


159
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享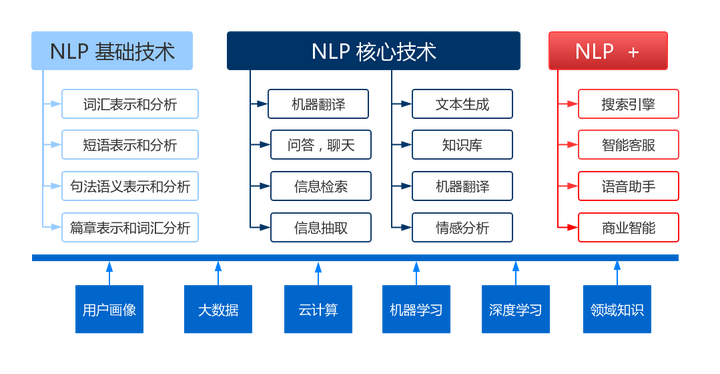
优点:
1. 自动化处理:NLP可以自动处理大量的文本数据,从而提高工作效率和准确性。它可以快速分析和理解大规模的文本,从中提取出有用的信息。
2. 人机交互:NLP可以使计算机能够与人类进行自然语言交互,例如智能助理、聊天机器人等。这种交互方式更加直观和便捷,使人机之间的交流更加自然和高效。
3. 多语言处理:NLP可以处理多种语言,实现跨语言的信息处理和翻译。这对于全球化的企业和跨国交流非常重要。
4. 情感分析和舆情监测:NLP可以分析文本中的情感和情绪信息,帮助企业和组织了解用户的态度和情感倾向,从而做出更好的决策。
缺点:
1. 语义理解的挑战:自然语言的语义非常复杂,存在歧义和多义性,这给语义理解和语义分析带来了挑战。尽管有很多技术和方法来处理这些问题,但仍然存在一定的误差和困难。
2. 数据稀缺和质量问题:NLP的性能很大程度上依赖于大规模高质量的训练数据。然而,获取和标注这样的数据是非常昂贵和耗时的,尤其是对于一些特定领域或语言的数据。
3. 文化和语言差异:不同的语言和文化背景可能会导致语言处理的差异和挑战。例如,某些语言可能没有严格的语法规则,或者存在特定的词汇和表达方式,这可能会影响到NLP的性能和准确性。
4. 隐私和伦理问题:NLP处理大量的文本数据,其中可能包含个人隐私信息。因此,保护用户隐私和处理数据的伦理问题是需要重视的。
以下是我对自己在自然语言处理方面的自我检讨:
1. 知识储备不足:自然语言处理是一个涉及多个学科的交叉领域,涉及到语言学、计算机科学、统计学等多个方面的知识。我需要进一步学习和深入理解这些知识,以便更好地应用于实际问题。
2. 技术应用不够成熟:尽管自然语言处理技术在近年来取得了很大的进展,但仍然存在一些挑战和限制。我需要更深入地了解当前的技术和方法,并不断关注最新的研究进展,以便能够更好地应对实际问题。
3. 数据处理和质量控制:自然语言处理的性能很大程度上依赖于训练数据的质量和多样性。我需要更加重视数据的处理和质量控制,确保使用的数据能够准确地反映实际情况,并且具有代表性。
4. 用户需求理解和满足:自然语言处理的最终目的是为用户提供有用的信息和服务。我需要更加关注用户的需求和反馈,不断改进和优化自己的系统,以便更好地满足用户的需求。
5. 隐私和伦理问题:自然语言处理涉及到大量的文本数据,其中可能包含个人隐私信息。我需要更加重视用户隐私的保护和处理数据的伦理问题,确保在处理数据时符合相关的法律和道德规范。
1. 语言理解:研究如何让计算机能够理解自然语言,包括词义消歧、句法分析、语义角色标注等任务。
2. 机器翻译:研究如何实现自动翻译,将一种语言的文本转换为另一种语言的文本。
3. 信息抽取:研究如何从大量的文本中提取出有用的信息,如实体识别、关系抽取等。
4. 文本分类和情感分析:研究如何对文本进行分类,如垃圾邮件过滤、情感分析等。
5. 问答系统:研究如何构建智能问答系统,使计算机能够回答用户提出的问题。
6. 文本生成:研究如何让计算机能够生成自然语言文本,如自动摘要、机器写作等。
7. 对话系统:研究如何构建能够进行自然对话的智能系统,使计算机能够理解和生成自然语言对话。

