


118
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 5 |
| Estimate | 估计这个任务需要多少时间 | 10 | 5 |
| Development | 开发 | 200 | 255 |
| Analysis | 需求分析 (包括学习新技术) | 20 | 5 |
| Design Spec | 生成设计文档 | 30 | 15 |
| Design Review | 设计复审 | 5 | 5 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| Design | 具体设计 | 60 | 120 |
| Coding | 具体编码 | 30 | 30 |
| Code Review | 代码复审 | 15 | 15 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 60 |
| Reporting | 报告 | 105 | 200 |
| Test Repor | 测试报告 | 30 | 30 |
| Size Measurement | 计算工作量 | 15 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 120 |
| 合计 | 315 | 460 |
本次任务共分为四个环节
学习词云制作库stylecloud
研读CSDN博客,主要参考如下:
让你的作品更出色——词云Word Cloud的制作方法
词云进阶:神奇的stylecloud
学习柱状图的绘制,数据可视化
学习HTTP 请求库request,了解浏览器的检查功能,判断URL位置,参考B站视频如下:
详细讲解用python爬哔哩哔哩搜索结果
简单流程如下:
headers、负载参数paramsarcurl正则表达式库re,学习正则表达式匹配,参考B站教程:Python爬虫实战教程:批量爬取某网站图片
同时,了解B站弹幕的存储位置,参考博客:B站弹幕接口
简单流程如下:
编写主程序,将整个流程串起来
在获取视频URL时,累计爬取300个视频,可视化结果,以完成题目要求
利用pycharm专业版自带的Profile检测性能,并利用多进程操作进行优化
我们利用pycharm中的插件SonarLint进行代码分析,参照pycharm检测提示消除了所有警告,如图:
每一类中我都写了程序测试函数功能是否正常运行
以下为示例:
业务流程如下:
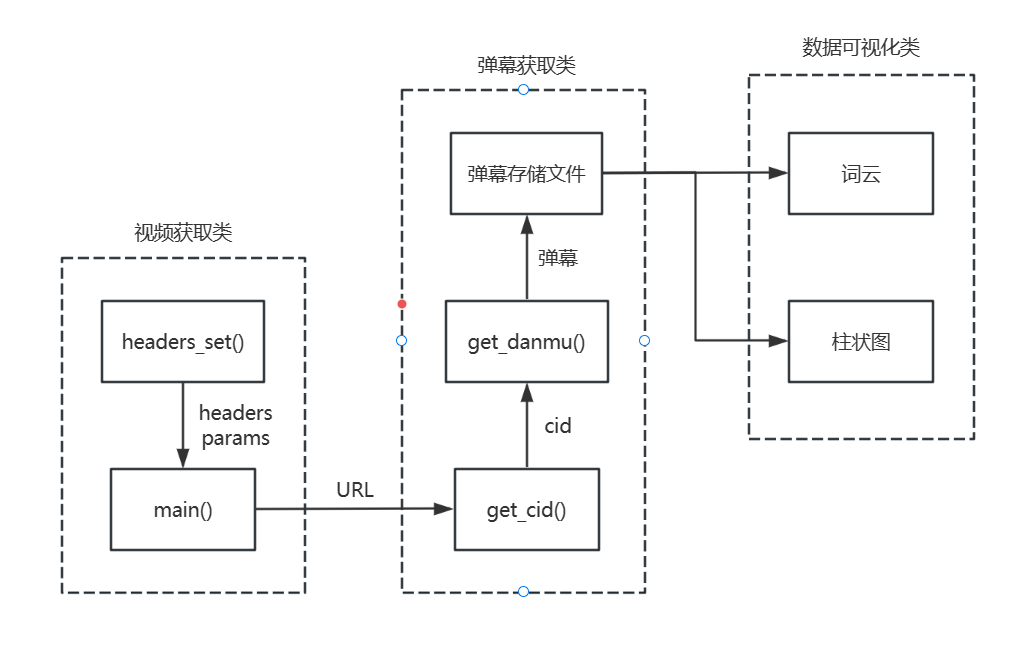
本代码共包含三个类
根据页码,搜索关键词,每页视频数等信息设置请求头和参数
def headers_set(keyword, page): # 设置每页的请求头和参数,方便遍历
try:
# 参数
params = {
'page': page, # 页码
'page_size': 30, # 每页视频数
'keyword': keyword, # 搜索关键词
# ...根据自己的请况添加
}
# 请求头
headers = {
# ...根据自己的情况添加
}
return headers, params
except Exception as e:
print(f"请求头与参数获取出现异常: {e}")
请求头获取
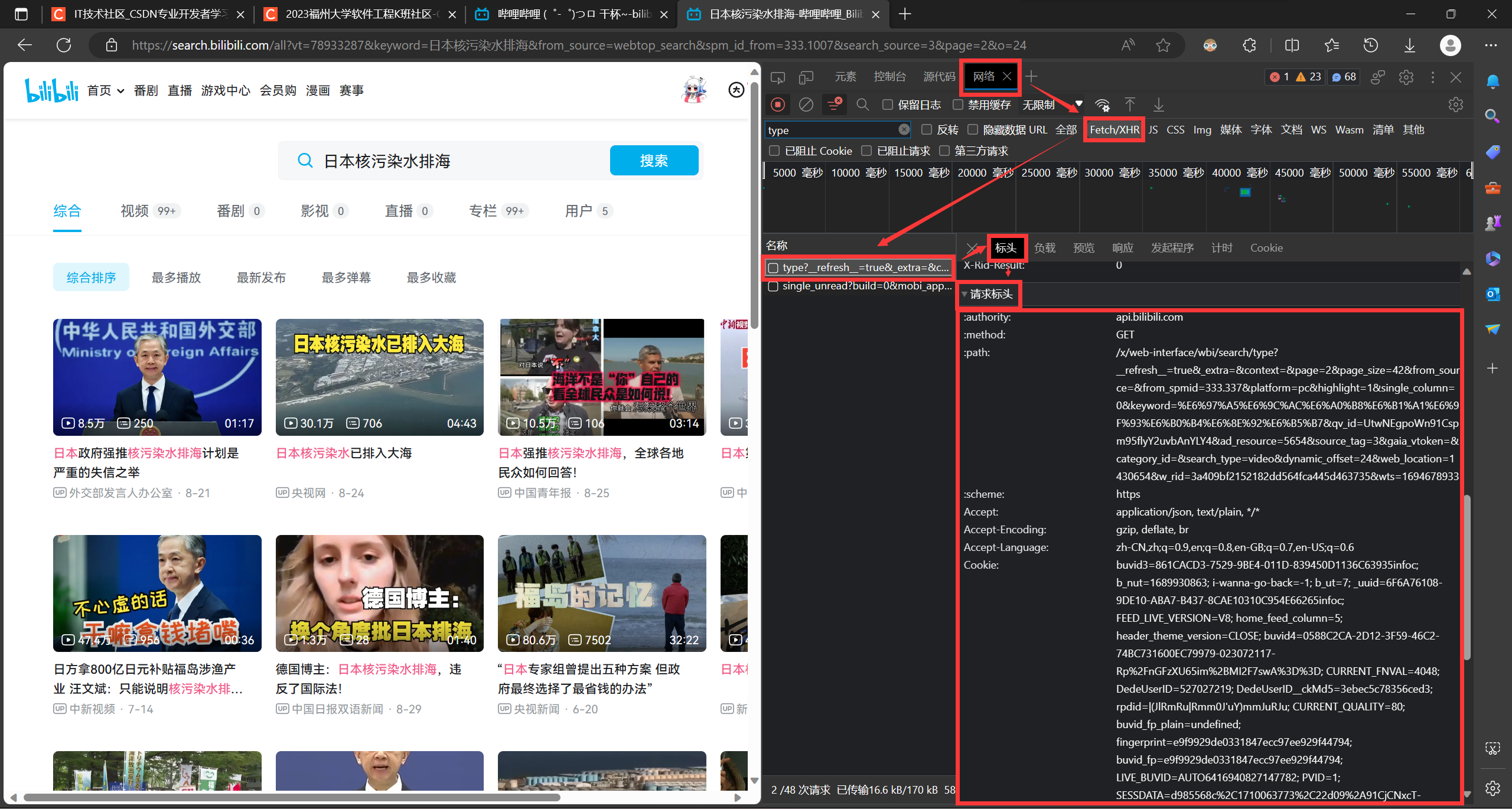
参数获取
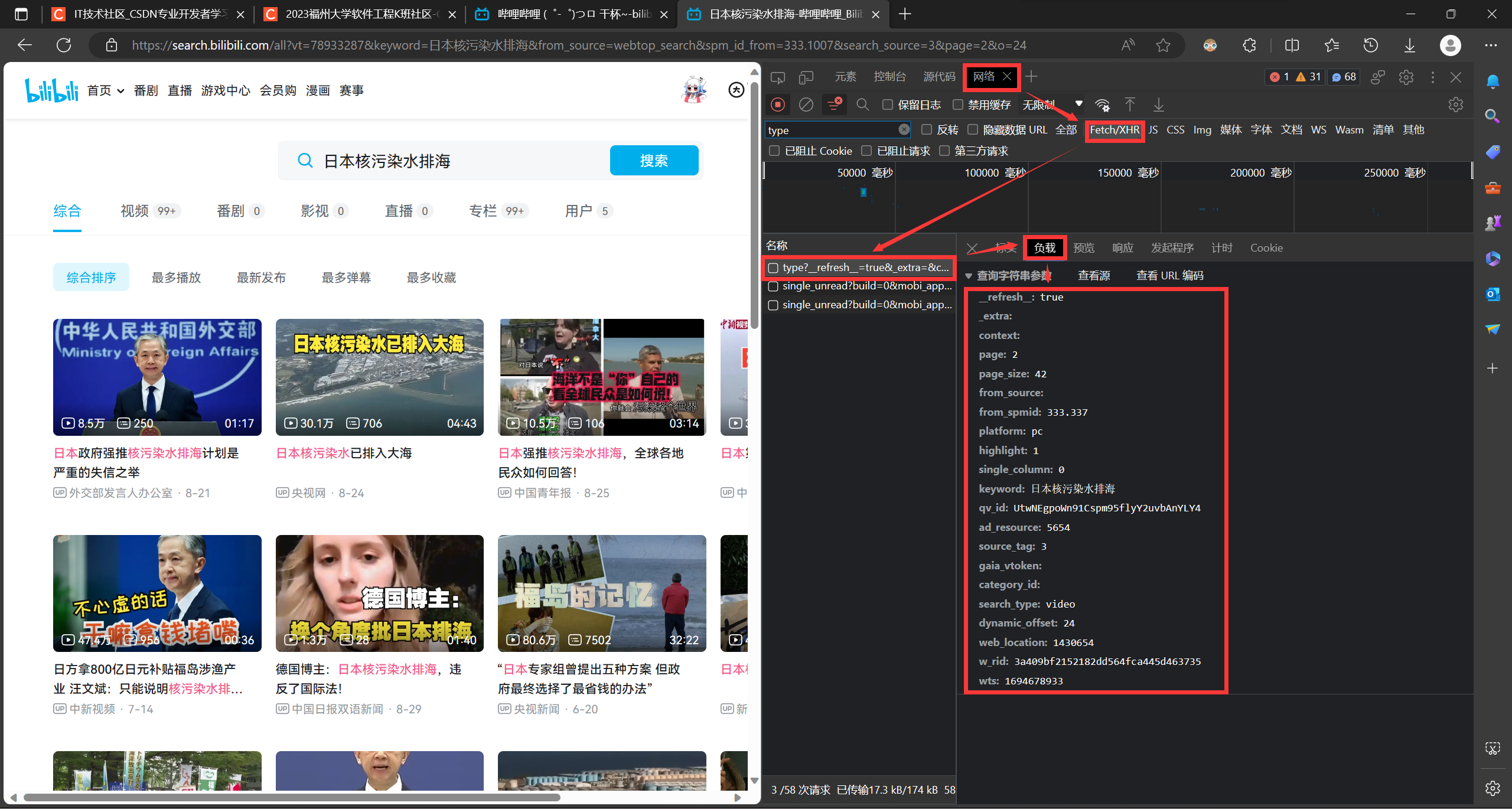
用于获取视频的URL,具体实现参照注释
def main(keyword, m):
try:
n = int(m / 30)
url = 'https://api.bilibili.com/x/web-interface/wbi/search/type'
urls = []
for page in tqdm.tqdm(range(1, n+1)):
headers, params = headers_set(keyword, page)
response = requests.get(url, headers=headers, params=params)
file = response.json()
results = file['data']['result']
for result in tqdm.tqdm(results):
urls.append(result['arcurl'])
return urls
except Exception as e:
print(f"URL获取出现异常: {e}")
通过访问视频页面,提取信息中的cid码,用于后面访问弹幕存放的网页
def get_cid(video_url, headers):
try:
response = requests.get(video_url, headers=headers) # 请求页面
response.encoding = 'utf-8' # 更改编码格式,防止乱码
html = response.text # 保存请求返回的信息
cid = re.search('"cid":(.*?),', html).groups()[0] # 正则表达式匹配,提取信息中的cid码
return cid
except Exception as e:
print(f"cid获取出现异常: {e}")
根据提取到的cid码,访问B站提供的comment接口,匹配提取弹幕信息
def get_danmu(cid, headers):
try:
danmu_url = f'https://comment.bilibili.com/{cid}.xml' # B站用于存储弹幕的URL,规则
response = requests.get(danmu_url, headers=headers) # 请求网页
response.encoding = 'utf-8' # 更改编码格式,防止乱码
html = response.text # 保存请求返回的信息
contexts = re.findall('<d p=".*?">(.*?)</d>', html) # 正则表达式匹配,提取信息中的弹幕信息(字符串)
return contexts
except Exception as e:
print(f"弹幕获取出现异常: {e}")
将弹幕列表存储
def write_txt(context_list, filename):
try:
with open(filename, 'a', encoding='utf-8') as f: # 创建TXT文件存储弹幕
for context in context_list:
f.write(str(context) + '\n') # 弹幕竖直排列写入
except Exception as e:
print(f"txt生成出现异常: {e}")
调用函数get_cid()和get_danmu()提取弹幕列表,返回
def main(video_url):
try:
headers = { # 请求头,由于弹幕提取不涉及翻页操作,这里不需要参数
# 参考以上获取方式
}
cid = get_cid(video_url, headers) # 获取cid码
danmu = get_danmu(cid, headers) # 获取弹幕列表
write_txt(danmu, './danmu.txt') # 写入文件
except Exception as e:
print(f"弹幕获取(总)出现异常: {e}")
调整参数,生成词云图
def cloud_making():
try:
stylecloud.gen_stylecloud(file_path='danmu.txt', # 存储弹幕的文件位置
icon_name='fas fa-radiation', # 云图图标
palette='cmocean.diverging.Balance_6', # 调色板
font_path="msyh.ttc", # 字体信息
background_color='white', # 背景颜色
output_name='cloud.jpg', # 输出图片文件名
gradient='horizontal', # 渐变
invert_mask=True, # 是否反转
size=2048, # 图片大小
)
except Exception as e:
print(f"词云生成出现异常: {e}")
将弹幕频次前20的字典数据可视化
def chart_making(labels, values):
try:
plt.rc("font", family='YouYuan') # 设置字体防止乱码
fig, ax = plt.subplots(figsize=(12, 6)) # 创建一个图表
sns.barplot(x=labels, y=values, ax=ax, color='blue') # 绘制柱状图
ax.set_title("弹幕频次前20")
ax.set_xlabel("弹幕")
ax.set_ylabel("频次")
ax.set_xticklabels(labels, rotation=45, ha='right') # 设置x轴标签为斜着显示
plt.show() # 显示图表
except Exception as e:
print(f"图表生成出现异常: {e}")
整个爬虫的核心,将各类串联,同时提供数据可视化
if __name__ == '__main__':
try:
time_start = time.time() # 记录开始时间
keyword = '日本核污染水排海' # 设置搜索关键词
n = 300 # 设置总视频数
danmu = [] # 弹幕列表
urls = get_video.main(keyword, n)
for url in tqdm.tqdm(urls):
get_danmu.main(url)
with open('./danmu.txt', 'r', encoding='utf-8') as file:
danmu = [danmu.strip() for danmu in file.readlines()] # 读取弹幕
print(len(danmu)) # 输出总爬取弹幕数
word_counts = Counter(danmu) # 记录频次
df = pd.DataFrame(word_counts.items(), columns=["弹幕", "频次"]) # 写入xlsx文件
df.to_excel("danmu.xlsx", index=False) # 生成文件
top_20_words = word_counts.most_common(20) # 提取频次前二十的弹幕
keys = []
values = []
for word, count in top_20_words:
keys.append(word)
values.append(count)
print(f"{word}: {count} ") # 输出到控制台
visualization.chart_making(keys, values) # 数据可视化
visualization.cloud_making() # 制作词云
time_end = time.time() # 记录结束时间
time_sum = time_end - time_start # 计算的时间差为程序的执行时间,单位为秒/s
print(time_sum)
except Exception as e:
print(f"main出现异常: {e}")
这边我们先是展示程序的总运行时间,总时间421.807s,这里我们采用time第三方库进行记录

然后展示各个类,各个函数的运行时间占比,这里是由pycharm专业版自动生成,此处仅展现部分
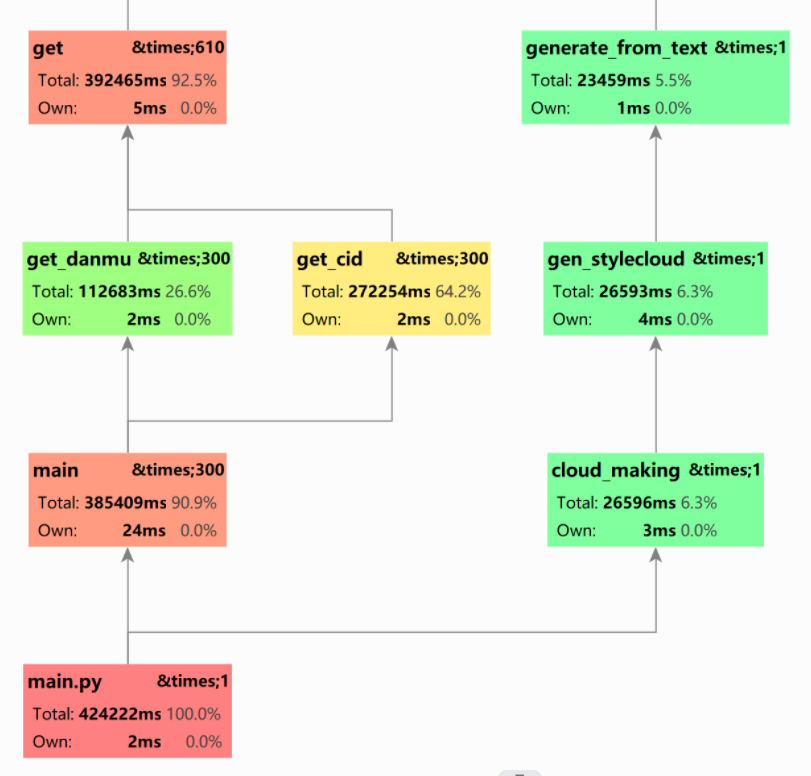
由以上图表可见,程序消耗最多的函数为get_cid(),可见对于cid以及弹幕的正则匹配耗时较大,以下将对其进行改进
这边我们采取的方法为“多进程并行”
对于爬取视频的URL、cid以及弹幕时,都需要进行多重循环
正常的python程序默认是单进程模式,从而对计算资源产生一定的浪费
这边我们增加并行进程数,使得爬取可以并行展开,从而大大提高效率
以下代码,实现30个进程同时运作,进行cid码以及弹幕获取的工作
def main(urls):
pool = multiprocessing.Pool(30) # 创建30个进程,一页有30个视频
for url in urls:
pool.apply_async(get_danmu.main(url)) # 并行爬取弹幕数据
pool.close() # 关闭进程池,表示不再接受新的任务
pool.join() # 等待所有进程任务完成
总时间为384.657s

总的来说有着很大的改进
结论:弹幕数据可见B站用户们对于保护海洋和地球的呼声非常高,对于日本核污染水排海是坚决抵制的,对于中国应对日本行为的措施也是持支持的态度
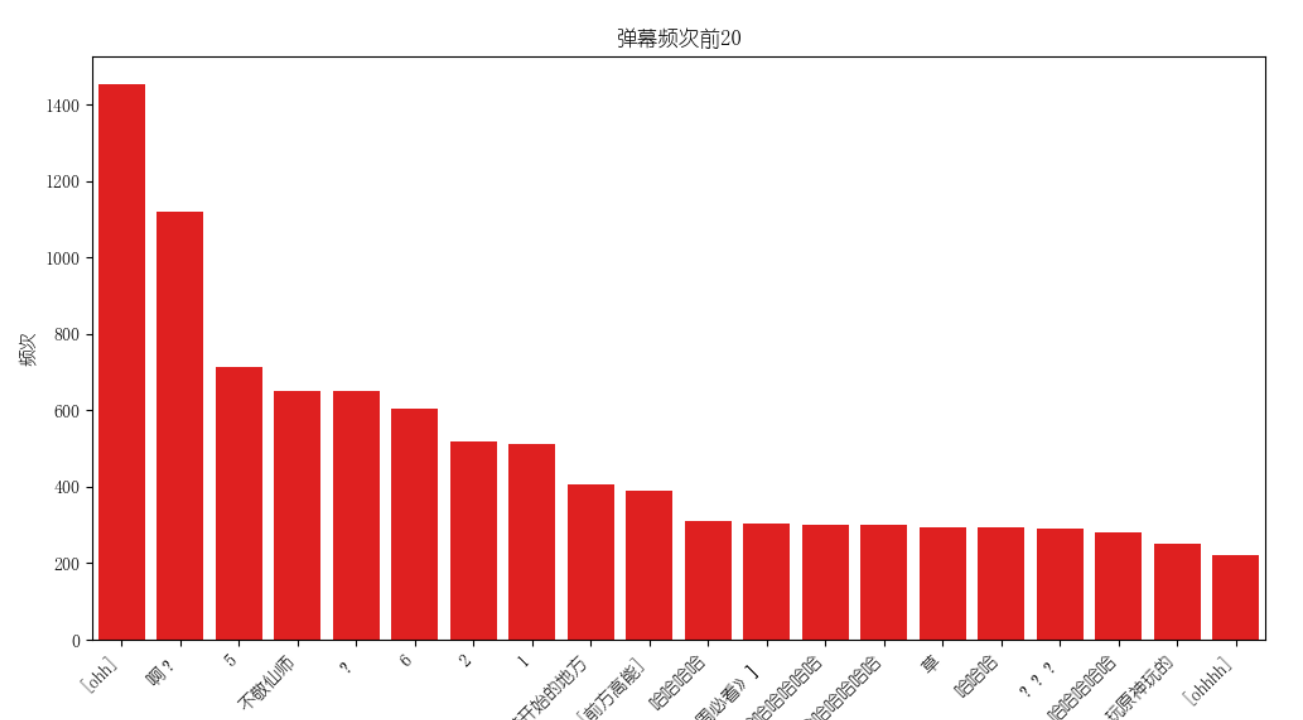
此结论通过弹幕频次前20的数据得出,这些数据出现最多的是“保护海洋”、“见证历史”、“支持”等,数据展示如下:
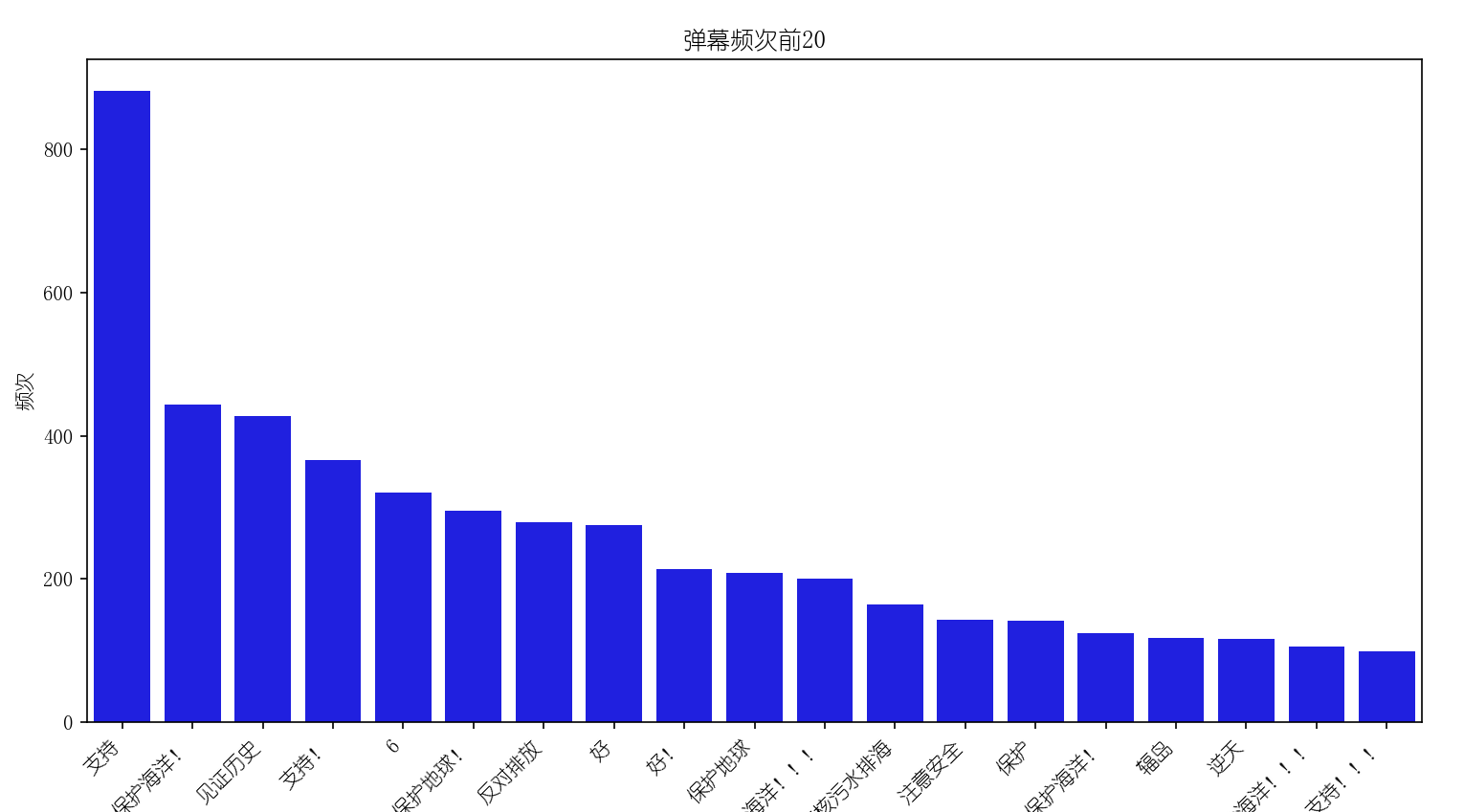
再次说明,此处的”支持”指的是用户们对中国政策的态度,坚决抵制日本的行为
利用stylecloud的词云库,将弹幕列表转换为词云图,同时规定好其属性
def cloud_making():
https://img-community.csdnimg.cn/images/40ae7b223b5048f297e287e55f4bcdbf.png "#left")
stylecloud.gen_stylecloud(file_path='danmu.txt', # 存储弹幕的文件位置
icon_name='fas fa-radiation', # 云图图标
palette='cmocean.diverging.Balance_6', # 调色板
font_path="msyh.ttc", # 字体信息
background_color='white', # 背景颜色
output_name='cloud.jpg', # 输出图片文件名
gradient='horizontal', # 渐变
invert_mask=True, # 是否反转
size=2048, # 图片大小
)
效果图如下:

利用python第三方库matplotlib.pyplot以及seaborn,将导入的字典输出为柱状图
def chart_making(labels, values):
plt.rc("font", family='YouYuan') # 设置字体防止乱码
fig, ax = plt.subplots(figsize=(12, 6)) # 创建一个图表
sns.barplot(x=labels, y=values, ax=ax, color='blue') # 绘制柱状图
ax.set_title("弹幕频次前20")
ax.set_xlabel("弹幕")
ax.set_ylabel("频次")
ax.set_xticklabels(labels, rotation=45, ha='right') # 设置x轴标签为斜着显示
plt.show() # 显示图表
效果图如下:
爬虫这次作业我的收获是真的大,过程也是十分的折磨,特别是在获取视频的URL时,我第一次获取时,只能获取到第一页的视频地址,甚至还一直都未发现,直到和其他同学对弹幕数量时,才发现弹幕的数量少了很多,然后在学习了几个视频之后,我对换页条件进行了重新规定,又出现了问题,翻一页之后便不能再翻页,可以说浏览器就是这么的复杂,非常之折磨。
经过这次我可以说自己已经在爬虫以及数据可视化的道路上走出了一大步,我踩过无数的坑,在下一次的爬虫实战中我觉得自己一定能做的更好
爬取了B站搜索关键词为原神的前300个视频中的弹幕,并做了词云分析和数据可视化,如下图:

可见原神玩家在B站的活跃

这个附加题你是懂得投评测组所好的,你是不是看了楚渔的第一次博客作业哈哈哈哈哈哈哈哈哈哈哈哈哈

附加题满昏!


