


118
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享Github链接:https://github.com/jockerUtf-8/pythonSpider
| Personal Soft ware process Stages | 预估耗时(min) | 实际耗时(min) |
|---|---|---|
| 估计这个任务需要多长时间 | 600 | 1000 |
| 计划 | 10 | 60 |
| 开发 | 40 | 140 |
| 需求分析 | 50 | 50 |
| 生成设计文档 | 50 | 50 |
| 代码规范 | 30 | 60 |
| 具体设计 | 30 | 60 |
| 具体编码 | 250 | 400 |
| 代码复审 | 20 | 30 |
| 测试 | 40 | 50 |
| 报告 | 40 | 50 |
| 测试报告 | 30 | 30 |
| 计算工作量 | 10 | 10 |
| 事后总结 | 10 | 10 |
一共拆成了3个部分,第一部分就是获取弹幕的url,由于之前没有python爬虫的经验,学了点基础课就开始上手了,查资料得知,把视频的地址的bilibili改成ibilibili,点进去才能找到弹幕的地址,所以我先寻找了300个视频的url,然后失败了好多次,最后才将视频地址找到,最后才是弹幕地址,其中我运用了xpath寻找到了视频的地址,也算是学会了很多第二部分就是处理弹幕内容,统计弹幕数量,我借助chatgpt的提示,采用字典匹配的模式处理文本中的每一行弹幕数据,最后将其倒序输出.第三部分则是数据的可视化表示我通过学习词云图的绘制方法以及excel的相关操作进一步完善数据。
首先我导入了以下几个包:
import time
from selenium import webdriver#selenium的浏览器真实模拟器
from selenium.webdriver.common.by import By
import requests#request请求方便快捷
import re#正则表达式
import wordcloud#词云专属包
import jieba#处理文字专用包
接着就是找到前300个弹幕的url地址并将其写入文件:
if __name__ == '__main__':
Link = []#记录300个视频的url
count = 0
proxy = {'http': '182.34.102.153:9999'}#我爬虫的次数太多了,ip被B站列入了黑名单,只能请求代理
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Mobile Safari/537.36'}
# 搜索关键词后第一页的网页地址
url = ['https://search.bilibili.com/all?keyword=%E6%97%A5%E6%9C%AC%E6%A0%B8%E6%B1%A1%E6%B0%B4%E6%8E%92%E6%B5%B7']
for i in range(14): # 每页是24个视频,至少要打开14页才能爬取到300个视频
if (i > 0): url.append(url[0] + '&page=' + str(i + 1) + '&o=' + str(24 * i)) # 第二页以后每页地址的规律格式
driver = webdriver.Chrome()
for i in range(14):
driver.get(url[i])
time.sleep(1) # 需要等待1秒,不然会因页面点击太快而出错
if (i == 0):
for j in range(24):
response = driver.find_element(By.XPATH,'/html/body/div[3]/div/div[2]/div[2]/div/div/div/div[2]/div/div[' + str(j + 1) + ']/div/div[2]/a') # 第一页中所有视频url的xpath规律格式
link = response.get_attribute('href') # 获取当前视频的url
link = link.replace('bilibili', 'ibilibili') # 弹幕信息在ibilibili的地址中
Link.append(link) # 收集url
count += 1
else:
for j in range(24): # 同第一页的代码同理,只是xpath的格式不同
response = driver.find_element(By.XPATH,'/html/body/div[3]/div/div[2]/div[2]/div/div/div[1]/div[' + str(j + 1) + ']/div/div[2]/a')
link = response.get_attribute('href')
# response.click()
link = link.replace('bilibili', 'ibilibili')
Link.append(link)
count += 1
if (count > 300): # 当获取的url达到300个时结束循环
break
for i in range(300):
response=requests.get(url=Link[i],headers=headers,proxies=proxy)#获取视频信息
content = response.text#获取信息文本
pattern = r'cid":"\d+"'#弹幕地址存储在信息文本中的cid中
match = re.search(pattern, content)#以上述模式寻找信息
cid=match.group()#group为匹配到的目标字符串
cid=cid.lstrip('cid":"')
cid=cid.rstrip('"')#去除边角
url='https://api.bilibili.com/x/v1/dm/list.so?oid='+cid#拼凑出弹幕的地址
print(url)
response=requests.get(url=url,headers=headers)#请求弹幕内容
response.encoding='utf-8'
contentList=re.findall('<d p=".*?">(.*?)</d>',response.text)#提取有效信息
for content in contentList:#写入弹幕.txt
with open('弹幕.txt','a',encoding='utf-8')as fp:
fp.write(content)
fp.write('\n')
由于本人比较菜,我自己摸索出来的办法就是就是通过xpath的规律找到300个视频的url地址,然后找到每个视频的cid并生成对应弹幕的地址,并将他们下载进来,时间复杂度比较大.
部分弹幕.txt文件如下,显然,内容会有很多冗余:
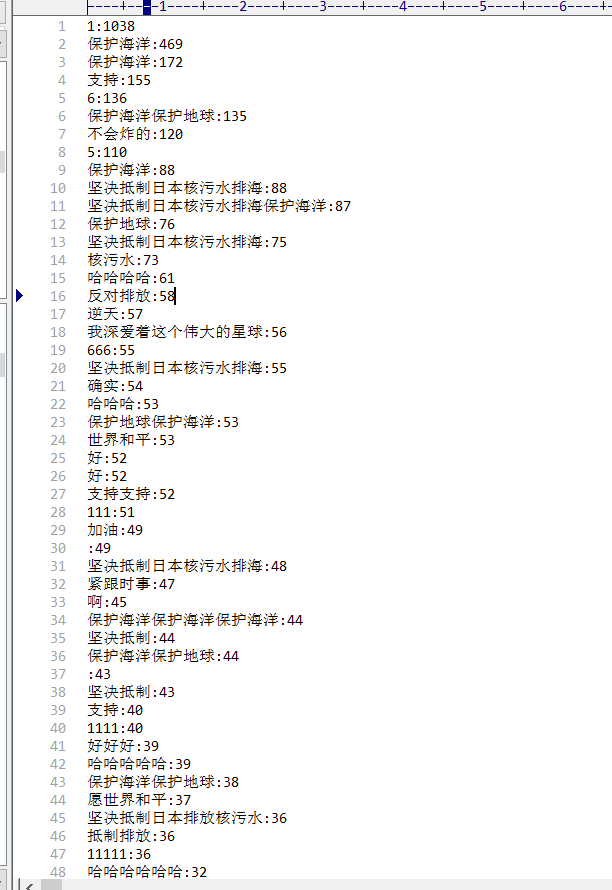
然后就是将采集到的数据文件弹幕.txt中的弹幕逐行读取到字典中,统计每种弹幕的数量,并将其输出到另一个文件B站弹幕中:
with open('弹幕.txt','r',encoding='utf-8')as fp:
lines=fp.readlines()#逐行读取文件
lineCount={}#建立空字典
for line in lines:#统计弹幕数
if line not in lineCount:#如果不在字典中,就创建新的数据
lineCount[line]=1
else:
lineCount[line]+=1#在字典中,就让次数加一
sortedDict = sorted(lineCount.items(),key=lambda x:x[1],reverse=True)#对字典进行降序排序
for i in range(len(sortedDict)):#循环每一个元组
danmu=str(sortedDict[i])#转化为字符串后更好处理
danmu=re.sub(r'[^\w\s,]','',danmu)
danmu=danmu.replace('n, ',':')#对字典中的元素规范化之后再写入文件
with open('B站弹幕.txt', 'a', encoding='utf-8') as fp:
fp.write(danmu)
fp.write('\n')
经过初步的处理,已经基本将数量统计出来了,但由于不同人输入格式的问题(比如有些人会多输入一些空格,不好识别)接下来可以用excel的合并计算的功能将冗余数据合并在一起,并且去除一些没有价值的弹幕信息。
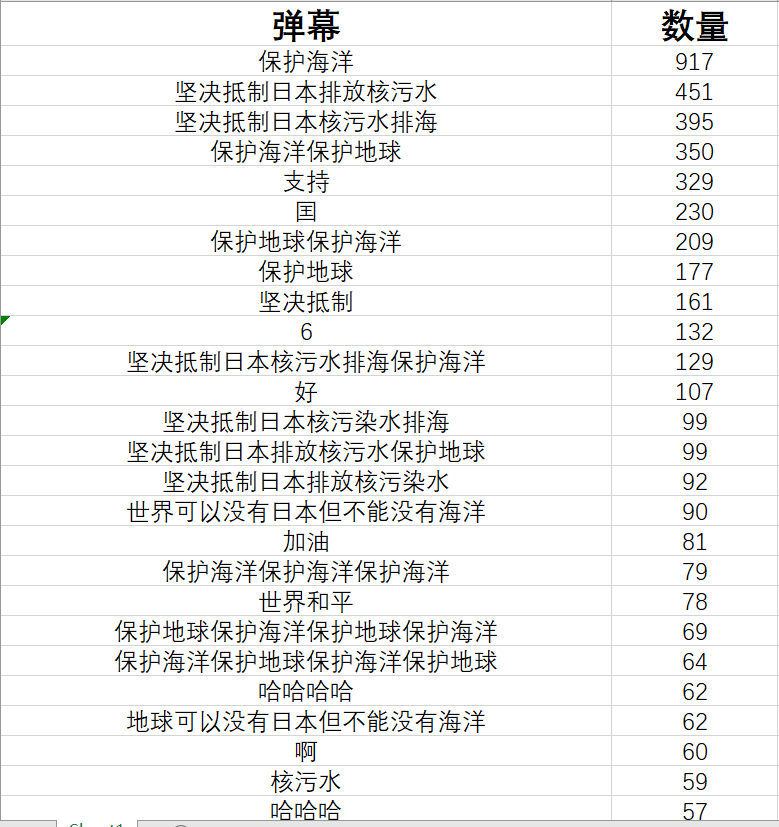
制作词云图:
f=open('B站弹幕.txt',encoding='utf-8')
txt=f.read()
string=' '.join(jieba.lcut(txt))
print(type(string))
wc=wordcloud.WordCloud(
width=700,#宽和高各700
height=700,
background_color='white',#背景白色
scale=15,#规模
font_path='STXINWEI.TTF'#字体
)
wc.generate(string)
wc.to_file('弹幕词云.png')
结果如下:

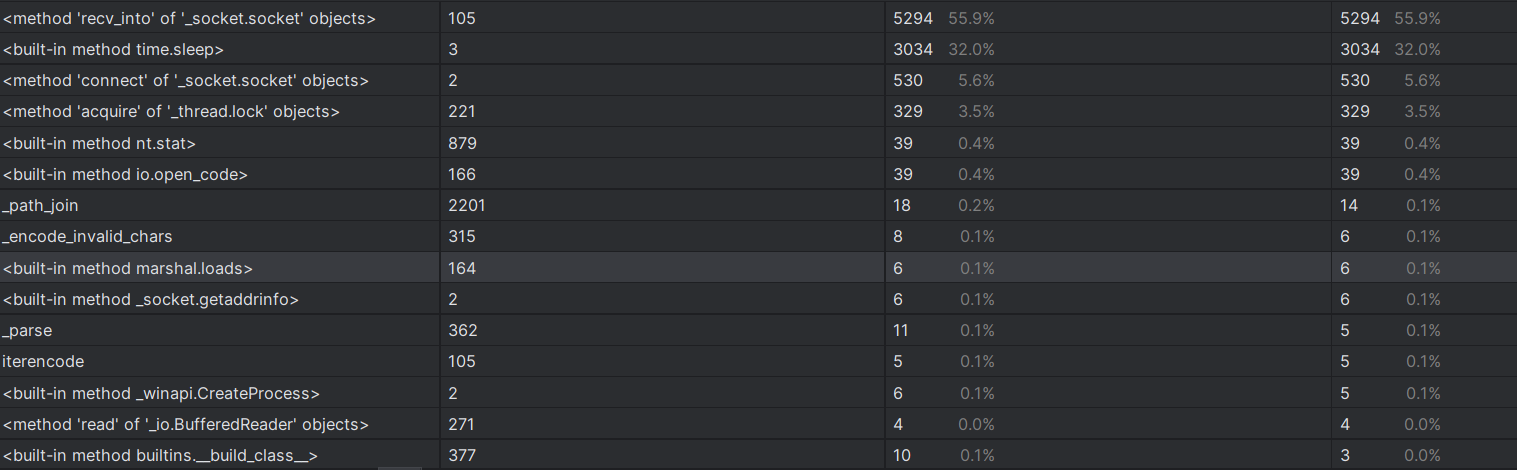
我一共写了三个.py的文件分别为爬取弹幕.py,统计数据.py和制作词云.py,使用pycharm自带的性能分析工具得出的结果如下(由于篇幅有限,只展示耗时最长的爬取弹幕的文件的结果):
以下这些是我通过将数量最多的100条弹幕让chatgp分析t得出的中国网友主流观点:
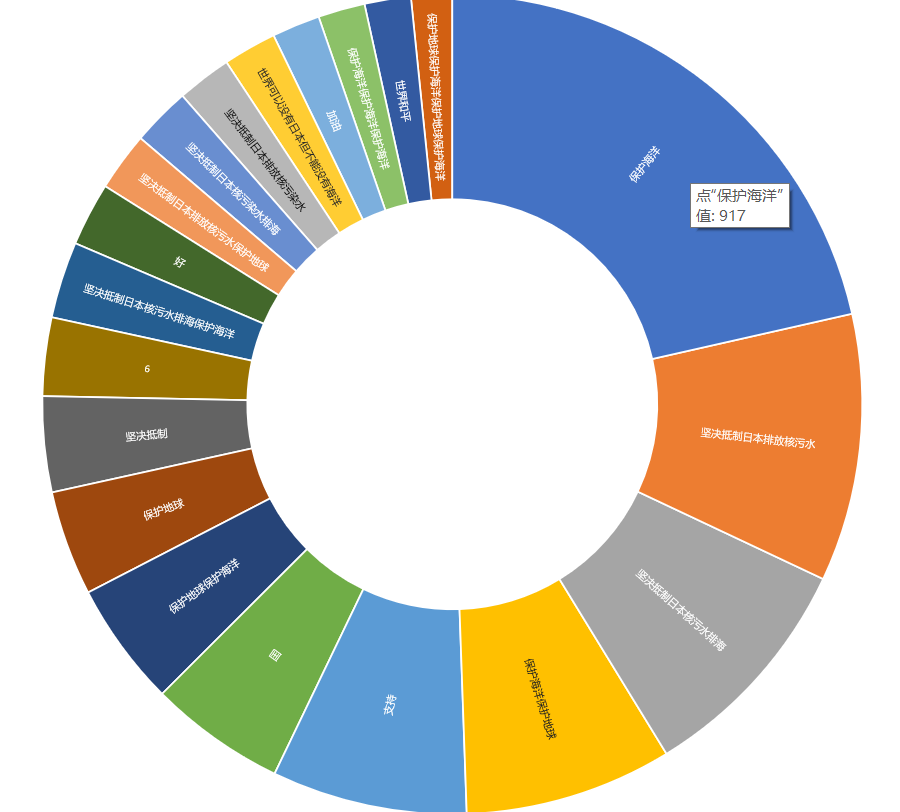
在制作数据可视化图像词云图的过程中。由于wordcloud函数需要传入规范化的字符串,所以我用了jieba库中的lcut函数将从B站弹幕中读出来的内容变成一行一行的,以方便生成词云图,并在wordcloud函数中输入相应的参数如长宽,背景颜色等,制作完词云图后,我也用处理后的excel表格的前20行生成了旭日图表:
在执行本次任务之前,我完全没学过爬虫,编程能力也很弱,但在这次实验中,我先学习了B站上的python爬虫的基本课程,然后上手实践,其中虽然遇到了许多困难,但在我的慢慢摸索和chatgpt的提示下,也算是圆满完成了,虽然和大佬们没法比,但对我自己来说已经是一个非常大的进步了,同时也让我意识到自身编程能力的不足,今后我也会更多地进行实操,学习更多的专业知识


