



119
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享链接:https://github.com/dai102101211/-/tree/main
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 40 | 30 |
| Development | 开发 | 900 | 1040 |
| · Analysis | · 需求分析 (包括学习新技术) | 200 | 300 |
| · Design Spec | · 生成设计文档 | 60 | 40 |
| · Design Review | · 设计复审 | 20 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| · Design | · 具体设计 | 200 | 240 |
| · Coding | · 具体编码 | 180 | 180 |
| · Code Review | · 代码复审 | 60 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改 | 160 | 180 |
| Reporting | 报告 | 120 | 100 |
| · Test Report | · 测试报告 | 30 | 20 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 50 |
| 合计 | 1060 | 1170 |
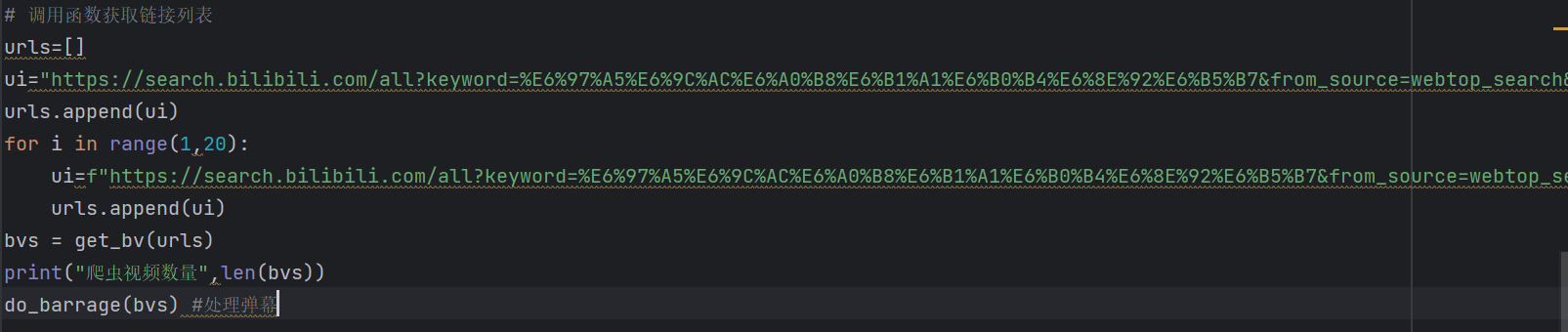
本次任务分为六个环节,分别是网页处理、多页弹幕提取合并、数据处理与保存、数据分析与统计、数据整理与可视化
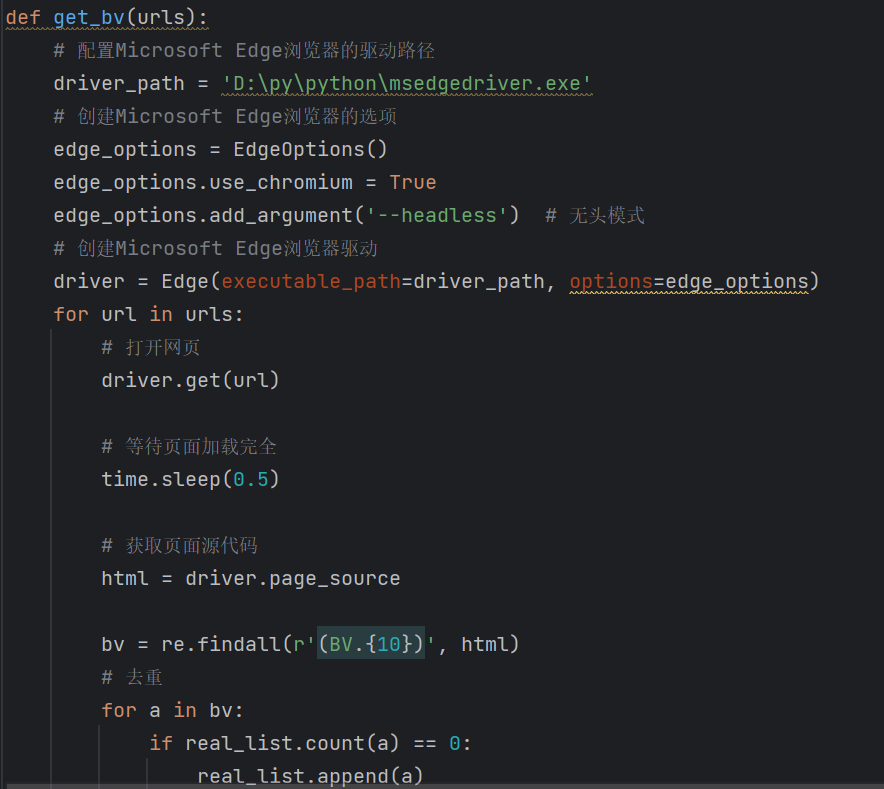
1.网页处理:使用Python的爬虫库(如re,time,requests)以及Edge的处理库from msedge.selenium_tools import EdgeOptions, Edg来获取b站页面的HTML
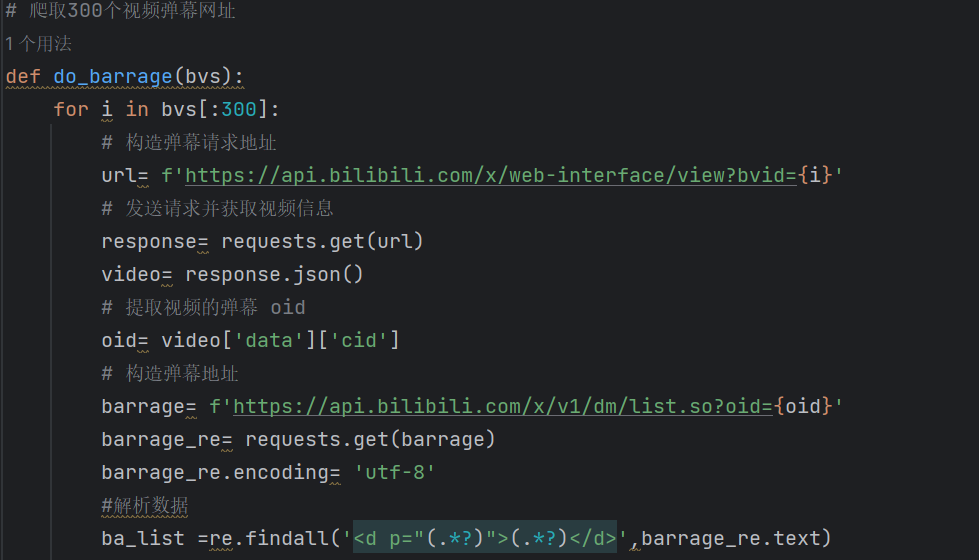
2.多页弹幕提取合并:解析HTML的BV号,并转化为oid号,得到前300个视频弹幕网址
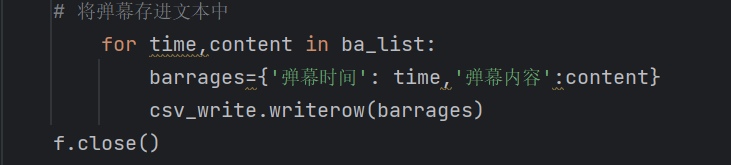
3.数据处理与保存:将数据弹幕数据的时间与数据文本使用csv库保存到csv文件中,为下一步数据分析与统计做准备
4.数据分析与统计:用python的数据库(如pandas库)进行读文件,运用collections 库与csv库进行弹幕数量前20的统计
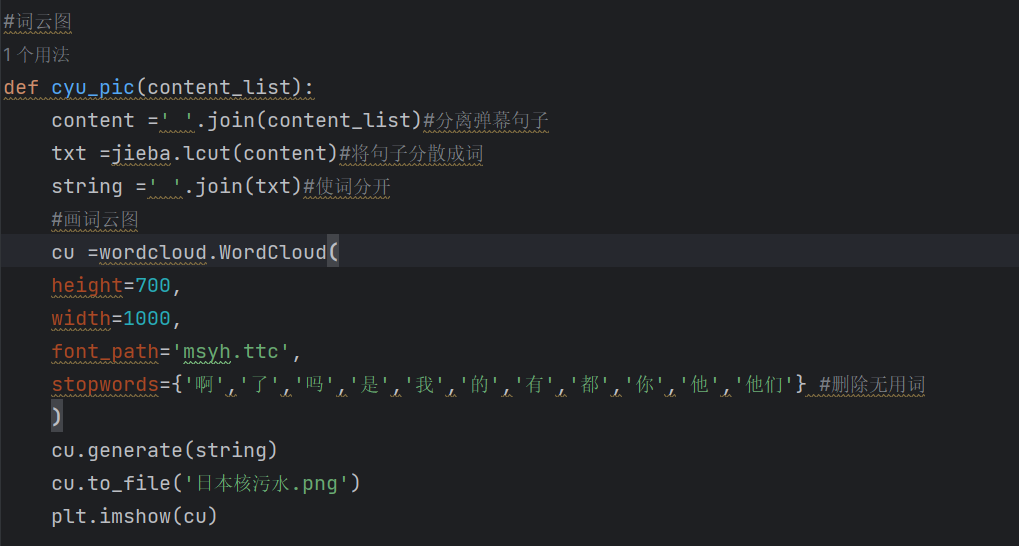
5.数据整理与可视化:运用jieba、wordcloudmatplotlib.pyplot进行弹幕数据统计,词云图的绘画
我将数据保存前的步骤,与数据结果分析,分为两个界面进行编写,所以有两个主函数,四个函数,分别是进行网页获取,弹幕分析,弹幕数量前20的整理,与词云图的生成
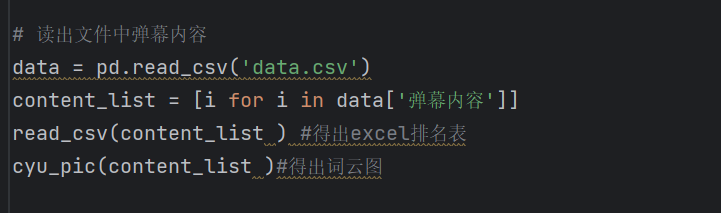
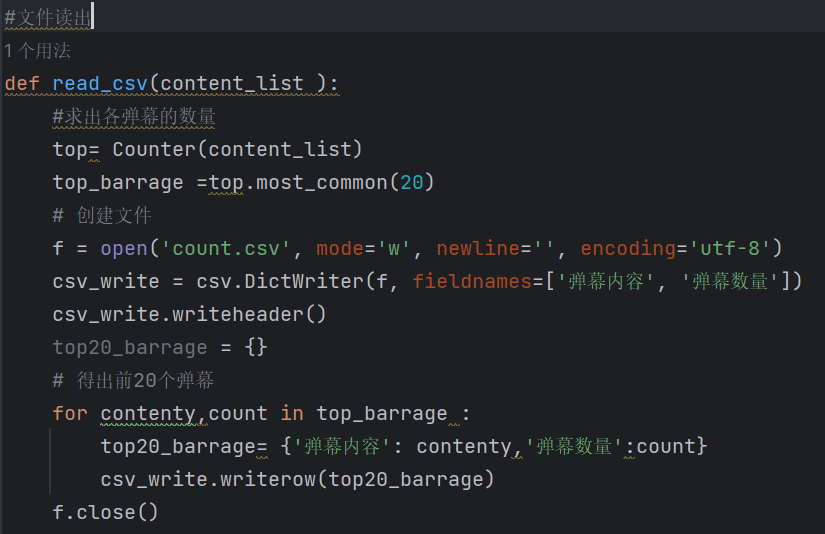
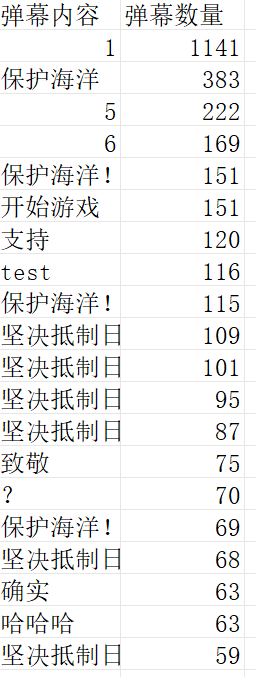
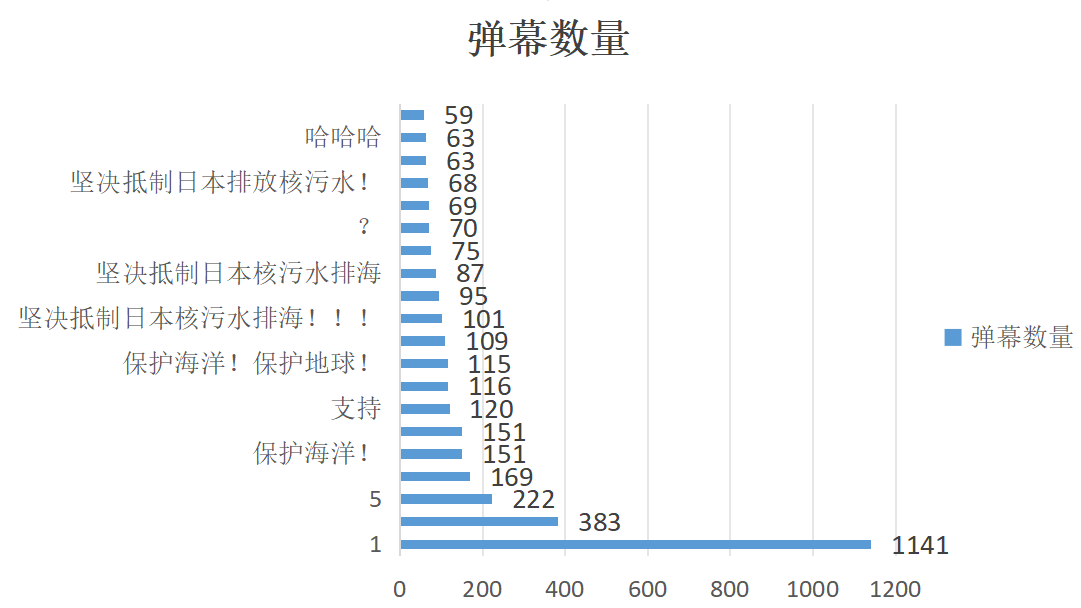
利用Counter得出弹幕数量前20的csv,得出除去数字,大部分是坚持抵制日本排污,要保护海洋;并且这个数据是基于b站的综合排序前300个视频得出的弹幕数据,所以数据庞大,即具有可靠性
利用jieba,wordcloud,matplotlib.pyplot进行弹幕拆解,词云图的制作,以及词云图保存

这次爬虫,是我从来没有接触过的东西,在短短的10天里,学到了许多,如:python的使用,爬虫的函数,数据的采集,
词云图制作等
爬虫:本次实践,意识到了edge与谷歌的网站区别,edge的爬虫有一个属于自己的库进行读取网页html,而谷歌无需;并且在爬虫时,遇到了b站的反爬虫机制,这个问题困扰我的时间最久;也因为这个反爬虫机制,导致每次爬虫视频数量可能不会相同
数据解析保存:这次作业让我知道了数据分析有很多方法,在这里头我使用正则re,虽然正则要时间与文本一起读取才可,而xpath与css虽然可以单独读取文本,但是xpath与css形成的csv数据处理起来较麻烦;这也是性能较低的原因
数据解析保存:词云图也是很神奇
我会再继续努力,在这个方面再学习,争取学到更多知识


