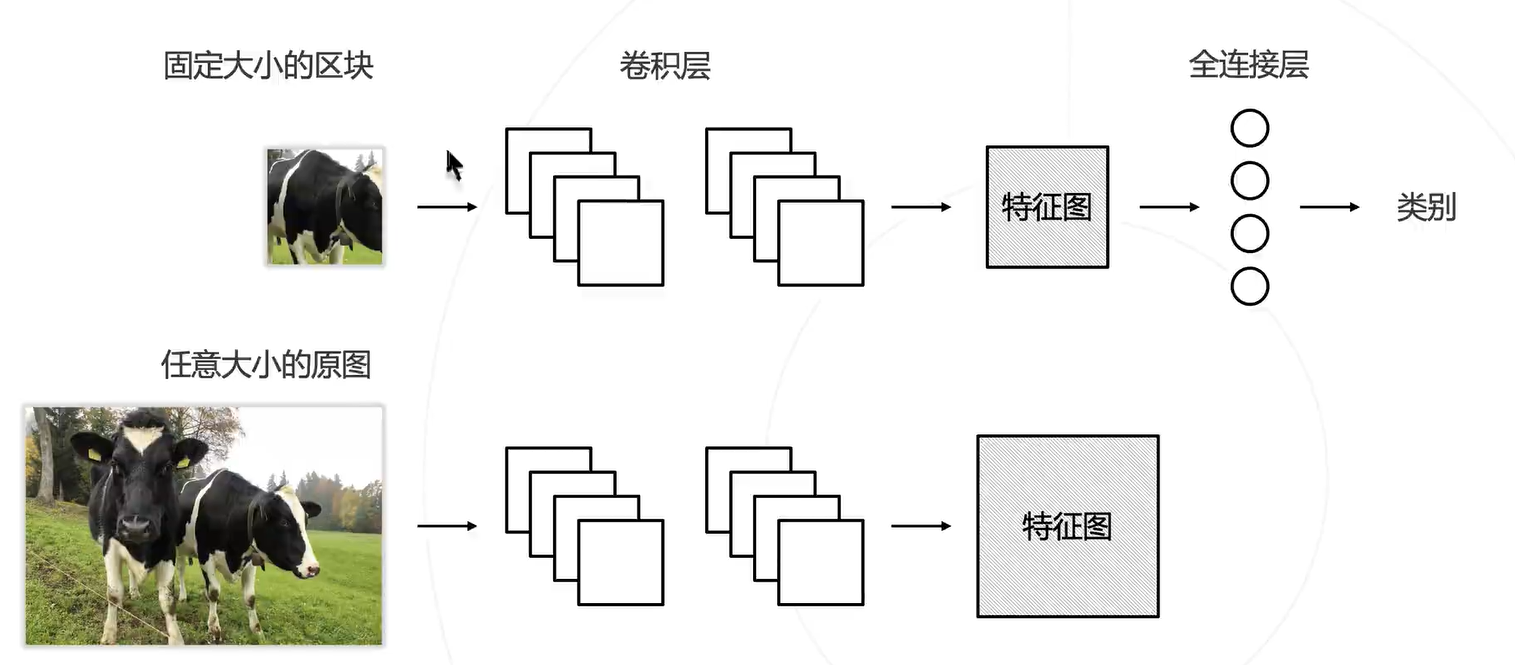
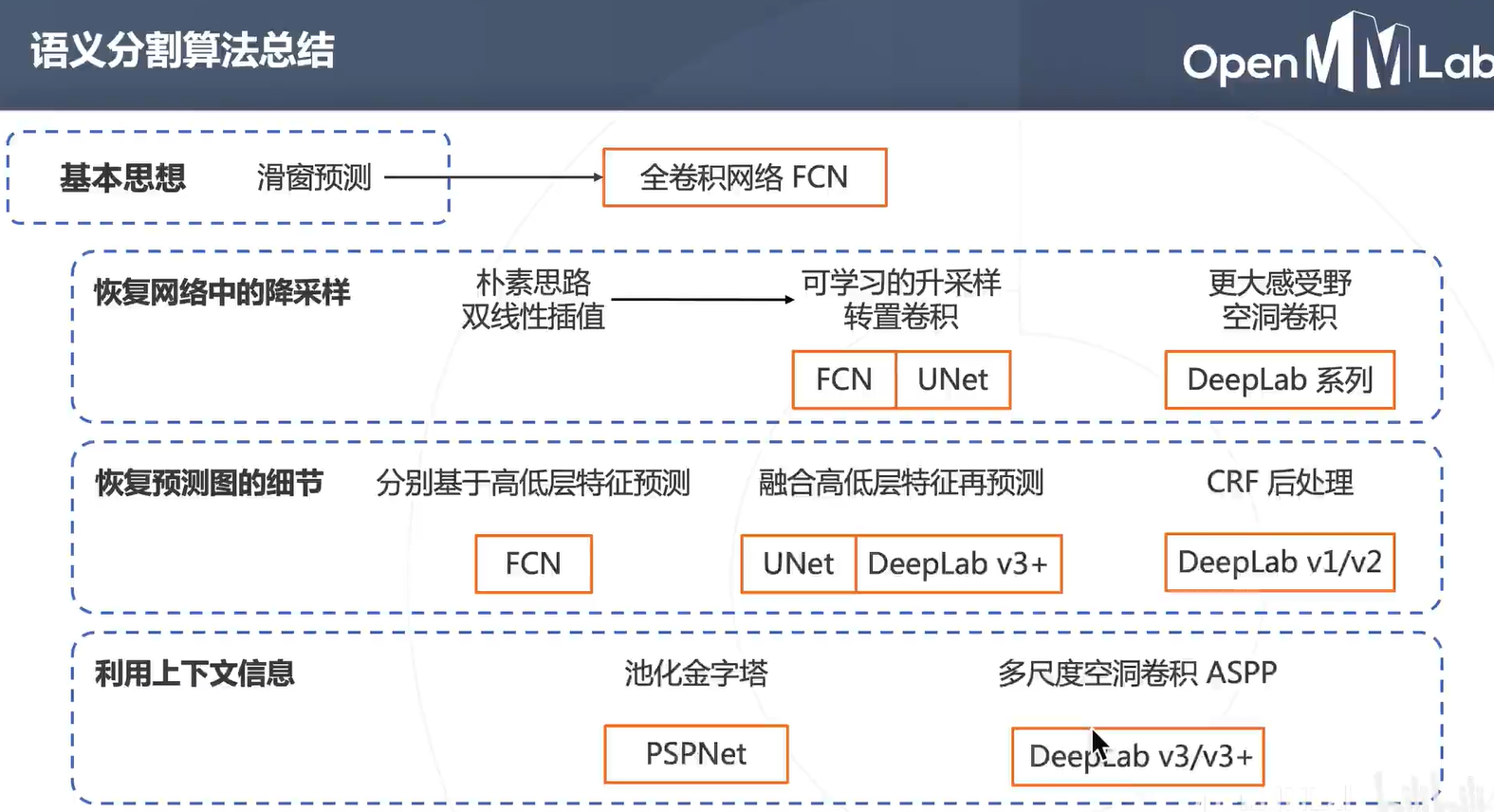
由于卷积神经网络的兴起给图像分类注入了新的血液,但之前都没有应用在图像分割领域。因此,最初的应用方式就是这种逐像素的分类,具体步骤如下:
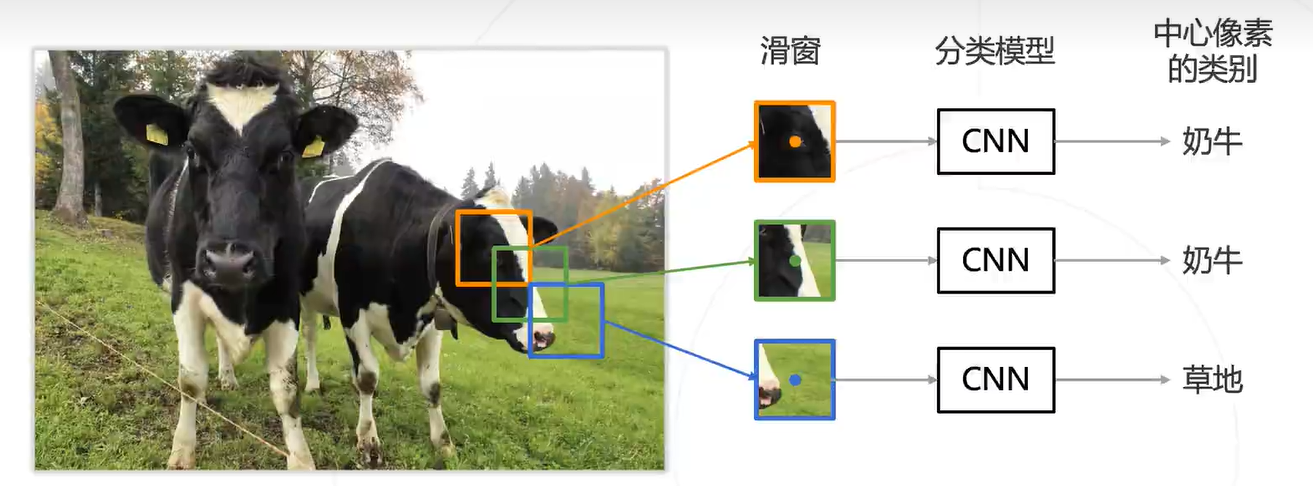
优点:可以充分利用起 CNN 模型
缺点:存在大量重复计算的重叠区域
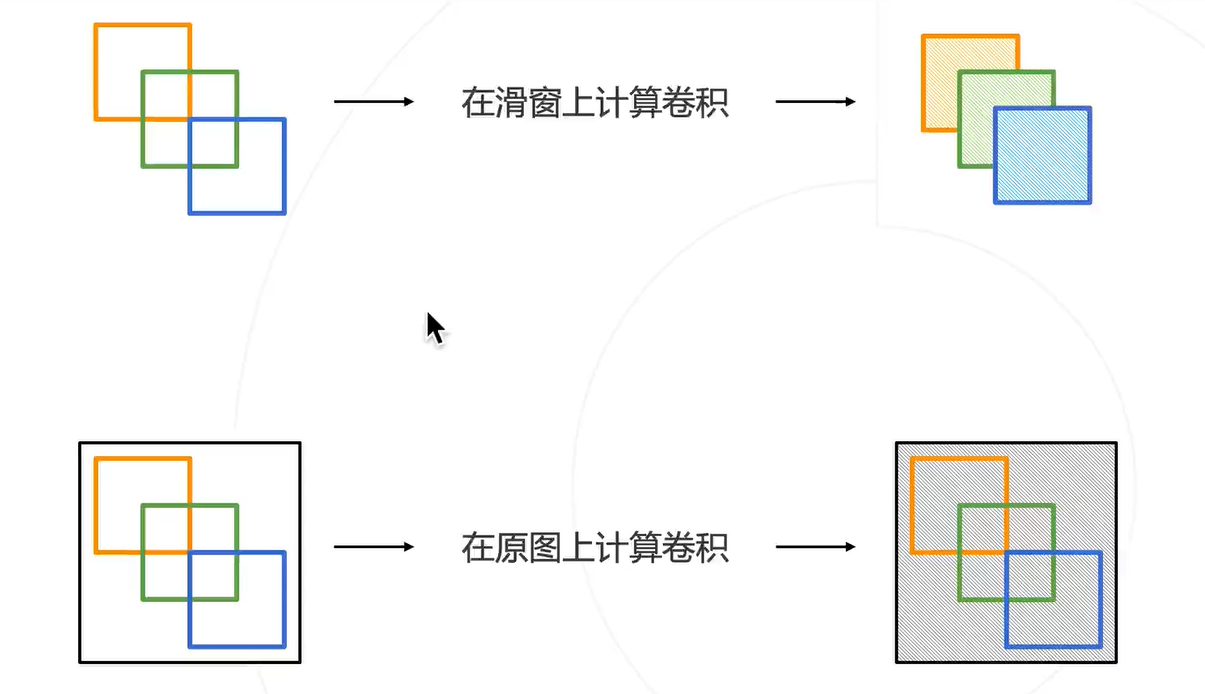
这一块个人感觉视频中没讲太清楚,所以借用了上一期的内容:
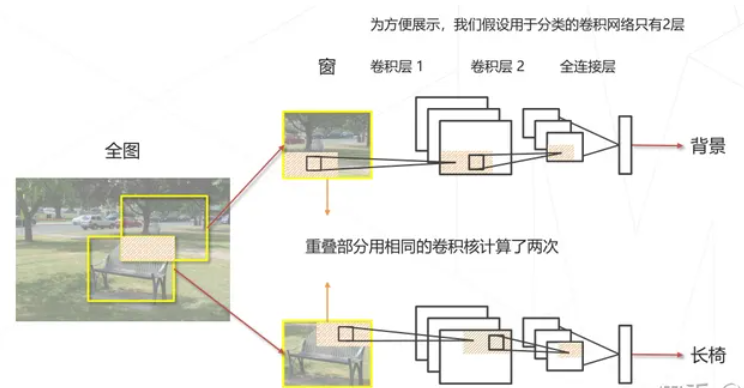
简单地讲,就是两个相邻的滑窗中间的重叠区域卷积后表现为相同的特征,因此这一块是可以被优化地。
在滑窗上计算卷积等价于在原图中计算卷积,因此可以在原图先计算一次卷积,然后复用这个结果。就相当于,先滑窗再卷积变成先卷积再滑窗,这样就少了很多重复计算了。
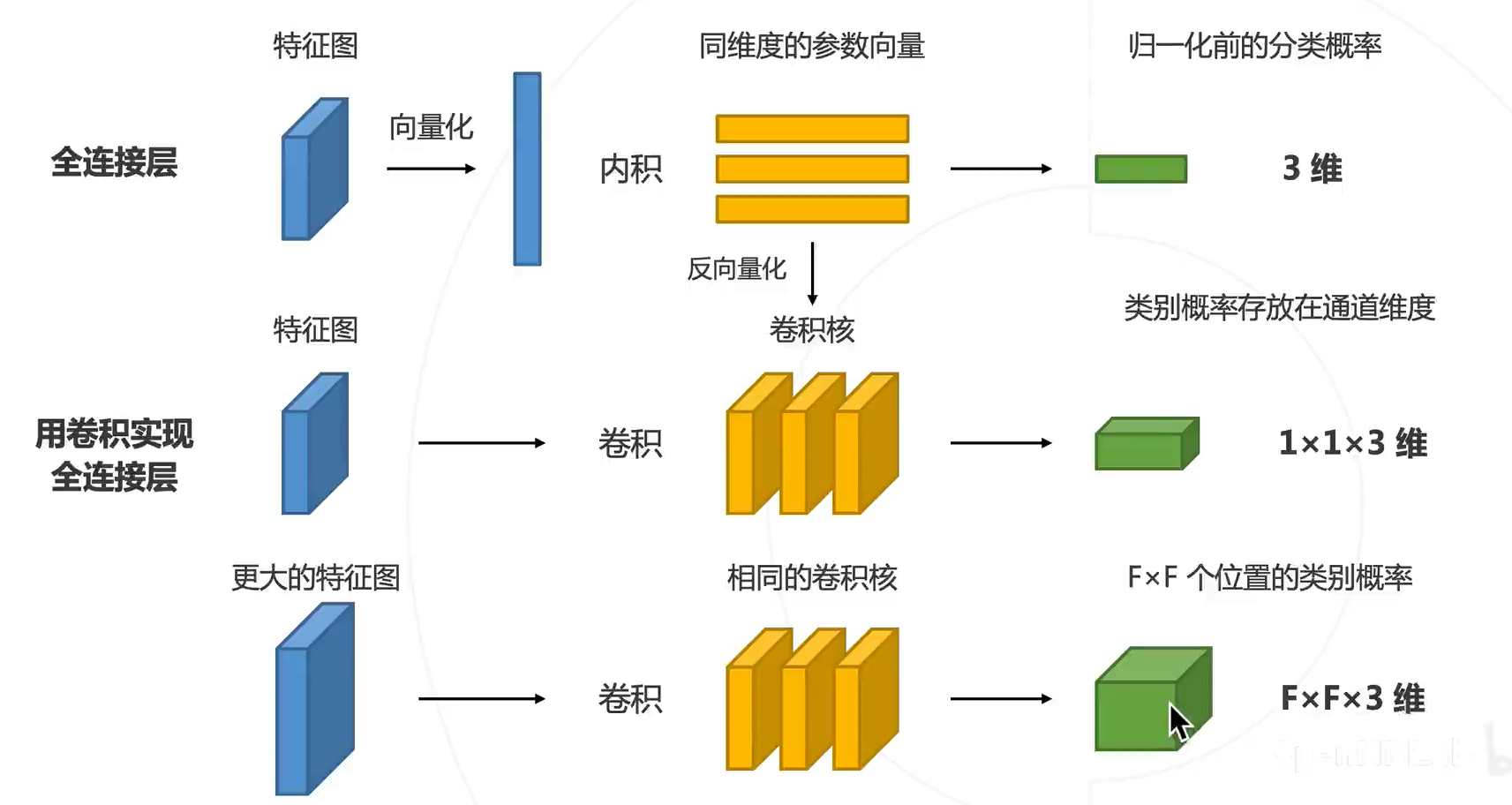
之前知道 1×1 的卷积核等价于全连接,子豪大佬这里说了来源,原来是 VGG 中提出的。感觉关键在反向量化那步。
2015 CVPR Best Paper
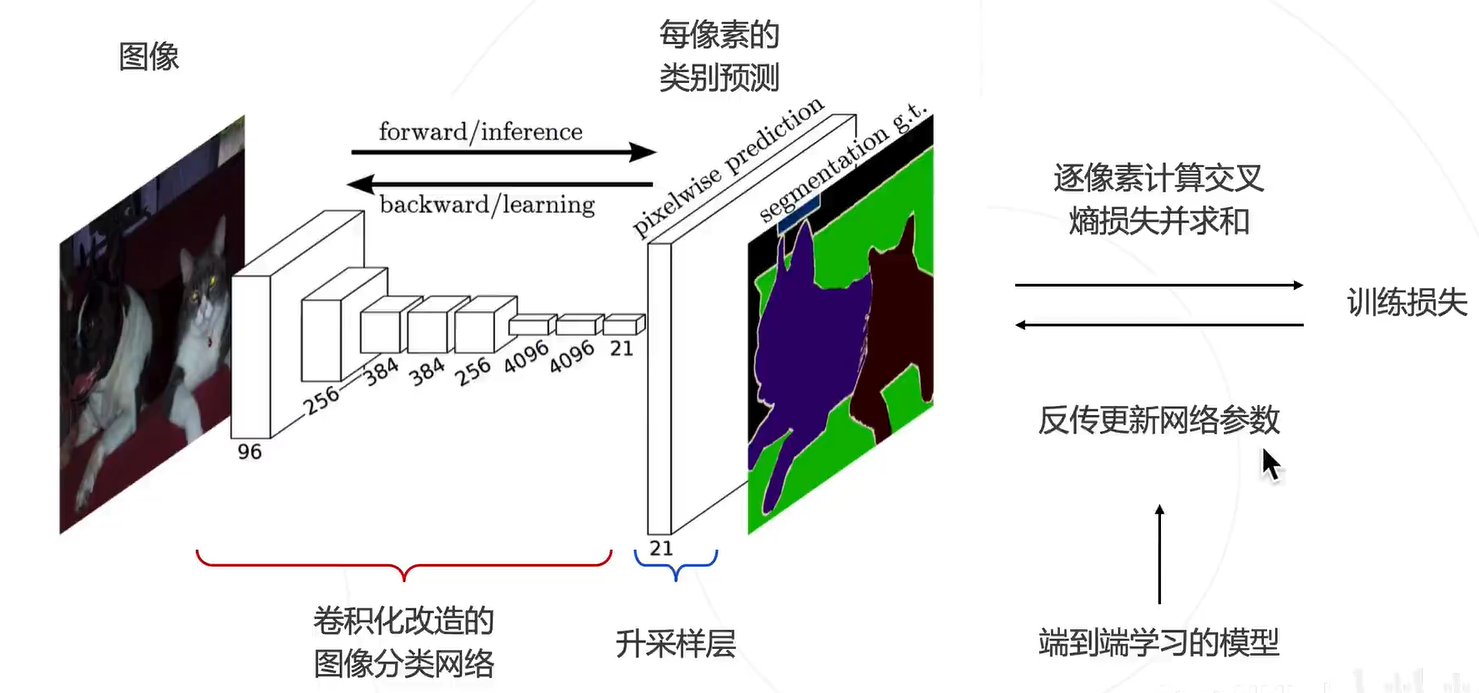
通过全连接卷积化,就把原来的图像分类的网络改成用于图像分割的网络,得到一张图片的概率图。
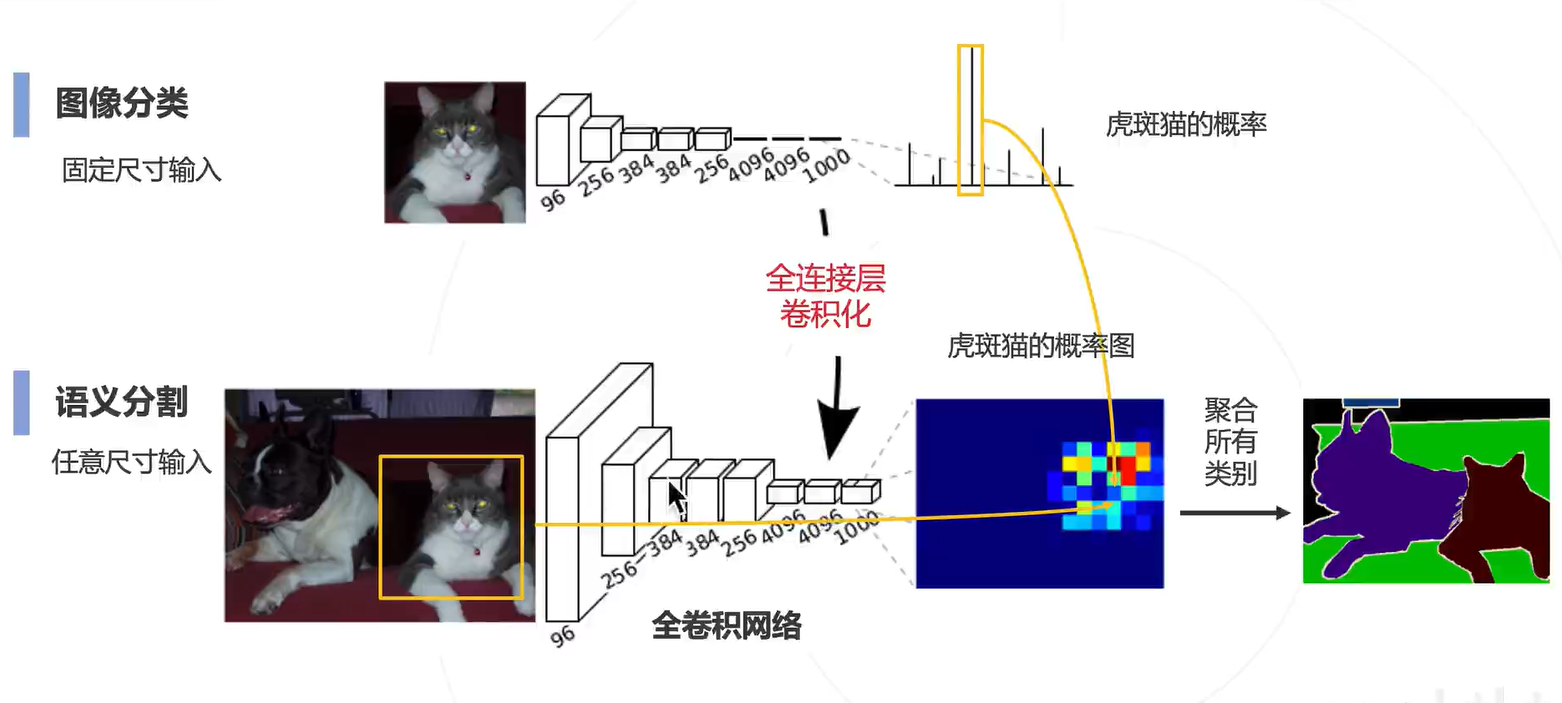
这里比较关键的一个问题就是如何把预测的图换源到原来图片特征图呢?技术:预测图升采样。恢复为原图的分辨率(小 Featur map --> 大 Feature map)
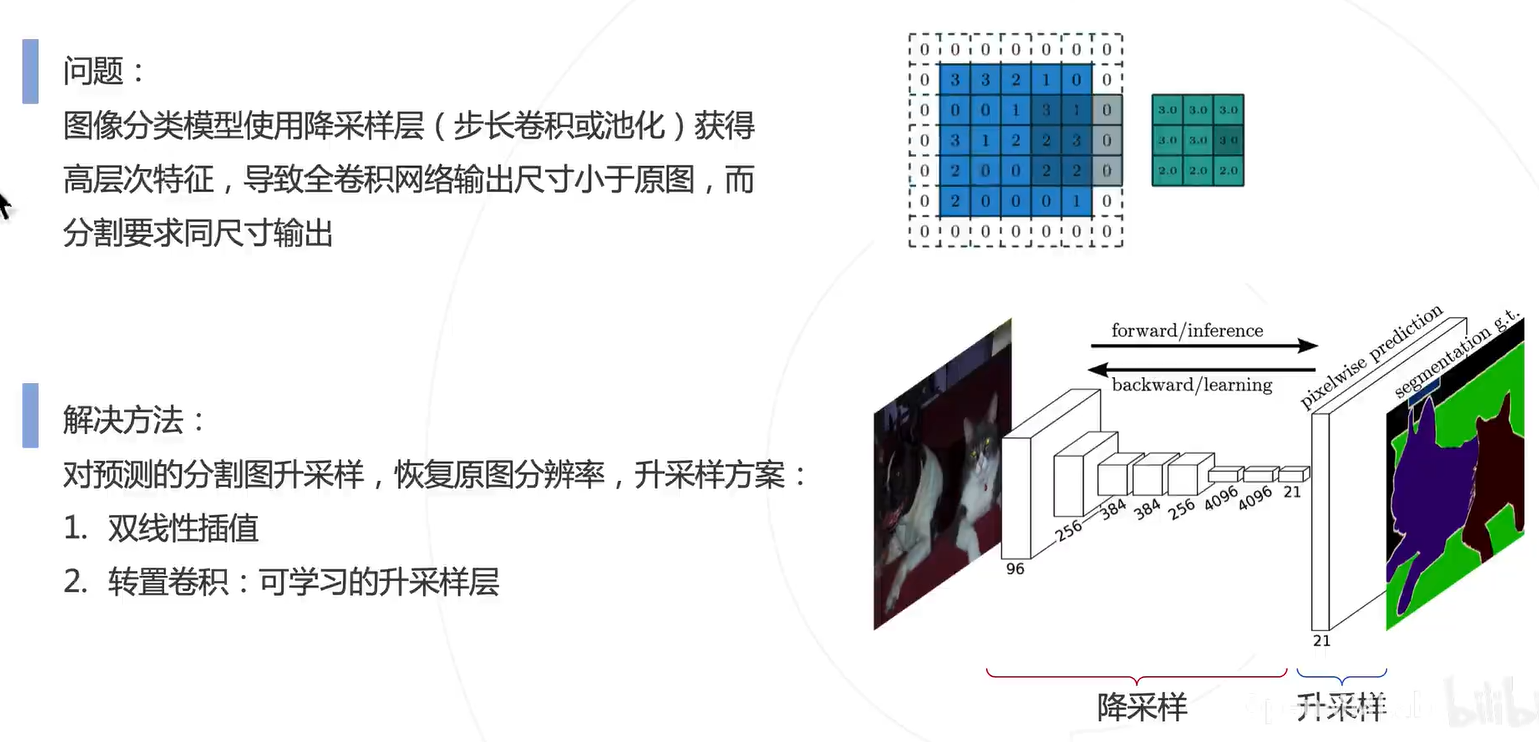
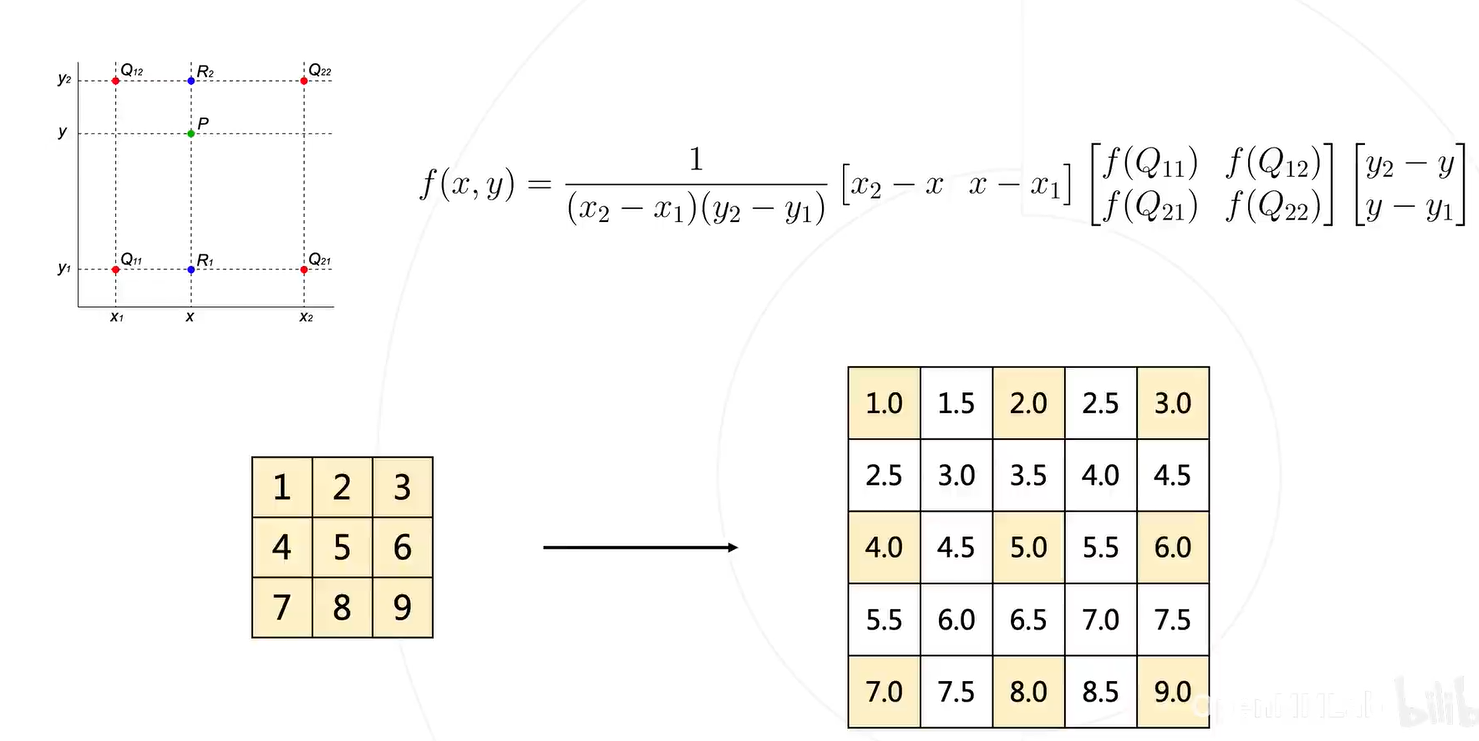
做法:1. 双线性插值;2. 转置卷积
一阶线性插值可以采用拉格朗日插值,二阶的相当于在基础上多做一次,只不过第二阶的输入是一阶的输出。
同样地,这种做法可以用卷积替代:
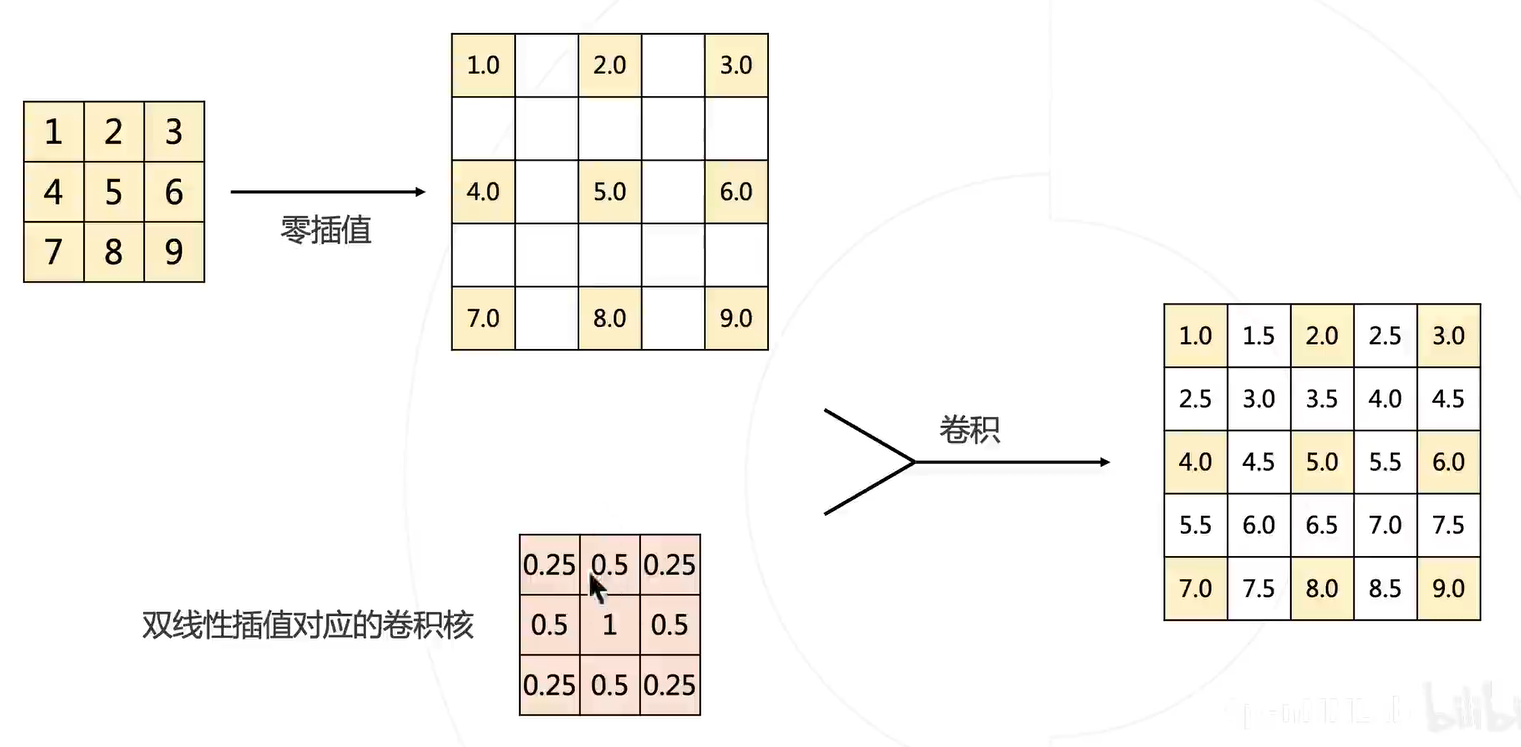
优点:这样的卷积是预定义好的,和那些 Sobel 滤波算法类似,不用学习。
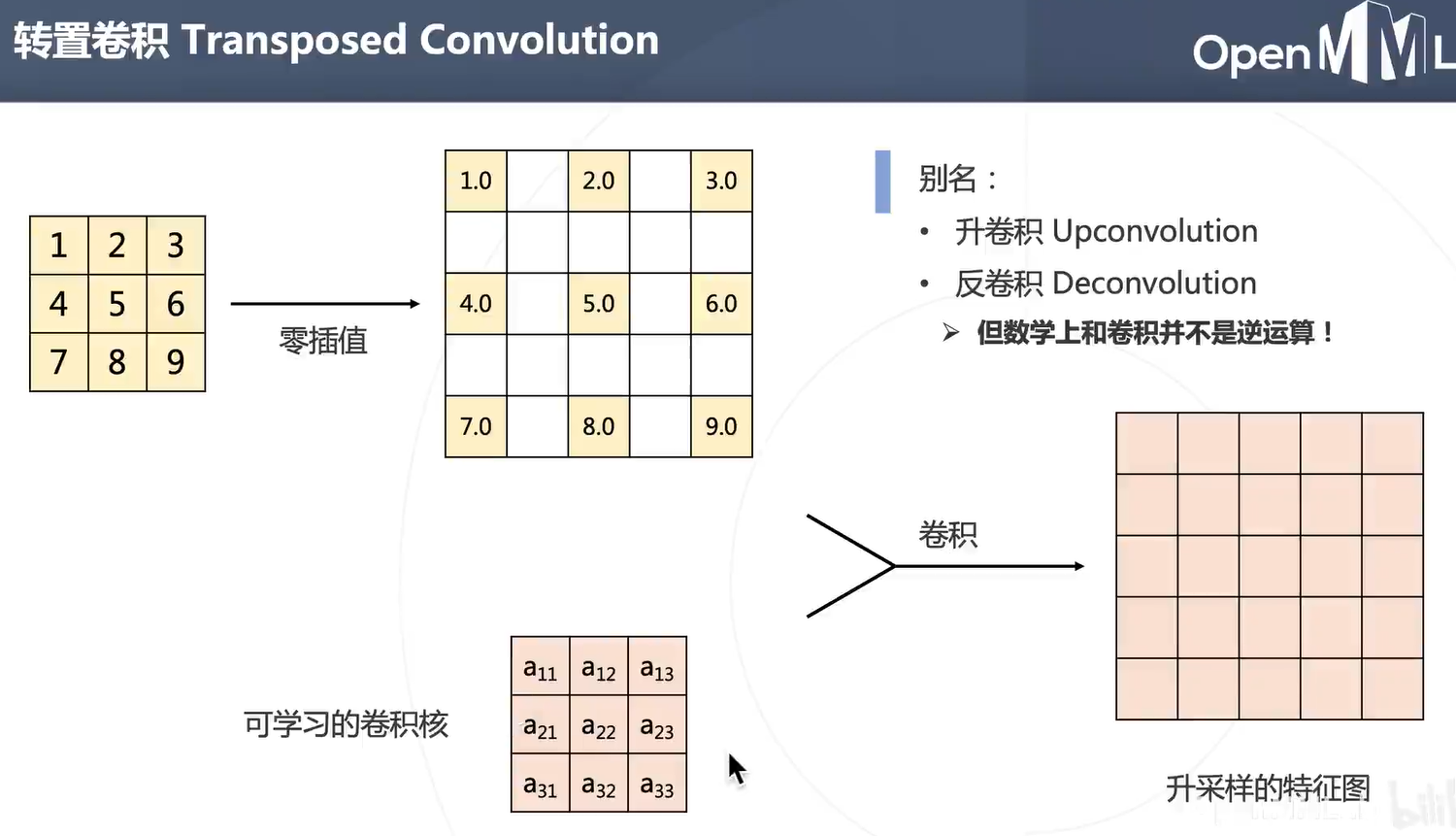
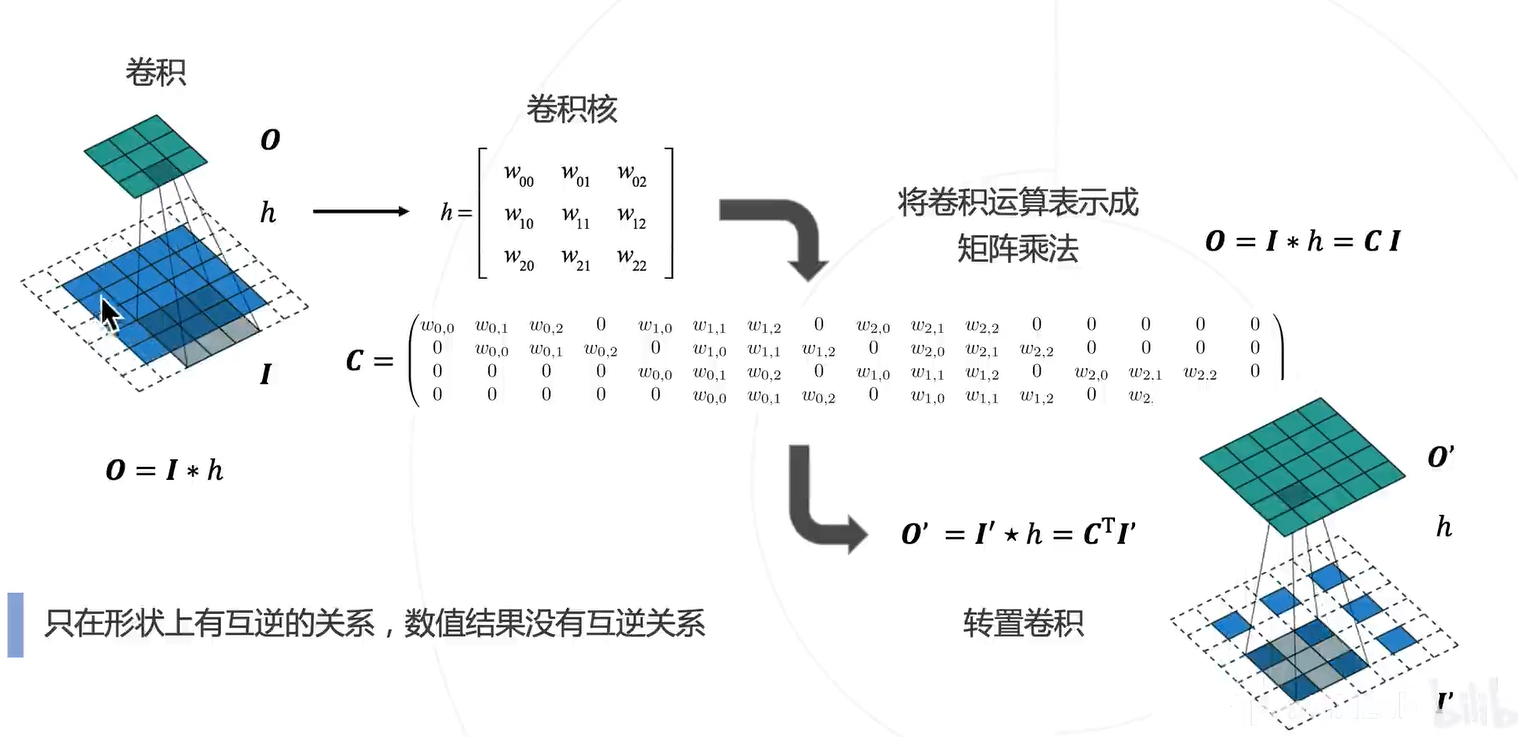
优点:可学习
和图像分类的区别就是中间升采样的部分,以及计算交叉熵的特征数会比图像分类网络多得多。
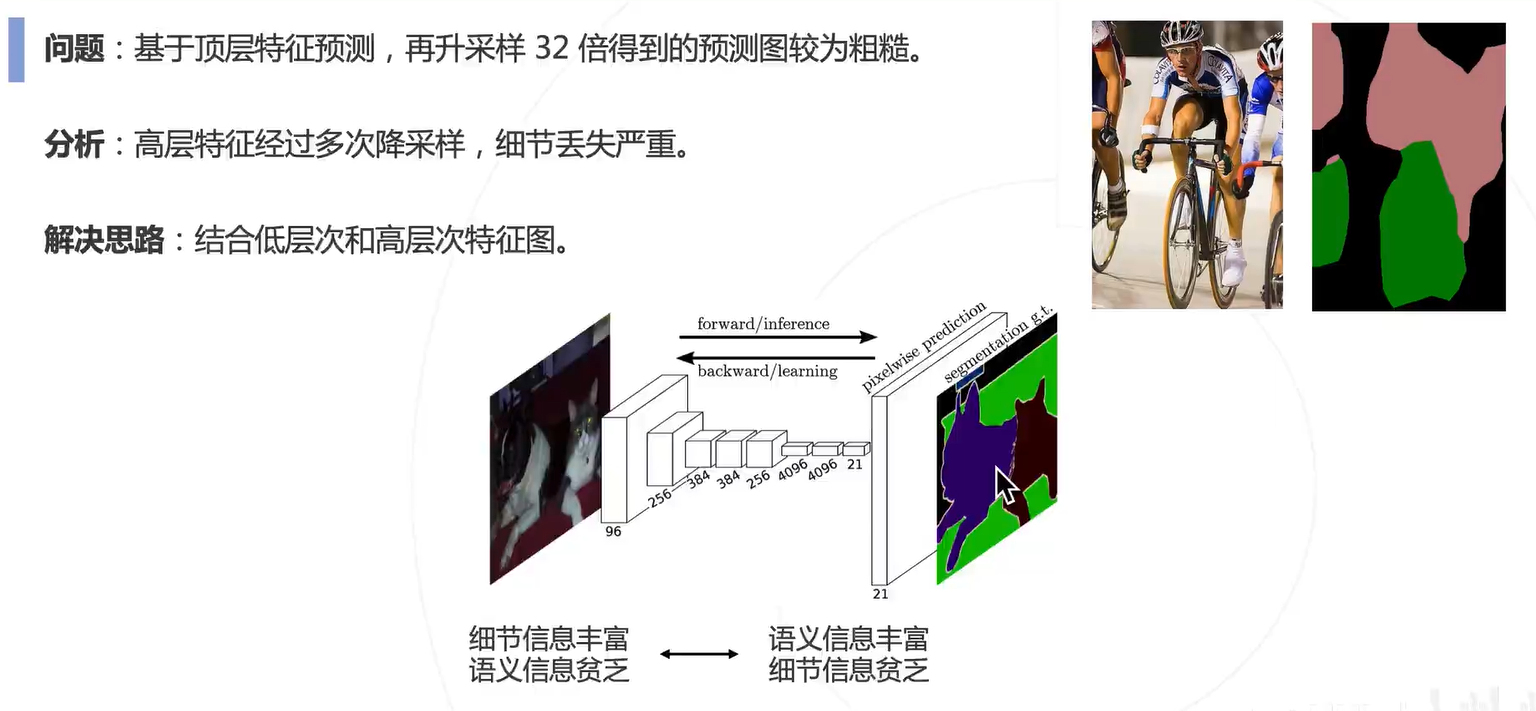
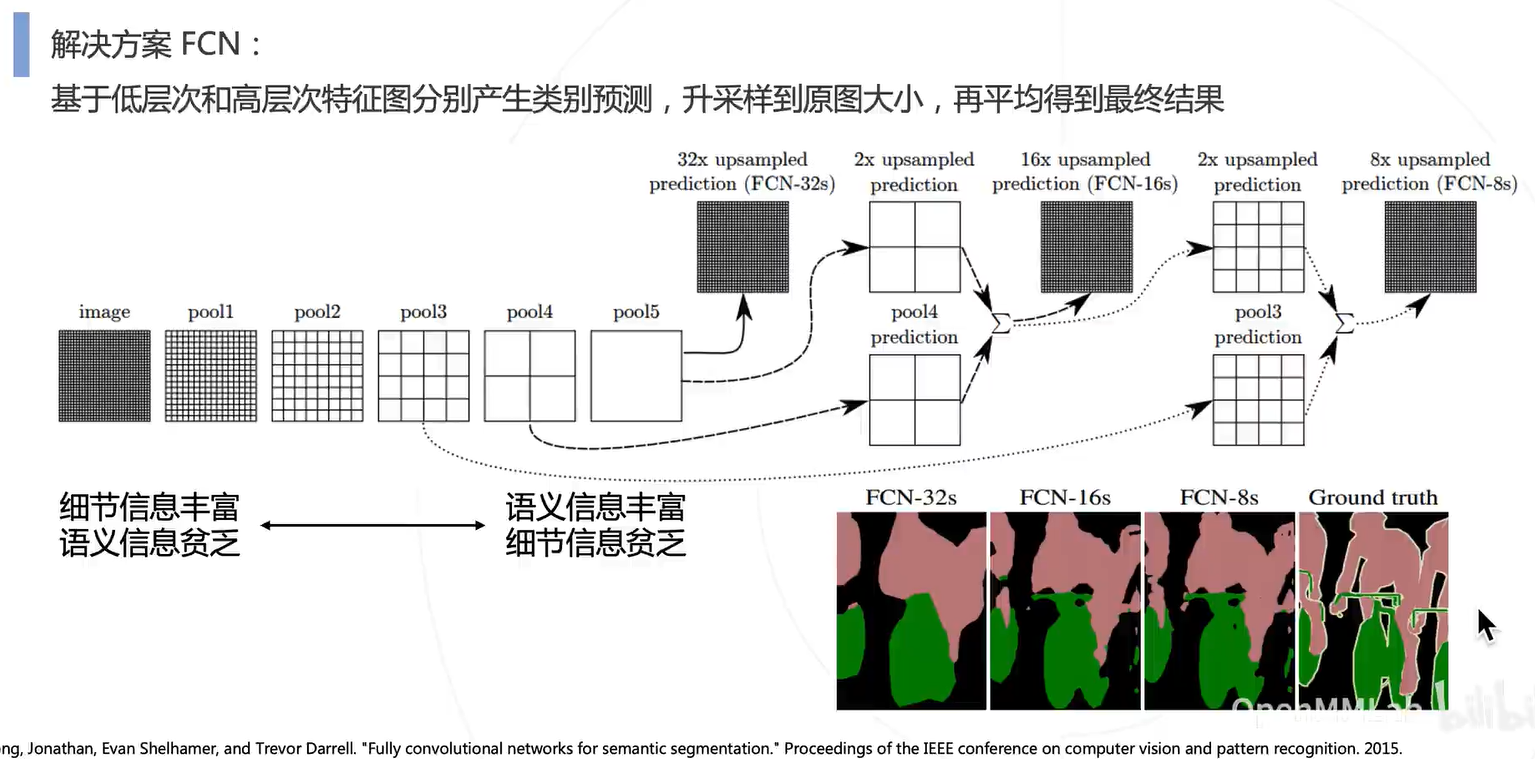
深层次的细粒度信息比较贫乏,而语义信息比较丰富;浅层则相反。因此结合深层和浅层的特征来还原语义分割图。
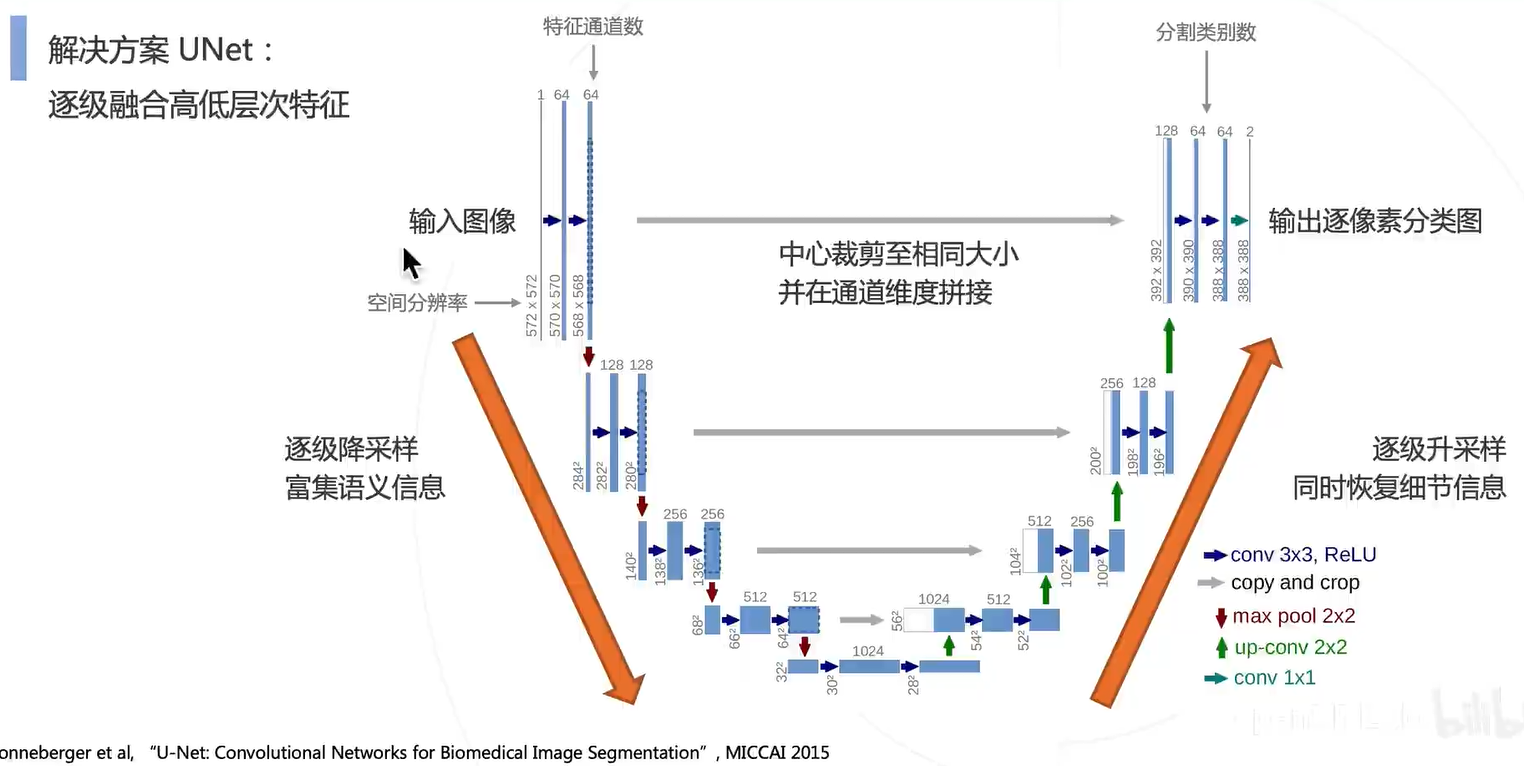
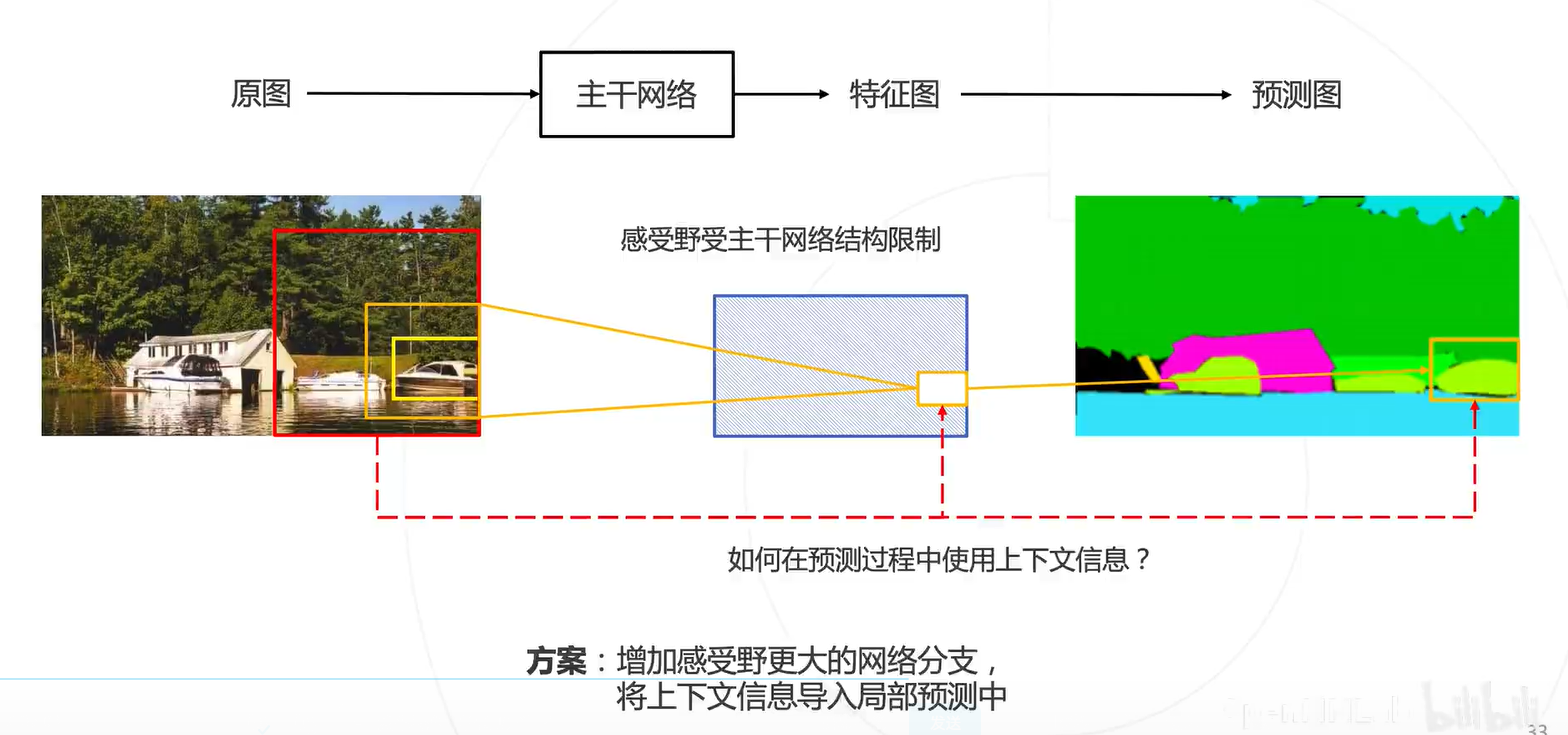
图像周围的内容就是上下文信息,可以帮助模型进行更准确的判断。所以模型就要有更大的感受野,结合上下文信息。
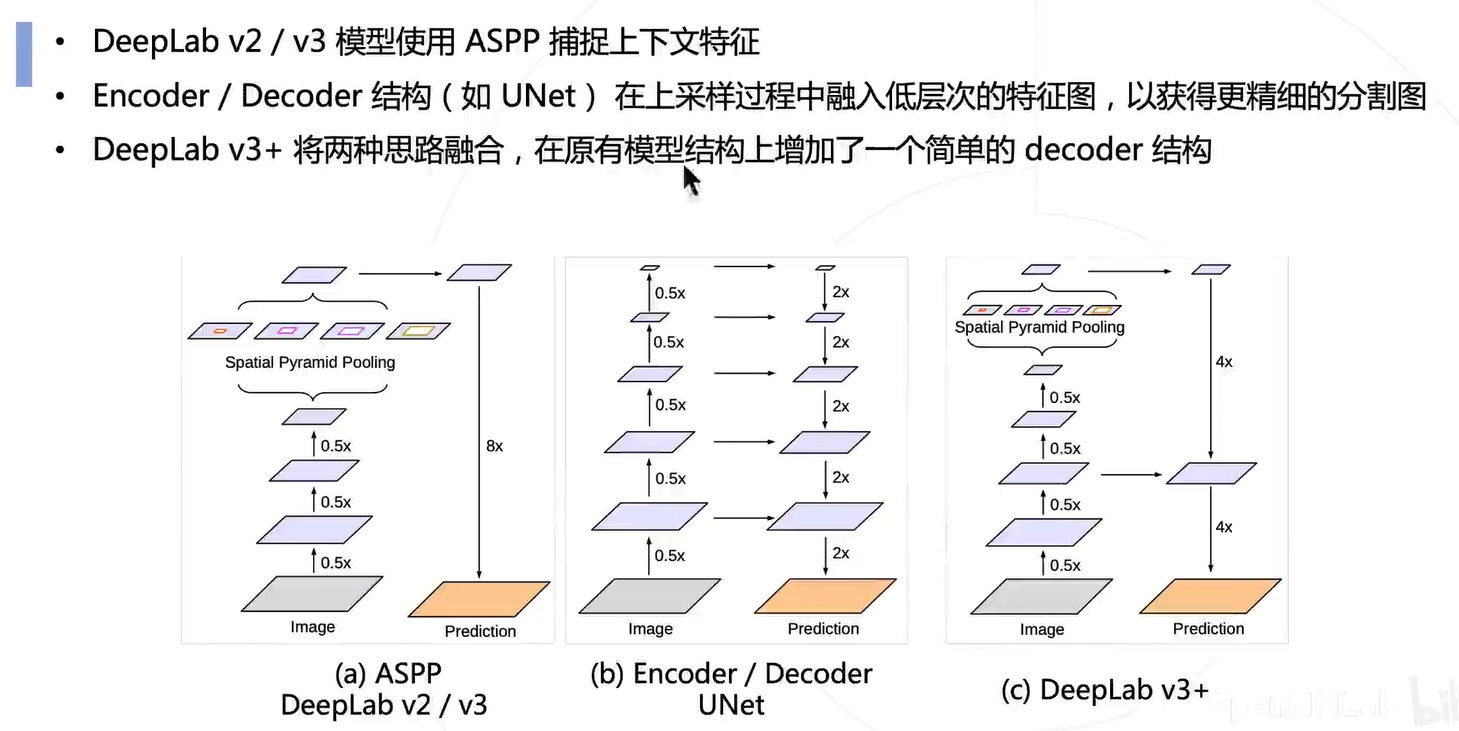
多尺度融合+上采样
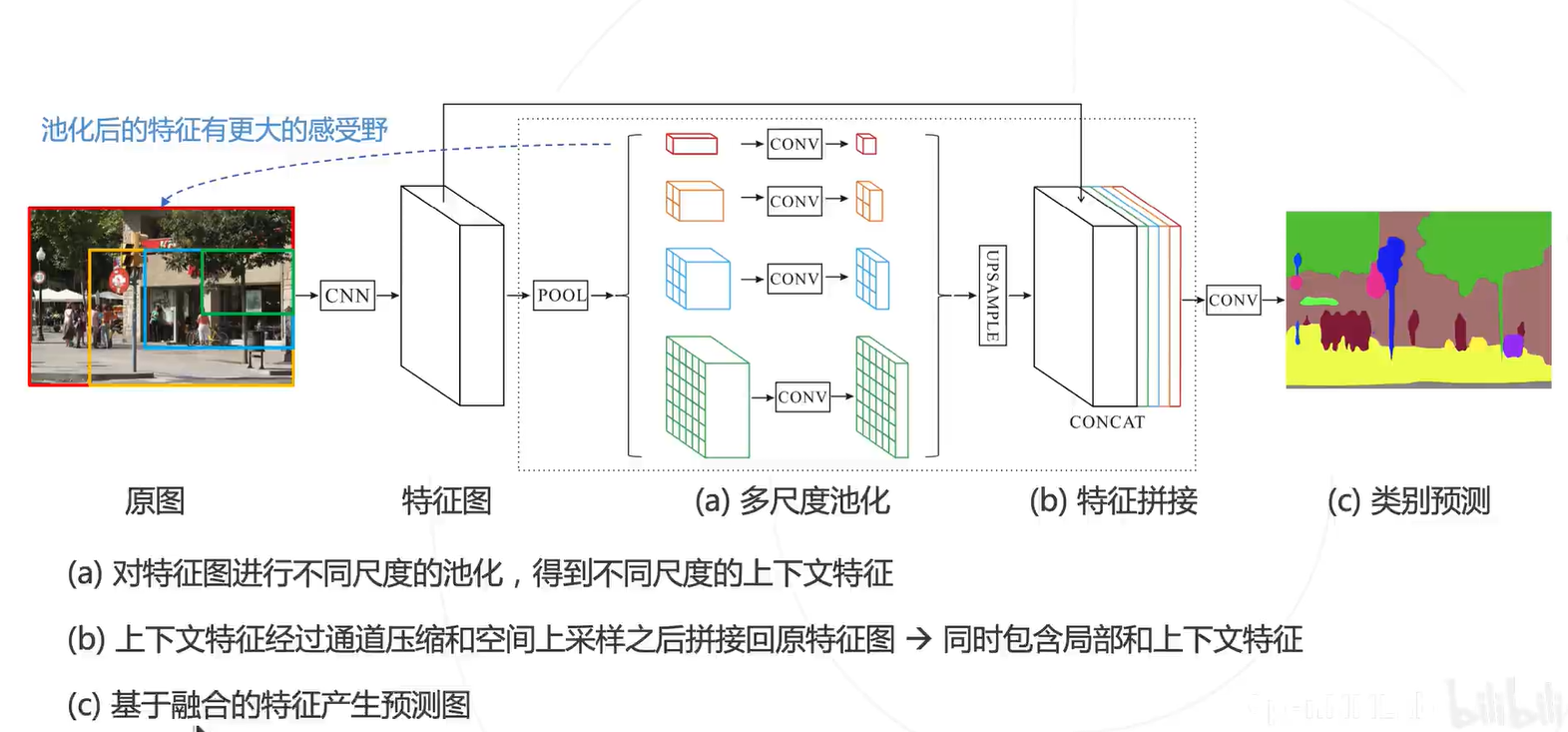
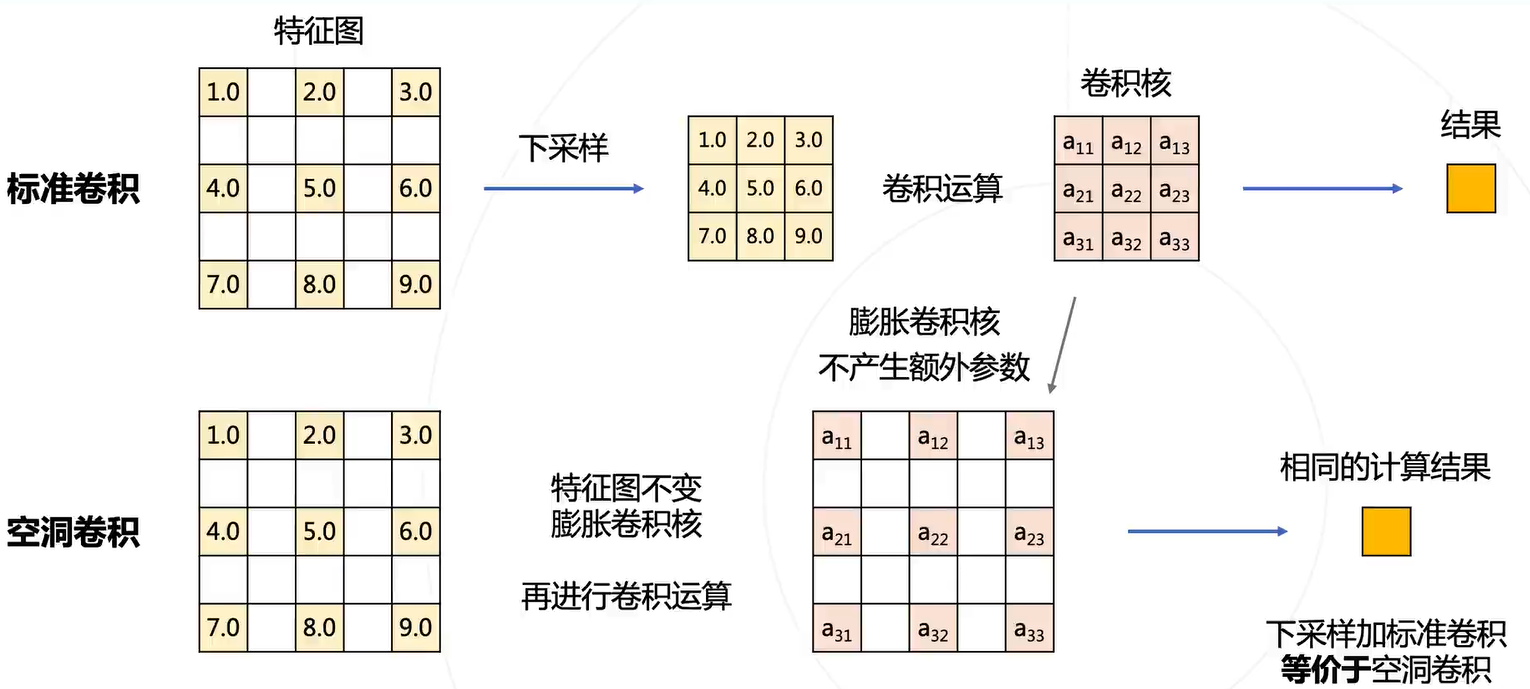
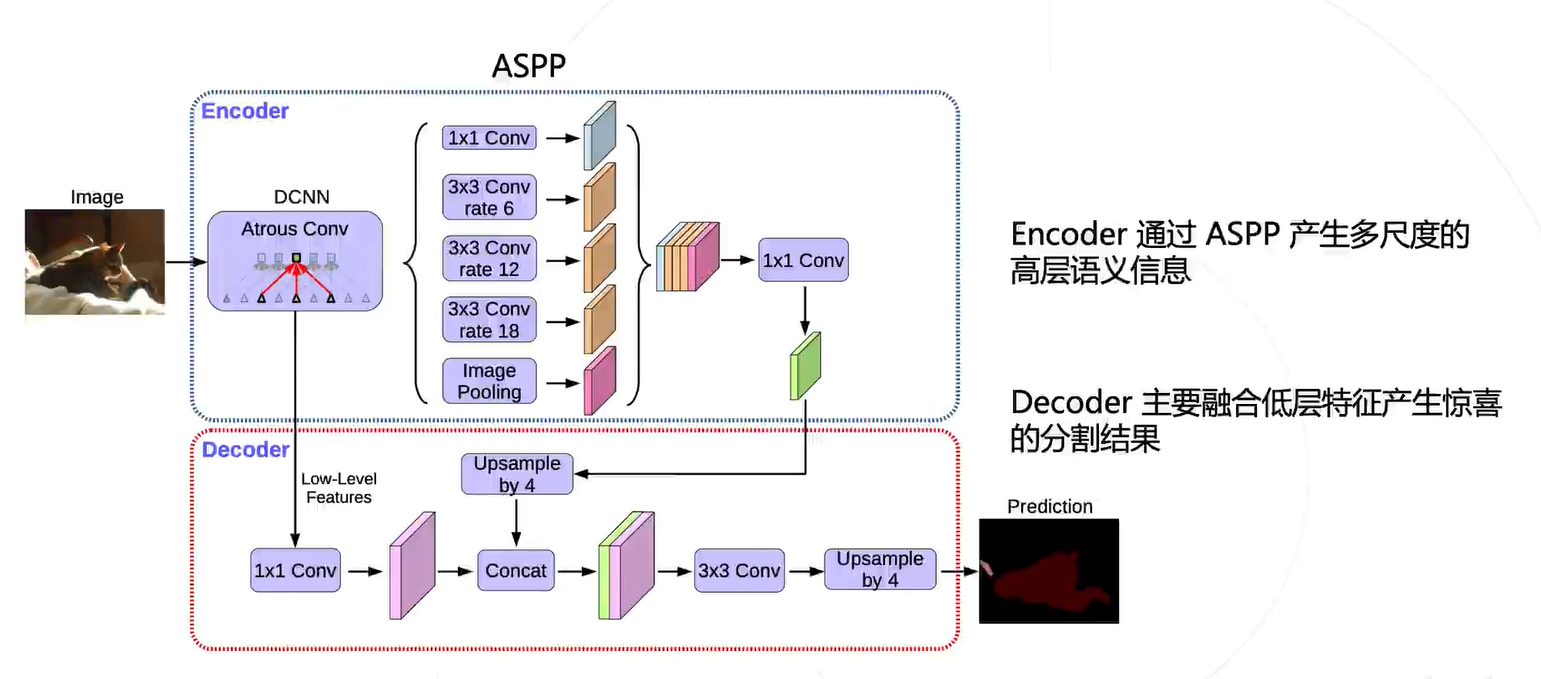
DeepLab 系列进一步把多尺度融合的思路发扬光大,并引入了空洞卷积增加卷积的感受野。

关键点:
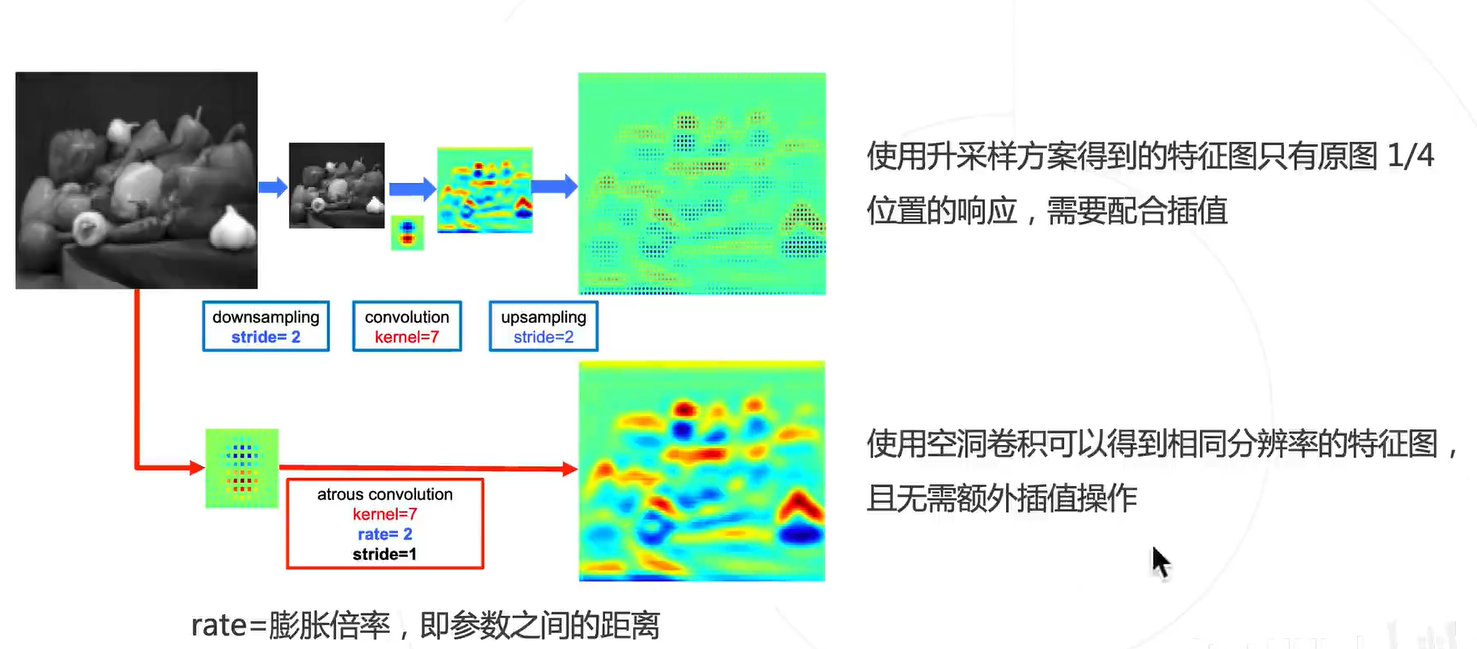
在不增加参数的情况下,增加感受野

空洞卷积=下采样+标准卷积
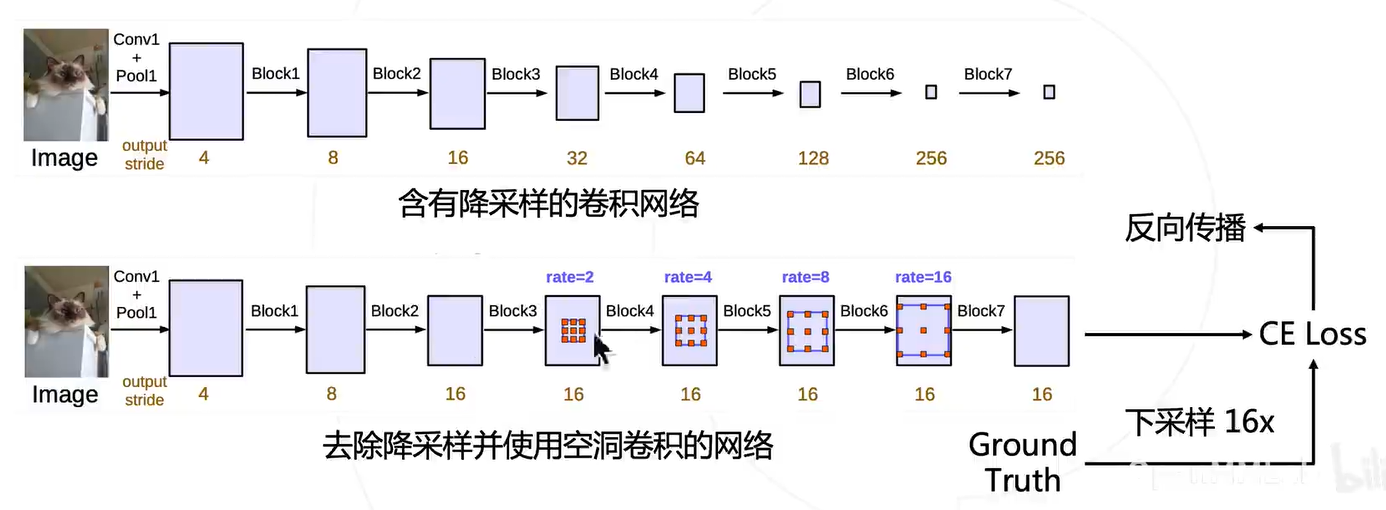
它在图像分类网络做以下修改:
结合原图颜色信息,对输出的特征进行边界精准化
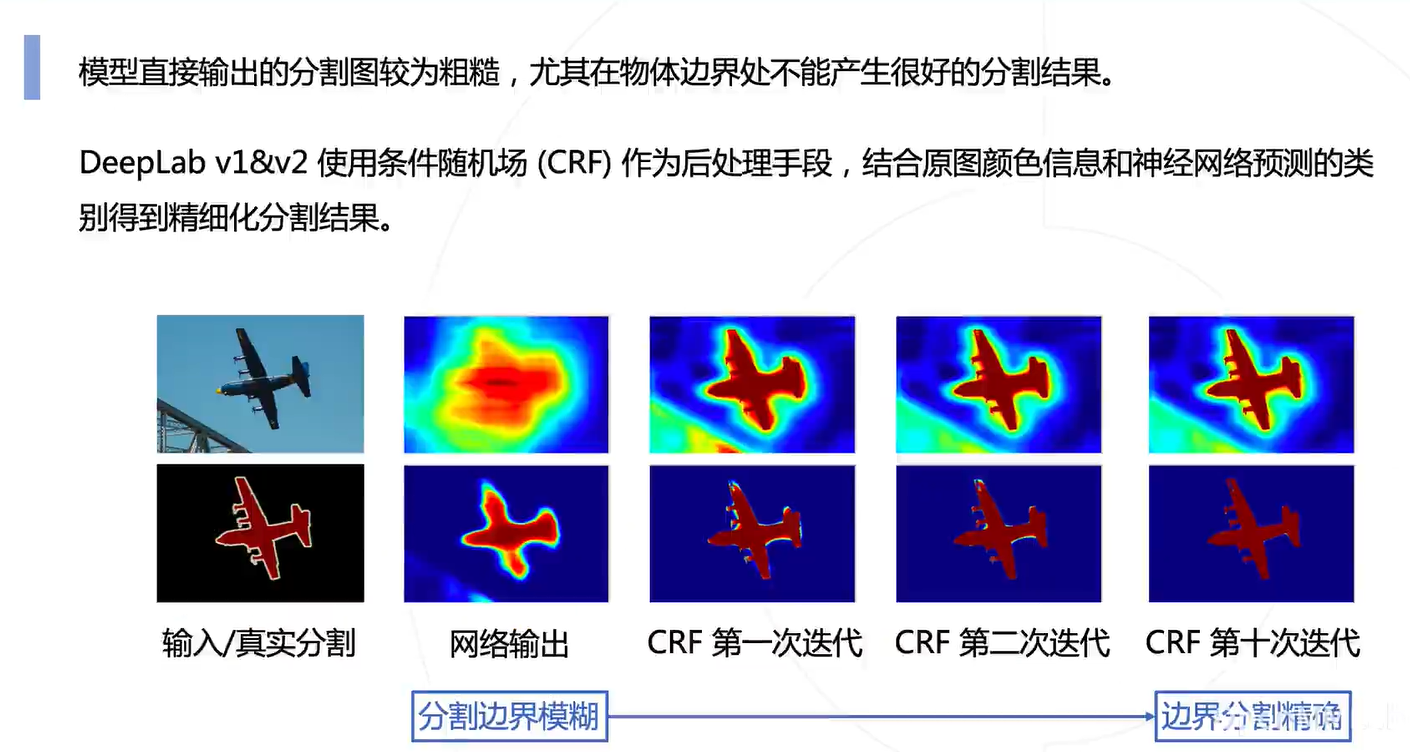
具体的做法就是在边界处加一个惩罚(物体内部尽量不要变,边界处颜色尽量要变,可以看出也有本文开头提到逐颜色预测的那个先验的味道):


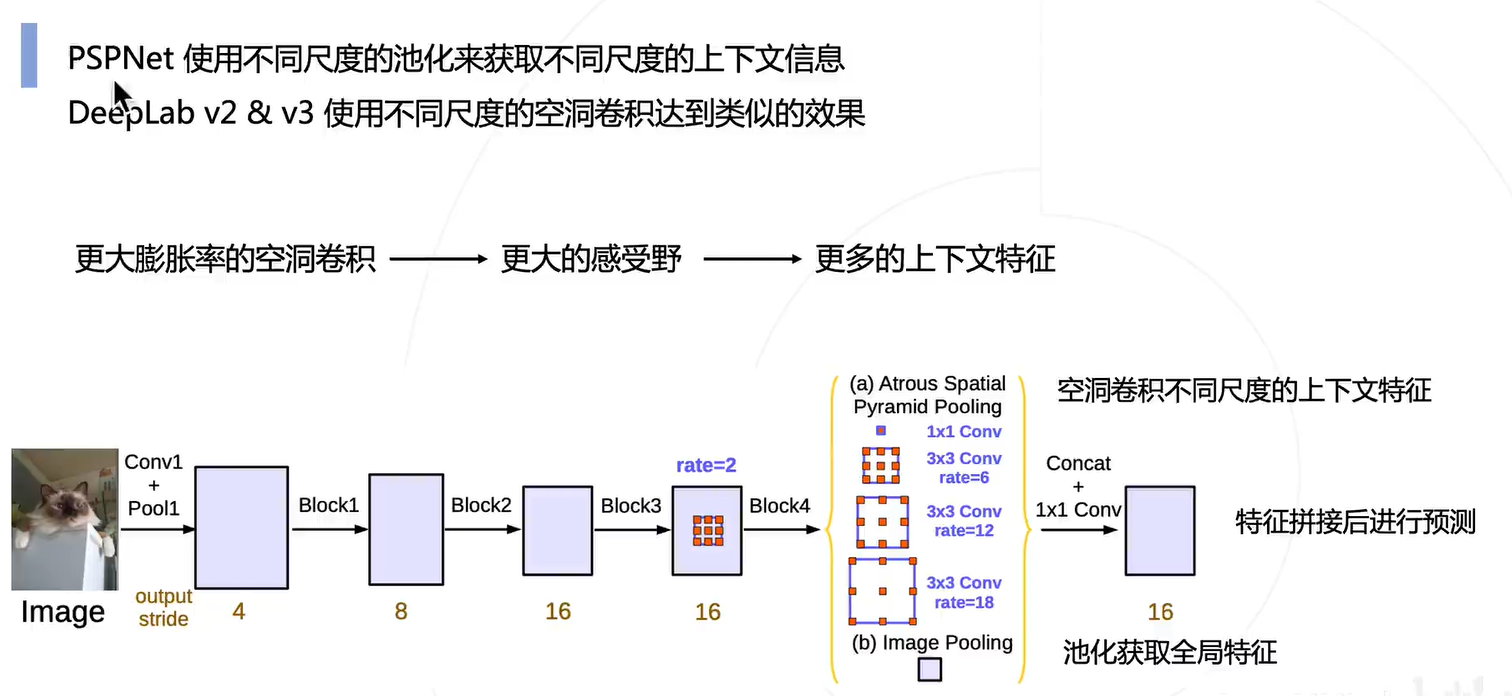
借鉴了 PSPNet 的思路
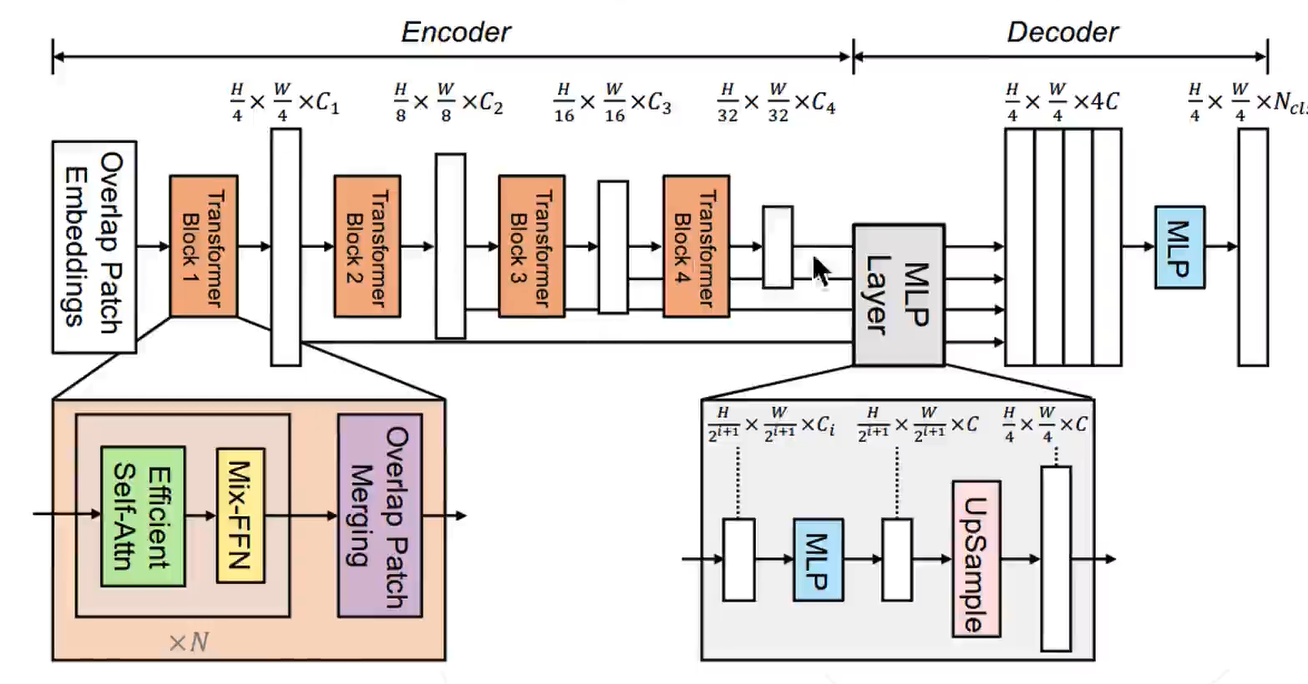
Transformer block + 多尺度融合
统一语义分割、实力分割、全景分割的模型
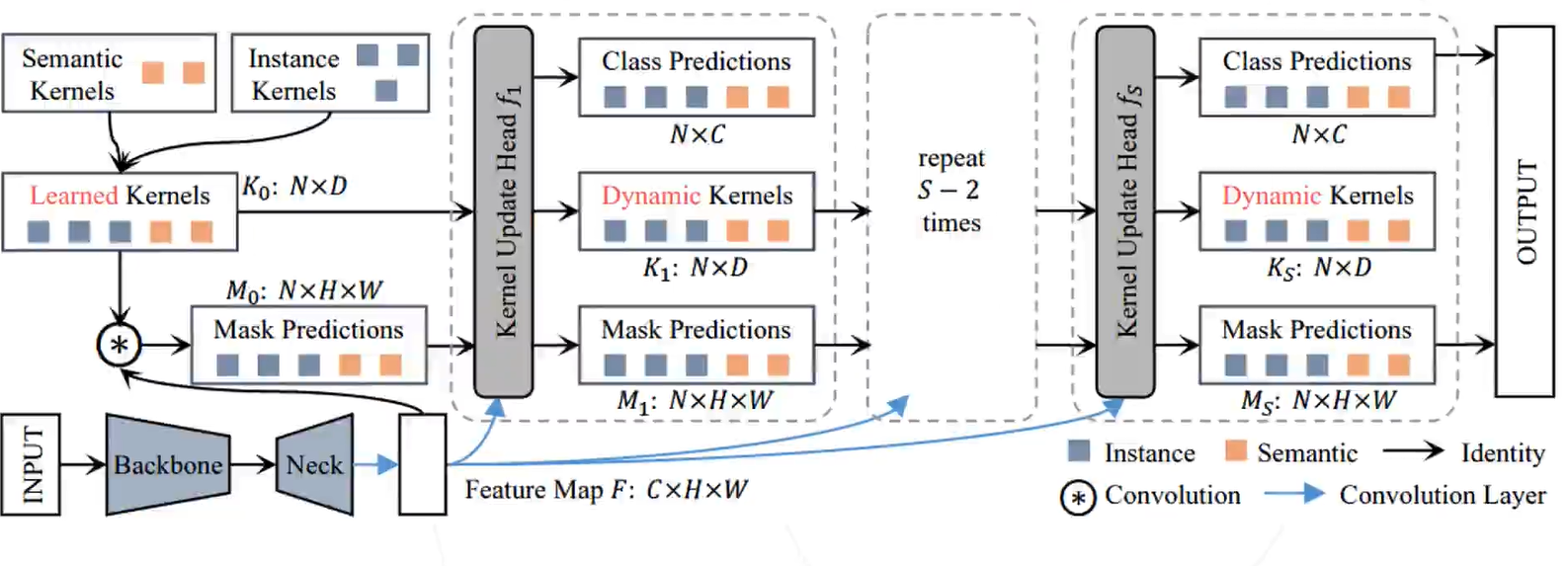
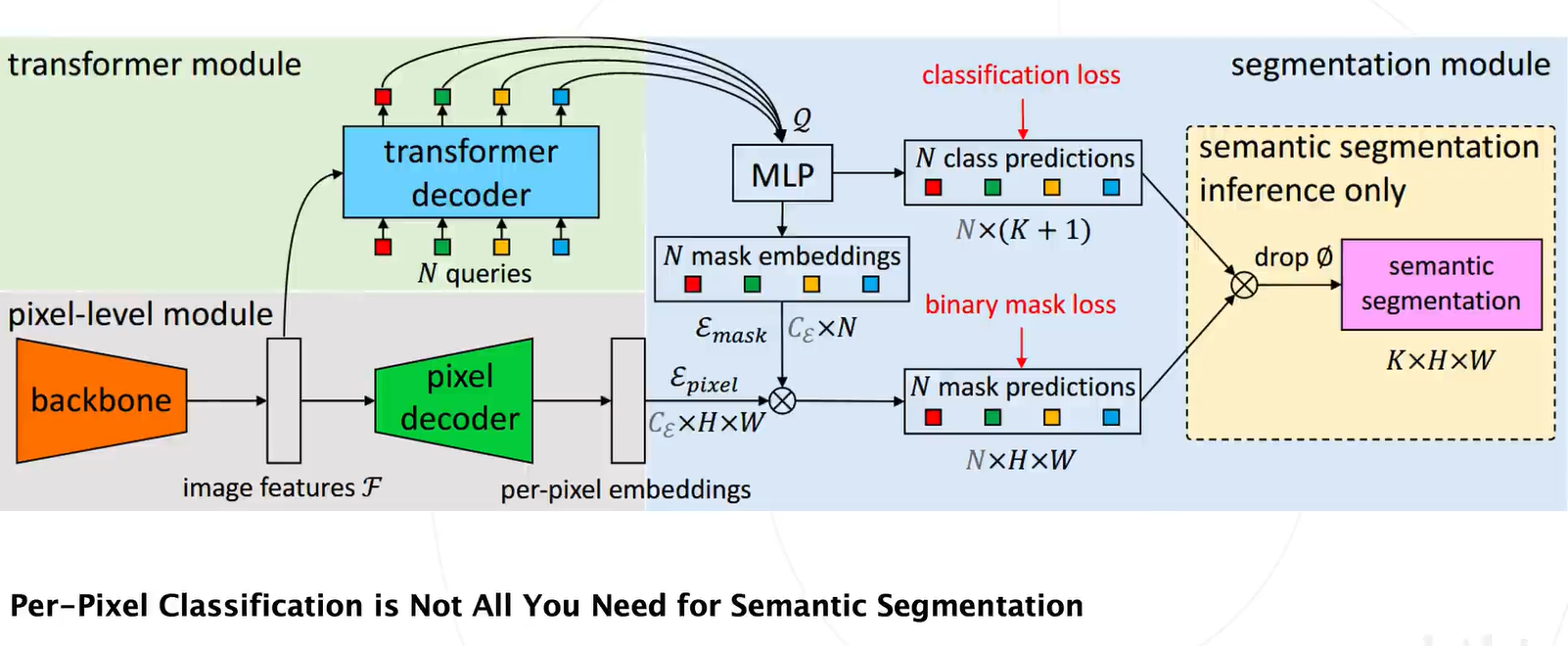
作者提出实例级别的分类就足够了,并不用逐像素分类
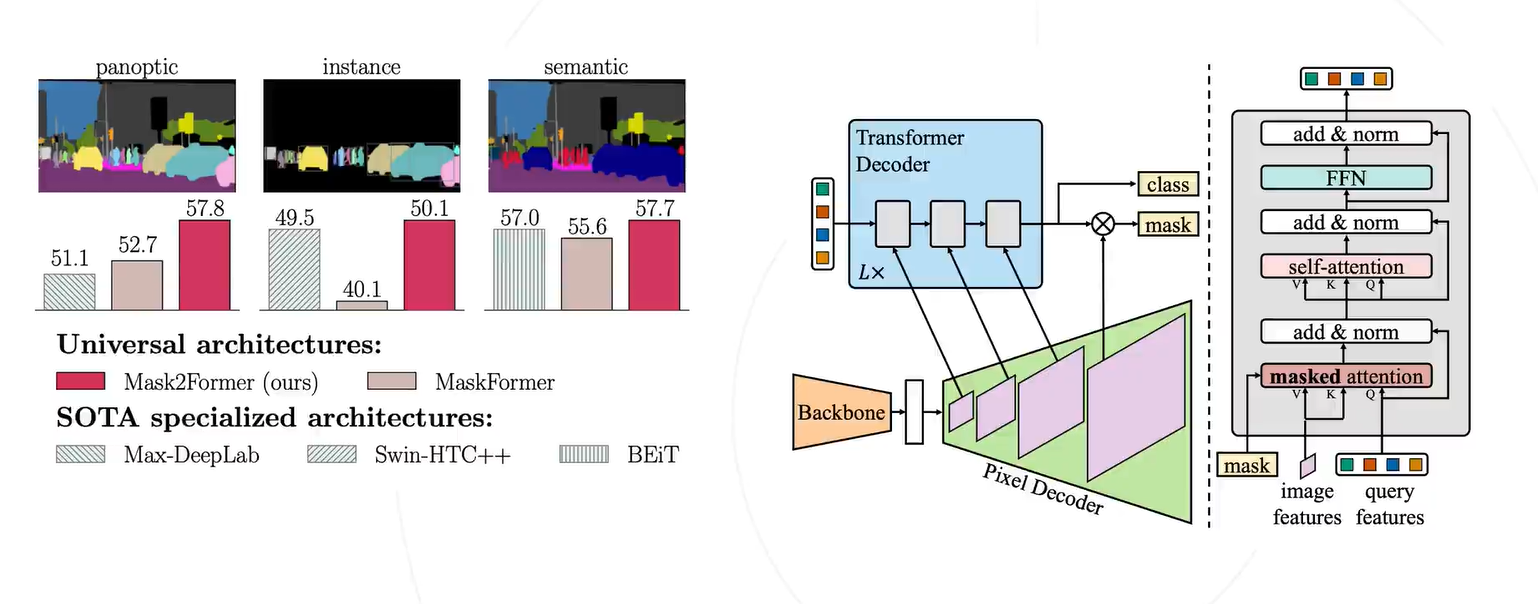
在 Transformer 块中用到了交叉注意力机制,作者这边说是 mask attention
这是一种视觉大模型,任意一张图片都可以分割,并且这种分割是带语义的。
个人觉得语义分割是最底层的任务,因为它已经是深入到对像素的分类,有个小疑惑,不知道类似矢量图那种图片有没有办法做分割?分割的图片如果不是RGB的可以做吗?其他颜色空间的图片是否有支持的模型?


