


118
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享(1.1)在Github仓库中新建一个学号为名的文件夹,同时在博客正文首行给出作业Github链接。
链接:https://github.com/aaadachen/102101307./tree/master/102101307
| PSP2.1 | 预估耗时(分钟) | 实际耗时(分钟) | |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 5 | 10 |
| Development | 开发 | -- | -- |
| · Analysis | · 需求分析 (包括学习新技术) | 180 | 180 |
| · Design Spec | · 生成设计文档 | 20 | 15 |
| · Design Review | · 设计复审 | 5 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| · Design | · 具体设计 | 60 | 60 |
| · Coding | · 具体编码 | 180 | 300 |
| · Code Review | · 代码复审 | 20 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 120 | 180 |
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 60 |
| · 合计 | 760 | 1040 |
(3.1)项目设计与技术栈。从阅读完题目到完成作业,这一次的任务被你拆分成了几个环节?你分别通过什么渠道、使用什么方式方法完成了各个环节?列出你完成本次任务所使用的技术栈。(5')
拆分成了5个环节,分别是:
1. 阅读题目,明确需要完成的任务。
2. 编写python代码,爬b站视频的弹幕,先获取这300个视频的bvid,然后转换成cid,得到每个视频的弹幕地址,根据这个弹幕地址获取每一条弹幕,写入text文本中。
3. 编写python代码, 统计每种弹幕数量,并按照降序排列把弹幕和对应的数量自动写入excel表格中,读取excel表格,获取弹幕对应列表的前二十个数据进行输出。
4. 编写python代码,读取弹幕的text文件,编写词云图。
5. 检查代码,撰写博客。
技术栈:主要用到了几个爬虫的库,requests,pandas,jieba,wordcloud等等
(3.2)爬虫与数据处理。说明业务逻辑,简述代码的设计过程(例如可介绍有几个类,几个函数,他们之间的关系),并对关键的函数或算法进行说明。(20')
代码总共调用了三个函数,分别是get_bvid(v_keyword,v_max_page),excel_danmu(),cloud(),主要功能分别是获取所有弹幕数据,对弹幕数据进行统计并与excel表格联系起来,绘制词云图。这三个函数的联系主要是excel_danmu()和cloud()功能的实现需要打开get_bvid(v_keyword,v_max_page)得到的'zong弹幕.txt'。
接下来介绍这三个函数:
1.首先调用函数get_bvid(v_keyword,v_max_page)爬取每个视频的bvid号,得到cid号,获取弹幕地址,把得到的弹幕数据写入文本里:
def get_bvid(v_keyword,v_max_page):#获取bvid号和cid号,然后获取弹幕
for page in range(1,v_max_page+1):
url = 'https://api.bilibili.com/x/web-interface/wbi/search/type'
headers = {
'Accept': 'application / json, text / plain, * / *',
'Cookie': ''太长了就不复制过来了 '',
'Referer': '太长了就不复制过来了',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
}#请求头
params = {
'__refresh__': 'true',
'_extra': '',
'context: ': '',
'page': page,
'page_size': 30,
'from_source': '',
'from_spmid': '333.337',
'platform': 'pc',
'highlight': '1',
'single_column': '0',
'keyword': v_keyword,
'qv_id': 'cpMVbw8zVemJGJvGYYMOebJCmI59wcxs',
'ad_resource': '5654',
'source_tag': '3',
'gaia_vtoken': '',
'category_id': '',
'search_type': 'video',
'dynamic_offset': 36,
'web_location': '1430654',
'w_rid': 'd4218a3244a08402538973f95d2b2887',
'wts': '1694605881'
}
r = requests.get(url,headers=headers,params=params)
j_data = r.json()
data_list = j_data['data']['result']
for index in data_list:
bvids = index['bvid']#为每一个视频的bvid号
#print(bvids)
url1 = f'https://api.bilibili.com/x/player/pagelist?bvid={bvids}&jsonp=jsonp'#获取每一个视频的地址
t1 = requests.get(url=url1, headers=headers)
t2 = t1.text
s3 = '"cid":'
cout3 = t2.find(s3)
cid = t2[cout3 + 6:cout3 + 16]
url2 = 'https://api.bilibili.com/x/v1/dm/list.so?oid={}'.format(cid)#获取每一个视频的弹幕地址
#print(url2)
res = requests.get(url=url2, headers=headers)
res.encoding = res.apparent_encoding
#把弹幕写进txt文本
data_list = re.findall('<d p=".*?">(.*?)</d>', res.text)
for dan in data_list:
with open('zong弹幕.txt', mode='a', encoding='utf-8') as f:
f.write(dan)
f.write('\n')
#print(dan)
2.然后调用函数excel1-danmu(),把打开存放弹幕的‘zong弹幕.txt',把弹幕和出现的次数按降序写入excel表格中,再调用excel表格,找到弹幕的列,根据对应的出现次数输出排名前20的弹幕
def excel_danmu(): #把弹幕读入excel表格并输出前20个
with open('zong弹幕.txt', 'r', encoding='utf-8') as file:
text = file.read().splitlines()
# 统计元素出现次数
counts = Counter(text)
# 转换为DataFrame并按降序排列
df = pd.DataFrame(list(counts.items()), columns=["Element", "Count"])
df = df.sort_values("Count", ascending=False)
# 写入Excel表格
df.to_excel("总results.xlsx", index=False)
# 读取Excel文件
df = pd.read_excel('总results.xlsx')
# 获取弹幕对应列表的前二十个数据进行输出
column_data = df['Element'].head(20)
print(column_data)
3.最后调用函数cloud()绘制词云图
def cloud(): #绘制词云图词yun
f = open('zong弹幕.txt', encoding='utf-8')
text = f.read()
text_list = jieba.lcut(text) # 进行分词
text_str = ''.join(text_list)
# 接下来为词云图配置
wc = wordcloud.WordCloud(
width=500, # 宽度
height=500, # 高度
background_color='white', # 背景颜色
stopwords={'了', '的', '啊', '是', '吧'}, # 停用字,词云图不会显示
font_path='msyh.ttc', # 字体颜色
mask = img,
collocations = False#防止词云图出现重复单词
)
wc.generate(text_str)
wc.to_file('词yuntu.png')
(3.3)数据统计接口部分的性能改进。记录在数据统计接口的性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(例如可通过VS /JProfiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。(6')
(3.4)数据结论的可靠性。介绍结论的内容,以及通过什么数据以及何种判断方式得出此结论(6')
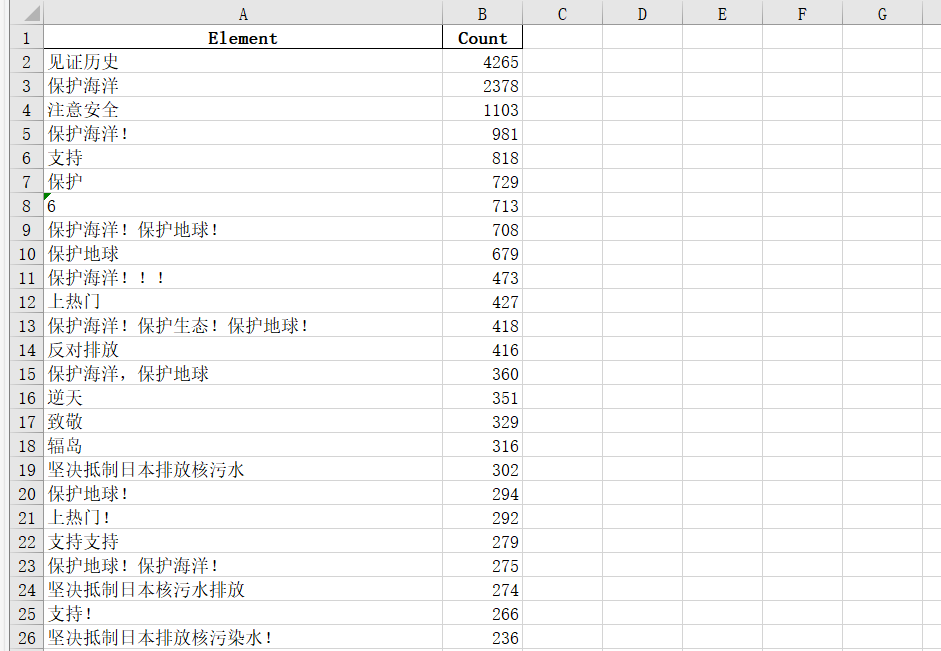
结论:分析excel表格,可以看出弹幕里人民群众还是很反感日本排放核污染水这一举动的,弹幕’保护海洋‘、’保护地球‘、‘反对排放’、‘坚决抵制’等字眼居多,坚持抵制日本排放核污染水,日本这一行为是为人所不齿的,我们都要好好保护环境,爱护海洋。
(3.5)数据可视化界面的展示。在博客中介绍数据可视化界面的组件和设计的思路。(15')
展示一下得到的词云图,是一个云朵的形状。用到python的jieba库进行弹幕的分词,wordcloud库来画词云图,numpy库来处理词云图背景图像数据

一开始其实只懂得一点python知识,刚看到题目的时候只懂得爬虫,而且爬虫也是能简单爬一点网页图片什么的,爬300个视频的弹幕一听就感觉好难,而且词云图还有用代码实现调用excel表格都没听说过,但是后面通过b站、csdn等渠道终于把代码写出来了,感觉过程确实很艰辛,但是又学会了一个技能,也多了解python几个库的功能,受益匪浅。


