16
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。需要注意的是KNN算法是监督学习中的分类算法,看起来和它的兄弟Kmeans算法有点像。KNN算法它的类别都是已知的,通过对已知分类的数据进行训练和学习,找到这些不同类的特征,在对未分类的数据进行分类。而kmeans算法属于非监督学习,我们事先是不知道数据会分为几类,通过聚类分析后将数据合成几个群体。
K-近邻算法(KNN)算法实现简单、高效。在分类、回归、模式识别等方面有着广泛的应用。该方法的思路是:在特征空间中,如果一个样本附近的k个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。就比如经常和我一块玩的人有10个人,他们中有6个人是好人,有1个人是比较坏的,有3个人又好又坏的,那么大家就认为我也是个好人,通过我接触某个类型的多少以此来给我定性。对应中国的古话:“近朱则赤,近墨者黑”。所以这个K的取值是很重要的,
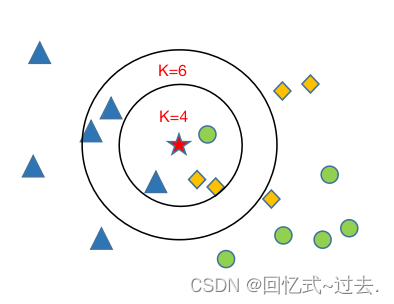
上图中圆环就是K的取值范围,当K的取值是4时,K被分到黄色一栏,当K的取值是6时,K被分到蓝色一栏.
通过上图我们知道K的取值是很重要的,那么我们该如何确定K的取值呢?在KNN中K是一个超参数,需要我们进行指定,一般情况下这个k和数据有很大关系,都是交叉验证进行选择,但是建议使用交叉验证的时候,k∈[2,20],使用交叉验证得到一个很好的k值。需注意最好K的取值为奇数,防止出现平票而无法分类的情况。
k值还可以表示我们的模型复杂度,k值越小,意味着模型复杂度变大,更容易过拟合(用极少数的样例来绝对这个预测的结果,很容易产生偏见,这就是过拟合)。k值越大,学习的估计误差越小,但是学习的近似误差就会增大,容易造成欠拟合。
度量空间中点距离有好几种度量方式,比如常见的曼哈顿距离计算,欧式距离计算等等。通常KNN算法中采用的是欧式距离,二维空间两个点的欧式距离计算公式如下:
欧氏距离:
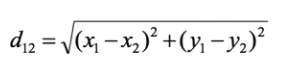
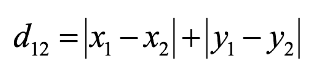
优点
缺点
输入:
算法:
输出:
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
from pylab import *
import openpyxl
datafile = '/Users/desktop/leastsquare.xlsx'
def knn(train_data, testdata, data_tag, k):
# 将数组统一化
# 将输入数据平铺为train_data_size行1列,便于与训练数据做差
new_testtdata = np.tile(test_data, (train_data.shape[0], 1))
new_testtdata = new_testtdata - train_data
new_testtdata = new_testtdata ** 2
new_testtdata1 = new_testtdata.sum(axis=1)
new_testtdata1 = new_testtdata1 ** 0.5 # 欧氏距离
# new_testtdata1 = pow(new_testtdata1,0.5)
# 将欧氏距离排序,返回对应的索引值
sortdata = np.argsort(new_testtdata1)
# 统计前k个类型数量
count = {}
for i in range(k):
vote = data_tag[sortdata[i]] # 第i个距离对应的标签
count[vote] = count.get(vote, 0) + 1 #统计某个标签个数
sortdata = sorted(count.items(), key=lambda x: x[1], reverse=True)
return sortdata[0][0], test_data
def Read_data():
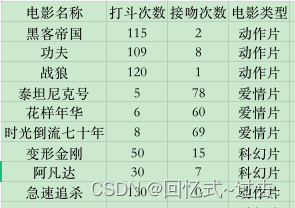
data = pd.read_excel(datafile, index_col=u'电影名称', sheet_name='knn_data2')
x = data[u'打斗次数'].tolist()
y = data[u'接吻次数'].tolist()
# z = data[u'z'].tolist()
b = data[u'电影类型'].tolist()
return x, y, b
x, y, b = Read_data()
def write_data(write_test_data, write_test_tag):
"""
:param write_test_data: 将测试数据写入文件
:param write_test_tag: 将预测后的标签写入文件
:return:
"""
# 打开Excel文件
workbook = openpyxl.load_workbook(datafile)
# 选择工作表
worksheet = workbook['knn_data2']
# 在指定单元格中写入数据
worksheet['A{}'.format(int(len(x)) + 2)] = int(len(x)) + 2
worksheet['B{}'.format(int(len(x)) + 2)] = write_test_data[0]
worksheet['C{}'.format(int(len(x)) + 2)] = write_test_data[1]
worksheet['D{}'.format(int(len(x)) + 2)] = write_test_tag
# 保存Excel文件
workbook.save(datafile)
# 调用matplotlib实现散点图
def Show():
'''
plt.scatter(x, y, c=b,cmap='viridis')
plt.show()
'''
# mpl.rcParams['font.sans-serif'] = ['SimHei']
tag1, data1 = knn(train_data, test_data, data_tag, k)
write_data(data1, tag1)
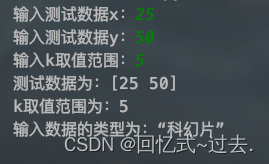
print('测试数据为:{}\n'
'k取值范围为:{}\n'
'输入数据的类型为:“{}”'.format(test_data, k, tag1))
# 添加颜色列表
colourlist = []
for i in b:
if i == '动作片':
colourlist.append('black')
if i == '科幻片':
colourlist.append('orange')
if i == '爱情片':
colourlist.append('red')
if tag1 == '动作片':
colourlist1 = ['black', 'Testdata is Action movie']
if tag1 == '科幻片':
colourlist1 = ['orange', 'Testdata is Science fiction film']
if tag1 == '爱情片':
colourlist1 = ['red', 'Testdata is Romantic film']
# 画出图表
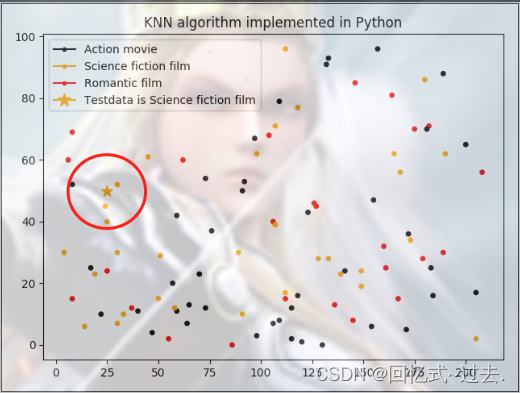
plt.title("KNN algorithm implemented in Python")
plt.ion()
plt.scatter(x, y, c=colourlist, s=15)
plt.scatter(data1[0], data1[1], c=colourlist1[0], marker='*', s=100)
didntLike = mlines.Line2D([], [], color='black', marker='.',
markersize=6, label='Action movie')
smallDoses = mlines.Line2D([], [], color='orange', marker='.',
markersize=6, label='Science fiction film')
largeDoses = mlines.Line2D([], [], color='red', marker='.',
markersize=6, label='Romantic film')
testdata = mlines.Line2D([], [], color=colourlist1[0], marker='*',
markersize=12, label=colourlist1[1])
# 添加图例
plt.legend(handles=[didntLike, smallDoses, largeDoses, testdata])
plt.show()
if __name__ == '__main__':
train_data = np.array(
[i for i in zip(Read_data()[0], Read_data()[1])]
)
data_tag = np.array(Read_data()[2])
test_x = int(input("输入测试数据x:"))
test_y = int(input("输入测试数据y:"))
test_data = np.array([test_x, test_y])
k = int(input("输入k取值范围:"))
Show()