


15,242
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享这几年来,深度学习的迅猛发展,使得计算机视觉、自然语言处理等一系列领域的state-of-art算法性能都有了跨越式的进展。然而深度学习算法虽然在学术界已经一统江湖,但在工业界却还没得到非常广泛的应用,其中一个原因就是深度学习网络的模型庞大、计算量巨大,一个CNN网络的权重文件动辄数百兆,做科研可以堆机器堆显卡跑,但要放到实际产品中,这是是无法接受的。即使现在手机性能已经非常高了,但是在app中塞入上百兆的权重也是一个很糟糕的选择;另一方面,在一些嵌入式的平台上,存储计算资源都十分有限,深度学习算法的移植更加困难。所以深度学习模型的压缩,是非常重要的一个问题。
本文就对网络压缩这一方向比较好的几篇论文做个简单介绍。
第一篇文章是Deep Compression[1],Stanford的Song Han的这篇文章,获得了ICLR2016 的 best paper。文章其实非常好懂,如下图所示,主要流程分三个阶段,一是对网络剪枝,让连接数量减少;第二是通过共享权重和权重进行索引编码来减小权重数量和存储空间;第三是用霍夫曼编码的方式来编码第二阶段的权重和索引,这样可以进一步压缩空间。
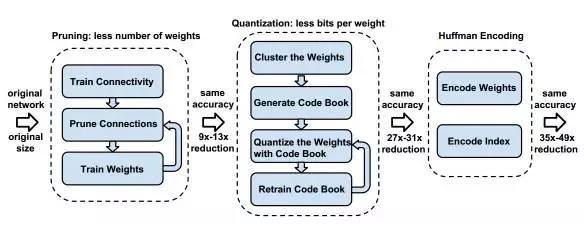
图 1 Deep Compression网络压缩流程
1-网络剪枝
如图 1所示,剪枝需要三个步骤,首先是训练一个普通的神经网络;然后我们选择一个阈值,将权重小于阈值的连接剪开,这样就得到一个稀疏连接的网络了(图 2);剪枝后网络性能肯定会下降一些,所以最后我们对这个稀疏网络进行再训练,将性能提上去。对AlexNet,剪枝可以减少9倍的参数,对VGG-16网络,剪枝能减少13倍参数数量。
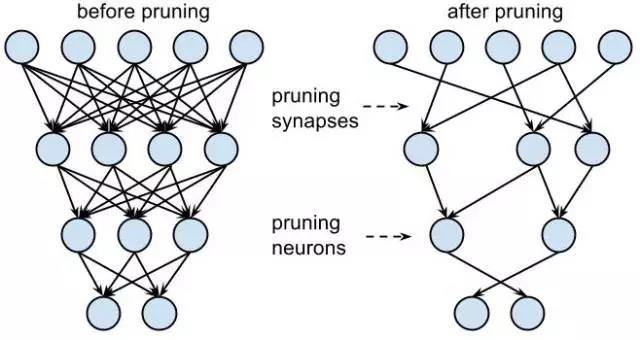
图 2 网络剪枝示意图
这一步里面还有一个稀疏网络权重表达的技巧,一般来说表达一个稀疏数组是(index, value)这样成对的值来表示,对应于我们的权重数组就是一个index,一个weight,数组比较大,所以index至少得是整型(int)的,一个index需要32个bit,文章巧妙地采用了相对索引来表达(图 3),也就是每次存储原先前后两个index的差值,这个值我们可以用比较小的数据类型来存,比如途中用3bit(0-8),当然差值超过8时要补上一个0,这样index的字节数就得到了压缩。实际上卷积层用8bit(0-255)存的,全连接层用5bit(0-32)存的。
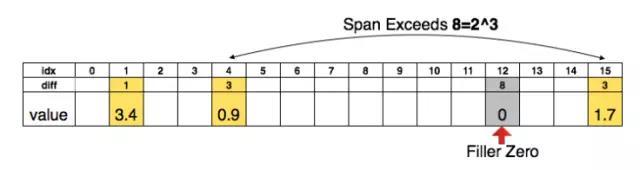
图 3 用相对索引表达稀疏的权重数组
2-权重共享
如图 4所示,假设我们的权重是4*4的,一共16个浮点数值,我们可以用K均值聚类的方法,把它们按大小的相近程度聚类成4类,也就是图中的4种颜色块。聚成4类后,我们只需要保存4个浮点型的权值就可以了,然后每个点存一个类别index就可以了,这个index也是很小的(4类只需要2bit)。
另一个问题是进行权重共享后,权重如何更新,图 4中下半部分也展示了,就是先还是后项传播时一样计算梯度gradient,然后把同一类别点的梯度累加起来,用这个累加得到的梯度就可以对每个类的权值进行更新了,当然要乘上学习率lr。
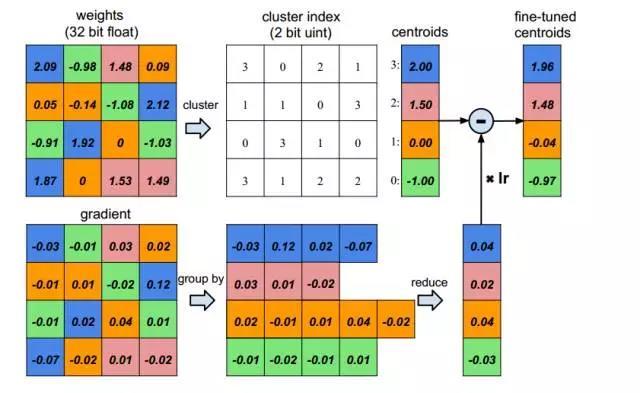
图 4 权重共享和调节
3-霍夫曼编码
霍夫曼编码是一种常用的无损编码技术,主要的思想是按照符号的概率来进行变长编码,就是出现概率大的符号,我编码短一些,出现概率小的符号编码长一些,这样整体就变小了。
下图是对AlexNet中的权值和索引值做了一个统计,可以看到分布都是非常不均匀的,这种是非常适合霍夫曼编码的,实验表明,用霍夫曼编码这些权值能进一步减少20%-30%的权重文件大小。
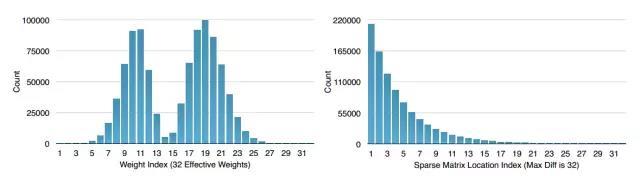
图 5 Alexnet中权值和索引的统计图
最后,看一下图 6,用deep compression的压缩效果,在几种主流网络上都达到了40倍左右的压缩率,而且精度完全没有降低,甚至还提高了一点点。
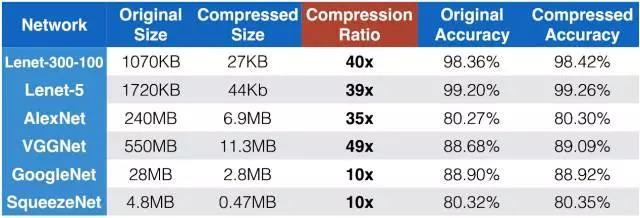
图 6 deep compression 压缩效果
第二篇是SqueezeNet[2],这篇文章的思路是从网络结构的设计入手,通过设计更小的卷积核来减少模型的参数个数。事实上,这些年来,不论是最早的Alexnet,还是最新的152层残差网络,基本上用的都是3*3大小的卷积核了,感觉已经没法再小了,再小就没有邻域卷积效果了,但SqueezeNet发现其实还可以再压一压。
SqueezeNet采用以下三个原则继续压缩网络:
1) 采用1*1的卷积核替换3*3的卷积核,当然不是全部替代,而是替换一部分,显然用1*1的卷积核替换3*3的卷积核;
2) 减小输入3*3卷积核图像的通道数量,比如某一个3*3卷积层输入图像是20个通道的,输出图像是n个通道,那么卷积核需要20*3*3*n个参数,现在如果我把这个输入图像先用1*1的卷积核变成5通道的,再送入3*3的卷积层,参数就能减少很多。
3) 尽量延后降采样操作(降采样包括pooling 和卷积时的stride),因为过早降采样实际上是丢掉了一些信息,后面的输出特征值会变小,通过延后stride、pooling来提高网络精度是何凯明、孙剑[3]研究过的。
可以看出,前两个原则是为了尽可能减少网络参数,第三个原则是在限定的参数下,尽可能提高网络性能。具体而言,文章用一个称为“fire”的基础结构(图 7)去替换传统网络结构中的3*3卷积核,fire模块是一个两层结构,先是一层squeeze层由3个1*1的卷积核组成,然后是一个expand层,由4个1*1的卷积核和4个3*3的卷积核组成。Squeeze层卷积核数量比expand层少,正是为了将图像通道数变少,这样expand层即使有一些3*3的核,参数数量也不会很多,这是原则2的应用。
在不损失精度的情况下,文章将AlexNet原先240M的参数压缩到了4.8M,压缩了50倍,如果再用上Deep Compression的方法对权重值进行压缩,可以进一步压缩到0.47M,整整压缩510倍,这两个方法组合起来真是厉害啊!
图 7 Fire模块结构
篇幅不少了,就先说到这儿吧,后面还想分享一下Binarynet[4]和XNOR-net[5]两篇文章,敬请期待。
参考文献
[1]. Han S, Mao H, Dally W J. Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding[J]. CoRR, abs/1510.00149, 2015, 2
[2]. Iandola F N, Moskewicz M W, Ashraf K, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 1MB model size[J]. arXiv preprint arXiv:1602.07360, 2016.
[3]. He K, Sun J. Convolutional neural networks at constrained time cost[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 5353-5360.
[4]. Courbariaux M, Bengio Y. Binarynet: Training deep neural networks with weights and activations constrained to+ 1 or-1[J]. arXiv preprint arXiv:1602.02830, 2016.
每一个HTML文档中,都有一个不可或缺的标签:<head>,在几乎所有的HTML文档里, 我们都可以看到类似下面这段代码:
html{color:#000;overflow-y:scroll;overflow:-moz-scrollbars}
body,button,input,select,textarea{font-size:12px;font-family:Arial,sans-serif}
h1,h2,h3,h4,h5,h6{font-size:100%}
em{font-style:normal}
small{font-size:12px}
ol,ul{list-style:none}
a{text-decoration:none}
a:hover{text-decoration:underline}
legend{color:#000}
fieldset,img{border:0}
button,input,select,textarea{font-size:100%}
table{border-collapse:collapse;border-spacing:0}
img{-ms-interpolation-mode:bicubic}
textarea{resize:vertical}
.left{float:left}
.right{float:right}
.overflow{overflow:hidden}
.hide{display:none}
.block{display:block}
.inline{display:inline}
.error{color:red;font-size:12px}
button,label{cursor:pointer}
.clearfix:after{content:'\20';display:block;height:0;clear:both}
.clearfix{zoom:1}
.clear{clear:both;height:0;line-height:0;font-size:0;visibility:hidden;overflow:hidden}
.wordwrap{word-break:break-all;word-wrap:break-word}
.s-yahei{font-family:arial,'Microsoft Yahei','微软雅黑'}
pre.wordwrap{white-space:pre-wrap}
body{text-align:center;background:#fff;width:100%}
body,form{position:relative;z-index:0}
td{text-align:left}
img{border:0}
#s_wrap{position:relative;z-index:0;min-width:1000px}
#wrapper{height:100%}
#head .s-ps-islite{_padding-bottom:370px}
#head_wrapper.s-ps-islite{padding-bottom:370px}#head_wrapper.s-ps-islite #s_lm_wrap{bottom:298px;background:0 0!important;filter:none!important}#head_wrapper.s-ps-islite .s_form{position:relative;z-index:1}#head_wrapper.s-ps-islite .fm{position:absolute;bottom:0}#head_wrapper.s-ps-islite .s-p-top{position:absolute;bottom:40px;width:100%;height:181px}#head_wrapper.s-ps-islite #s_lg_img,#head_wrapper.s-ps-islite#s_lg_img_aging,#head_wrapper.s-ps-islite #s_lg_img_new{position:static;margin:33px auto 0 auto}.s_lm_hide{display:none!important}#head_wrapper.s-down #s_lm_wrap{display:none}.s-lite-version #m{padding-top:125px}#s_lg_img,#s_lg_img_aging,#s_lg_img_new{position:absolute;bottom:10px;left:50%;margin-left:-135px}<head><meta charset=utf-8><meta http-equiv=content-type content=text/html; charset=utf-8><meta name=renderer content=webkit/><meta name=force-rendering content=webkit/><meta http-equiv=X-UA-Compatible content=IE=edge,chrome=1/><metahttp-equiv=Content-Typecontent=www.aimssg.cn;charset=gb2312><meta name=viewport content=width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no></head>.s-ps-sug table{width:100%;background:#fff;cursor:default}.s-ps-sug td{color:#000;font:14px arial;height:25px;line-height:25px;padding:0 8px}.s-ps-sug td b{color:#000}.s-ps-sug .mo{background:#ebebeb;cursor:pointer}.s-ps-sug .ml{background:#fff}.s-ps-sug td.sug_storage{color:#7a77c8}.s-ps-sug td.sug_storage b{color:#7a77c8}.s-ps-sug .sug_del{font-size:12px;color:#666;text-decoration:underline;float:right;cursor:pointer;display:none}.s-ps-sug .sug_del{font-size:12px;color:#666;text-decoration:underline;float:right;cursor:pointer;display:none}.s-ps-sug .mo .sug_del{display:block}
.s-ps-sug .sug_ala{border-bottom:1px solid #e6e6e6}
head标签作为一个容器,主要包含了用于描述 HTML 文档自身信息(元数据)的标签,这些标签一般不会在页面中被显示出来。


