

118
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| · Planning | · 计划 | 10 | 15 |
| · Estimate | · 估计这个任务需要多少时间 | 555 | 811 |
| · Development | · 开发 | 475 | 706 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 165 |
| · Design Spec | · 生成设计文档 | 25 | 23 |
| · Design Review | · 设计复审 | 10 | 6 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 7 |
| · Design | · 具体设计 | 60 | 53 |
| · Coding | · 具体编码 | 200 | 367 |
| · Code Review | · 代码复审 | 20 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 45 |
| · Reporting | · 报告 | 80 | 105 |
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 60 |
| · 合计 | 565 | 826 |
根据提供的PSP表格对任务进行规划,规划各个步骤用时
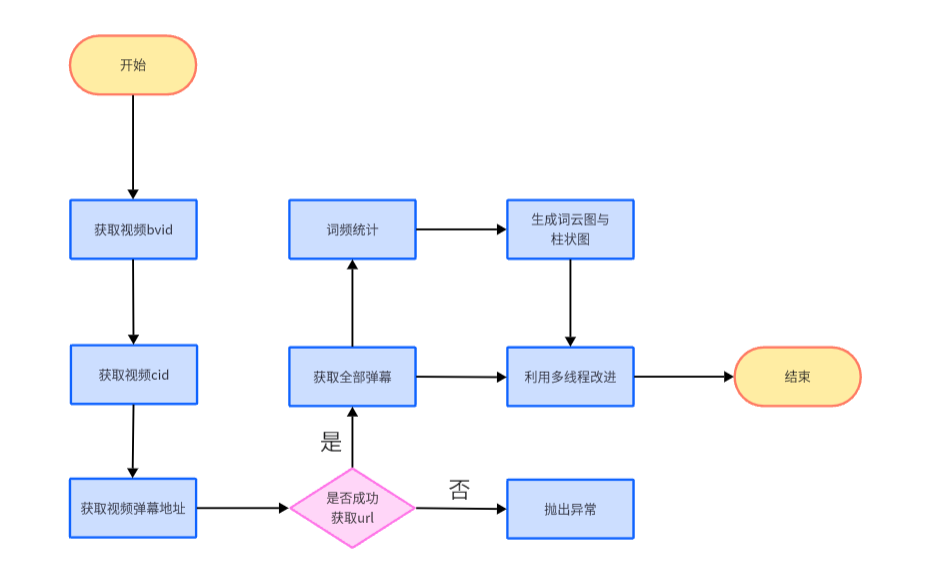
通过学习b站中的教学视频,学会爬取指定视频的弹幕,也对整体框架有了清楚的认识
技术栈:Python request库,Edge浏览器开发者工具,Python正则表达式
通过查阅得知b站api,通过查询其数据结构,得到视频的bvid。得到bvid之后以同样的方法通过api获取指定视频cid
技术栈:Python request库,json文件数据结构分析
在上一步得到视频的cid号之后,通过弹幕地址可以进行爬取弹幕。利用正则表达式转换符合格式的字符串,之后将得到的弹幕列表写入Excel中
技术栈:Python正则表达式,Edge浏览器开发者工具,Python文件存取操作(openpyxl与pandas库相关操作),Python request库
先读入Excel文件,先将读取的列转换成以空格分隔为形式的字符串,在将其变成列表。之后就可以用collection库中的Counter类统计词频,得到一个字典
字典中key为弹幕,value为频次。再利用sorted方法对字典以value(频次)为关键词进行排序,之后将弹幕出现次数输出到Excel中,应题目要求输出出现次数前20的弹幕
技术栈:Python collection库,Python sorted方法,Python文件存取操作(openpyxl与pandas库相关操作)
我利用一个基于wordcloud实现的stylecloud,使用stylecloud.generate_stylecloud()_ 方法来生成词云图,传递相应的文本文件,生成词云图
技术栈:Python stylecloud库
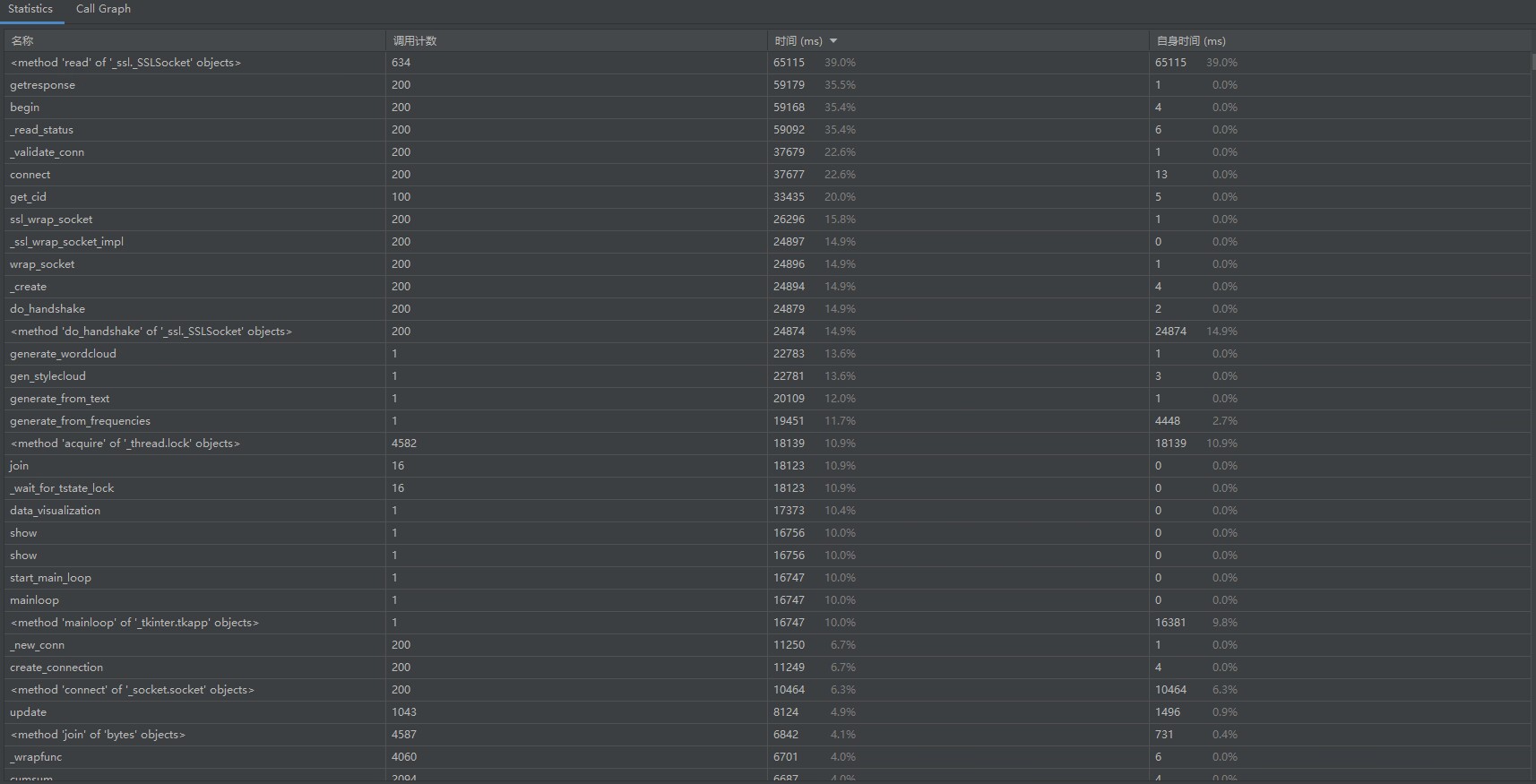
这里利用pycharm的插件SonarLint进行Code Quality Analysis,参照官方检测规则及修复示例消除了所有警告,如图:
技术栈:SonarLint的运用
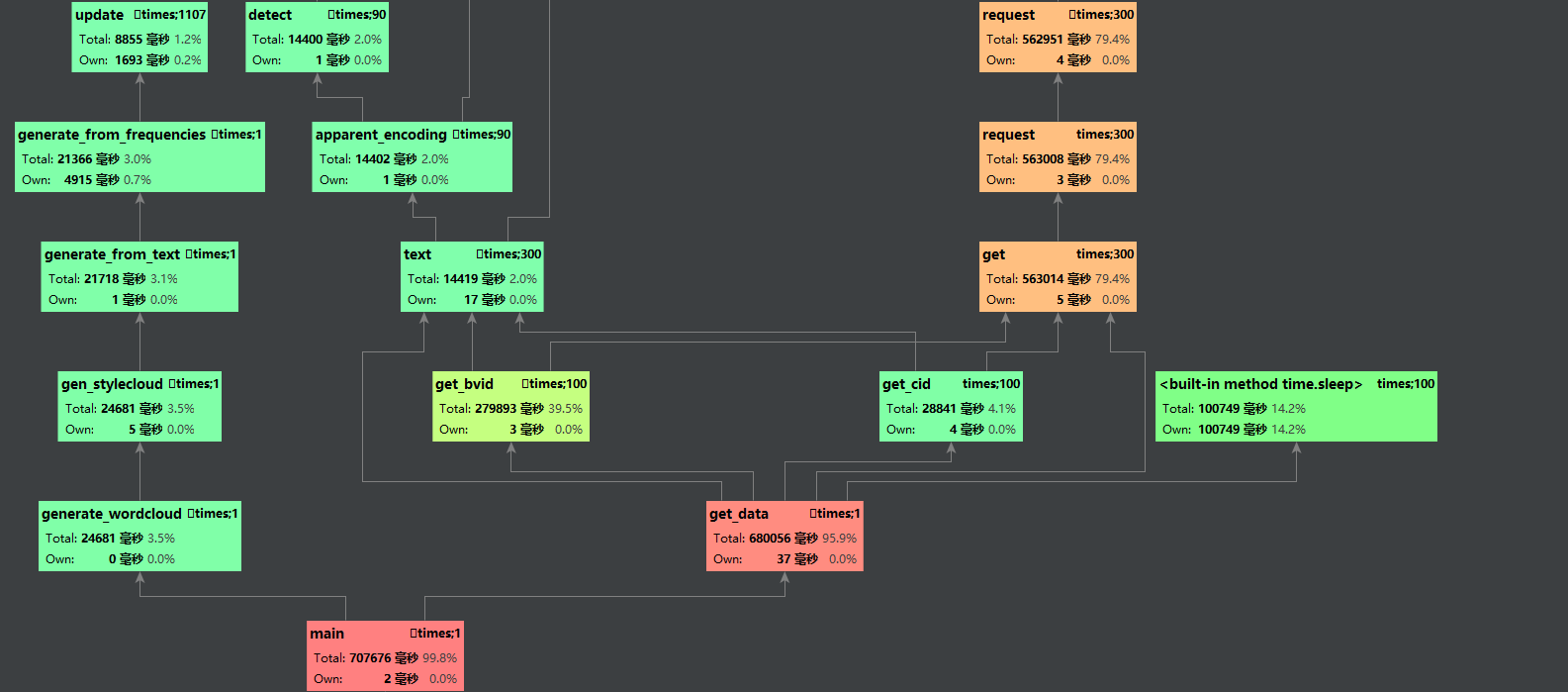
利用pycharm专业版自带的功能检测过后,利用多进程并发进行优化
技术栈:多进程并发工作,队列
利用python自带的unittest进行单元测试,顺利通过单元测试
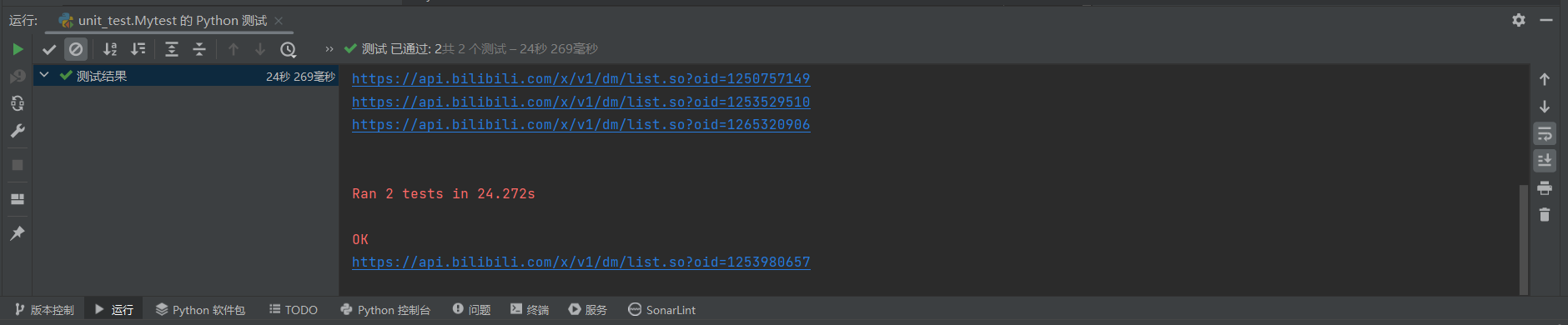
def get_bvid(page_number, number): # 根据搜索页api获取视频的bvid号
# url即网址
url = 'https://api.bilibili.com/x/web-interface/search/all/v2?' \
'page=' + str(page_number) + '&keyword=%E6%97%A5%E6' \
'%9C%AC%E6%A0%B8%E6%B1%A1%E6%9F%93%E6%B0%B4%E6%8E%92%E6%B5%B7'
headers = {
'cookie': '...此处省略',
'origin': 'https://www.bilibili.com',
'referer': 'https://www.bilibili.com/video/BV1yF411C7ZJ/?spm_id_from='
'333.337.search-card.all.click&vd_source=e5ea948412c2a8820992ad19400de8ab',
'user-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.81'
}
response = requests.get(url=url, headers=headers).text # 利用HTTP的get方法,以json格式得到文件
json_data = json.loads(response) # 用python内置函数将json文件转换成字典格式
return json_data['data']['result'][11]['data'][number]['bvid'] # 根据key得到value
def get_cid(bvid): # 视频的bvid号得到指定视频的cid号
try:
url = 'https://api.bilibili.com/x/player/pagelist?bvid=' + str(bvid) + '&jsonp=jsonp'
response = requests.get(url).text # 利用HTTP的get方法,以json格式得到文件
json_dict = json.loads(response) # 用python内置函数将json文件转换成字典格式
bulletchat_api = tempApi.replace("{number}", str(json_dict['data'][0]['cid']))
apiQueue.put(bulletchat_api)
print(bulletchat_api)
return json_dict['data'][0]['cid'] # 根据key得到value
except (KeyError, IndexError, requests.RequestException) as e:
print(f"获取cid出现异常: {e}")
return None
def get_data():
while not apiQueue.empty():
response = requests.get(url=apiQueue.get(), json=params, headers=headers) # 利用HTTP的get方法,得到json格式文件
response.encoding = response.apparent_encoding
print(response)
data = re.findall('<d p=".*?">(.*?)</d>', response.text) # re.findall第一个参数pattern是模式串,第二个是字符串
# 以list形式返回符合模式串格式的所有字符串
print(data)
for index in data:
threadLock.acquire()
print(index)
file_txt = open('全部弹幕.txt', 'a', encoding='utf-8')
file_txt.write(index + '\n')
total_sheet.append([index]) # 添加到所创建的工作表sheet中
threadLock.release()
time.sleep(1)
def calculate_frequency():
try:
workbook = openpyxl.Workbook() # 创建一个工作簿
sheet = workbook.active # 在工作簿中创建一个工作表
sheet.append(['弹幕']) # 为表加上列名
sheet.cell(row=1, column=2).value = '频次'
new_workbook = openpyxl.Workbook()
new_sheet = new_workbook.active
new_sheet.append(['弹幕'])
new_sheet.cell(row=1, column=2).value = '频次'
excel_path = '全部弹幕.xlsx'
fd = pd.read_excel(excel_path) # 读出文件
lines = fd['弹幕'] # 得到列名为弹幕的一列数据
text = ' '.join(lines.astype(str)) # 先把得到的数据转换成str类型文件,在用空格把它们连接起来
words = text.split() # 将得到的字符串分割成列表
word_counts = collections.Counter(words) # 用collections库中的Counter 类统计每个词出现的次数
sorted_word_counts = sorted(word_counts.items(), key=lambda x: x[1], reverse=True) # 按第二列对词频统计结果按照频次进行排序
for word, count in sorted_word_counts:
sheet.append([word, count])
for i in range(20):
new_sheet.append(sorted_word_counts[i])
print("排名第" + str(i + 1) + ": ", end="")
print(sorted_word_counts[i])
workbook.save('统计弹幕出现次数.xlsx')
new_workbook.save('排名前20的弹幕数量.xlsx')
except Exception as e:
print(f"计算频次出现异常: {e}")
def generate_wordcloud():
try:
stylecloud.gen_stylecloud(file_path='全部弹幕.txt',
font_path='C:\\Windows\\Fonts\\STZHONGS.TTF',
palette='colorbrewer.diverging.Spectral_11',
icon_name='fas fa-skull ',
background_color='black',
size=2048,
gradient='horizontal',
output_name='词云图.png')
except Exception as e:
print(f"生成词云出现异常: {e}")
def data_visualization():
try:
excel_file = '排名前20的弹幕数量.xlsx'
df = pd.read_excel(excel_file)
values = df['弹幕'] # 第一列是弹幕
frequencies = df['频次'] # 第二列是频次
# 创建可视化图表
plt.figure(figsize=(10, 6)) # 设置图表尺寸
plt.bar(values, frequencies) # 创建柱状图
plt.xlabel('弹幕') # 设置X轴标签
plt.ylabel('频次') # 设置Y轴标签
plt.title('频次分布图') # 设置图表标题
# 显示图表
plt.xticks(rotation=270) # 设置X轴标签旋转,以防止标签重叠
plt.tight_layout() # 自动调整布局,以防止标签重叠
plt.show()
except Exception as e:
print(f"数据可视化出现异常: {e}")

组件:matplotlib库,stylecloud库,pandas库
设计思路:最开始时想利用wordcloud库工具实现词云图的制作,但是想要制作好看的词云图需要将png或者jpeg等格式的图片资源同一并上传才能运行,于是就换了一种生成方法,但是其实也是基于wordcloud库实现的一种方法,这种方法在不将背景图片一并上传的同时也能生成词云图
在本次作业真正入手实践之间,在会运用爬虫技术爬取百度上的图片,并不会甚至没听说过可以爬取b站弹幕。在动手实践时也是遇到了许多困难,在爬虫代码的实现上所费时不多,更多的是在爬取过多次,被封后的等待时间以及在性能分析那块费时许久。git的使用也是摸索了好久,遭遇种种错误之后终于调通了。
总的来说,这次作业让我学习到了许多之前没了解过的领域,如Code Quality Analysis、多线程并发执行、Git的使用和单元测试等等等等,都是之前从未探索过的领域。同时更加熟悉了python的文件读取操作、matplotlib库进行绘图以及爬虫技术的拓展。最重要的是,锻炼了独立面对一个繁琐项目的能力,能够在有限的时间中完成各项任务,也加强了面对异常情况的查阅资料处理能力,对我来说这是一次启发性的项目体验,能够让我在今后的学习生活中更好的独立完成任务。
在最后的多线程优化环节折腾了一天多的时间,又是在deadline前爆赶,在以后面对比较繁琐的任务时,应该提前做好规划,分成小块,逐步完成。下次一定!
原先是想爬取YouTube相关视频弹幕以此获取世界主流媒体看法,后来遇到了种种困难,时间也不太充裕了,所有就在国内的新闻媒体上爬取了一些国外媒体的相关文字报道,经过许多无效文字的筛选,结果如下图所示:

由此可以看出英美媒体明显支持日本,淡化核废水排海的危害。而法国媒体的态度较为中立。土耳其和阿拉伯世界也比较反对日本排海,阿拉伯半岛新闻谴责日本把太平洋当作垃圾桶。马来西亚媒体则十分务实低调,态度不明确,但让自己国家老百姓放心会选择性筛选进口日本的食品。
预测事件走向:经过全球大部分国家对日本海产品的抵制,日本海产品行业必将受到全方位的影响,包括日本的经济方面也会造成很大的影响。这不仅可能会引发国际上的贸易争端,更可能导致全球其他国家之间的紧张关系。
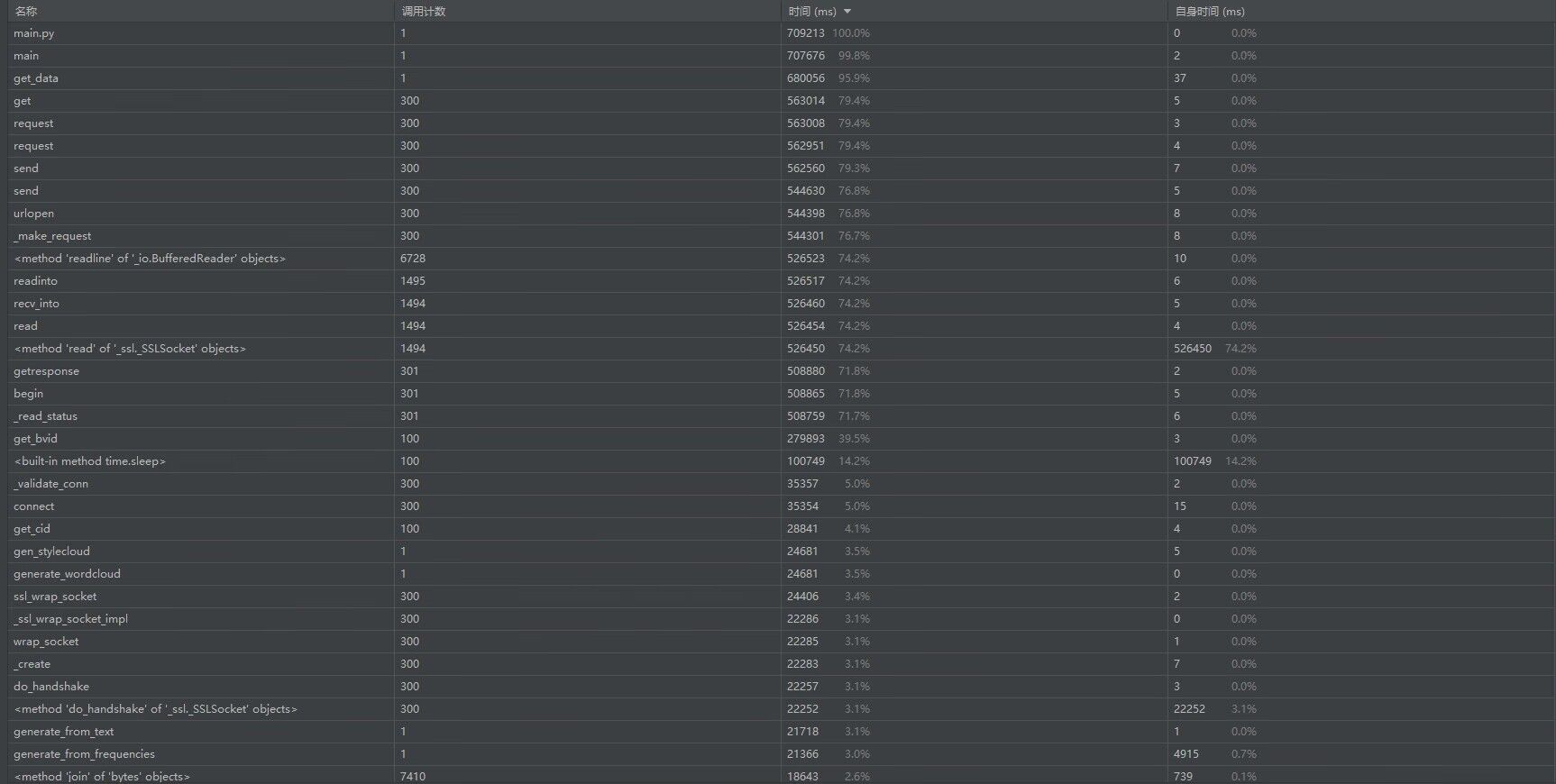
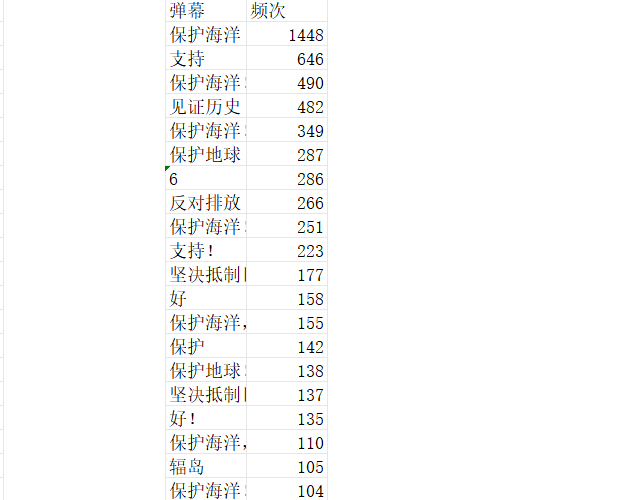
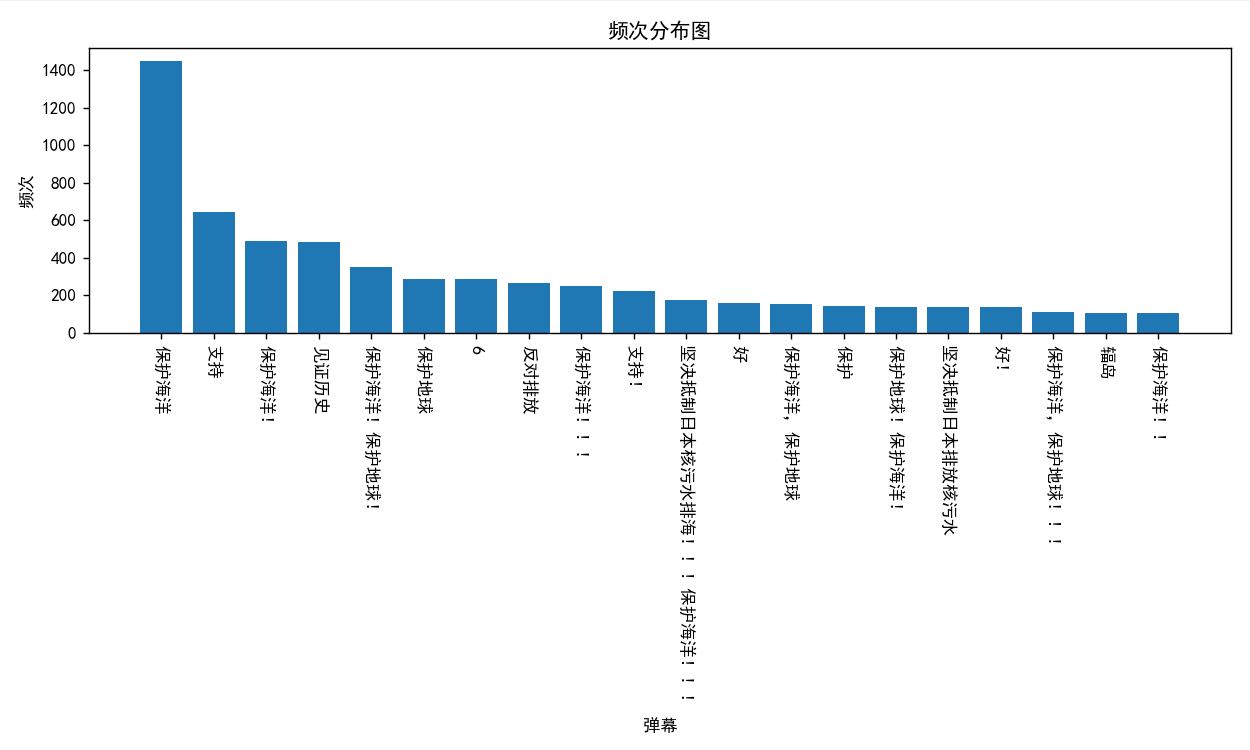
我爬取了b站关键词为无畏契约的前300个视频中的弹幕,并做了词云分析和数据可视化,如下图:

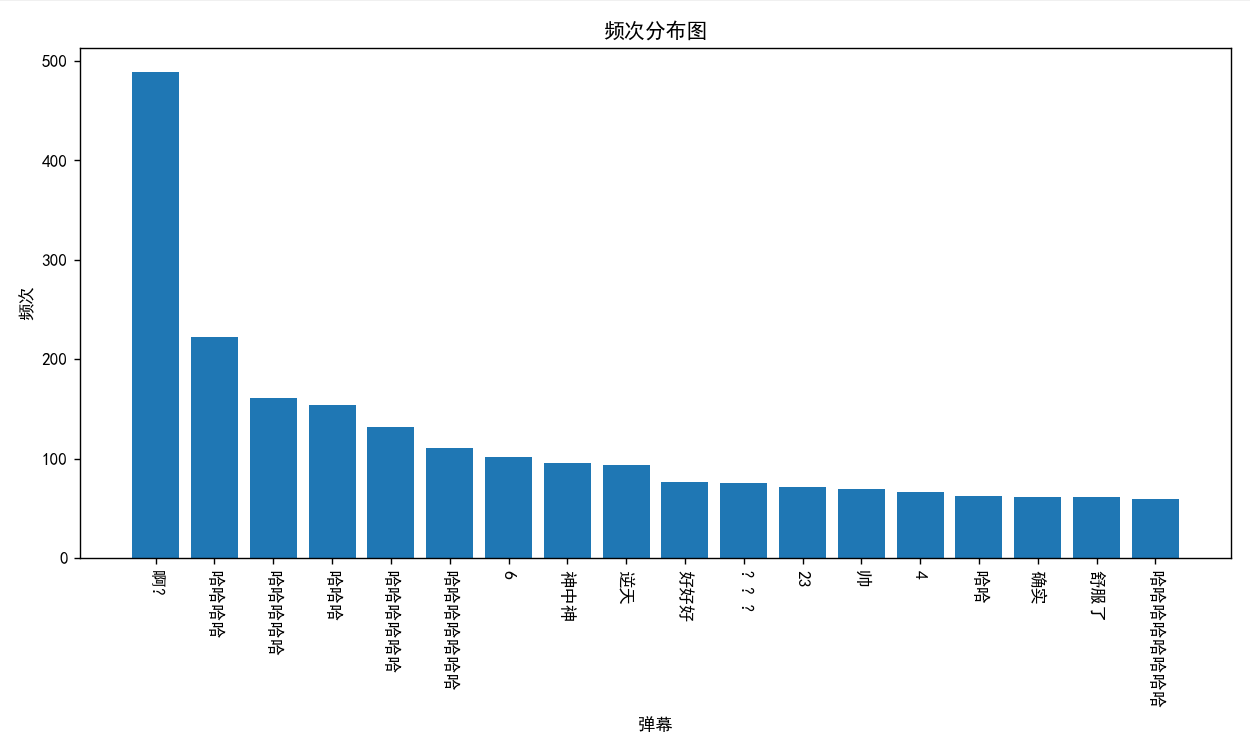
由此可以看出无畏契约玩家对 '啊?' 的使用率很高,并且玩家们都是非常开心的在玩游戏以及看相关视频

啊,哈哈哈哈哈,你确定都不去除一下stop words?

巨ccccccccccccc

