


1,040
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享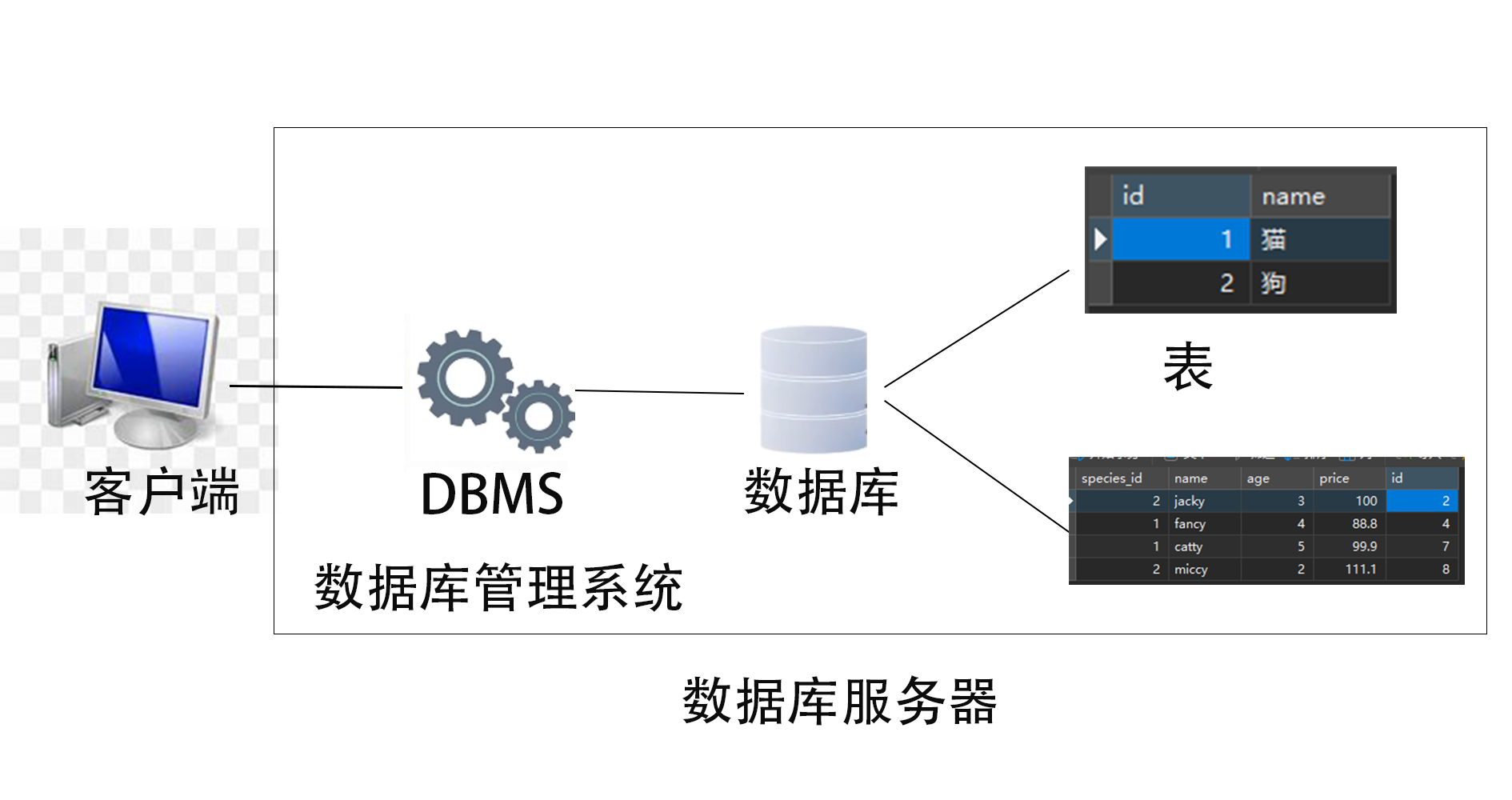
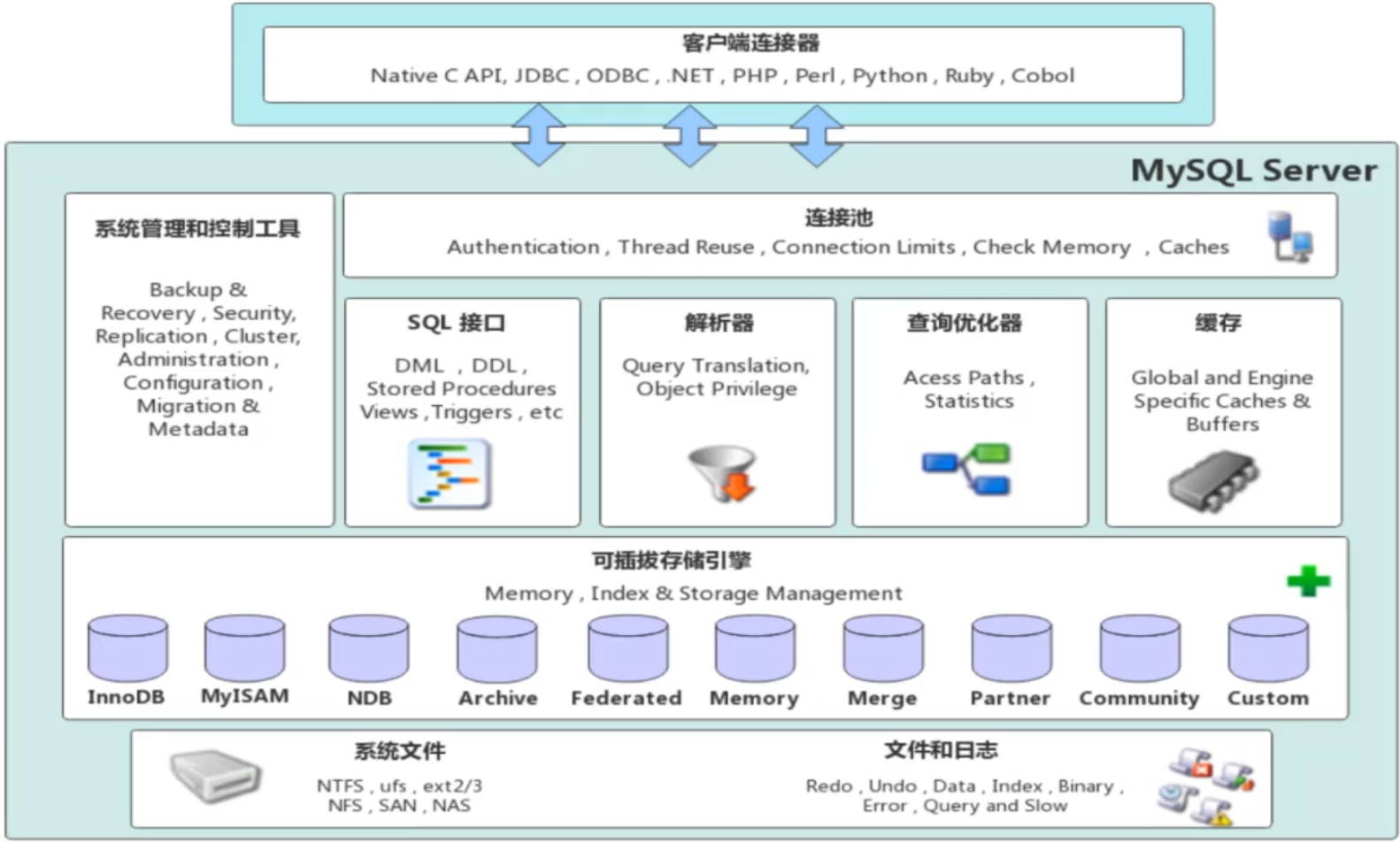
连接层
最上层是一些客户端和连接服务,主要完成一些类似于连接处理,授权认证及相关的安全方案。
服务层
第二层架构主要完成大多数的核心服务功能, 如SQL接口,并完成缓存的查询,SQL的分析和优化,部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如过程,函数
引擎层
存储引擎真正的负责了MySQL中数据的存储和提取, 服务器API和存储引擎进行通信。不同的存储引擎具有不同的功能,根据需要选取合适的存储引擎
存储层
将数据存储在文件系统之上,并完成存储引擎的交互
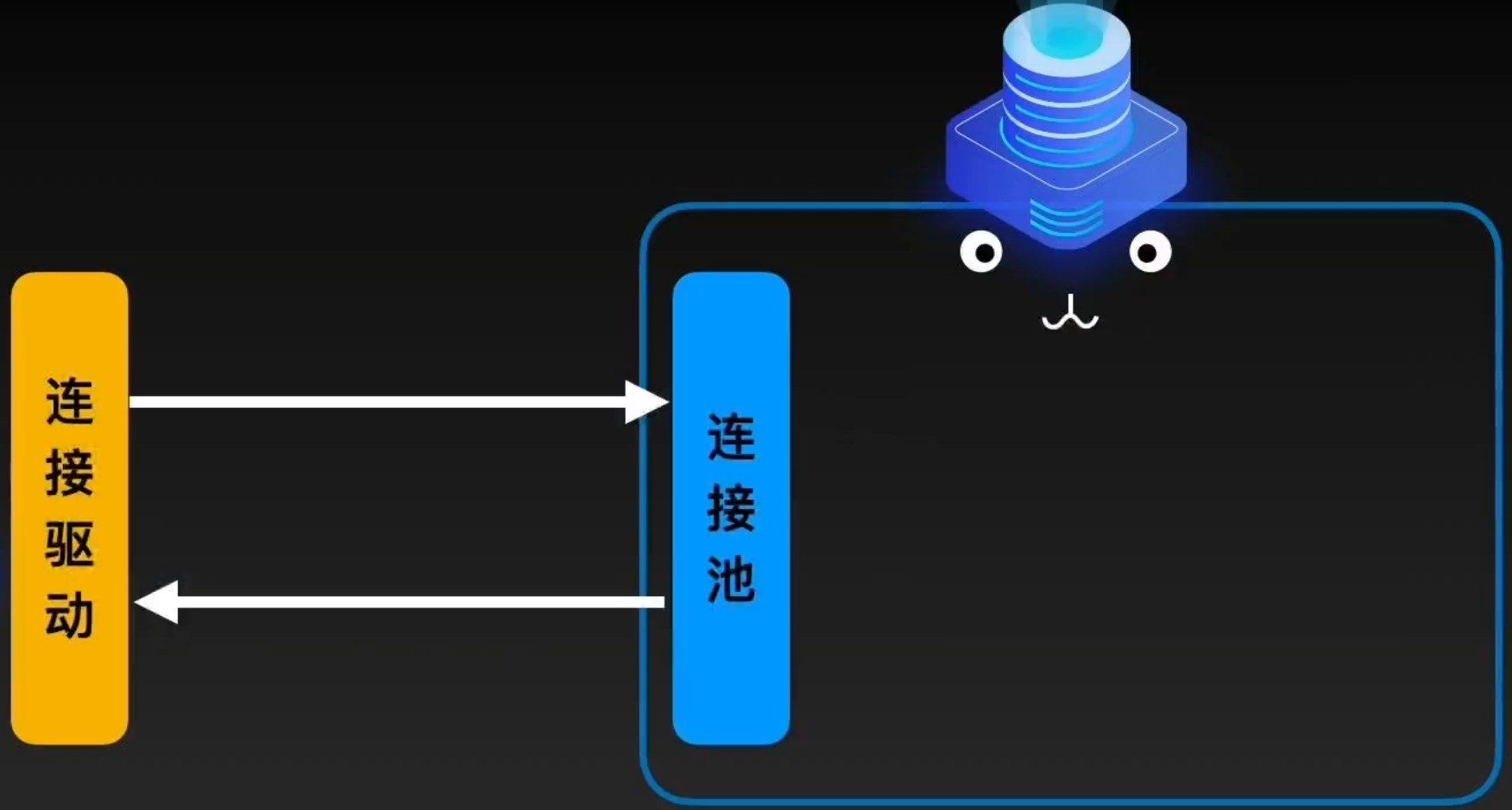
客户端现通过“客户端连接驱动”和“连接池”建立连接,这个连接通常会使用TCP/IP协议。由于服务端和客户端之间使用半双工模式通信,在任意时刻,一端开始发送消息,另一端需要接收完整消息才能响应它,所以客户端只能用一个数据包将语句发送给服务器,返回给客户端的数据也需要客户端完整的接收
在接受到SQL语句后,首先会在“查询缓存”中进行查找,“查询缓存是一个map<SQL语句,查询结果>结构,key是SQL语句, value是查询结果。不过,在5.7版本中默认关闭,并在8.0版本后移除
之后,会由SQL解析器进行词法分析和语法分析,通过语法解析器的验证后,接下来会通过预处理器将请求进行拆分。先提交SQL模板语句。再提交参数并进行执行。这样的话,对于多次重复执行的语句来说,可以提交并处理一次模板即可,不断提交参数实现多次执行,提高效率。在此过程中,也会进行语法验证,如表和列是否存在,别名歧义等。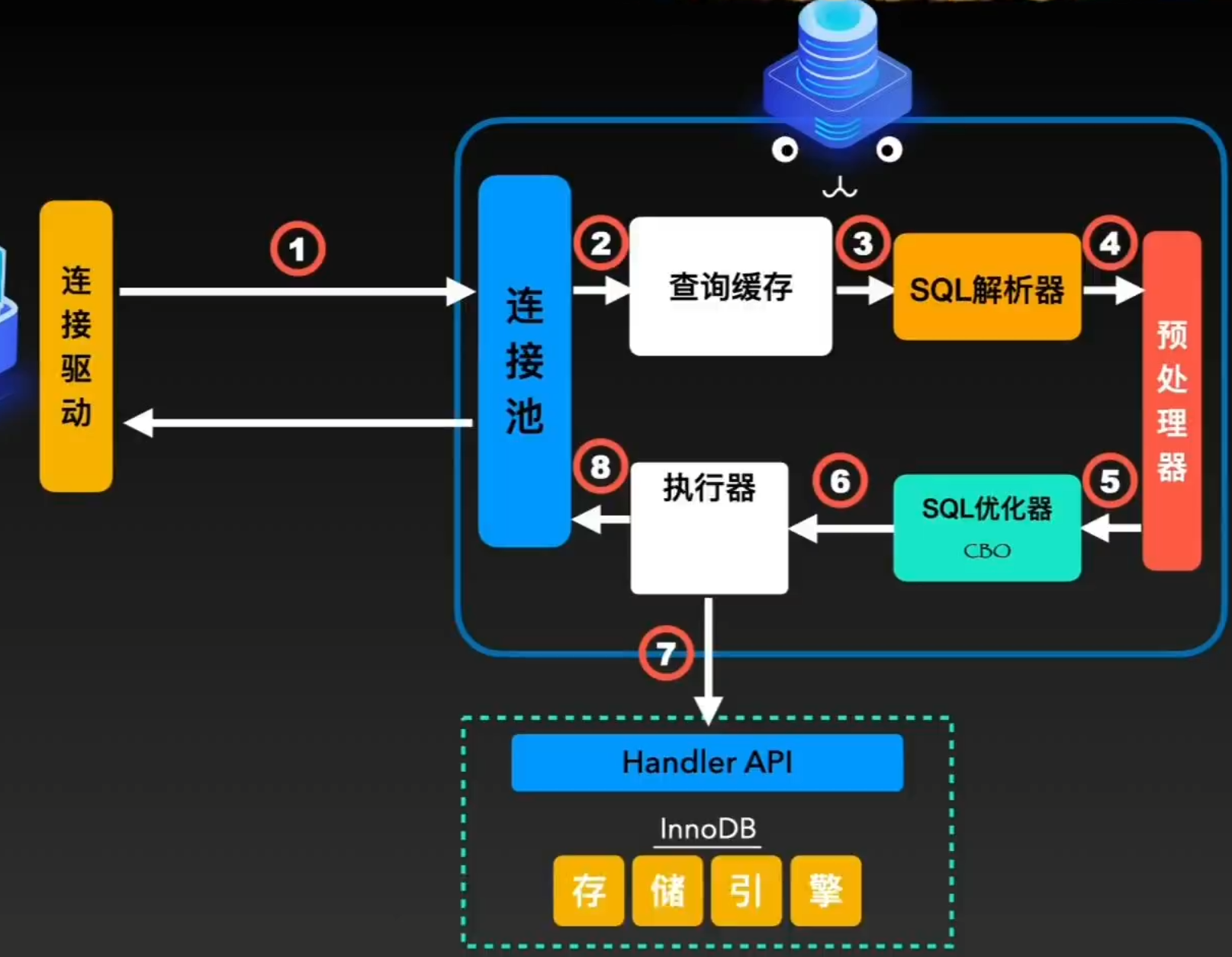
经过SQL预处理之后就会进入下一个环节:对SQL进行优化。通过对成本的优化器”CBO“,从目标众多的执行路径中,选择一个最小的执行路径作为执行计划。成本是指通过数据表、数据量、索引等信息,计算出SQL语句对应的IO成本和CPU成本的消耗值。
通过优化器之后,SQL就会变成一个可执行的”执行计划“,执行器就会再存储引擎中查找相关的Handler API,同时进行组合和调用
在InnoDBs收到命令后,首先会在”执行器“中将各种请求进行拆分,即MTR
如果是一个读指令,则回去内存中通过”自适应哈希索引(AHI)“进行查找并进行返回。InnoDB会根据”热点页“建立”自适应哈希索引“提升”热点页“的查询速度。如果Buffer Pool中没有找到要查找的数据,则会通过”预读“的方式从磁盘空间中加载到Buffer Pool中,然后返回数据完成读指令。同时Buffer Pool会通过free链表、flush链表、LRU链表这三个链表来管理数据页的写入位置、刷盘位置以及数据页淘汰
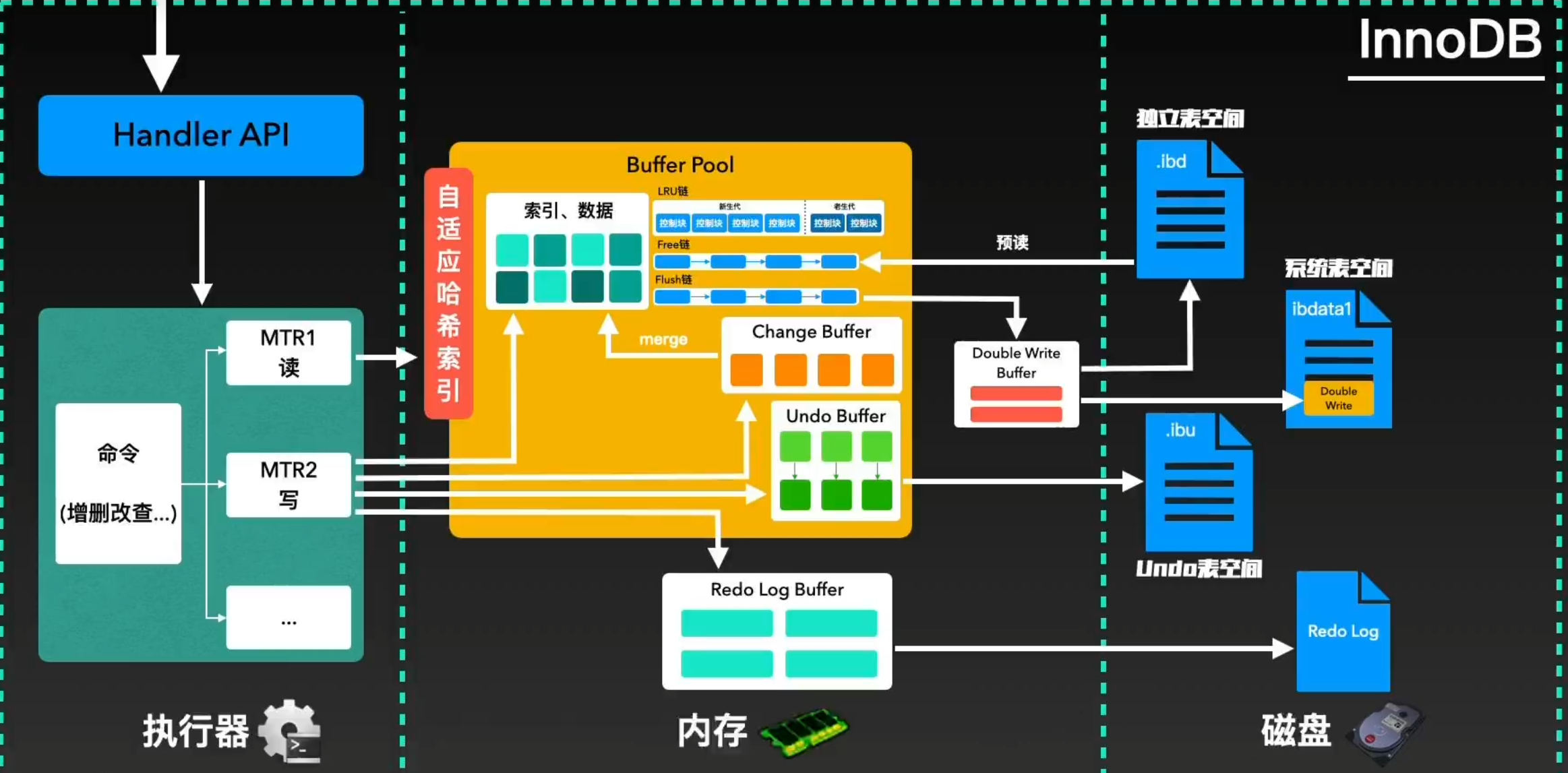
如果是一个写指令,则要先写入负责回滚的Uedo Log,然后将数据记录到Redo Log Buffer, 同时根据一定规则刷到磁盘的Redo Log中。之后,需要将真实数据写入Buffer Pool。在这之前也会根据一定规则判定,是否将写入变更缓冲Change Buffer中,再后续某些时机合并到Buffer Pool中
数据进入Buffer Pool中之后,就要将数据写入磁盘中了。为了保证”页“的完整传输,会先将数据写入Double Write Buffer,同时写入磁盘中系统表空间的Double Write里, 这样即使在”页“传输到一半时断点或进程挂掉,而产生残缺的”页“,也可以通过Double Write进行恢复。最后,将真实数据刷入磁盘后就完成了数据写入。接下来详细介绍一下数据写入的过程
MySQL选择了一个既可靠,性能又高作为默认引擎--InnoDB。InnoDB在可靠性和高性能之间做了平衡,在事务控制,读写效率,多用户并发,索引搜索等众多方面均有不俗的表现,成为绝大所属情况下的首选引擎。同其他引擎一样,其最核心的作用就是通过执行器对内存中的数据进行写入和读取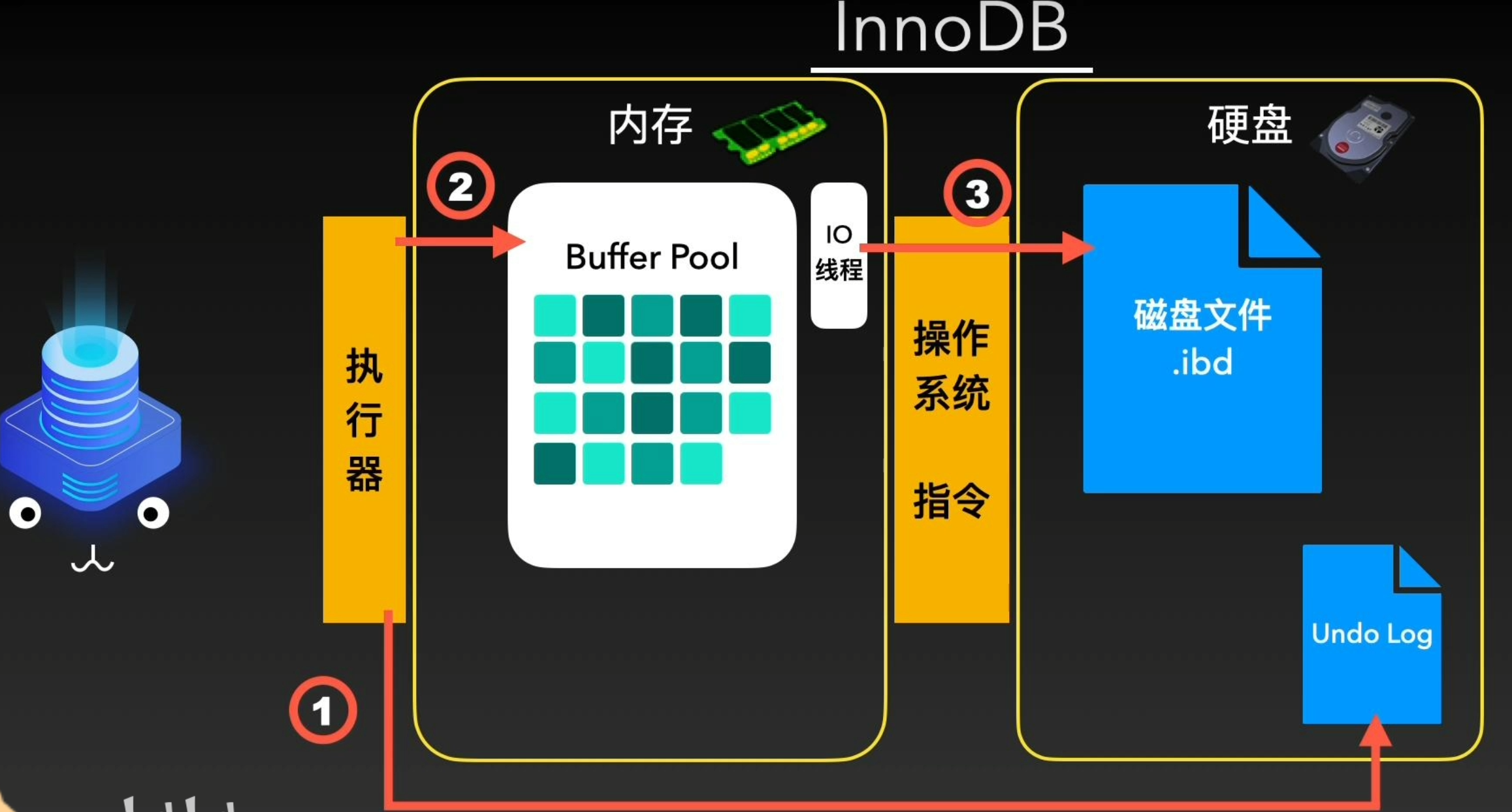
因为内存的查询和写入速度要远高于磁盘,所以一切的逻辑处理和读取写入都只操作内存中的数据,这个区域被称为Buffer Pool。
InnoDB会把它需要写入的数据,插入或者更新到Buffer Pool中。为了支持回滚,就需要在此之前,将数据的旧值记录到另一个地方,就是Undo Log文件。将数据写入内存之后,InnoDB就会让IO线程在特定时机将内存中的数据读取并写入磁盘中。
但是,一旦断点或服务挂掉,那么处于内存中还没来得及刷入磁盘的数据,就会永久丢失。因此为了应对突发情况,设计了Redo Log体系应对
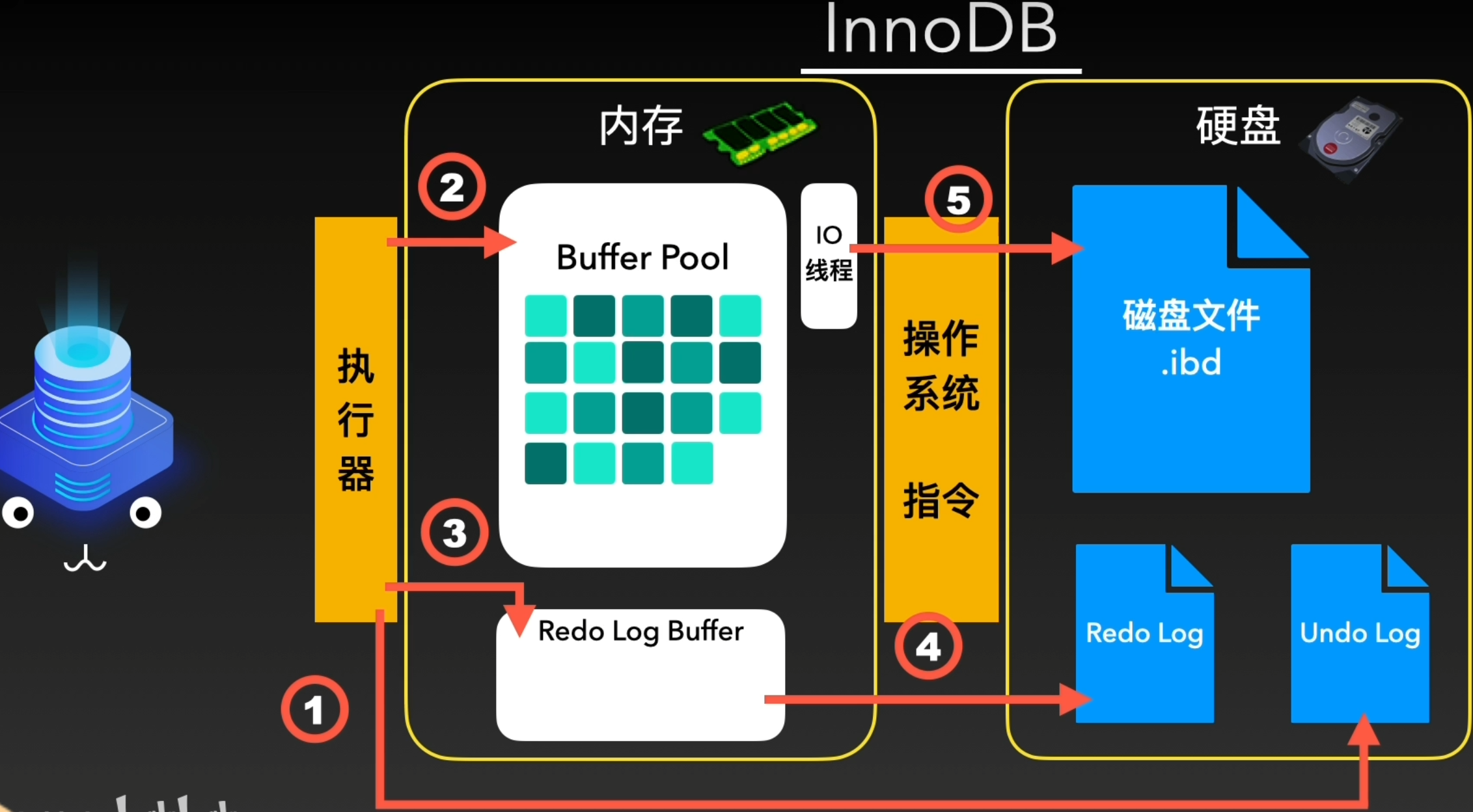 这套体系在数据进入Buffer Pool之后,就将更新写入信息放入内存的另一个区域Redo Log Buffer中,然而,光写入内存也无法解决刚才的问题,因此还要将其刷入磁盘中。
这套体系在数据进入Buffer Pool之后,就将更新写入信息放入内存的另一个区域Redo Log Buffer中,然而,光写入内存也无法解决刚才的问题,因此还要将其刷入磁盘中。
InnoDB提供多种刷盘策略,默认为1,表示每次每次在事务提交前,都会将更新写入信息写到内存Redo Log Buffer中,与此同时添加到操作系统内存中,并立刻进行刷盘
 而0、2两个策略的一致性没有这么强,0策略只会写入到内存Redo Log Buffer中,每个一秒钟才会进行系统内存放入和刷盘操作。2策略会写入Redo Log Buffer和操作系统内存,但也会等待每秒的刷盘操作
而0、2两个策略的一致性没有这么强,0策略只会写入到内存Redo Log Buffer中,每个一秒钟才会进行系统内存放入和刷盘操作。2策略会写入Redo Log Buffer和操作系统内存,但也会等待每秒的刷盘操作
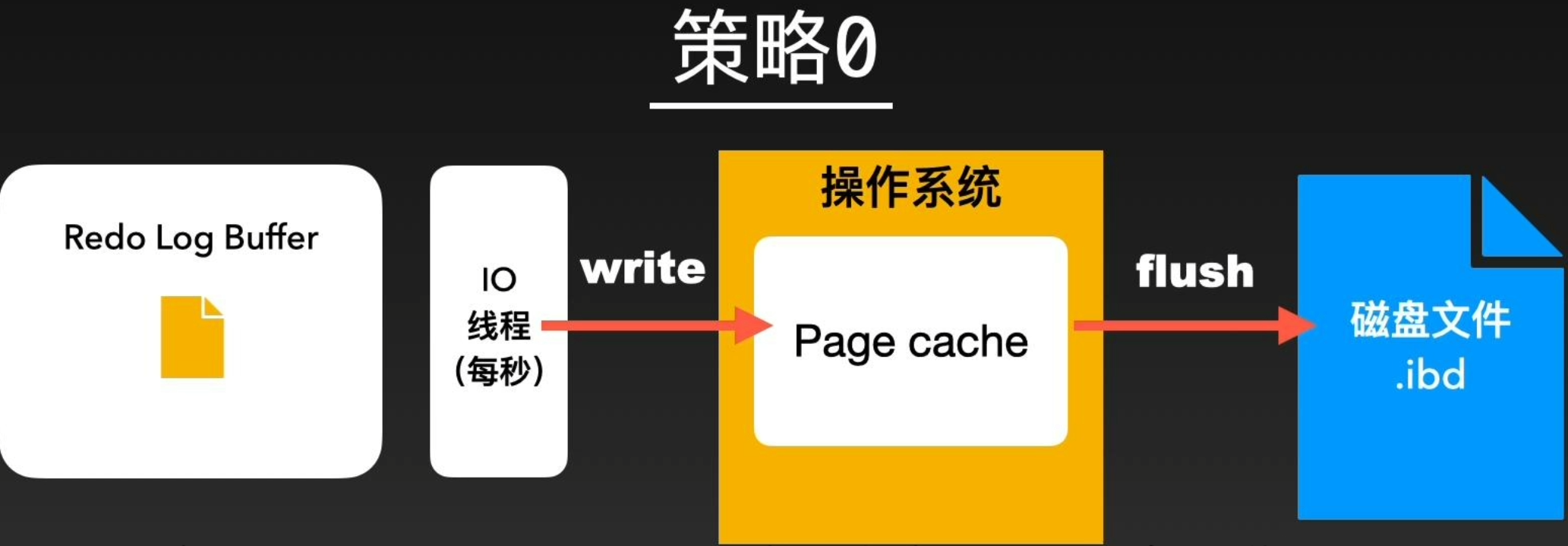

这样,即使内存中数据丢失了,由于Redo日志会把数据更新写入的信息都记录下来,重启后会优先从Redo日志中恢复没有刷进磁盘的数据,从而保证了数据的完整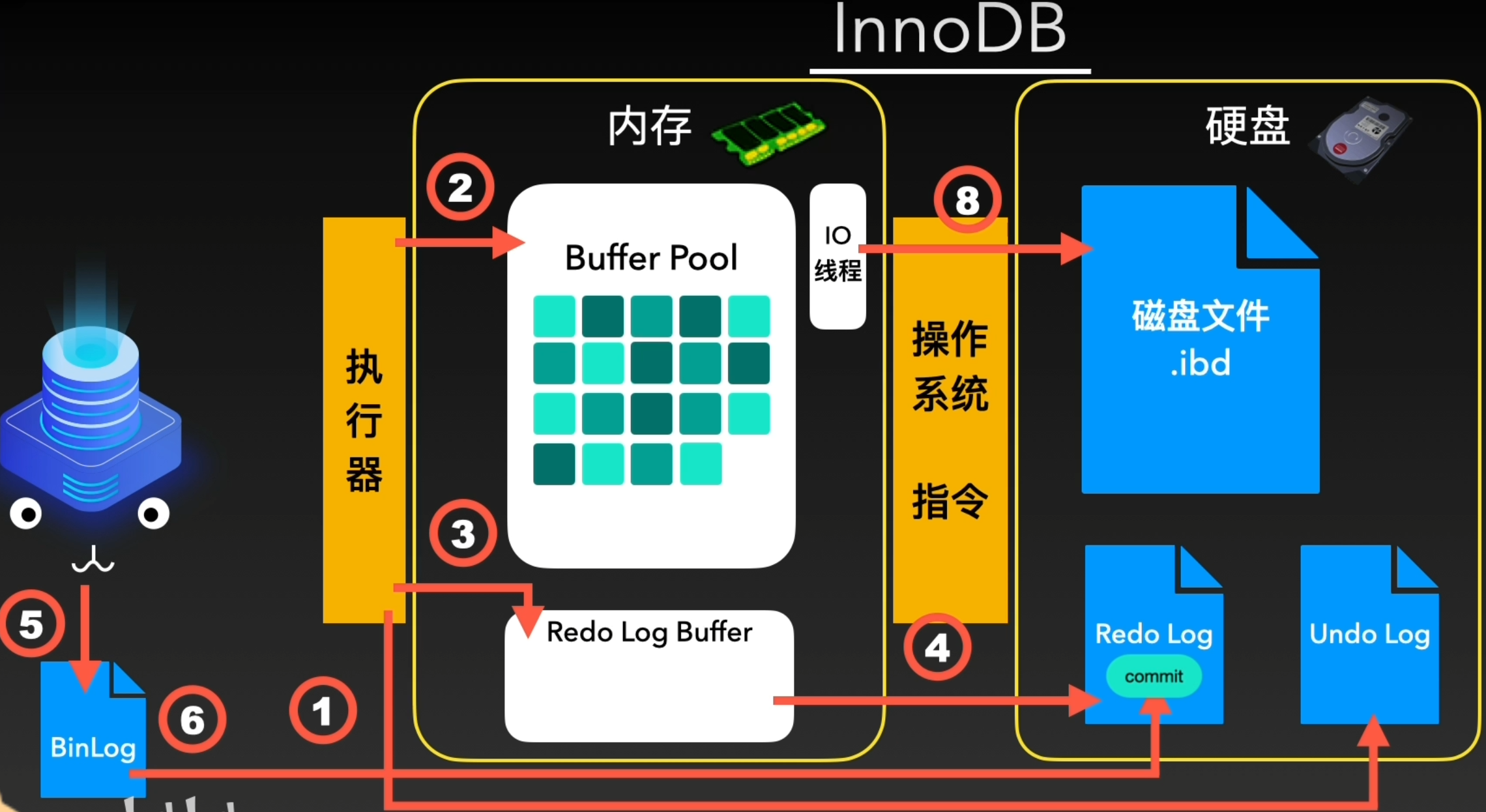
此外,还有BinLog日志,可以提供变更历史查询,数据库备份和恢复,主从复制等功能
在Redo Log日志写入的同时,会进行BinLog的刷盘操作。在刷盘成功后,会告知Redo日志事务“已提交”这个信息,Redo日志也打入“commit”标记。这样一次数据写入的流程就完成了
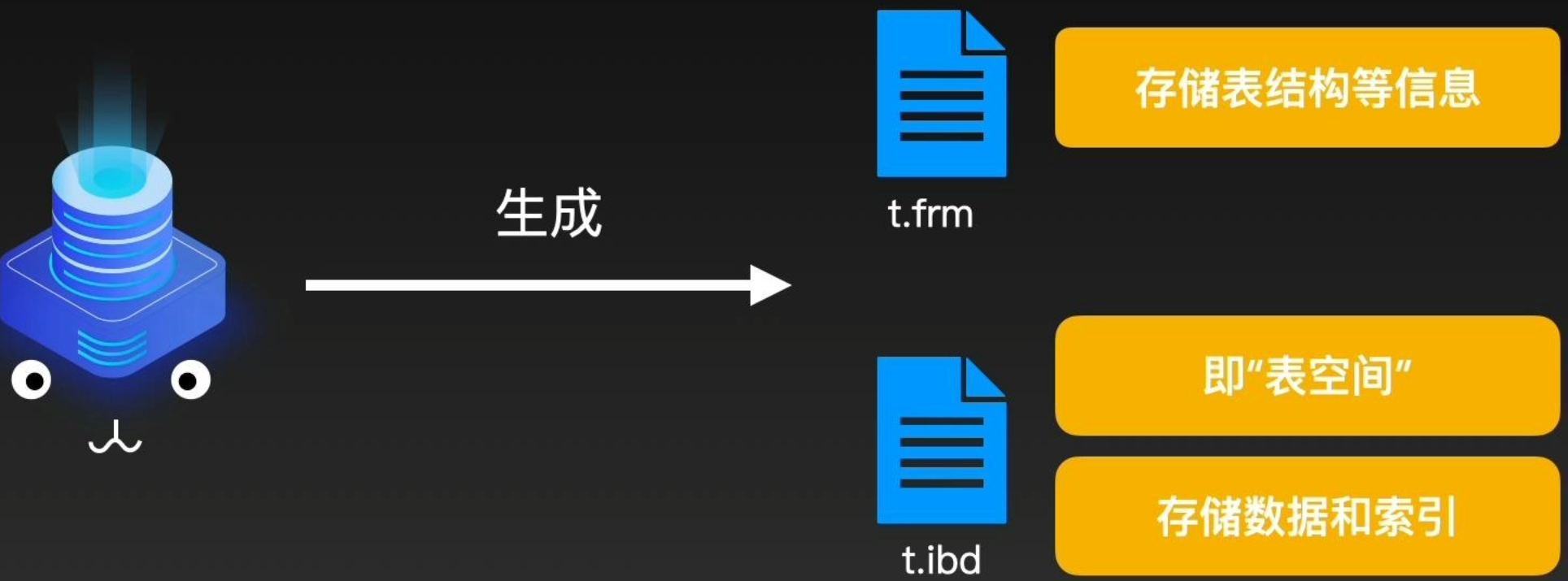
当新创建时,会在磁盘data目录下创建对应的两个文件,frm文件存放表结构等信息,ibd文件存储表的数据和索引,(5.7版本之后才会为每个表创建一个ibd文件,称为独立表空间,在此之前所有数据和索引都会被存放在系统表空间中,也被称为共享表空间)
表空间共分为5类,分别为独立表空间, 系统表空间,Undo表空间,通用表空间和临时表空间
在ibd文件中,最重要的结构体是“页”, 是InnoDB中内存与磁盘交互的最小存储单元。在磁盘中,每个“页”内部的地址都是连续的,因为,通常情况下,查找的数据均会连需存在,秩序在磁盘中读取一段连续的数据放入内存,后续的查询大概率就可以直接从内存中找到,这样就通过减少磁盘的访问次数大大提高了效率
一段内容连续的“页”大小为固定的16KB, 即使没有数据,也会占用16KB大小,同时,与索引B+树中节点对应
这16KB结构比较多样,跟据不同的场景,会选择不同类型的“页”。页共有12种,不论什么类型的页,都会包含“页头”File Header和“页尾”File Trailer,介于这两者之间的“主体信息”会根据不同类型由不同的结构,最常用的是存储数据和索引的索引页,它的主题信息会使用数据“行”进行填充,“行”共分为4类,各有特点,以应对不同类型。行是最大为8KB但大小不固定的结构,主要包括表里每一行的真实数据和额外信息
当读写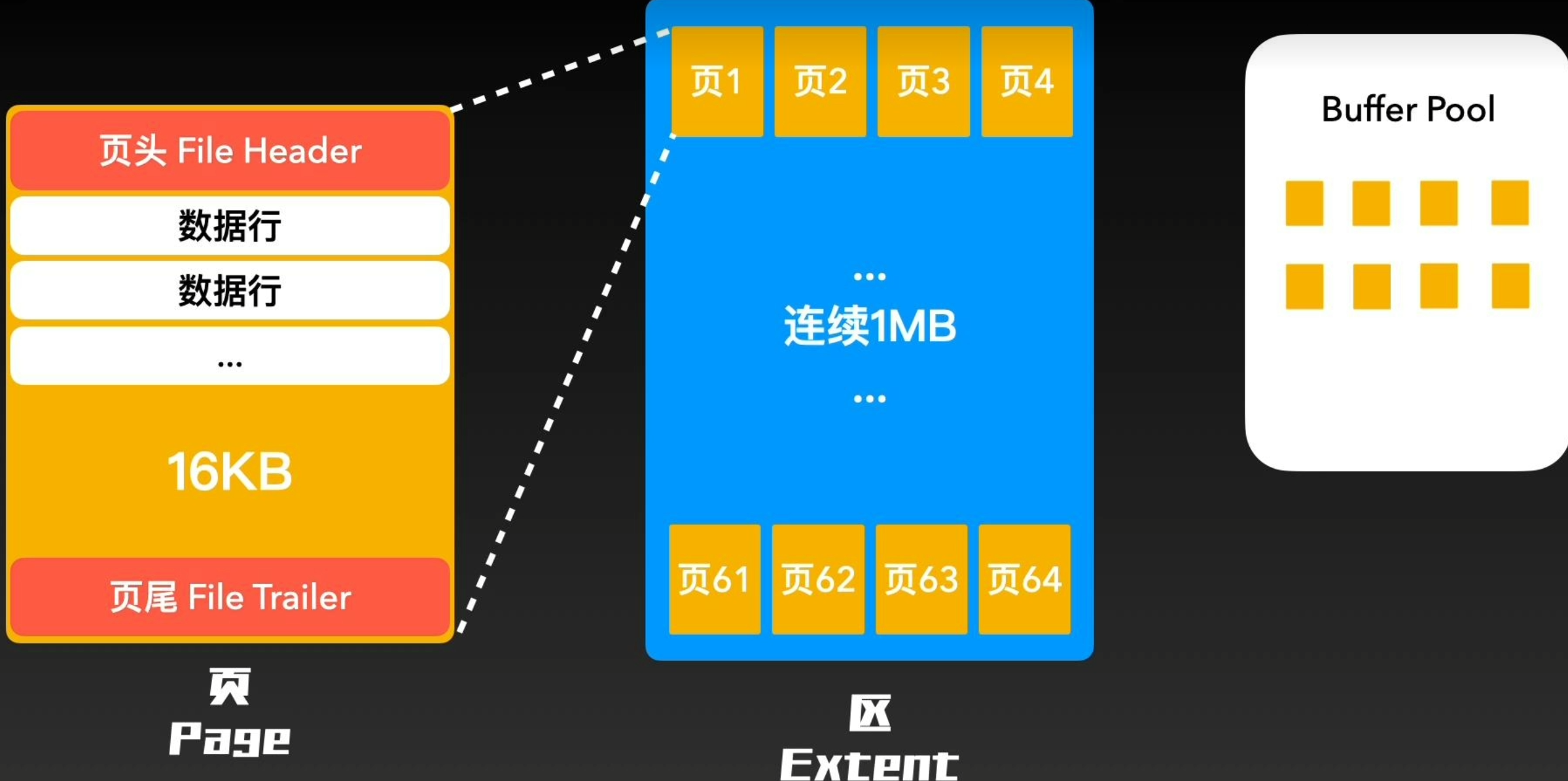 量较大时,跨“页”读取会十分平常,如果多个页物理地址差距过大,(对于机械磁盘)多份数据在磁盘中很可能处在不同磁道,就会发生磁头运动,大大降低性能。所以,使用“区”结构,每个区存放64个地址连续的“页”,这样即使发生跨页读取,大概率也在附近相关地址。同时,如果频繁读取某个区内的页,就可以将整个区内的页全部移入内存,减少后续查询对磁盘的访问次数
量较大时,跨“页”读取会十分平常,如果多个页物理地址差距过大,(对于机械磁盘)多份数据在磁盘中很可能处在不同磁道,就会发生磁头运动,大大降低性能。所以,使用“区”结构,每个区存放64个地址连续的“页”,这样即使发生跨页读取,大概率也在附近相关地址。同时,如果频繁读取某个区内的页,就可以将整个区内的页全部移入内存,减少后续查询对磁盘的访问次数
在新建表时,由于不知道后续数据量,为了减少空间浪费,InnoDB会创建6个页(8.0后为7个),并放在表中间的碎片区中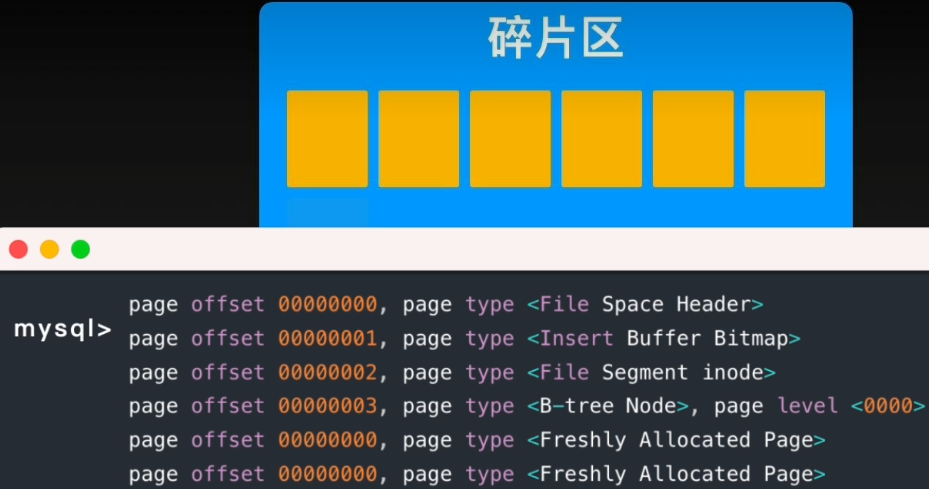
其中,后两个为空闲页,即可用页,前四个存储表空间和区组条目信息、change buffer相关信息,段信息,索引根信息
构建32个零散页后,后续会每次直接申请完整的区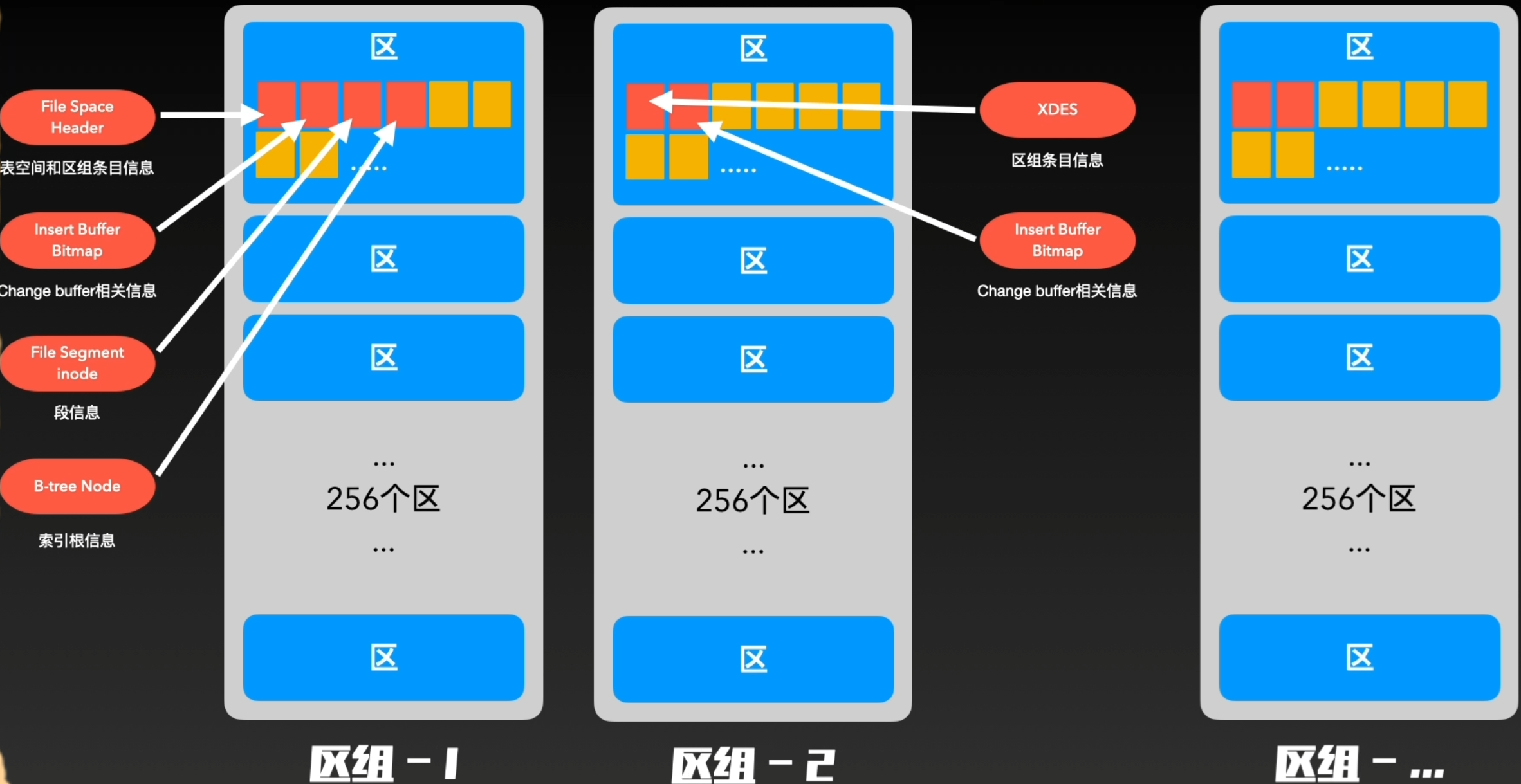
为了有效的管理区,还使用了“组”结构。每一个区组管理固定256个区。第一个区组前四个页较特殊,即6个初始页的前四个,其他区的前两个表均为XDES, Insert Buffer Bitmap。通过区组,可以在物理结构层面高效定位和管理每个区
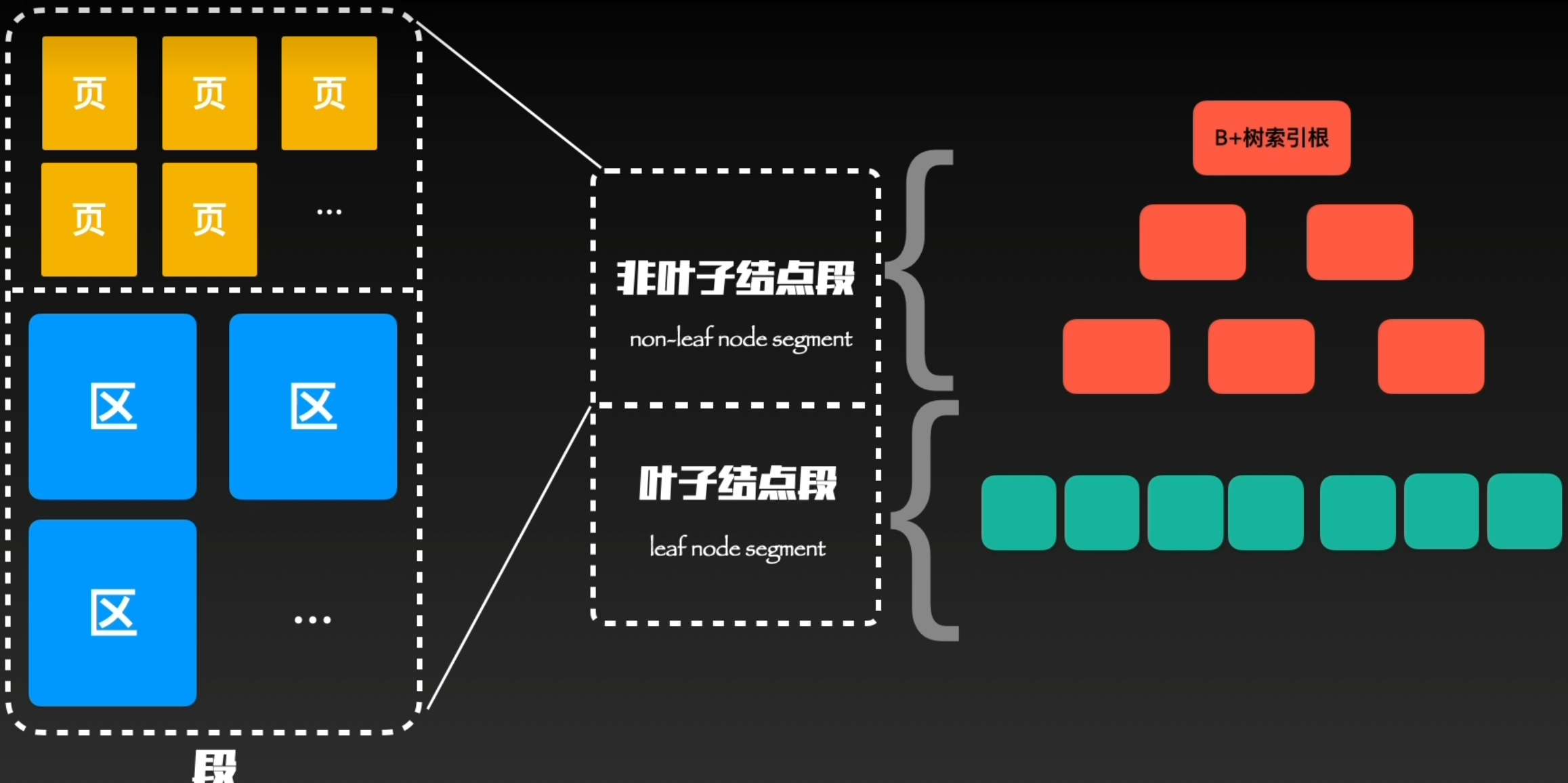
与区、区组不同,段是一个逻辑概念,并不对应连续的物理区域。
段的主要作用时用来区分不同功能区的“区”和在碎片区中的"页",分为非叶子节点段,叶子节点段。这两个段与冲说的B+索引中的叶子、非叶子节点相对应
简单理解为”非叶子节点段“存储和管理索引树,叶子节点段管理和存储实际数据

