视频地址
底层视觉与MMEditing
- 1. 图像超分辨率 Super Resolution
- 1.1 经典方法:稀疏编码
- 1.2 基于卷积网络SRCNN和FSRCNN
- 1.2.1 SRCNN
- 1.2.2 FSRCNN
- 1.2.3 SRResnet
- 1.3 损失函数与模型评估
- 逐像素计算的损失函数:MSE 均方误差
- 感知损失函数:特征重构损失函数
- 1.4 对抗生成网络GAN简介
- 1.5 基于GAN的模型SRGAN与ESRGAN
- 1.5.1 SRGAN
- 1.5.2 ESRGAN
- 1.5.3 改进方案:
- 1.6 视频超分辨率介绍
- 1.6.1 EDVR
1. 图像超分辨率 Super Resolution
图像超分辨率的目标:
- 提高图像的分辨率
- 高分图像符合低分图像的内容
- 恢复图像的细节,增加真实的内容
以往未使用AI技术时通过双线性插值来提高图像的分辨率
但是双线插值只能简单地提高分辨率并不能生成真实的内容
图像超分辨率的应用:
- 经典游戏的高清重制
- 老旧照片修复
- 老动画高清重制
- 节约传输高清图像的带宽(服务器存储低分辨率图像,到用户设备时通过超- 分辨率任务还原回高清图像,google就是这样做的)
- 民生领域:医疗影相,卫星影相等等
图像超分的解决思路:
- (1)基于已知数据学习高低分辨率图像之间的关系:先验知识
- (2)在先验知识的约束下,恢复高清图像
1.1 经典方法:稀疏编码
通过无监督学习从图像中获取一组图像基块,使得图像中任意一个区域可以由数个基块图像线性组合而成
训练过程中通过低分辨率的学习高分辨率的稀疏矩阵
推理过程中通过低分辨率转化为高分辨率的基块图像,然后再组成高分辨率的图像
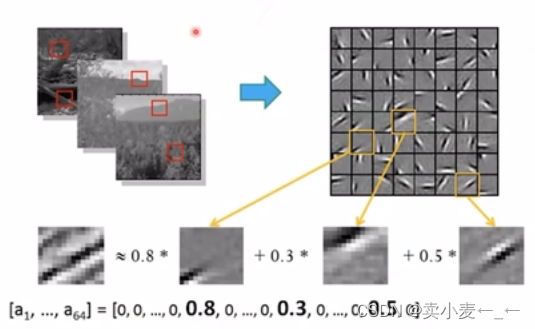
缺点:即便已经学习出稀疏矩阵,对低分辨率和高分辨率的权重和系数的学习以然难以收敛,训练和推理都十分耗时
1.2 基于卷积网络SRCNN和FSRCNN
1.2.1 SRCNN
SRCNN先对低分辨率的图像进行双线性插值使其大小和高分辨率一致,再输入到卷积网络
SRCNN单个卷积层的物理意义:
- 提取图像块的低层次特征
- 对低层次特征进行非线性转换未高层特征
- 组合邻域的高层次特征,恢复高清图像
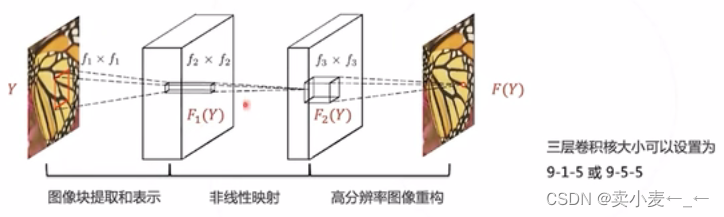
缺点:由于进行插值时不产生额外的信息,因此产生了一定的冗余计算,所以SRCNN的速度非常慢,达不到实时的标准1.2.2 FSRCNN
在SRCNN的基础上做了改进 - 不使用双线性插值放大图像,而是改用转置卷积
- 使用1x1的卷积核对特征通道进行压缩,降低卷积的运算量
- 若干卷积层后通过转置卷积提高图像的分辨率
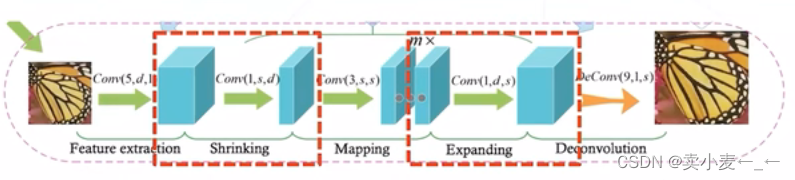
优点:
(1)仅用CPU便可达到实时推理的标准
(2)训练方便,处理不同的上采样倍数时,只需微调转置卷积的权重即可
缺点:
其实是转置卷积的缺点,当卷积核的size和步长stride不等时,便会在不同的位置叠加不同次数的合成,造成不均匀的重叠现象,称为棋盘格效应
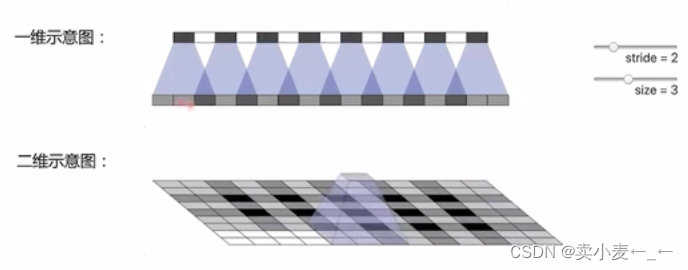
有两种方法可以处理
(1)先对特征图进行最近邻插值或者线性插值等上采样操作,放大特征图,在进行卷积,缩小到原来的输出尺寸
(2)次像素卷积提供了另一种上采样方案,先将原图卷积成 rxr 通道的特征图,再把每个位置的所有通道的特征图摊平成rxr面积的图像,这样便把原图放大r倍
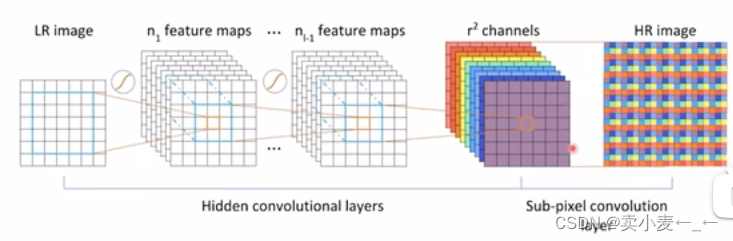
1.2.3 SRResnet
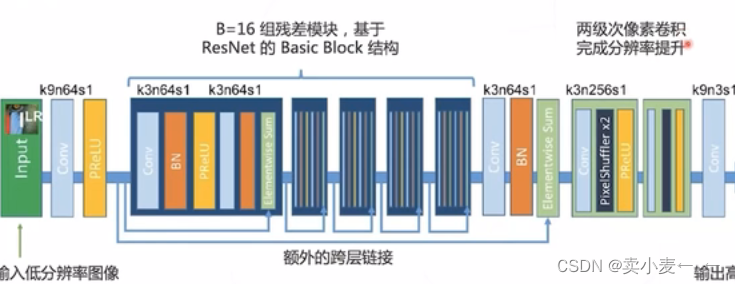
随着残差网络的发布,一些旧的模型也得到升级
将原来SRCNN的主干网络替换成残差模块便是SRResnet
1.3 损失函数与模型评估
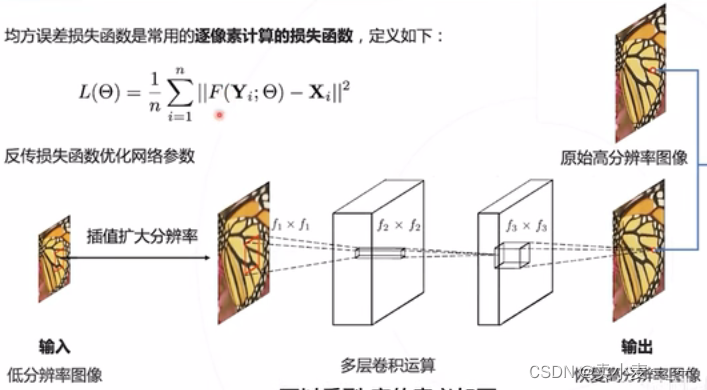
逐像素计算的损失函数:MSE 均方误差
MSE(Mean Square Error)逐像素计算恢复图像和原高分图像的平方误差
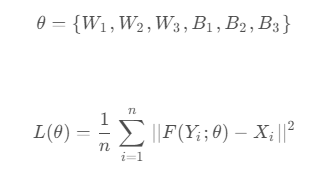
最小化算是函数即可鼓励网络完美恢复高分辨率图像
感知损失函数:特征重构损失函数
比较恢复图像与原始高分图像的语义特征,并计算损失
常见的做法是用一个在imagenet上训练好的vgg网络去获取恢复图像和原始高分图像的特征,然后计算损失
减少特征重构损失:输出图像在感知上与目标图像相匹配,不要求两者完全一致
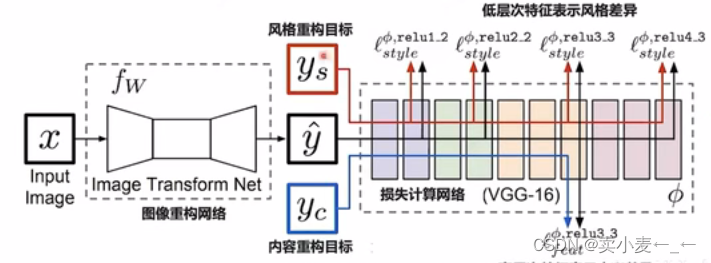
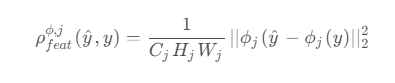
模型评估:PSNR
峰值信噪比(Peak signal-to-noise ratio,PSNR)为最大信号能量与平均噪声能量的比值,值越大恢复效果越好
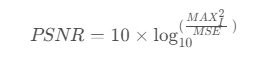
1.4 对抗生成网络GAN简介
之前介绍的都是监督学习,学习数据对之前的关系
而gan是一种无监督学习,学习的是数据结构的概率分布
应用:
(1)gan生成逼真人脸

(2)使用gan转译图像

(3)使用gan进行超分辨率任务

gan网络的原理是通过数据集训练出一个符合训练数据结构的概率分布G
然后通过任意的输入z从概率分布G上采集数据
在训练时,在引入一个判别网络来判断生成数据的真假
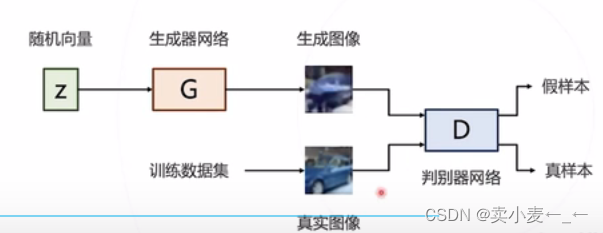
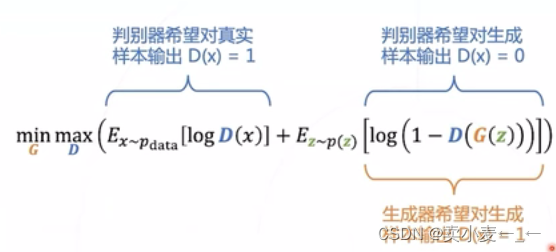
gan的优化:
生成器希望样本输出都是真的
判别器则是希望生成器的输出都是假的,训练的样本都是真的
1.5 基于GAN的模型SRGAN与ESRGAN
前面介绍的SRCNN产生的图像过于平滑,而gan则是能生成细节更为丰富,更为真实的高清图像
1.5.1 SRGAN
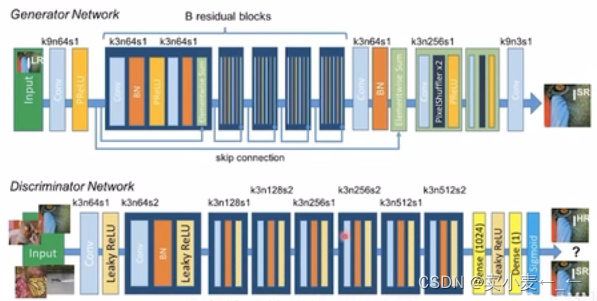
在SRResnet的基础上改成gan的结构,便是SRGAN
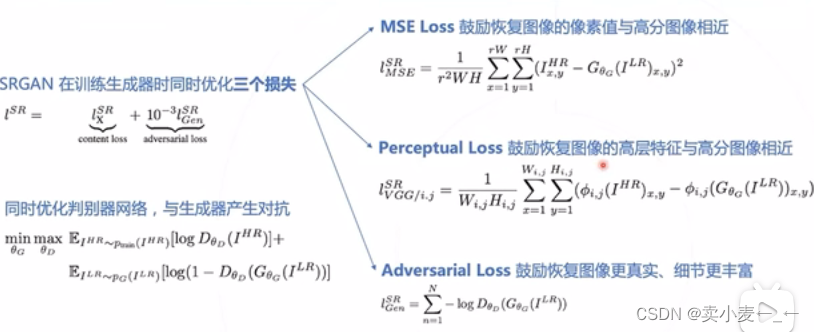
SRGAN在训练时,同时优化三个损失
- MSE Loss 鼓励恢复图像的像素值与高分图像相近
- Perceptual Loss 鼓励恢复图像的高层特征与高分图像相近
- Adversarial Loss 鼓励恢复图像更真实,细节更丰富
1.5.2 ESRGAN
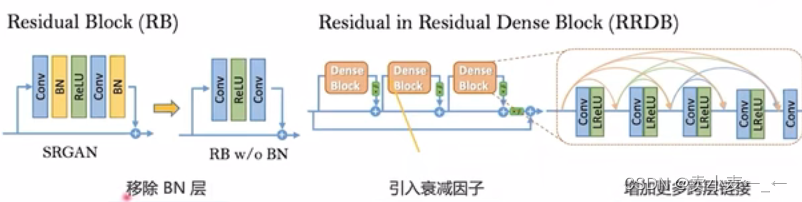
使用RRDB替换原来时残差模块(RB)
因为RB的BN层在超分辨网络中会产生一些负面效果
引入三个dense block,block之间用一个衰减因子β链接,使得三个模块的输出都乘以β在输出到下一层
1.5.3 改进方案:
(1)使用Ragan结构替换gan结构
ragan的判别器会判断真是图像是否比生成图像更真实,生成图像是否比真是图像更虚假
(2)使用非线性激活前的响应计算感知损失
- 激活后的响应值更稀疏,削弱监督信号的强度
- 使用激活后的响应会使得恢复图像在亮度上产生偏移
1.6 视频超分辨率介绍
视频复原的经典流程
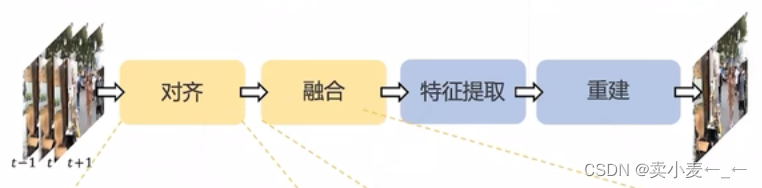
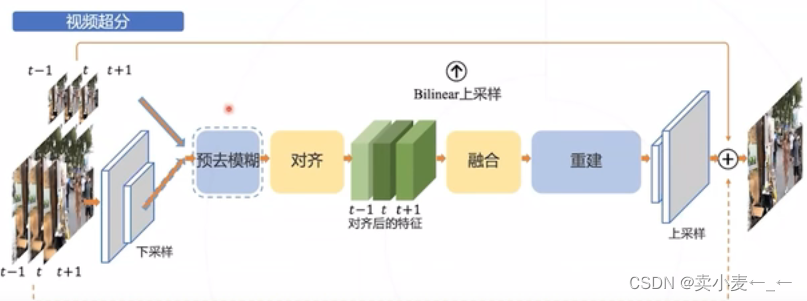
1.6.1 EDVR
将一帧图像和前后各一帧的图像以及,经过下采样的真实图像一起送入网络
先进行图像去模糊
利用光流进行图像对齐
然后送卷积网络中提取特征
对两个图像的特征值做特征融合
在进行重建
最后进行上采样获得该帧的高清的图像
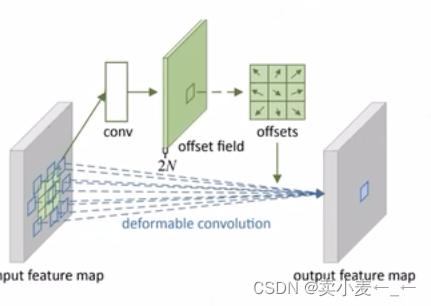
可变形卷积
该卷积核中具备增加的偏移量,使得采样位置能够灵活变化
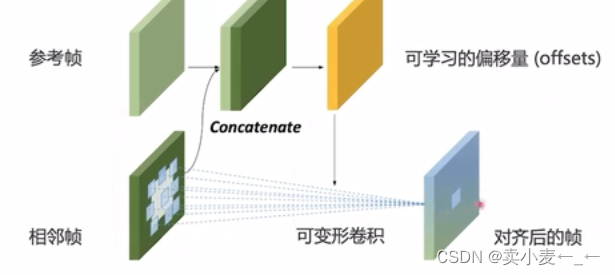
将参考帧与相邻帧拼在一起在送入卷积网络中得到这一帧的可学习的偏移量,再将偏移量送入可变形卷积网络中对相邻帧进行卷积,便可获得对齐后的帧



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


