


162
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享实验源码:
代码执行结果:
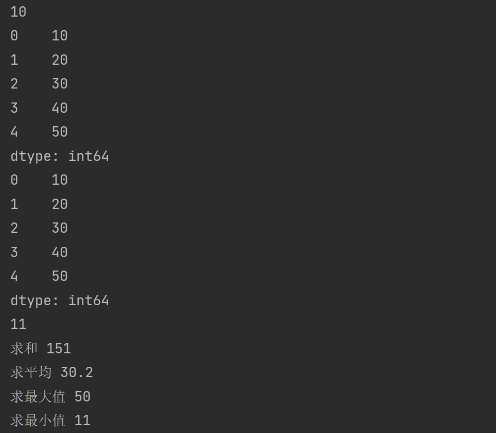
代码修改及意图:(1)对Series对象生成的数组填充不同类型的数据,观察其是否能存储不同类型的数据;
(2)打印s[-1],观察它与Python中的列表的区别;
(3)对生成的数组进行求和、求平均、求最大值和最小值。
结论:有Series对象生成的数组,它与Python中的列表相似和不同支持,首先是Series对象生成的数组不支持反向索引,及无法使用s[-1]来获取数组中的最后一个元素;它与列表一样,均可以使用切片的方式来获得数组片段;Series对象生成的数组有许多内置函数,来进行数据处理。
实验源码:
代码执行结果:
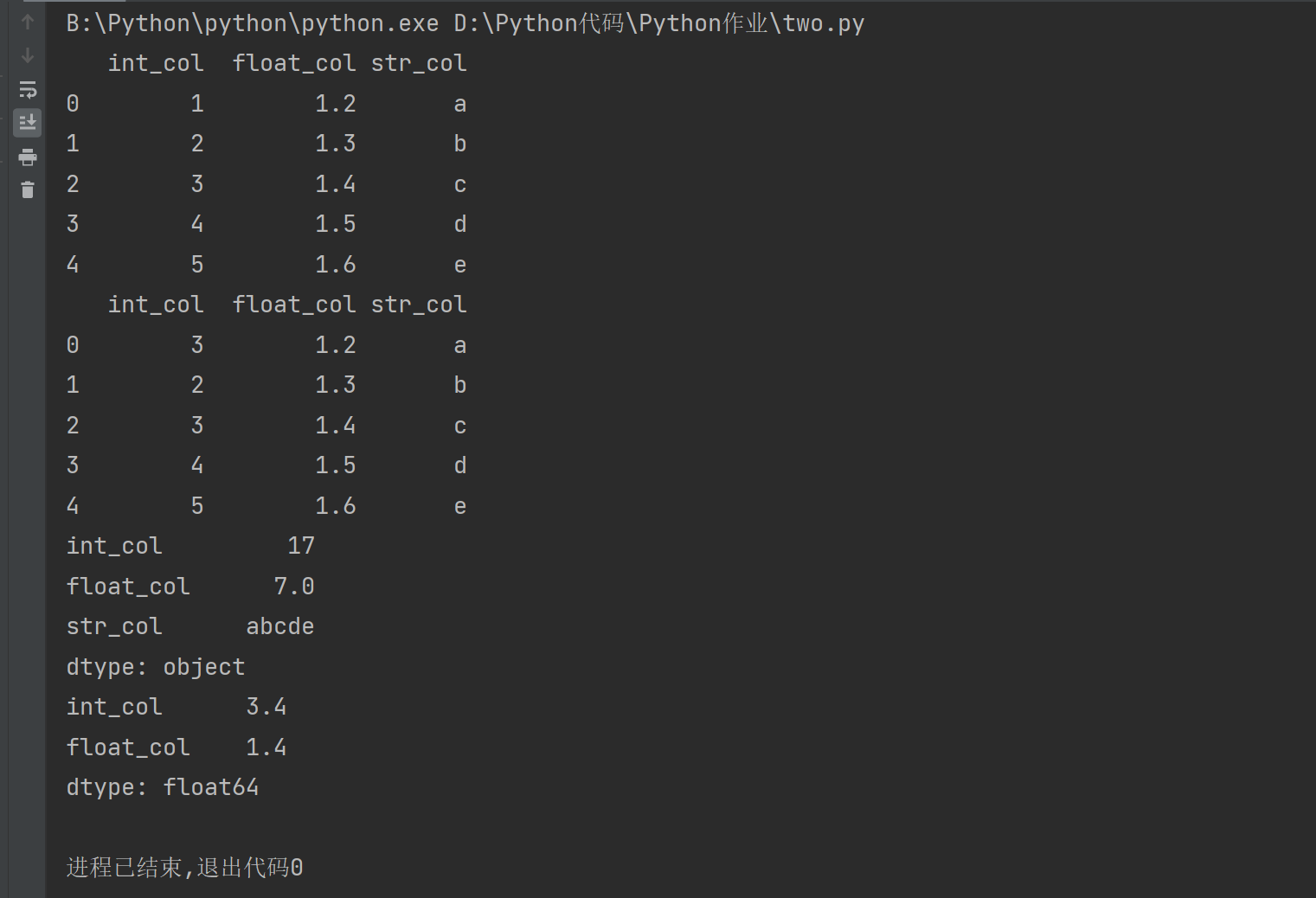
代码修改及其意图:(1)在求平均值时,将代码修改为 print(df.mean(numeric_only=True)) ,因为df.mean()方法只能求数值型数据的平均值,不能求字符串或者其他非数值型数据的平均值,所以要使用 numeric_only = True 来使它只求数据数值型的列的平局值。
结论:pandas中的DataFrame() 方法可以将字典(列表)生成矩阵的形式,从而能够使对数据的操作更加方便。有DataFrame()生成的数据结构,每一行和每一 列都有相应的行和列的名称,可以通过同时使用行和列的名称来获取相应的数据。在使用该数据结果求行(列)平均值时,一定要保证该行(列)中的所有 元素均为数值型数据。
实验源码:
import pandas as pd
import matplotlib.pyplot as plt
data = {
'city': ['beijing', 'shanghai', 'guangzhou', 'shenzhen'],
'population': [2171, 2424, 1500, 1303],
'gdp': [20000, 30000, 19002, 19990],
'area': [16410, 6340, 7434, 1996]
}
df = pd.DataFrame(data)
print(df)
pop_rank = df['population'].rank(ascending=False)
gdp_rank = df['gdp'].rank(ascending=False)
area_rank = df['area'].rank(ascending=False)
print(pop_rank)
print(gdp_rank)
print(area_rank)
ax = df.plot(kind='bar', x='city', y=['population', 'gdp', 'area'], title='China Capital Cities')
plt.show()
代码执行结果:
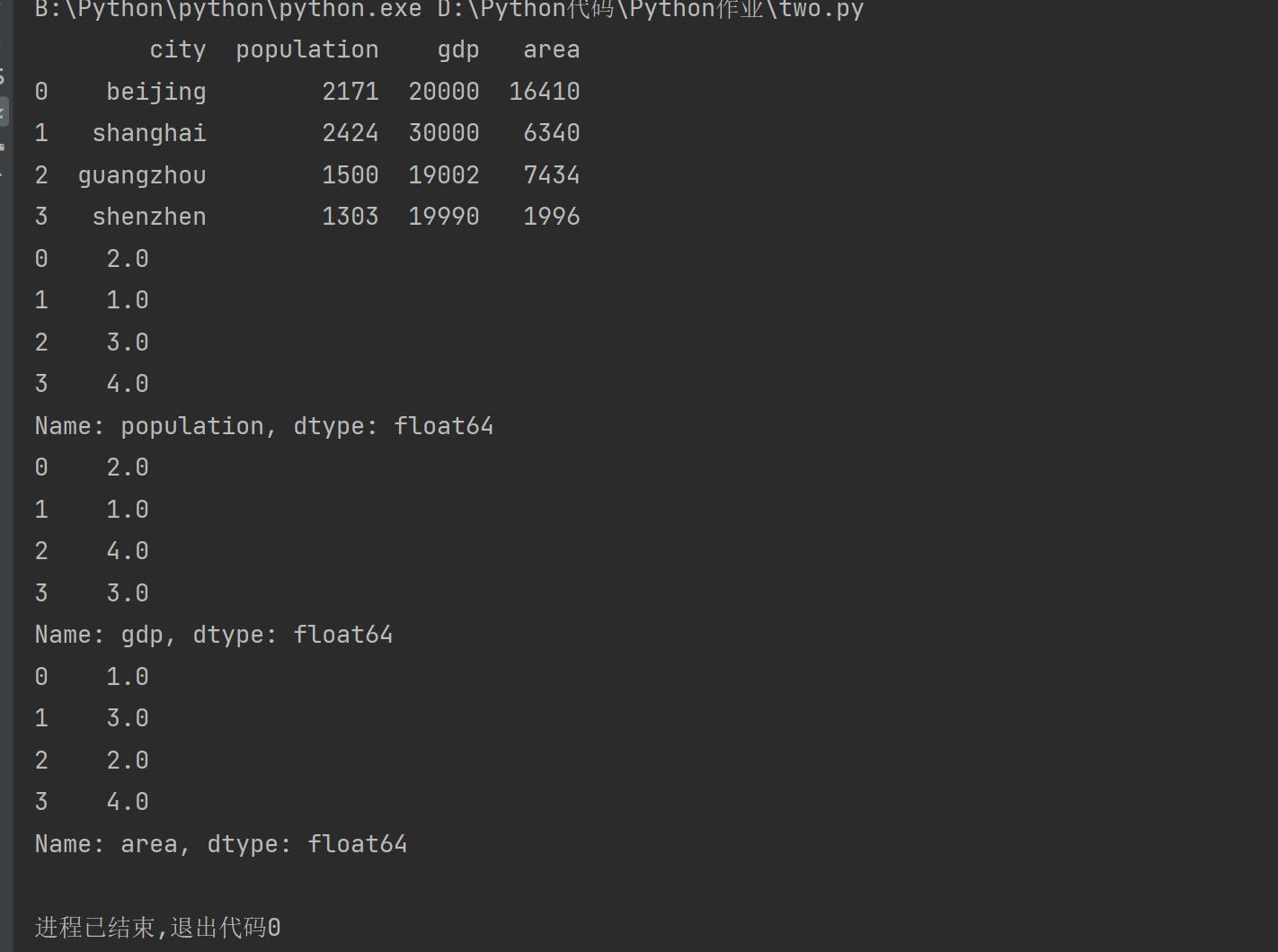
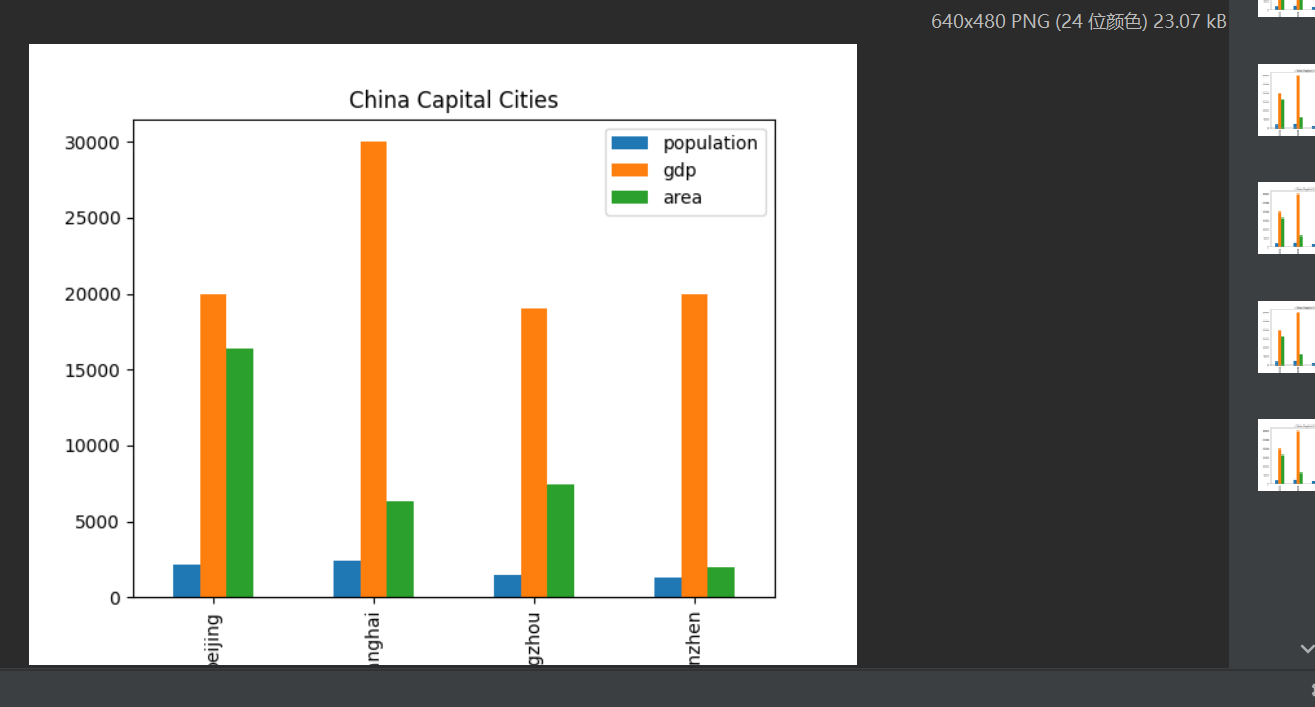
代码修改及其意图:我将data字典中城市的名称由中文全部改为了字母拼音,为了使城市的名称能够展示在数据统计图的 X 轴上,必须得使用英文字母。
结论:pandas库可以很方便的对矩阵中的每一列(行)中的数据进行按照升序(降序)来排列;matplotlib库能够将pandas库中生成的矩阵的每一列进行数据统计,并生成相应的数据统计图。

