


1,537
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享Schema 设计的三大基本原则:
而三者并不冲突,上面三点其中某一点做得很好,另外两点也会做的不错。
Talking is cheap,下面我们来结合具体的例子来了解下三大原则。
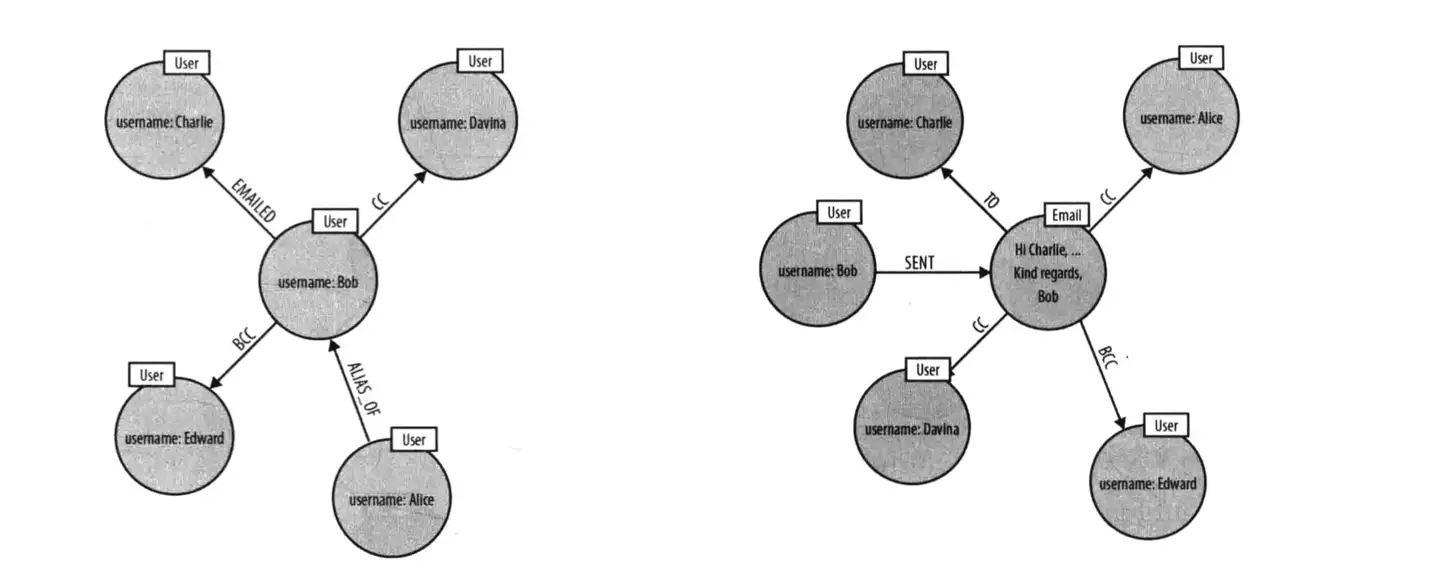
如何设计一个高性能的 schema
上图是 Neo4j 图数据库书籍中的示例图。简单描述下这个场景,Bob 和 Charlie 等人在发邮件。那你设计这么一个场景的 Schema 是否很自然就会将发邮件变成关系边?因为 Bob 同 Charlie 发邮件,不是很明显就是发邮件关系吗?那我们来回顾下上面说的三大原则第一点:尊重领域实体关系。Bob 和 Charlie 建立联系自然不是通过发邮件这个行为,而是通过邮件本身来建立联系,所以这里便缺少了一个实体。在考虑可视化分析原则这边,你要分析实体之间的关系,你思考它们是通过什么来建立的联系。这时候就会发生之前提到过的发邮件设置为边的情况(把邮件放置在边上),单看 Bobo 的话(左图),我们可以清楚地看到发邮件这个动作。左图上面部分,Bobo Emailed Charlie。但如果这时候,要查看这个邮件抄送给了谁,还有这封邮件有哪些相关人,像左图的 schema 就不能很好地进行查询。因为缺少了 Email 这个实体。而上图右侧部分便能可以方便地找寻相关信息。
下面再来讲下如何进行实体和属性选择。
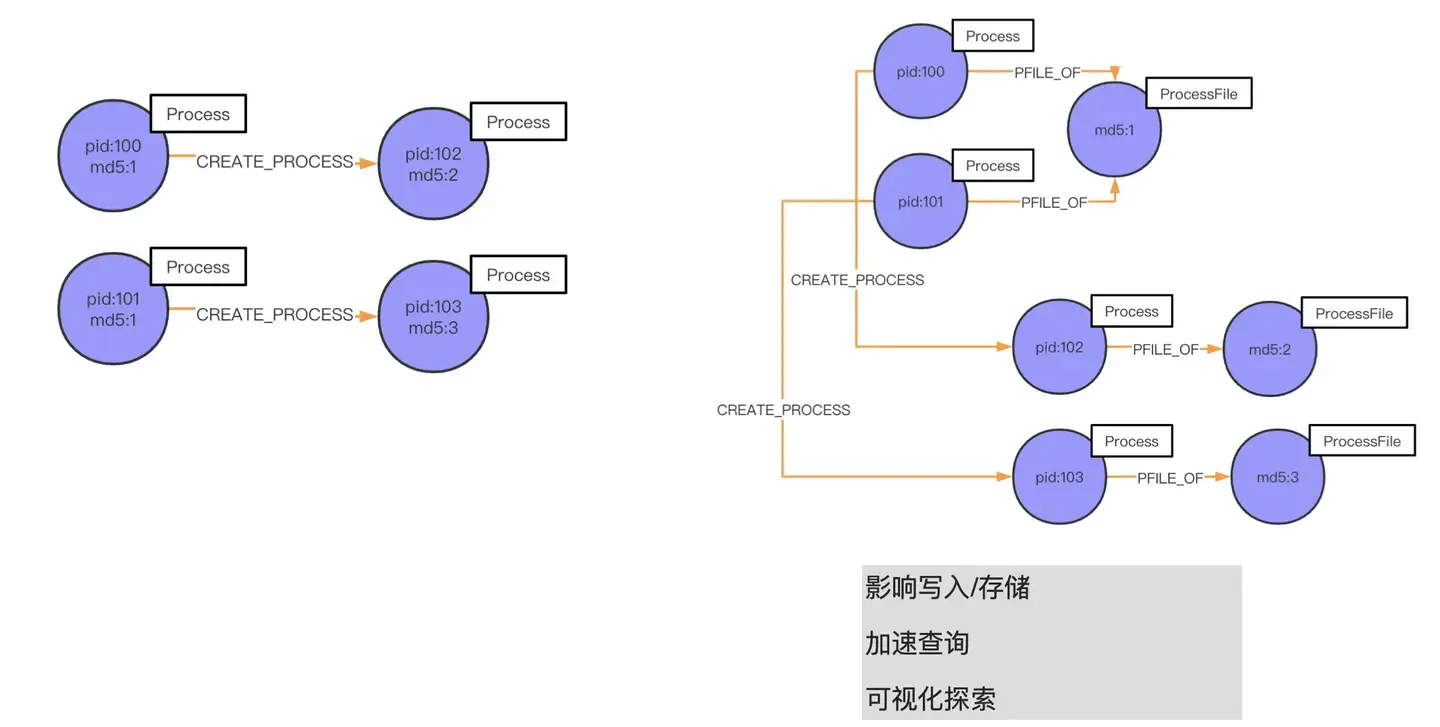
如何设计一个高性能的 schema
在这个部分,我将结合青藤云的情况来讲一个我们的 case——进程之间的父子关系。
如上图左侧所示,md5 为 1 的 pid 100 进程起了一个 pid 102 的子进程,这个子进程的 md5 是 2。同时,md5 也为 1 的 pid 101 也起了进程,pid 为 103、md5 为 3。按照我们之前的实现方法,是在 md5 上创建索引,继而建立起跟 pid 102、pid 103 的联系。但这种做法,上面讲过性能并不高,免索引复杂是 O(1),而这种做法的复杂度是 O(logn)。所以说,我们这时候应该基于 ProcessFile 进程文件 md5 来建立关系(进程间是基于 md5 联系起来的):我们先抽取 md5 建立一个名叫 ProcessFile 的实体,属性是 md5。如果我们要查询指定进程所关联的进程,很直观地去找寻和这个 ProcessFile 关联的进程就可以分析出来我们要的结果。举个例子,pid 102 的进程是一个木马,我想找寻是哪个父进程释放的它,或者是同它父进程同 md5 文件的进程,该怎么找?
上图的展示了两种形式,第一种(左侧)的话就需要找索引;第二种(右侧)通过 CREATE_PROCESS 就可以直接找到 pid 102 的父进程 pid 100,再通过 PFILE_OF 关系你可以找到它同 md 文件的进程 pid 101。
好的,简单结合 Schema 设计三大原则来回顾下这个 case:
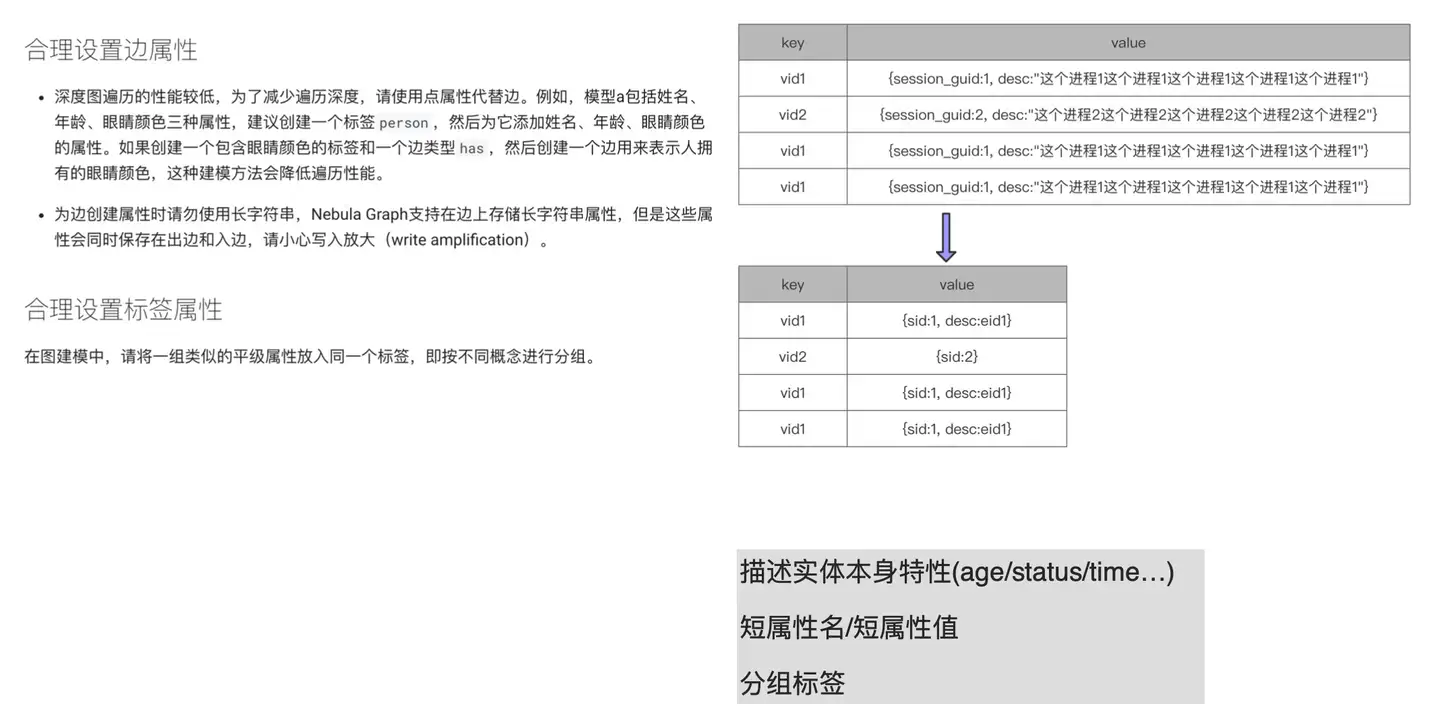
如何设计一个高性能的 schema
上图左边描述文字截自 v2.0 的官方文档:https://docs.nebula-graph.com.cn/2.0/3.ngql-guide/1.nGQL-overview/2.graph-modeling/#_3。
在合理设置边属性的第二部分提到,“为边创建属性时请勿使用长字符串”。这个和我们之前提到过的,属性名和属性值都应该短,不应该长是一个意思。像上图右侧部分,很明显可以看到 vid 重复写多次的话,每次写就是重复的流量和存储,这会大大增大内存占用和磁盘容量。如果我们把 session_guid 变成 sid 会节约很多存储。而后面的描述信息,也有两种处理方式。第一种,直接删除描述;第二种,将过长的描述存储在外部,比如放置在 Elasticsearch,然后将 ES 存储这块内容的 eid 存储在上图的 value 中。这样也可以大大减少存储量,提升写入 / 查询性能。
除了这点之外,我们还要注意合理设置分组标签。青藤云暂时没遇到类似 case,所以这里讲下这句话什么意思。简单来说,就是写入这边需要做一个 tag 的区分,结合上文提到的二分查找,你就比较好理解了。举个简单例子,这里有个人,他的公司相关信息,或者年龄相关的信息,或者是个人喜好之类的信息用相关的 tag 区分开,这样查询时可以更快地找到对应的信息。
最后回到文档「合理设置边属性」中第一部分中的“深度图遍历的性能较低,为了减少遍历深度,请使用点属性代替边。例如,模型 a 包括姓名、年龄、眼睛颜色三种属性,建议您创建一个标签 person,然后为它添加姓名、年龄、眼睛颜色的属性。”,按照官方的举的例子,固然是这样的。但实际应用中,并非一定要遵循这一原则——属性用点属性而不是用边,该用实体的时候还是得用实体。所以我这里下面备注写了:描述实体本身特性。像实体本身的特性 age / status,边的 time / count 这些属性会变成相对应的属性,这样能更好地描述本质特性,也能起到比较好的辅助效果。
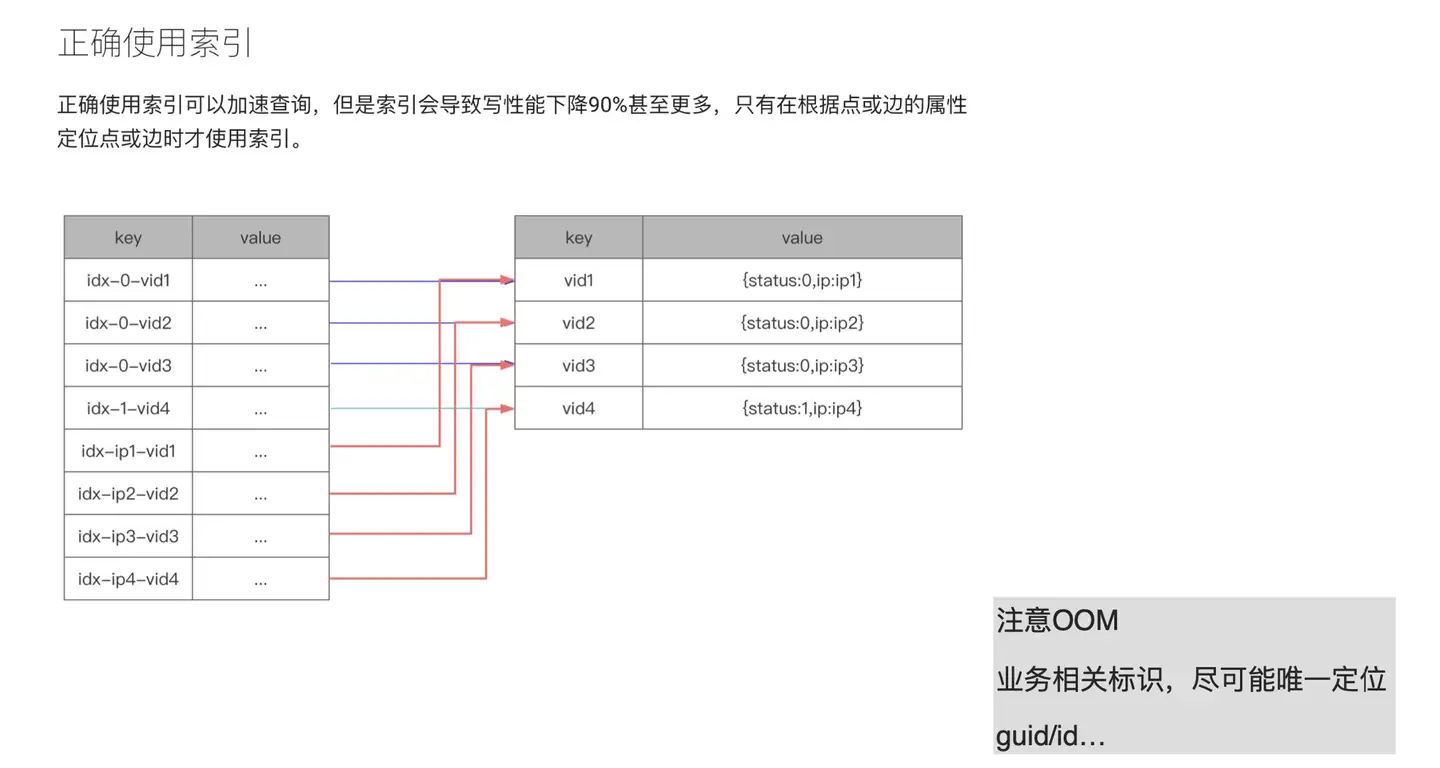
如何设计一个高性能的 schema
借助之前我们的实践经验,来讲下索引这块内容。在 NebulaGraph 的官方文档中提及了:尽量少用索引。那么问题来了,到底什么时候应该用索引呢?我们先从原理上来解释下索引。在上图的例子中,value 中存储了 2 样东西:一个是 status,状态;另外一个是 ip。右侧的表格是对应的 kv 存储结构,key 是个点结构。给点加索引之后,它便会变成左侧表格的结构,idx-x-vid1。如果我们要查询 status 等于 0 的这列值的时候,由于加了索引之后数据结构是以 0(status)为前缀,vid 放在 0 后面;如果我们要查询 ip 的话,存储结构则将 ip 变成前缀,vid 存储在后面。这样会产生何种问题呢?status 如果只有 1 和 0,现在你有 1 万亿的点,这样添加索引是没有意义的。而且,因为 NebulaGraph 的查找是二分查找,复杂度收敛到 O(n),相当于有多少数据就查多少数据。即便你添加了一个 limit,但是在 NebulaGraph 这边(注:本次分享时,NebulaGraph 的最新版本为 v2.0.1)limit 并没有下推,所以所有数据会先捞上来到计算层,在内存中使用 limit 进行数据过滤。
正是由于这种情况,所以在 v2.5 之前的 NebulaGraph 用户会经常在论坛反馈 OOM 问题,其实就是内存爆炸。
所以说,索引应该是尽可能和业务相关的标识。
如何设计一个高性能的 schema
通过上面的 Neo4j 这个 case 我们来讲解下颗粒度问题。
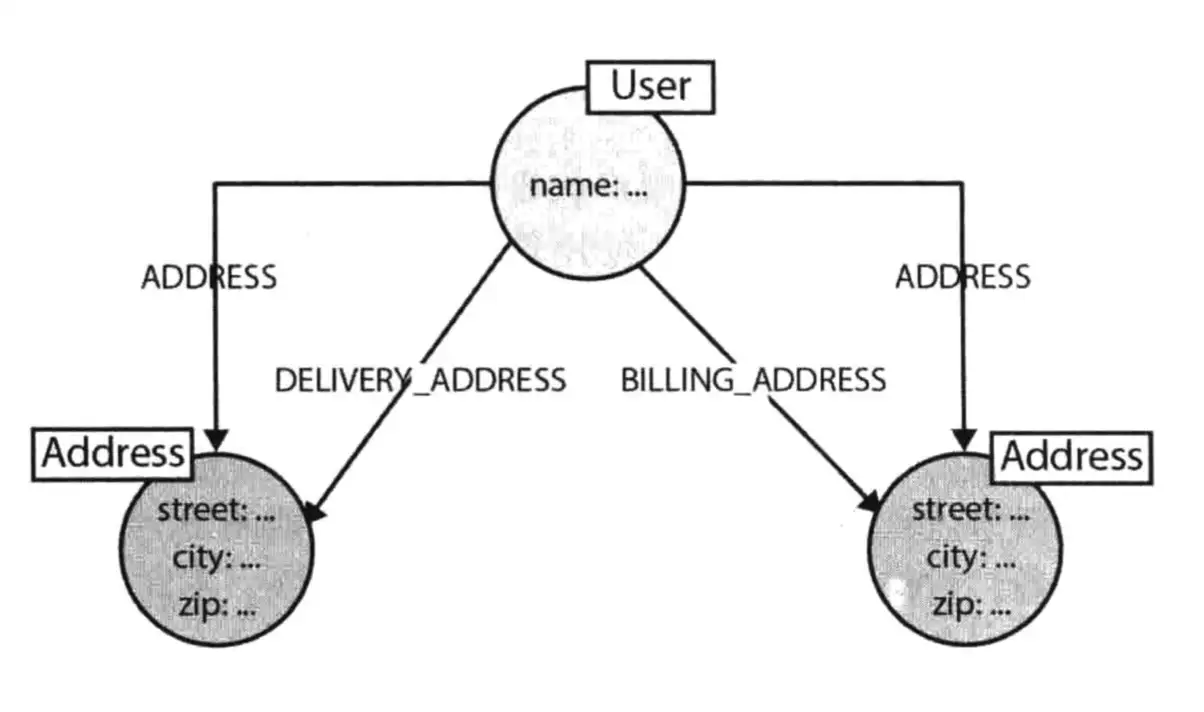
像上面的人有 2 个地址,一个是收件地址,另外一个是付款地址。如果此时,我们想找寻这个人的地址,如果没有 ADDRESS 这个通用标签的话,DELIVERY_ADDRESS 和 BILLING_ADDRESS 这两个关系都得查下。这时候如果用的是二分查找,如果这堆关系本身存储在一起还好,可以一次性查找出来;但,如果关系不在一起,就需要分 2 次查询,这会降低它的查询速率。
因此,我们可以再创建一个通用标签,但是要注意的是,标签的建立是基于对某个业务有强需求。像上面的例子,需要知道用户的所有地址,也要知道他的单独地址,比如:收件地址。这种情况下,建立一个通用标签才是一个加速的方法,但注意要谨慎使用。同样的,通用标签设计时,也需要考虑可视化的情况。
如何设计一个高性能的 schema
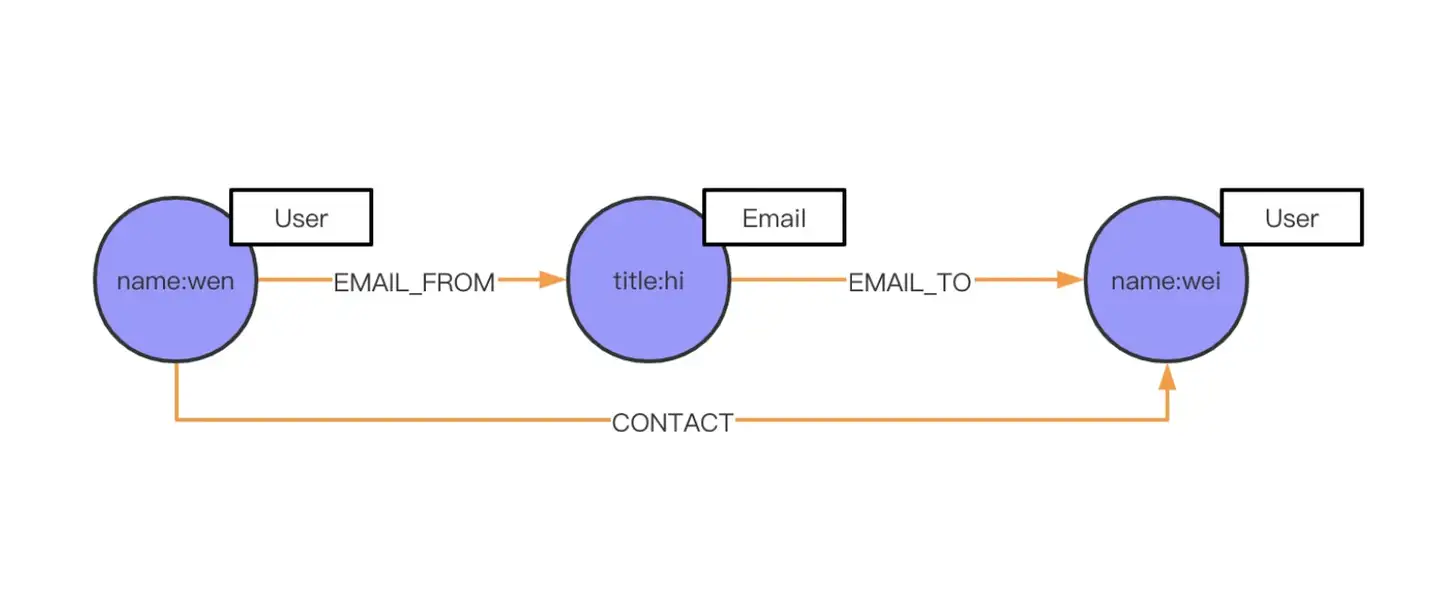
之前我们讲过一个发邮件的例子,但是现在场景有所变化了,我现在不关心发邮件这个事情,我只关心人和人之间的关系,比如,wen 这个人的联系关系,有谁和他联系过,而这个联系方式可能是 Email,也可能是手机(Phone),或者是微信。这时候我应该如何设计 schema 呢?当然之前的设计是可以沿用的,但为了加速查询,满足业务上的需求。这里加了 CONTACT 属性,用来加速查找。
讲到这里,我们总结下上面的例子,其实我们的例子都是围绕着三大原则来展开的,即:性能、可视化、领域关系。

