



118
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享 (1.1)在Github仓库中新建一个学号为名的文件夹,同时在博客正文首行给出作业Github链接。
https://github.com/dhr-del/102101205
●(2.1)在开始实现程序之前,在附录提供的PSP表格记录下你估计将在程序的各个模块的开发上耗费的时间。**
●(2.2)在你实现完程序之后,在附录提供的PSP表格记录下你在程序的各个模块上实际花费的时间。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 580 | 560 |
| Development | 开发 | 420 | 520 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 30 |
| · Design Spec | · 生成设计文档 | 60 | 30 |
| · Design Review | · 设计复审 | 20 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 10 |
| · Design | · 具体设计 | 120 | 180 |
| · Coding | · 具体编码 | 180 | 180 |
| · Code Review | · 代码复审 | 60 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改 | 60 | 30 |
| Reporting | 报告 | 120 | 60 |
| · Test Report | · 测试报告 | 30 | 20 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 10 |
| 合计 | 580 | 600 |
●(3.1)项目设计与技术栈(从阅读完题目到完成作业,这一次的任务被你拆分成了几个环节?你分别通过什么渠道、使用什么方式方法完成了各个环节?列出你完成本次任务所使用的技术栈。)
本次任务被我拆分成了4个环节,分别为:爬虫、数据分析、可视化处理
爬虫:这方面因为之前从来没有接触过,所以需要花额外的时间去看视频学习,了解爬虫基本过程,可以 通过B站、CSDN、github等学习
数据分析:利用python语言将爬取到的弹幕数据整理分析,以及预测未来趋势
可视化:包括制作词云图,制作柱状图,这部分主要注重美观
三个环节用到的python技术栈:
●requests库
●re库
●selenium库
●Counter库
●jieba库
●pandas库
●csv库
●wordcloud库
●datetime库
●(3.2)爬虫与数据处理(说明业务逻辑,简述代码的设计过程(例如可介绍有几个类,几个函数,他们之间的关系),并对关键的函数或算法进行说明。)
1.一些功能函数
① get_bv() #用于获得300个视频的BV号
因为B站使用了大量的 JavaScript 技术来动态渲染内容,而只使用传统的 HTTP 请求和解析工具只会返回None。在大量尝试后,最后我选择使用浏览器驱动器来处理 JavaScript 渲染,它可以提供改链接的完整代码。具体实现如下:
sum_bv = []
def get_bv(urls):
# 配置Microsoft Edge浏览器的驱动路径
driver_path = 'D:\Download\AppGallery\python\MicrosoftWebDriver.exe'
# 创建Microsoft Edge浏览器的选项
edge_options = EdgeOptions()
edge_options.use_chromium = True
edge_options.add_argument('--headless') # 无头模式
# 创建Microsoft Edge浏览器驱动
driver = Edge(executable_path=driver_path, options=edge_options)
for url in urls:
# 打开网页
driver.get(url)
# 等待页面加载完全
time.sleep(3)
# 获取页面源代码
html = driver.page_source
per_bv = re.findall(r'(BV.{10})', html)
# 去重
for a in per_bv:
sum_bv.append(a)
# 关闭浏览器驱动
driver.quit()
return sum_bv
② get_dm_url(bv) #已知一个视频的BV号,获取该视频的弹幕地址
根据Bilibili提供的API接口规范来构造请求地址,并通过网络请求获取需要的数据。具体实现如下:
def get_dm_url(bv):
# 构造弹幕请求地址
url = f'https://api.bilibili.com/x/web-interface/view?bvid={bv}'
# 发送请求并获取视频信息
response = requests.get(url)
data = response.json()
# 提取视频的弹幕 oid
oid = data['data']['cid']
# 构造弹幕地址
dm_url = f'https://api.bilibili.com/x/v1/dm/list.so?oid={oid}'
return dm_url
③ getdanmu(video_urls) #已知300个视频的弹幕地址,通过数据解析,获取该弹幕,并保存到'弹幕数据.csv'
具体实现如下:
def getdanmu(video_urls):
#创建文件
f = open('弹幕数据.csv', mode='w', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['弹幕时间', '弹幕内容'])
csv_writer.writeheader()
# 循环遍历每个视频URL
for i, url in enumerate(video_urls):
# 发送请求
response = requests.get(url)
response.encoding = 'utf-8'
# 解析数据
info_list = re.findall('<d p="(.*?)">(.*?)</d>', response.text)
# 保存弹幕数据到CSV文件
for info, content in info_list:
send_time = info.split(',')[4]
time = datetime.datetime.fromtimestamp(int(send_time))
time = time.strftime('%Y-%m-%d %H:%M:%S')
dit = {'弹幕时间': time, '弹幕内容': content}
csv_writer.writerow(dit)
# print(dit)
f.close()
④ ciyunzhizuo() #已知300个视频的弹幕数据,通过结巴分词制作词云图
具体实现如下:
def ciyunzhizuo():
getdanmu(real_oid)
# 读取数据
df = pd.read_csv('弹幕数据.csv')
# 获取弹幕内容 列表推导式
content_list = [i for i in df['弹幕内容']] #把弹幕内容弄成一个列表
# 列表合并成字符串
content = ' '.join(content_list)#content_list列表中的所有元素连接在一起成为一个字符串,每个元素用空格隔开
# 生成词云图
txt = jieba.lcut(content)# 结巴分词 #对 content 进行分词,将分词结果存储在 txt 变量中,每个分词有一个单引号
string = ' '.join(txt)# 列表合并成字符串 #使用空格将列表 txt 中的所有分词连接成一个字符串,每个分词用空格隔开#使用空格将列表 txt 中的所有分词连接成一个字符串,每个分词用空格隔开
wc = wordcloud.WordCloud(height=700, width=1000, background_color='pink', font_path='msyh.ttc',
stopwords={'了', '我', '的', '的', '是', '吗', '我', '啊', '有', '都', '你', '他','他们'})#排除一些文字
wc.generate(string)#输入词云图所需数据
wc.to_file('词云图.png')
⑤ get_top_elements #已知300个视频的弹幕数据,统计出现次数前20的弹幕
def get_top_elements(lst, n):
count = Counter(lst) #统计每个弹幕出现的次数
top_elements = count.most_common(n) #n=20
return top_elements
●(3.3)数据统计接口部分的性能改进记录在数据统计接口的性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(例如可通过VS /JProfiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。)
通过对代码的分析,在执行时间,由于我的代码中包含多个请求和解析的过程,以及对大量数据进行处理和存储的步骤。在数据量较大或有大量网页请求时,可能会花费较长的时间来执行完全部任务。因此,对函数 get_bv() ,我们可以对它进行并行处理优化:
def process_url(url):
# 配置Microsoft Edge浏览器的驱动路径
driver_path = 'D:\Download\AppGallery\python\MicrosoftWebDriver.exe'
# 创建Microsoft Edge浏览器的选项
edge_options = EdgeOptions()
edge_options.use_chromium = True
edge_options.add_argument('--headless') # 无头模式
# 创建Microsoft Edge浏览器驱动
driver = Edge(executable_path=driver_path, options=edge_options)
try:
# 打开网页
driver.get(url)
# 等待页面加载完全
time.sleep(3)
# 获取页面源代码
html = driver.page_source
per_bv = re.findall(r'(BV.{10})', html)
return per_bv
finally:
# 关闭浏览器驱动
driver.quit()
def get_bv(urls):
sum_bv = []
with ThreadPoolExecutor() as executor:
# 提交每个URL的处理任务到线程池
results = executor.map(process_url, urls)
# 收集处理结果
for per_bv in results:
sum_bv.extend(per_bv)
return sum_bv
优化前:

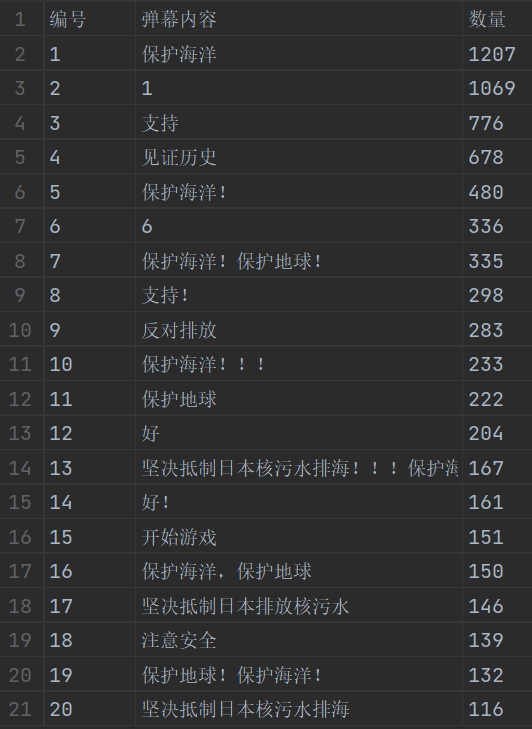
●(3.4)数据结论的可靠性(介绍结论的内容,以及通过什么数据以及何种判断方式得出此结论)
数据结论:通过对弹幕出现次数前20的统计,如下图,可以看出,越来越多的人关注这件事情,大家对于日本这一行为表现出极大的谴责,对保护地球、保护海洋的呼吁也愈发浩大。
●(3.5)数据可视化界面的展示(博客中介绍数据可视化界面的组件和设计的思路。)
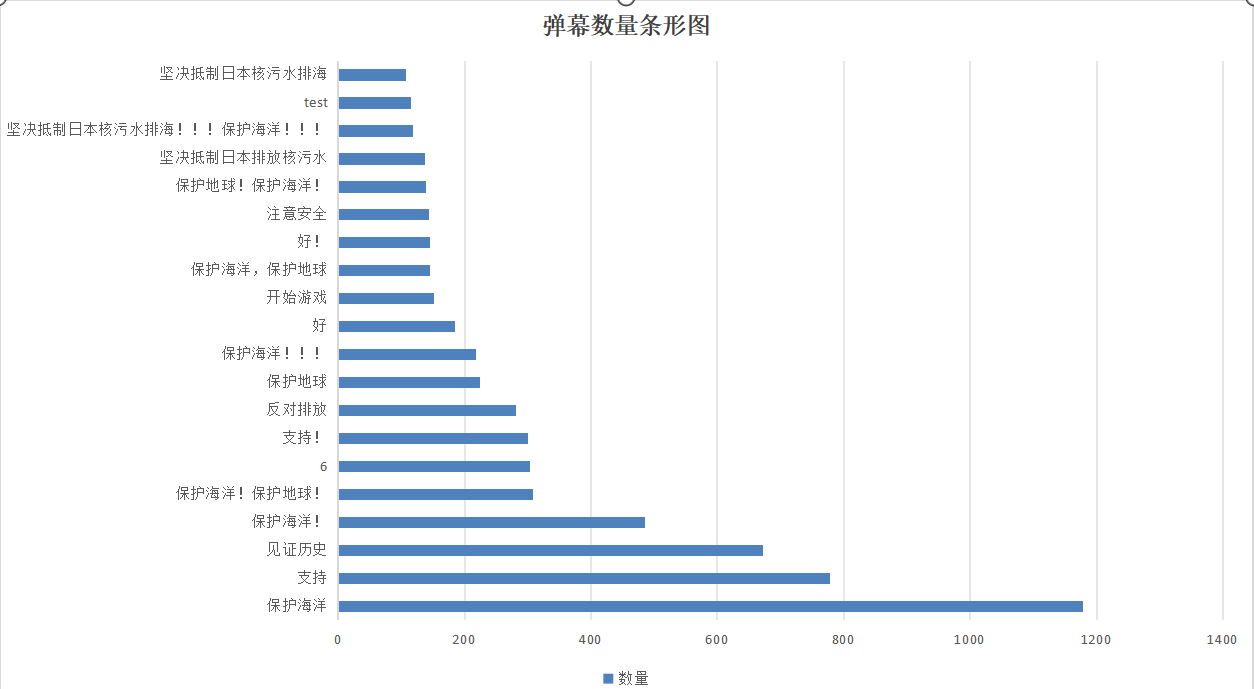

用到的主要组件有:
●wordcloud库:用于生成词云图
●Pandas:用于处理 Excel、csv 文件,读取弹幕数据。
●Jieba:将弹幕文本进行分词处理。
设计思路:
●将所有弹幕内容连接在一起成为一个字符串,每个元素用空格隔开,统计每个弹幕出现的次数,存到xlsx表格,再制作相应的柱状图;
●将所有弹幕内容进行结巴分词,每个分词用空格隔开,排除一些文字如“的”“我”“吗”等词,制作相应的词云图,调参使词云图更加美观。
●(4.1)在这儿写下你完成本次作业的心得体会,当然,如果你还有想表达的东西但在上面两个板块没有体现,也可以写在这儿~
本次任务我的心得体会是:
●在开始具体的编程之前,对相关知识一定要有了解,不可以盲目展开编程,不然中途一定会走很多的弯路,然后浪费巨多巨多的时间!!!
●在编写代码过程中,真的遇到了很多很多的异常和bug,一定要稳住心态,往往是“柳暗花明又一村”
●初次接触爬虫,将这个项目独立完成,其实真的蛮有成就感的。


