




136,140
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

1、导入数据时MySQL的处理方式 :
当我们通过MySQL命令将数据导入到MySQL数据库中时,MySQL会首先查找导入数据中是否存在同名的表,如果存在,那么MySQL会判断该表是否为临时表,如果是,则会将原来的表替换掉,如果不是,则会抛出重复表名或表名异常的错误提示。此时,数据不会产生任何覆盖,也就是说,您的原始数据依然存在,无需担心数据覆盖的问题。 覆盖导入数据的处理方式 如果您要有意覆盖原来的数据库或表,那么有两种方式可以实现: 使用MySQL命令:在导入数据时,使用“–replace”或“–overwrite”参数即可覆盖原来的数据,例如“mysql -u root -p database< data.sql --replace”或“mysql -u root -p database< data.sql --overwrite”。 使用MySQL工具:在MySQL可视化工具中,导入数据时可以选择“覆盖原表”或“仅填充数据”,如果您选择“覆盖原表”,那么新数据会覆盖掉原有的数据,否则只会更新数据。 注意 以上的覆盖方式需要慎重使用,否则可能会导致您的数据丢失或者被覆盖掉,这种情况最好是提前备份原数据,在进行覆盖操作之前可以先检查数据的完整性,以确保数据的安全性和正确性。 结论 综上所述,当我们执行MySQL命令将数据导入到MySQL数据库时,MySQL会通过判断是否存在同名的表,并根据临时表标记来决定数据是否会覆盖原有数据。
另:source执行文件中的SQL语句时,是否覆盖、丢失的问题,要检查你的SQL语句文件,如果文件里面有删除表、建立表的语句,那么现有数据会丢失。另外查看你的数据库是否有唯一索引或者主键,如果有的话,重复数据是无法加载的。
mysqldunp取决于导入的sql文件中的操作语句。如果sql文件中的操作语句是INSERT INTO,则导入的数据会被插入到原有的数据后面,不会覆盖原有的数据。这种情况下,我们可以在原有的数据基础上添加新的数据。如果sql文件中的操作语句是UPDATE或者DELETE,则导入的数据会覆盖原有的数据。这种情况下,我们需要谨慎操作,避免误操作导致数据的丢失。如果sql文件中包含DROP TABLE语句,比如常见的DROP TABLE IF EXISTS `product` ,则会删除原有的表并重新创建一个新的表。一般情况下,mysqldump导出来的数据表结构,前面都有DROP TABLE IF EXISTS `tables_name`;然后再create;即会删除;总之,在导入sql文件之前,我们需要仔细查看sql文件中的操作语句,以免误操作导致数据的丢失。对于单张表,可使用insert into old_tb select * from new_tb;处理。
2、mysqldump工作原理
mysqldump作为MySQL自带的逻辑备份工具。它的备份原理是通过协议连接到 MySQL数据库,将需要备份的数据查询出来,将查询出的数据转换成对应的insert语句,当我们需要还原这些数据时,重新执行一遍这些insert语句,相当于对过去重演,即可将对应的数据还原。
1)备份流程如下:
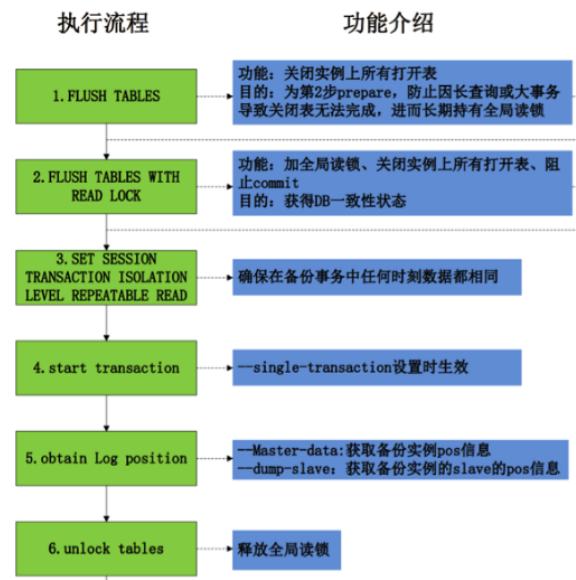
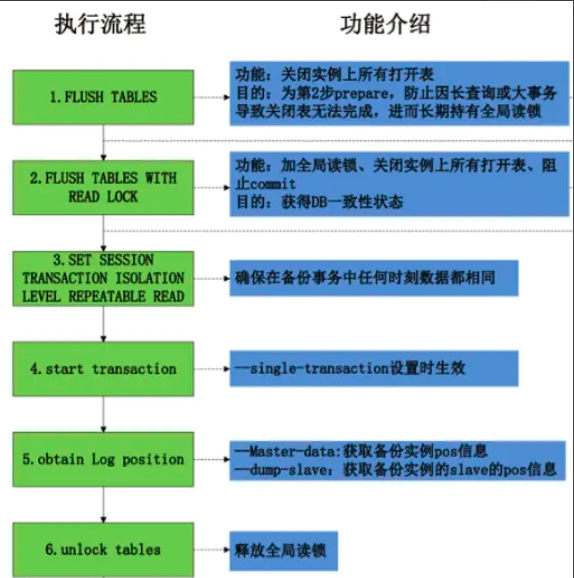
1.调用FWRL(flush tables with read lock),全局禁止读写
2.开启快照读,获取此期间的快照(仅仅对innodb起作用)
3.备份非innodb表数据(*.frm,*.myi,*.myd等)
4.非innodb表备份完毕之后,释放FTWRL
5.逐一备份innodb表数据
6.备份完成
--------------------详细-----------------------------
1、set sql_mode =''
2、 FLUSH /*!40101 LOCAL */ TABLES 关闭所有打开的表
3、 FLUSH TABLES WITH READ LOCK 加全局读锁,禁止commit,运行读,获取DB一致性数据
4、SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ 设置会话RR隔离级别,避免不可重复读和幻读,保证数据导出时相同
5、START TRANSACTION /*!40100 WITH CONSISTENT SNAPSHOT */ 获取当前数据库的快照,这个是由mysqldump中--single-transaction决定,mysql innodb支持
6、SHOW MASTER STATUS 获取binlog file 与positon,有--master-data参数决定值 2 为注释,值1 不注释
7、UNLOCK TABLES 释放全局锁
8、SAVEPOINT sp
9、select * from T T表DDL会堵住,所有操作会被DDL rename result table堵住
10、ROLLBACK TO SAVEPOINT sp 表备份结束,回滚到保存点sp,释放select MDL锁
11、 release SAVEPOINT sp
eg1:mysqldump -uroot -proot -h127.0.0.1 --all-databases --single-transaction --routines --events --triggers --master-data=2 --hex-blob --default-character-set=utf8mb4 --flush-logs --quick > all.sql
我们来看下日志:tail -f /var/lib/mysql/localhost.log
第一步:
FLUSH /*!40101 LOCAL */ TABLES # 这里是刷新表
第二步:
FLUSH TABLES WITH READ LOCK # 因为开启了--master-data=2,这时就需要flush tables with read lock锁住全库,
记录当时的master_log_file和master_log_pos点
思考: 执行flush tables操作,并加一个全局读锁,那么以上两个命令貌似是重复的,为什么不在第一次执行flush tables操作的时候加上锁呢?
简而言之,是为了避免较长的事务操作造成FLUSHTABLESWITHREADLOCK操作迟迟得不到锁,但同时又阻塞了其它客户端操作。
第三步:
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ # --single-transaction参数的作用,设置事务的隔离级别为可重复读,
即REPEATABLE READ,这样能保证在一个事务中所有相同的查询读取到同样的数据,也就大概保证了在dump期间,如果其他innodb引擎的线程修改了表的数据并提交,对该dump线程的数据并无影响,然而这个还不够,还需要看下一条
第四步:
START TRANSACTION /*!40100 WITH CONSISTENT SNAPSHOT */ # 获取当前数据库的快照,这个是由mysqldump中--single-transaction决定的。
# WITH CONSISTENT SNAPSHOT能够保证在事务开启的时候,第一次查询的结果就是
事务开始时的数据A,即使这时其他线程将其数据修改为B,查的结果依然是A。简而言之,就是开启事务并对所有表执行了一次SELECT操作,这样可保证备份时,在任意时间点执行select * from table得到的数据和执行START TRANSACTION WITH CONSISTENT SNAPSHOT时的数据一致。
【注意】,WITH CONSISTENT SNAPSHOT只在RR隔离级别下有效。
第五步:
SHOW MASTER STATUS # 这个是由--master-data决定的,记录了开始备份时,binlog的状态信息,
包括MASTER_LOG_FILE和MASTER_LOG_POS
这里需要特别区分一下master-data和dump-slave
master-data:
--master-data=2表示在dump过程中记录主库的binlog和pos点,并在dump文件中注释掉这一行;
--master-data=1表示在dump过程中记录主库的binlog和pos点,并在dump文件中不注释掉这一行,即恢复时会执行;
dump-slave
--dump-slave=2表示在dump过程中,在从库dump,mysqldump进程也要在从库执行,
记录当时主库的binlog和pos点,并在dump文件中注释掉这一行;
--dump-slave=1表示在dump过程中,在从库dump,mysqldump进程也要在从库执行,
记录当时主库的binlog和pos点,并在dump文件中不注释掉这一行;
第六步:
UNLOCK TABLES # 释放锁。
2)mysqldump 对 InnoDB 和 MyISAM 两种存储引擎进行备份的差异。
2.1 对于支持事务的引擎如 InnoDB,参数上是在备份的时候加上 –single-transaction 保证数据一致性
–single-transaction 实际上通过做了下面两个操作 :
① 在开始的时候把该 session 的事务隔离级别设置成 repeatable read ;
② 然后启动一个事务(执行 begin ),备份结束的时候结束该事务(执行 commit )
有了这两个操作,在备份过程中,该 session 读到的数据都是启动备份时的数据(同一个点)。可以理解为对于 InnoDB 引擎来说加了该参数,备份开始时就已经把要备份的数据定下来了,
备份过程中的提交的事务时是看不到的,也不会备份进去。
2.2 对于不支持事务的引擎如 MyISAM,只能通过锁表来保证数据一致性,这里分两种情况:
1)导出全库:加 –lock-all-tables 参数,这会在备份开始的时候启动一个全局读锁
(执行 flushtableswithread lock),其他 session 可以读取但不能更新数据,
备份过程中数据没有变化,所以最终得到的数据肯定是完全一致的;
2)导出单个库:加 –lock-tables 参数,这会在备份开始的时候锁该库的所有表,
其他 session 可以读但不能更新该库的所有表,该库的数据一致;
3)附录:
#查询数据库中所有表名
select table_name from information_schema.tables where table_schema='csdb' and table_type='base table';
#查询指定数据库中指定表的所有字段名column_name
select column_name from information_schema.columns where table_schema='csdb' and table_name='users'
#分月导入数据不覆盖的网络经验案例
1.首先导出时可以只导出创建表结构的语句,注意选项-d,表示只导出表结构
mysqldump -uroot -B 库名 --tables 表名 -d --master-data=2 --force -S /usr/local/mariadb_3306/mariadb.sock >/data/table-structure
2.然后再按月份导出数据文件,注意选项-t,只导出表数据
mysqldump -uroot -B 库名 --tables 表名 -t --master-data=2 --force -S /usr/local/mariadb_3306/mariadb.sock --where="createTime<'2016-11-01 00:00:00'" >2016-11
3.然后先导入表结构语句
mysql -uroot -B 库名 --force -S /usr/local/mariadb_3309/mariadb.sock </data/table-structure
4.再依次导入数据
mysql -uroot -B 库名 --force -S /usr/local/mariadb_3309/mariadb.sock <2016-11
5.直接使用mysqldump导出时,默认导出了数据和表结构,导入时会判断表是否存在,存在则删除,新建一个,就会把原来已导入的数据一起删除,出现了覆盖的效果。
3、修改sql文件,注释掉,对不存在的表创建:
s#^DROP#/*DROP#g #打开sql,注释掉drop语句
:%s#CREATE TABLE#CREATE TABLE if not exists#g
命令回顾:
:s/str1/str2/ 替换当前行第一个 str1 为 str2
:s/str1/str2/g 替换当前行中所有 str1 为 str2
:m,ns/str1/str2/ 替换第 n 行开始到最后一行中每一行的第一个 str1 为 str2
:m,ns/str1/str2/g 替换第 n 行开始到最后一行中所有的 str1 为 str2
:1,$s/mpks/mpkss/g 将第一行到最后一行的mpks都替换成mpkss
//注:m和n 为数字,若m为 .,表示为当前行开始;若n为$,则表示到最后一行结束)
//如果使用 # 作为分隔符,则中间出现的 / 不会作为分隔符,比如:
:s#str1/#str2/# 替换当前行第一个 str1/ 为 str2/
:%s+/oradata/apras/+/user01/apras1+ (使用+ 来 替换 / ): /oradata/apras/替换成/user01/apras1/
//其他:%s/str1/str2/(等同于 :g/str1/s//str2/) 替换每一行的第一个 str1 为 str2
:%s/str1/str2/g (等同于 :g/str1/s//str2/g 和 :1,$ s/str1/str2/g ) 替换文中所有 str1 为 str2
从替换命令可以看到,g 放在命令末尾,表示对搜索字符串的每次出现进行替换;不加 g,表示只对搜索
完成后,执行sql导入:mysql> source /tmp/rsms_struct.sql;
验证:
SELECT COUNT(*) TABLES, table_schema FROM information_schema.TABLES WHERE table_schema = 'rsms';
//查询所有数据库表的数量
SELECT COUNT(*) TABLES, table_schema FROM information_schema.TABLES GROUP BY table_schema;
4)或mysqldump导出时,添加--skip-add-drop-table参数,使得导出的数据,不含drop
mysqldump -h127.0.0.1 -uroot -p --skip-add-drop-table --databases dbname --tables tablename > /tmp/tables1.sql
5)其他参考:
