


535
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享视频来源:MMSegmentation代码课
终端命令行下载最新源码:git clone https://github.com/open-mmlab/mmsegmentation.git -b dev-1.x
终端命令行进入目录:cd mmsegmetation
终端命令行安装 MMSegmentation:pip install -v -e .
##检查和测试
# 检查 mmsegmentation
#没有报错,即证明安装成功。
import mmseg
from mmseg.utils import register_all_modules
from mmseg.apis import inference_model, init_model
print('mmsegmentation版本', mmseg.__version__)
在mmsegmetation目录下创建三个子目录:
下载素材至data目录——
上海驾车街景视频,视频来源:https://www.youtube.com/watch?v=ll8TgCZ0plk

命令行转到mmsegmentation目录下,在命令行中键入下述命令,opacity是可视化透明度
python demo/image_demo.py data/street_uk.jpeg configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py checkpoint/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth --out-file outputs/B1_uk_pspnet.jpg --device cuda:0 --opacity 0.5

python demo/image_demo.py data/street_uk.jpeg configs/segformer/segformer_mit-b5_8xb1-160k_cityscapes-1024x1024.py checkpoint/segformer_mit-b5_8x1_1024x1024_160k_cityscapes_20211206_072934-87a052ec.pth --out-file outputs/B1_uk_segformer.jpg --device cuda:0 --opacity 0.5

python demo/image_demo.py data/street_uk.jpeg configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py checkpoint/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024_20221202_141901-28ad20f1.pth --out-file outputs/B1_uk_Mask2Former.jpg --device cuda:0 --opacity 0.5

python demo/image_demo.py data/street_uk.jpeg configs/segformer/segformer_mit-b5_8xb2-160k_ade20k-640x640.py checkpoint/segformer_mit-b5_640x640_160k_ade20k_20220617_203542-940a6bd8.pth --out-file outputs/B1_Segformer_ade20k.jpg --device cuda:0 --opacity 0.5

命令行转到mmsegmentation目录下,在命令行中键入下述命令,opacity是可视化透明度
python demo/video_demo.py data/street_20220330_174028.mp4 configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py checkpoint/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024_20221202_141901-28ad20f1.pth --device cuda:0 --output-file outputs/B3_video.mp4 --opacity 0.5
基于Cityscapes 街景数据集预训练mask2former模型
# -*- coding = utf-8 -*-
# @Time : 2023/6/17 13:17
# @Author : Happiness
# @Software : PyCharm
####导入工具包
import os
import numpy as np
import time
import shutil
import torch
from PIL import Image
import cv2
import mmcv
import mmengine
from mmseg.apis import inference_model
from mmseg.utils import register_all_modules
register_all_modules()
from mmseg.datasets import CityscapesDataset
####载入模型
# 模型 config 配置文件
config_file = 'configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py'
# 模型 checkpoint 权重文件
checkpoint_file = 'checkpoint/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024_20221202_141901-28ad20f1.pth'
from mmseg.apis import init_model
model = init_model(config_file, checkpoint_file, device='cuda:0')
from mmengine.model.utils import revert_sync_batchnorm
if not torch.cuda.is_available():
model = revert_sync_batchnorm(model)
#### 输入视频路径
input_video = 'data/traffic.mp4'
#input_video = 'data/street_20220330_174028.mp4'
#创建临时文件夹,存放每帧结果
temp_out_dir = time.strftime('%Y%m%d%H%M%S')
os.mkdir(temp_out_dir)
print('创建临时文件夹 {} 用于存放每帧预测结果'.format(temp_out_dir))
#####视频单帧预测
# 获取 Cityscapes 街景数据集 类别名和调色板
from mmseg.datasets import cityscapes
classes = cityscapes.CityscapesDataset.METAINFO['classes']
palette = cityscapes.CityscapesDataset.METAINFO['palette']
def pridict_single_frame(img, opacity=0.2):
result = inference_model(model, img)
# 将分割图按调色板染色
seg_map = np.array(result.pred_sem_seg.data[0].detach().cpu().numpy()).astype('uint8')
seg_img = Image.fromarray(seg_map).convert('P')
seg_img.putpalette(np.array(palette, dtype=np.uint8))
show_img = (np.array(seg_img.convert('RGB'))) * (1 - opacity) + img * opacity
return show_img
##### 视频逐帧预测.
# 读入待预测视频
imgs = mmcv.VideoReader(input_video)
prog_bar = mmengine.ProgressBar(len(imgs))
# 对视频逐帧处理
for frame_id, img in enumerate(imgs):
## 处理单帧画面
show_img = pridict_single_frame(img, opacity=0.15)
temp_path = f'{temp_out_dir}/{frame_id:06d}.jpg' # 保存语义分割预测结果图像至临时文件夹
cv2.imwrite(temp_path, show_img)
prog_bar.update() # 更新进度条
# 把每一帧串成视频文件
#mmcv.frames2video(temp_out_dir, 'outputs/B3_video.mp4', fps=imgs.fps, fourcc='mp4v')
mmcv.frames2video(temp_out_dir, 'outputs/B4_video.mp4', fps=imgs.fps, fourcc='mp4v')
shutil.rmtree(temp_out_dir) # 删除存放每帧画面的临时文件夹
print('删除临时文件夹', temp_out_dir)
数据集
解压到数据集data目录下
数据集配置文件
保存路径为/mmsegmentation/mmseg/datasets/StanfordBackgroundDataset.py
如果操作了这一步,下一小节配置文件第一步就不用复制了
修改 ../mmsegmentation/mmseg/datasets/init.py,添加数据集
保存路径维/mmsegmentation/mmseg/datasets/init.py会替换掉原有文件
# -*- coding = utf-8 -*-
# @Time : 2023/6/17 17:57
# @Author : Happiness
# @File : split.py
# @Software : PyCharm
####导入工具包
import os
import random
#获取全部数据文件名列表
PATH_IMAGE = 'D:/0.dive into pytorch/openmmlab/mmsegmentation/data/Glomeruli-dataset/images'
all_file_list = os.listdir(PATH_IMAGE)
all_file_num = len(all_file_list)
random.shuffle(all_file_list) # 随机打乱全部数据文件名列表
###指定训练集和测试集比例
train_ratio = 0.8
test_ratio = 1 - train_ratio
train_file_list = all_file_list[:int(all_file_num*train_ratio)]
test_file_list = all_file_list[int(all_file_num*train_ratio):]
print('数据集图像总数', all_file_num)
print('训练集划分比例', train_ratio)
print('训练集图像个数', len(train_file_list))
print('测试集图像个数', len(test_file_list))
train_file_list[:5]
['SAS_21883_001_35.png',
'VUHSK_1352_59.png',
'SAS_21908_001_60.png',
'SESCAM_9_0_25.png',
'SAS_21896_001_26.png']
test_file_list[:5]
['VUHSK_1272_101.png',
'SAS_21937_001_117.png',
'VUHSK_1502_11.png',
'SAS_21904_001_3.png',
'VUHSK_1502_8.png']
###生成两个txt划分文件
with open('D:/0.dive into pytorch/openmmlab/mmsegmentation/data/Glomeruli-dataset/splits/train.txt', 'w') as f:
f.writelines(line.split('.')[0] + '\n' for line in train_file_list)
with open('D:/0.dive into pytorch/openmmlab/mmsegmentation/data/Glomeruli-dataset/splits/val.txt', 'w') as f:
f.writelines(line.split('.')[0] + '\n' for line in test_file_list)
如果操作了上一节StanfordBackgroundDataset文件的下载,下一步就不用复制了,直接代码块
将下面这段代码原封不动复制到文件\mmsegmentation\mmseg\datasets\basesegdataset.py
@DATASETS.register_module()
class StanfordBackgroundDataset(BaseSegDataset):
METAINFO = dict(classes = ('background', 'glomeruili'), palette = [[128, 128, 128], [151, 189, 8]])
def init(self, **kwargs):
super().init(img_suffix='.png', seg_map_suffix='.png', **kwargs)
# -*- coding = utf-8 -*-
# @Time : 2023/6/17 18:25
# @Author : Happiness
# @File : newconfig.py
# @Software : PyCharm
######导入工具包
import numpy as np
from PIL import Image
import os.path as osp
from tqdm import tqdm
import mmcv
import mmengine
import matplotlib.pyplot as plt
# 数据集图片和标注路径
data_root = 'D:/0.dive into pytorch/openmmlab/mmsegmentation/data/Glomeruli-dataset'
img_dir = 'images'
ann_dir = 'masks'
# 类别和对应的颜色
classes = ('background', 'glomeruili')
palette = [[128, 128, 128], [151, 189, 8]]
####修改数据集类(指定图像扩展名)
#After downloading the data, we need to implement load_annotations function in the new dataset class StanfordBackgroundDataset.
from mmseg.registry import DATASETS
from mmseg.datasets import BaseSegDataset
# @DATASETS.register_module()
# class StanfordBackgroundDataset(BaseSegDataset):
# METAINFO = dict(classes = classes, palette = palette)
# def __init__(self, **kwargs):
# super().__init__(img_suffix='.png', seg_map_suffix='.png', **kwargs)
#文档:https://github.com/open-mmlab/mmsegmentation/blob/master/docs/en/tutorials/customize_datasets.md#customize-datasets-by-reorganizing-data
####修改config配置文件
# 下载 config 文件 和 预训练模型checkpoint权重文件
from mmengine import Config
cfg = Config.fromfile('D:/0.dive into pytorch/openmmlab/mmsegmentation/configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py')
cfg.norm_cfg = dict(type='BN', requires_grad=True) # 只使用GPU时,BN取代SyncBN
cfg.crop_size = (256, 256)
cfg.model.data_preprocessor.size = cfg.crop_size
cfg.model.backbone.norm_cfg = cfg.norm_cfg
cfg.model.decode_head.norm_cfg = cfg.norm_cfg
cfg.model.auxiliary_head.norm_cfg = cfg.norm_cfg
# modify num classes of the model in decode/auxiliary head
cfg.model.decode_head.num_classes = 2
cfg.model.auxiliary_head.num_classes = 2
# 修改数据集的 type 和 root
cfg.dataset_type = 'StanfordBackgroundDataset'
cfg.data_root = data_root
cfg.train_dataloader.batch_size = 8
cfg.train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='RandomResize', scale=(320, 240), ratio_range=(0.5, 2.0), keep_ratio=True),
dict(type='RandomCrop', crop_size=cfg.crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PackSegInputs')
]
cfg.test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', scale=(320, 240), keep_ratio=True),
# add loading annotation after ``Resize`` because ground truth
# does not need to do resize data transform
dict(type='LoadAnnotations'),
dict(type='PackSegInputs')
]
###3修改成绝对路径
cfg.train_dataloader.dataset.data_root='D:/0.dive into pytorch/openmmlab/mmsegmentation/data/Glomeruli-dataset/'
cfg.val_dataloader.dataset.data_root='D:/0.dive into pytorch/openmmlab/mmsegmentation/data/Glomeruli-dataset/'
cfg.test_dataloader.dataset.data_root='D:/0.dive into pytorch/openmmlab/mmsegmentation/data/Glomeruli-dataset/'
cfg.train_dataloader.dataset.type = cfg.dataset_type
cfg.train_dataloader.dataset.data_root = cfg.data_root
cfg.train_dataloader.dataset.data_prefix = dict(img_path=img_dir, seg_map_path=ann_dir)
cfg.train_dataloader.dataset.pipeline = cfg.train_pipeline
cfg.train_dataloader.dataset.ann_file = 'splits/train.txt'
cfg.val_dataloader.dataset.type = cfg.dataset_type
cfg.val_dataloader.dataset.data_root = cfg.data_root
cfg.val_dataloader.dataset.data_prefix = dict(img_path=img_dir, seg_map_path=ann_dir)
cfg.val_dataloader.dataset.pipeline = cfg.test_pipeline
cfg.val_dataloader.dataset.ann_file = 'splits/val.txt'
cfg.test_dataloader = cfg.val_dataloader
# 载入预训练模型权重
cfg.load_from = 'D:/0.dive into pytorch/openmmlab/mmsegmentation/checkpoint/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
# 工作目录
cfg.work_dir = './work_dirs/tutorial'
# 训练迭代次数
cfg.train_cfg.max_iters = 800
# 评估模型间隔
cfg.train_cfg.val_interval = 400
# 日志记录间隔
cfg.default_hooks.logger.interval = 100
# 模型权重保存间隔
cfg.default_hooks.checkpoint.interval = 400
# 随机数种子
cfg['randomness'] = dict(seed=0)
####保存config配置文件
cfg.dump('Glomeruli_pspnet_cityscapes.py')
# -*- coding = utf-8 -*-
# @Time : 2023/6/18 12:27
# @Author : Happiness
# @File : train.py
# @Software : PyCharm
####载入config配置文件
from mmengine import Config
cfg = Config.fromfile('Glomeruli_pspnet_cityscapes.py')
####准备训练
from mmengine.runner import Runner
from mmseg.utils import register_all_modules
# register all modules in mmseg into the registries
# do not init the default scope here because it will be init in the runner
register_all_modules(init_default_scope=False)
runner = Runner.from_cfg(cfg)
###开始训练
if __name__=='__main__':#不加这个会报错,多线程错误
runner.train()
终端命令行先转到当前项目文件Glomeruli下
测试集精度指标
python ../../tools/test.py Glomeruli_pspnet_cityscapes.py ./work_dirs/tutorial/iter_800.pth

测试集速度指标
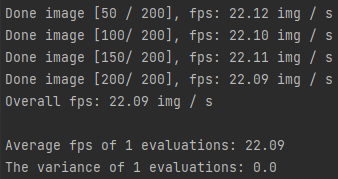
python ../../tools/analysis_tools/benchmark.py Glomeruli_pspnet_cityscapes.py ./work_dirs/tutorial/iter_800.pth
# -*- coding = utf-8 -*-
# @Time : 2023/6/18 16:29
# @Author : Happiness
# @File : tuili.py
# @Software : PyCharm
#####用训练得到的模型预测
####3导入工具包
import numpy as np
import matplotlib.pyplot as plt
from mmseg.apis import init_model, inference_model, show_result_pyplot
import mmcv
import cv2
####载入模型
# 载入 config 配置文件
from mmengine import Config
cfg = Config.fromfile('Glomeruli_pspnet_cityscapes.py')
from mmengine.runner import Runner
from mmseg.utils import register_all_modules
# register all modules in mmseg into the registries
# do not init the default scope here because it will be init in the runner
register_all_modules(init_default_scope=False)
runner = Runner.from_cfg(cfg)
# 初始化模型
checkpoint_path = './work_dirs/tutorial/iter_800.pth'
model = init_model(cfg, checkpoint_path, 'cuda:0')
####载入测试集图像,或新图像
img = mmcv.imread('D:/0.dive into pytorch/openmmlab/mmsegmentation/data/Glomeruli-dataset/images/SAS_21883_001_6.png')
####语义分割预测
result = inference_model(model, img)
result.keys()
['seg_logits', 'pred_sem_seg']
pred_mask = result.pred_sem_seg.data[0].cpu().numpy()
#####可视化语义分割预测结果
plt.imshow(pred_mask)
plt.show()
# 可视化预测结果
visualization = show_result_pyplot(model, img, result, opacity=0.7, out_file='pred.jpg')
plt.imshow(mmcv.bgr2rgb(visualization))
plt.show()
###语义分割预测结果-连通域分析
plt.imshow(np.uint8(pred_mask))
plt.show()
connected = cv2.connectedComponentsWithStats(np.uint8(pred_mask), connectivity=4)
plt.imshow(connected[1])
plt.show()
####3获取测试集标注
label = mmcv.imread('Glomeruli-dataset/masks/VUHSK_1702_39.png')
label_mask = label[:,:,0]
plt.imshow(label_mask)
plt.show()
####对比测试集标注和语义分割预测结果
# 真实为前景,预测为前景
TP = (label_mask == 1) & (pred_mask==1)
# 真实为背景,预测为背景
TN = (label_mask == 0) & (pred_mask==0)
# 真实为前景,预测为背景
FN = (label_mask == 1) & (pred_mask==0)
# 真实为背景,预测为前景
FP = (label_mask == 0) & (pred_mask==1)
plt.imshow(TP)
plt.show()
confusion_map = TP * 255 + FP * 150 + FN * 80 + TN * 10
plt.imshow(confusion_map)
plt.show()
####混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix_model = confusion_matrix(label_map.flatten(), pred_mask.flatten())
import itertools
def cnf_matrix_plotter(cm, classes, cmap=plt.cm.Blues):
"""
传入混淆矩阵和标签名称列表,绘制混淆矩阵
"""
plt.figure(figsize=(10, 10))
plt.imshow(cm, interpolation='nearest', cmap=cmap)
# plt.colorbar() # 色条
tick_marks = np.arange(len(classes))
plt.title('Confusion Matrix', fontsize=30)
plt.xlabel('Pred', fontsize=25, c='r')
plt.ylabel('True', fontsize=25, c='r')
plt.tick_params(labelsize=16) # 设置类别文字大小
plt.xticks(tick_marks, classes, rotation=90) # 横轴文字旋转
plt.yticks(tick_marks, classes)
# 写数字
threshold = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > threshold else "black",
fontsize=12)
plt.tight_layout()
plt.savefig('混淆矩阵.pdf', dpi=300) # 保存图像
plt.show()
classes = ('background', 'glomeruili')
cnf_matrix_plotter(confusion_matrix_model, classes, cmap='Blues')
命令行进入到mmsegmentation目录下:cd mmsegmentation
定义数据集类(各类别名称及配色)
定义数据集类(各类别名称及配色)存放在mmseg/datasets/DubaiDataset.py目录中
注册数据集类
注册数据集类存放在mmseg/datasets/init.py目录下(会替代掉原有文件)
定义训练及测试pipeline
定义训练及测试pipeline存放在configs/base/datasets/DubaiDataset_pipeline.py目录下
保存 下载模型config配置文件的路径“configs/pspnet/pspnet_r50-d8_4xb2-40k_DubaiDataset.py”
# -*- coding = utf-8 -*-
# @Time : 2023/6/17 23:24
# @Author : Happiness
# @File : newconfig.py
# @Software : PyCharm
#####导入工具包
import numpy as np
from PIL import Image
import os.path as osp
from tqdm import tqdm
import mmcv
import mmengine
import matplotlib.pyplot as plt
####载入config配置文件
from mmengine import Config
cfg = Config.fromfile('../../configs/pspnet/pspnet_r50-d8_4xb2-40k_DubaiDataset.py')
#####修改config配置文件
cfg.norm_cfg = dict(type='BN', requires_grad=True) # 只使用GPU时,BN取代SyncBN
cfg.crop_size = (256, 256)
cfg.model.data_preprocessor.size = cfg.crop_size
cfg.model.backbone.norm_cfg = cfg.norm_cfg
cfg.model.decode_head.norm_cfg = cfg.norm_cfg
cfg.model.auxiliary_head.norm_cfg = cfg.norm_cfg
# modify num classes of the model in decode/auxiliary head
# 模型 decode/auxiliary 输出头,指定为类别个数
cfg.model.decode_head.num_classes = 6
cfg.model.auxiliary_head.num_classes = 6
cfg.train_dataloader.batch_size = 8
cfg.train_dataloader.dataset.data_root='D:/0.dive into pytorch/openmmlab/mmsegmentation/data/Dubai-dataset/'####换成你自己的绝对路径
cfg.val_dataloader.dataset.data_root='D:/0.dive into pytorch/openmmlab/mmsegmentation/data/Dubai-dataset/'####换成你自己的绝对路径
cfg.test_dataloader.dataset.data_root='D:/0.dive into pytorch/openmmlab/mmsegmentation/data/Dubai-dataset/'####换成你自己的绝对路径
cfg.test_dataloader = cfg.val_dataloader
# 结果保存目录
cfg.work_dir = './work_dirs/DubaiDataset'
# 训练迭代次数
cfg.train_cfg.max_iters = 3000
# 评估模型间隔
cfg.train_cfg.val_interval = 400
# 日志记录间隔
cfg.default_hooks.logger.interval = 100
# 模型权重保存间隔
cfg.default_hooks.checkpoint.interval = 1500
# 随机数种子
cfg['randomness'] = dict(seed=0)
####查看完整config配置文件
# print(cfg.pretty_text)
#3####保存config配置文件
cfg.dump('pspnet-DubaiDataset.py')
记得换路径
# -*- coding = utf-8 -*-
# @Time : 2023/6/17 23:42
# @Author : Happiness
# @File : train.py
# @Software : PyCharm
####导入工具包
import numpy as np
import os.path as osp
from tqdm import tqdm
import mmcv
import mmengine
####载入config配置文件
from mmengine import Config
cfg = Config.fromfile('pspnet-DubaiDataset.py')
####准备训练
from mmengine.runner import Runner
from mmseg.utils import register_all_modules
# register all modules in mmseg into the registries
# do not init the default scope here because it will be init in the runner
register_all_modules(init_default_scope=False)
runner = Runner.from_cfg(cfg)
###开始训练
if __name__=='__main__':
runner.train()
终端cmd跳转到mmsegmentation目录文件下——cd mmsegmentation
测试集精度指标
python tools/test.py projects/dubai/pspnet-DubaiDataset.py projects/dubai/work_dirs/DubaiDataset/iter_3000.pth

```python
# -*- coding = utf-8 -*-
# @Time : 2023/6/18 11:49
# @Author : Happiness
# @File : tuili.py
# @Software : PyCharm
####导入工具包
import numpy as np
import matplotlib.pyplot as plt
from mmseg.apis import init_model, inference_model, show_result_pyplot
import mmcv
import cv2
####载入配置文件
# 载入 config 配置文件
from mmengine import Config
cfg = Config.fromfile('pspnet-DubaiDataset.py')
from mmengine.runner import Runner
from mmseg.utils import register_all_modules
# register all modules in mmseg into the registries
# do not init the default scope here because it will be init in the runner
register_all_modules(init_default_scope=False)
runner = Runner.from_cfg(cfg)
###载入模型
checkpoint_path = './work_dirs/DubaiDataset/iter_3000.pth'
model = init_model(cfg, checkpoint_path, 'cuda:0')
###载入测试集图像,或新图像
#使用绝对路径不怕报错
img = mmcv.imread('D:/0.dive into pytorch/openmmlab/mmsegmentation/data/Dubai-dataset/img_dir/val/3.jpg')
###语义分割预测
result = inference_model(model, img)
['seg_logits', 'pred_sem_seg']
pred_mask = result.pred_sem_seg.data[0].cpu().numpy()
###可视化语义分割预测结果
plt.imshow(pred_mask)
plt.show()
# 可视化预测结果
visualization = show_result_pyplot(model, img, result, opacity=0.7, out_file='pred.jpg')
plt.imshow(mmcv.bgr2rgb(visualization))
plt.show()
#####获取测试集标注
label = mmcv.imread('D:/0.dive into pytorch/openmmlab/mmsegmentation/data/Dubai-dataset/img_dir/val/3.jpg')
label_mask = label[:,:,0]
plt.imshow(label_mask)
plt.show()
####对比测试集标注和语义分割预测结果
# 测试集标注
# 语义分割预测结果
# 真实为前景,预测为前景
TP = (label_mask == 1) & (pred_mask==1)
# 真实为背景,预测为背景
TN = (label_mask == 0) & (pred_mask==0)
# 真实为前景,预测为背景
FN = (label_mask == 1) & (pred_mask==0)
# 真实为背景,预测为前景
FP = (label_mask == 0) & (pred_mask==1)
plt.imshow(TP)
plt.show()
confusion_map = TP * 255 + FP * 150 + FN * 80 + TN * 30
plt.imshow(confusion_map)
plt.show()
####混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix_model = confusion_matrix(label_mask.flatten(), pred_mask.flatten())
import itertools
def cnf_matrix_plotter(cm, classes, cmap=plt.cm.Blues):
"""
传入混淆矩阵和标签名称列表,绘制混淆矩阵
"""
plt.figure(figsize=(10, 10))
plt.imshow(cm, interpolation='nearest', cmap=cmap)
# plt.colorbar() # 色条
tick_marks = np.arange(len(classes))
plt.title('Confusion Matrix', fontsize=30)
plt.xlabel('Pred', fontsize=25, c='r')
plt.ylabel('True', fontsize=25, c='r')
plt.tick_params(labelsize=16) # 设置类别文字大小
plt.xticks(tick_marks, classes, rotation=90) # 横轴文字旋转
plt.yticks(tick_marks, classes)
# 写数字
threshold = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > threshold else "black",
fontsize=12)
plt.tight_layout()
plt.savefig('混淆矩阵.pdf', dpi=300) # 保存图像
plt.show()
classes = ['Land', 'Road', 'Building', 'Vegetation', 'Water', 'Unlabeled']
cnf_matrix_plotter(confusion_matrix_model, classes, cmap='Blues')


