



119
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享(1.1)在Github仓库中新建一个学号为名的文件夹,同时在博客正文首行给出作业Github链接。(2')
作业链接:https://github.com/Novelty0826/SEwork
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 600 | 800 |
| Development | 开发 | 200 | 160 |
| Analysis | · 需求分析 (包括学习新技术) | 400 | 420 |
| · Design Spec | · 生成设计文档 | 30 | 40 |
| Design Review | · 设计复审 | 60 | 100 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 150 | 120 |
| · Design | · 具体设计 | 100 | 150 |
| · Coding | · 具体编码 | 200 | 320 |
| · Code Review | · 代码复审 | 100 | 120 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 200 | 240 |
| Reporting | 报告 | 150 | 120 |
| · Test Repor | · 测试报告 | 100 | 90 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 20 |
| · 合计 | 2400 | 2780 |
本次任务一共分为六个环节,分别为:需求分析、知识学习、代码实现、运行测试、代码改进、总结汇报
主要通过b站、csdn、ChatBot等渠道学习有关爬虫和数据可视化分析等内容
技术栈:requests、re正则表达式、json、jieba、wordcloud、numpy、Image、pandas
流程大致分为以下六个模块:分析搜索界面内容、bv号获取、cid获取、弹幕采集、导入excel统计数量、绘制词云图
代码的设计主要分为三个函数:采集弹幕、导入excel统计数量、绘制词云图
1)采集弹幕函数
part_1:通过开发者工具获得页面相关内容、采集页面信息、模拟浏览器上网
def get_search(v_keyword,v_max_page):
for page in range(1,v_max_page +1):
# 请求地址
url = 'https://api.bilibili.com/x/web-interface/wbi/search/type'
}
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)……'
'Referer': 'https://www.bilibili.com/video/',
'Accept': 'application/json, text/plain, */*',
'Cookie': 'buvid3=9BA66FD7-589E-4AF5-87E8-C695F18E4E55167635infoc;……'
}
params = {
'__refresh__': 'true',
'_extra': '',
'context': '',
'page': page,
'page_size': 30,
'from_source': '',
'from_spmid': '333.337',
'platform': 'pc',
'highlight': '1',
'single_column': '0',
'keyword': v_keyword,
'qv_id': 'zv2B6HhWqYvAFxesiXAQQFxOifMOsPoe',
'ad_resource': '5654',
'source_tag': '3',
'gaia_vtoken': '',
'category_id': '',
'search_type': 'video',
'dynamic_offset': 36,
'web_location': '1430654',
'w_rid': '0775703a753e9316d09c4bb77a9a5de0',
'wts': '1694586356'
}
# 向页面发送请求
r = requests.get(url, headers=headers, params=params)
part_2:通过分析数据获得综合排序视频的bv号
for index in r.json()['data']['result']:
bv_id = index['bvid']
with open('bv_id_1.txt', mode='a', encoding='utf-8') as f:
f.write(bv_id)
f.write('\n')
part_3:通过分析数据获得各个视频的cid号,再通过api接口获得弹幕地址,采集弹幕、导出弹幕文本
cid_url = 'https://api.bilibili.com/x/player/pagelist?bvid=' + bv_id + '&jsonp=jsonp'
response = requests.get(url=cid_url, headers=headers).content.decode('utf-8')
res_dict = json.loads(response)
values = res_dict['data']
for cid_values in values:
cid = cid_values.get('cid')
cid = str(cid)
# print(cid)
url_1 = 'https://api.bilibili.com/x/v1/dm/list.so?oid=' + cid
response = requests.get(url=url_1, headers=headers).content.decode('utf-8')
# print(response.text)
print(response)
content_list = re.findall('<d p=".*?">(.*?)</d>', response)
print(content_list)
# for 遍历输出内容
for content in content_list:
with open('弹幕文本.txt', mode='a', encoding='utf-8') as f:
f.write(content)
f.write('\n')
print(content)
2)导入execel表格统计弹幕数量函数
def get_excel():
with open('弹幕文本.txt', 'r', encoding='utf-8') as file:
lines = file.readlines()
line_counts = {}
for line in lines:
content = line.strip() # 去除行尾换行符等空白字符
if content in line_counts:
line_counts[content] += 1
else:
line_counts[content] = 1
df = pd.DataFrame(list(line_counts.items()), columns=['弹幕', '出现次数'])
df_sorted = df.sort_values(by='出现次数', ascending=False)
df_sorted.to_excel('结果统计.xlsx', index=False)
excel统计情况如下

3)绘制词云图函数
def get_wordcloud():
f = open('弹幕文本.txt', encoding='utf-8')
txt = f.read()
print(txt)
string = ' '.join(jieba.lcut(txt))
print(string)
mask = np.array(Image.open("photo_4.png"))
wc = wordcloud.WordCloud(
width=1000,
height=700,
background_color='white',
font_path='msyh.ttc',
scale=15,
colormap='Blues',
mask=mask
)
# wc.recolor()
wc.generate(string)
wc.to_file('词云图.png')
此部分未做成
结论:对于“日本核污染水排海”这一国际事件,大部分b站用户表现出极大的反对意见,对“日本核污染水排海”进行谴责与批评,相当一部分网友提倡保护海洋,反对排放。
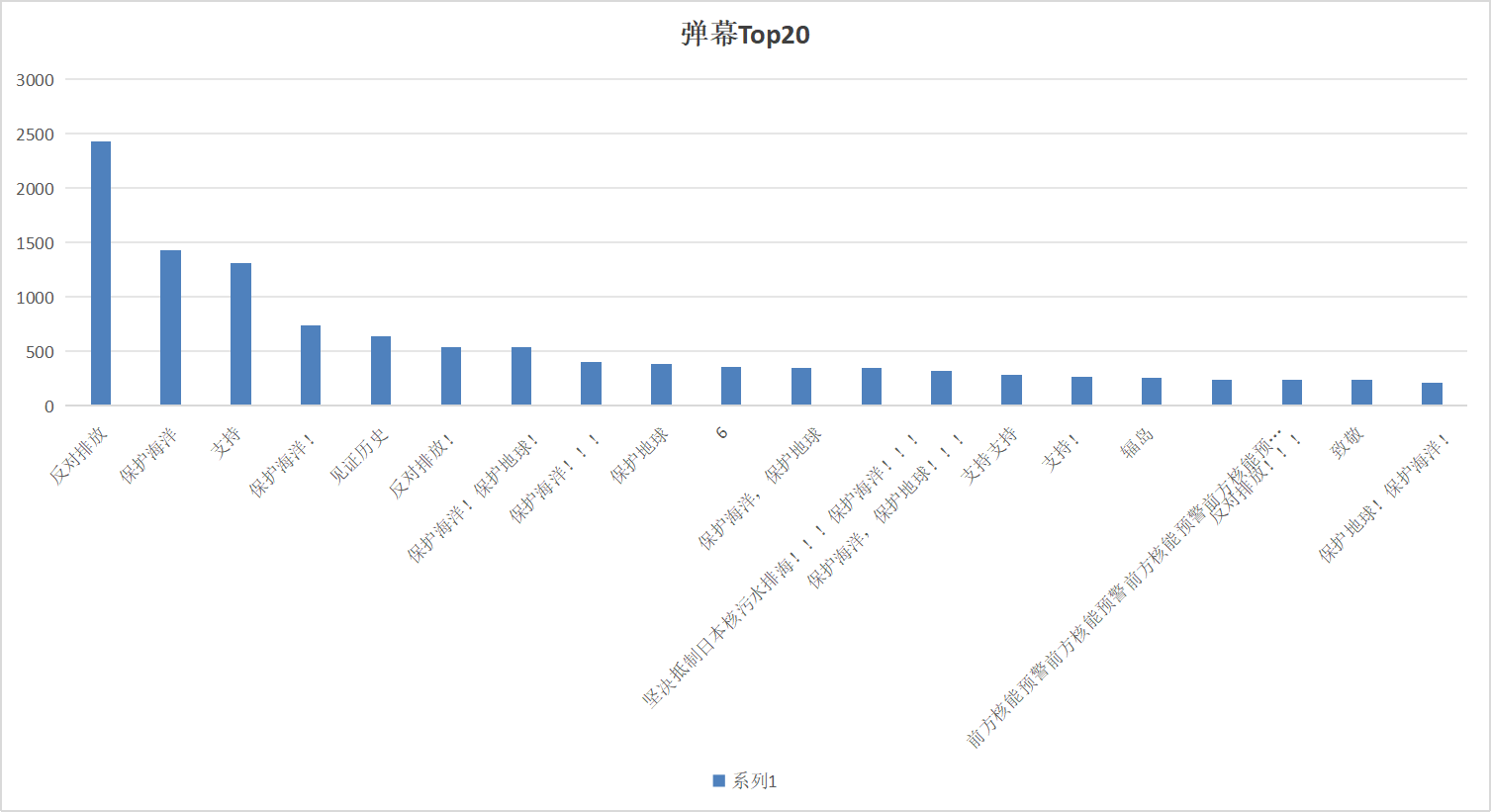
结论依据:通过爬取了相关词条下视频的大量弹幕,弹幕数量多达十万余条,数量之大更具有可靠性。分析弹幕的过程中,我统计了发布数量前二十的弹幕,“反对排放”位居第一,多达2430条,接着是“保护海洋”,多达1429条,“见证历史”642条,由此可见我国民众对日本核污水排海这一事件的关心以及态度。
主要分为两个内容:词云图以及弹幕Top20的柱形图。词语图用了oython的jieba库进行分词处理,统计各词的频次,然后利用wordcloud库生成词云图,词云图修改了轮廓形状以及字体颜色,增加美观性。弹幕Top20柱形图在excel自带的作图功能实现。

不敢想象,如果没有这项作业我会变得多么活泼开朗。咳咳,就是对于一个几乎没有python基础的人来说这项作业真的不简单,一开始没有什么头绪,在b站看了不少弹幕爬虫视频才慢慢摸索出一点点门道,但是问题是我要怎么批量爬取而不是只爬取一个视频,然后我又四处寻找,终于找到了我的救命视频解决我的问题,接着就是怎么绘制词云图和统计弹幕数量,其中表扬一下ChatBot,真是我的好帮手。
通过这次任务我也体会到了自学的重要性,课堂上的东西远远不够。在完成项目的过程中,遇到了诸多问题,有的问题也真的让我非常崩溃,但是最后也都差不多解决了,解决不了的就随它去,心态也比以前好多了。
整个作业完成下来,算是对爬虫有的大概的认识,但是因为时间紧迫,其实有很多问题还是没有太弄懂,处于一个一知半解的状态,前期预留的时间不够,以后再有任务一定做好规划,但是没有关系,留着以后慢慢琢磨吧,整体收获还是很大的。


