


162
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享import pandas as pd
# 定义Series对象
data = pd.Series([10, 20, 30, 40, 50], index=['a', 'b', 'c', 'd', 'e'])
# 访问Series对象中的数据
print(data['a'])
print(data['c':'d'])
# 修改Series对象中的数据
data['b'] = 25
# 打印Series对象
print(data)
# 对Series对象进行计算
print("和:", data.sum())
print("平均值:", data.mean())
index参数定义了Series对象的索引,可以使用索引名称或位置访问和修改数据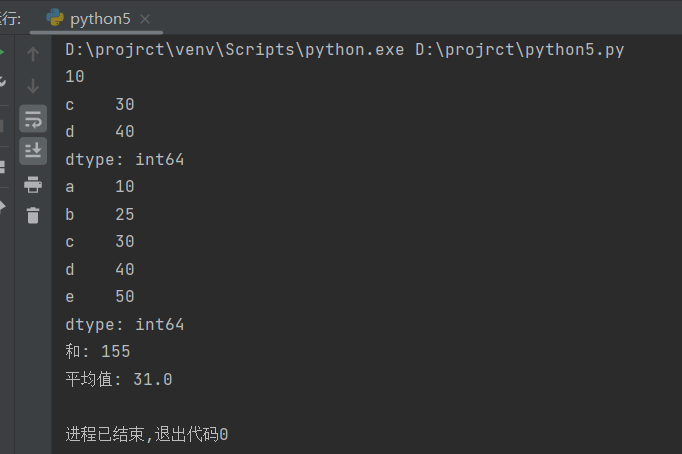
import pandas as pd
# 定义DataFrame对象
data = pd.DataFrame({'整数': [1, 2, 3, 4, 5], '浮点数': [1.2, 2.3, 3.4, 4.5, 5.6], '字符串': ['a', 'b', 'c', 'd', 'e']}, index=['r1', 'r2', 'r3', 'r4', 'r5'])
# 访问DataFrame对象中的数据
print(data.iloc[2, 1])
# 修改DataFrame对象中的数据
data.iat[2, 1] = 10.5
# 打印DataFrame对象
print(data)
# 对DataFrame对象进行计算
print("和:", data.sum())
print("平均值:", data.mean())
index参数定义了DataFrame对象的行索引,bing1使用.iloc[]方法和行/列位置访问和修改数据。我们还可以使用.iat[]方法来访问和修改单个值。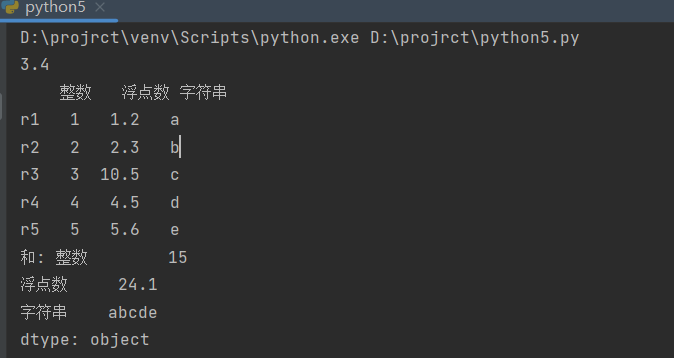
import pandas as pd
import matplotlib.pyplot as plt
# 定义DataFrame对象
data = pd.DataFrame({
'城市名称': ['北京', '上海', '广州', '深圳',],
'人口': [2171, 2424, 1500, 1303],
'GDP': [330320, 32679, 20353, 22458],
'城市面积': [16410, 6340, 7434, 1996]
})
# 计算人口最多的城市
pop_rank = data.sort_values(by='人口', ascending=False)
print('人口最多的城市:', pop_rank.iloc[0]['城市名称'])
# 计算GDP最高的城市
gdp_rank = data.sort_values(by='GDP', ascending=False)
print('GDP最高的城市:', gdp_rank.iloc[0]['城市名称'])
# 计算人口密度排名
data['人口密度'] = data['人口'] / data['城市面积']
density_rank = data.sort_values(by='人口密度', ascending=False)
print('人口密度排名:', density_rank['城市名称'].values)
# 使用Pandas绘图
fig, axs = plt.subplots(2, 2, figsize=(12, 8))
data.plot(kind='bar', x='城市名称', y='人口', ax=axs[0][0])
axs[0][0].set_title('城市人口')
data.plot(kind='bar', x='城市名称', y='GDP', ax=axs[0][1])
axs[0][1].set_title('城市GDP')
data.plot(kind='bar', x='城市名称', y='城市面积', ax=axs[1][0])
axs[1][0].set_title('城市面积')
data.plot(kind='bar', x='城市名称', y='人口密度', ax=axs[1][1])
axs[1][1].set_title('城市人口密度')
plt.tight_layout()
plt.show()
plot()方法是一种更简单的方法来对DataFrame对象进行可视化,但可能会对绘图的样式和布局有所限制。
我的结论:Pandas能够很好地处理多列数据,并支持数据透视表的应用,可以方便地对数据进行汇总、分组和分析。

