


118
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享https://github.com/54zzyy/102101424.git
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 1500 | 2000 |
| Development | 开发 | 500 | 740 |
| · Analysis | · 需求分析 (包括学习新技术) | 600 | 750 |
| · Design Spec | · 生成设计文档 | 50 | 60 |
| · Design Review | · 设计复审 | 100 | 140 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 25 | 30 |
| · Coding | · 具体编码 | 100 | 110 |
| · Code Review | · 代码复审 | 15 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 35 | 40 |
| Reporting | 报告 | 25 | 30 |
| · Test Repor | · 测试报告 | 10 | 10 |
| · Size Measurement | · 计算工作量 | 10 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| · 合计 | 1510 | 2020 |
(3.1)项目设计与技术栈。
问:从阅读完题目到完成作业,这一次的任务被你拆分成了几个环节?
我将此次任务分为三个环节:①阅读要求,上网查找相关资料②进行爬虫编程,过程中学习新的爬虫知识③测试代码的可行性,与预估结果进行比较。
问:你分别通过什么渠道、使用什么方式方法完成了各个环节?
通过上网查资料,b站观看相关视频的方式了解到需要达到预估目标的途径,将爬虫知识进一步完善,通过与同学交流,发现自己代码的错误点并及时改正,最后进行最终结果的测试完成。
问:列出你完成本次任务所使用的技术栈。
python爬虫基础入门技术
(3.2)爬虫与数据处理。说明业务逻辑,简述代码的设计过程(例如可介绍有几个类,几个函数,他们之间的关系),并对关键的函数或算法进行说明。
首先是通过开发者工具进行抓包,通过接口找到视频弹幕的数据地址,通过模拟浏览器对服务器发送请求,由于题目要求爬300个视频的弹幕地址,所以主题框架应该是在一个循环中进行
import requests # 第三方
for page in range(1,11):
其次,确定请求方式为get 要爬取视频的弹幕数据地址,应该先得到每个包含多个视频页面地url地址和请求头进行伪装
import requests # 第三方
for page in range(1,11):
if page==1:
url=f'https://search.bilibili.com/video?vt=12970522&keyword=日本核污染水排海'
else:
url=f'https://search.bilibili.com/video?vt=12970522&keyword=日本核污染水排海&page={page}'
# headers 请求头,进行伪装
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.1.5162 SLBChan/103'
}
response = requests.get(url=url, headers=headers)
response.encoding = response.apparent_encoding
得到包含得到每个包含多个视频页面地url地址和请求头之后,继续获取每个页面中每个视频的url地址和每个视频的请求头,通过正则表达式形成一个列表
继而在其中得到每个视频的url地址和请求头后,便可得到每个弹幕的url地址
import re # 正则表达式
text_list = re.findall(',aid:.*?bvid:"(.*?)",title:.*?keyword', response.text)
for i in text_list:
video_url ='http://www.ibilibili.com/video/'+ i
#print(video_url)
resp = requests.get(url=video_url)
resp.encoding = resp.apparent_encoding
#print(resp.text)
dm_url = re.findall('<a href="(.*?)" class="btn btn-default" target="_blank">弹幕</a>', resp.text)
'''for index in dm_url:
print(index)'''
然后在通过弹幕url地址爬取弹幕信息,并形成弹幕文本
for index in dm_url:
resp_new = requests.get(url=index)
resp_new.encoding = resp.apparent_encoding
data_list = re.findall('<d p=".*?">(.*?)</d>', resp_new.text)
for i in data_list:
with open('弹幕.txt', mode='a', encoding='utf-8') as f:
f.write(i)
f.write('\n')
if i in cnts:
cnts[i] += 1
else:
cnts[i] = 1
print(i)
用jieba将弹幕切割然后进行排序,最后生成词云图
import openpyxl
import heapq
cnts={}
def write_lines_excel(arr):
work_book = openpyxl.Workbook()
sheet = work_book.create_sheet('arrage')
sheet.cell(1, 1, 'top20的弹幕内容')
sheet.cell(1, 2, '弹幕出现次数')
for index, row in enumerate(arr):
for co in range(len(row)):
sheet.cell(index + 2, co + 1, row[co])
work_book.save('top20弹幕.xlsx')
dic = {}
dic.update({k: cnts[k] for k in heapq.nlargest(20, cnts, key=cnts.get)})
arr=[]
for key,value in dic.items():
arr.append((key,value))
#将top20的弹幕生成表格
write_lines_excel(arr)
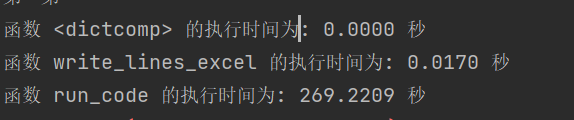
(3.3)数据统计接口部分的性能改进。记录在数据统计接口的性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(例如可通过VS /JProfiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。(6'
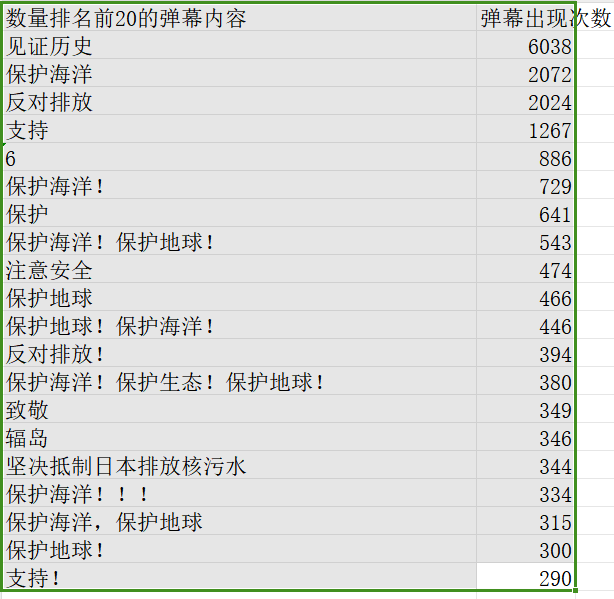
(3.4)数据结论的可靠性。介绍结论的内容,以及通过什么数据以及何种判断方式得出此结论(6')
数量排名前20的弹幕内容 弹幕出现次数形成表格
(3.5)数据可视化界面的展示。在博客中介绍数据可视化界面的组件和设计的思路。(15')

(4.1)在这儿写下你完成本次作业的心得体会,当然,如果你还有想表达的东西但在上面两个板块没有体现,也可以写在这儿~(10')
第一次接触爬虫,还是有点难度。很多不懂的地方通过求解同学才得以解决,很多函数和环境的搭载不会使用,通过网上教学和同学帮助最终还是完成了作业
很多关键性代码自己还是没办法完整实现。


