



118
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享(1.1)作业链接:https://github.com/Zslown/102101529
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 600 | 720 |
| Development | 开发 | 120 | 160 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 90 |
| · Design Spec | · 生成设计文档 | 20 | 20 |
| · Design Review | · 设计复审 | 20 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| · Design | · 具体设计 | 60 | 80 |
| · Coding | · 具体编码 | 120 | 140 |
| · Code Review | · 代码复审 | 20 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 70 |
| Reporting | 报告 | 40 | 50 |
| · Test Repor | · 测试报告 | 20 | 20 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| · 合计 | 620 | 740 |
五个环节:计划工作,准备工作,代码实现,代码测试 ,代码修改
计划工作阶段:我先是通过邹欣老师的博客制作了自己的PSP表格,然后严格按照表格的计划紧锣密鼓地推进任务
准备工作阶段:我通过B站,知乎教程先是提前了解了可能即将会用到的库函数,同时也在此期间获取到了b站视频以及弹幕的接口地址,
代码实现阶段:通过b站教程的实习,我跟着一点一点敲出能够完成以下功能代码:获取bv号,获取cid,获取弹幕数据,统计并写入Excel,制作词云图
代码测试阶段:可以从结果入手,例如打开Excel看一下弹幕量,才三四万是肯定不够的,就说明代码有错误;或者在中间加上Test函数来测试
代码修改阶段:修改上述阶段遇到的bug,并将代码进行封装,减少耦合性,同时加上注释,按照规范修改,增加可读性。
技术栈:BeautifulSoup库,pandas库,request库,stylecloud库
业务逻辑:通过调取关键词搜索的页面来批量获取视频的bv号,同时注意到url带有page属性,通过修改page属性来完成翻页,以爬取300个bv号—>通过bv号进入官方的弹幕接口,获取b站弹幕地址—>批量爬取弹幕数据,进行频次统计并排序—>将完整弹幕列表写入txt,输出频次Top20弹幕,并将其与频次统计表分别写入Excel—>使用txt文件绘制词云图
说明:由上述内容可知,需要get_bvid('网址'),get_cid('bv号列表'),get_danmu('cid列表'),sort_danmu('弹幕列表'),这几个主要函数,get_bvid提供bv号给get_cid获取cid—>get_cid提供cid给get_danmu爬取弹幕—>get_danmu提供弹幕给sort_danmu进行统计整理,然后写入文档,最后绘制词云图
关键代码:
一、get_bvid函数:选取搜索网页的url进行爬取,在数据包中发现BV号在tag为a class属性值为'img-anchor'中,可以转为str类型并进行截取
def get_bvid():
try:
bv_list = []
for page in tqdm.tqdm(range(15)):
# 进行翻页操作
page += 1
#对页面发送请求
r1 = requests.get(url='*****'&page={}'.format(page), headers=headers)
#获取爬取的视频内容
html1 = r1.text
# 爬虫解析页面
soup = BS(html1, 'xml')
# 搜索标签为a class属性值为img-anchor的内容 会得到视频的url(str类型)
video_list = soup.find_all("a", class_ = "img-anchor")
# 对于一页内的20个视频进行循环,并将bv号存入列表中
for i in tqdm.tqdm(range(20)):
b_v = (video_list[i]).get('href')
bvv = b_v[25:37]
bv_list.append(bvv)
# print(bvv)
except Exception as e:
print("get_bvid出错:", e)
return bv_list
二、get_cid函数:利用bvid和comment接口进入B站弹幕地址,爬取json数据包,并截取其中cid
def get_cid(bv_list):
try:
cid_list = []
# 遍历列表内的300个bv号获取cid列表
for i in tqdm.tqdm(range(len(bv_list))):
# 对某个视频发送请求
r2 = requests.get(url=f'https://api.bilibili.com/x/player/pagelist?bvid={bv_list[i]}', headers=headers)
# 将页面内容转换成json数据包
html2 = r2.json()
# 获取视频对应的cid号
cid = html2['data'][0]['cid']
cid_list.append(cid)
except Exception as e:
print("get_cid出错:", e)
return cid_list
三、get_danmu()利用cid以及comment接口爬取弹幕数据
def get_danmu(cid_list):
try:
for cid in cid_list:
danmu_url = 'http://comment.bilibili.com/{}.xml'.format(cid)
# 对弹幕页发送请求
r3 = requests.get(danmu_url)
r3.encoding = 'utf-8'
html3 = r3.text
soup = BS(html3, 'xml')
# 搜索所有标签为d的内容
text_list = soup.find_all('d')
for t in text_list:
danmu_list.append(t.text)
# 在生成弹幕列表的同时进行词频的统计
# 没出现过的弹幕数量赋初值1
if danmu_dict.get(t.text) is None:
danmu_dict[t.text] = 1
# 出现过的弹幕数量加1
else:
danmu_dict[t.text] += 1
# 选取出现频次Top20的弹幕
except Exception as e:
print("get_danmu出错:", e)
return danmu_dict
四、sort_number函数:将得到的字典转化成元组并按照value值排序,最后复写回原字典
def sort_danmu(danmu_dict):
try:
danmu_number_dict = {}
# 将字典类型转换为元组,并且key值和value值交换
danmu_tuplelist = [(danmu_value, danmu_key) for danmu_key, danmu_value in danmu_dict.items()]
# 用元组的sorted函数实现对value的排序
danmu_tuplelist_sort = sorted(danmu_tuplelist, reverse=True)
# 将元组内容回写入字典内
for i in range(20):
danmu_number_dict[(danmu_tuplelist_sort[i][1])] = danmu_tuplelist_sort[i][0]
# 将频次Top20写入文档
except Exception as e:
print("sort_danmu出错:", e)
return danmu_number_dict
性能分析:我用的是Pycharm专业版自带的profile进行图形化分析,分析图如下:

# 创建一个进程数为15的进程池
sum_pool = multiprocessing.Pool(processes=15)
# 循环创建15个进程
for k in range(15):
sum_pool.apply_async(get_danmu(), args=(k, danmu_txt))
# 关闭进程池
sum_pool.close()
# 等待所有进程任务结束
sum_pool.join()
对比一下改进前后的数据
修改前:

修改后:

可以看到运行时间减少了约100秒,证明了增加线程数的可行性
数据结论:弹幕数据表明大多数B站网友对日本核废水排海持反对态度,对保护海洋和保护地球呼声很高
这个数据结论是我通过统计弹幕词组出现频次归纳总结出来的,在这些弹幕中“保护地球”“保护海洋”“坚决反对”“抵制排海“等字样出现次数较多,图片如下:
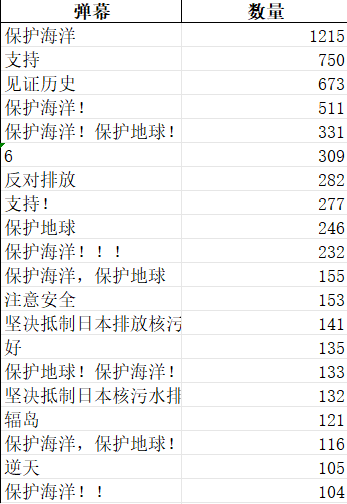
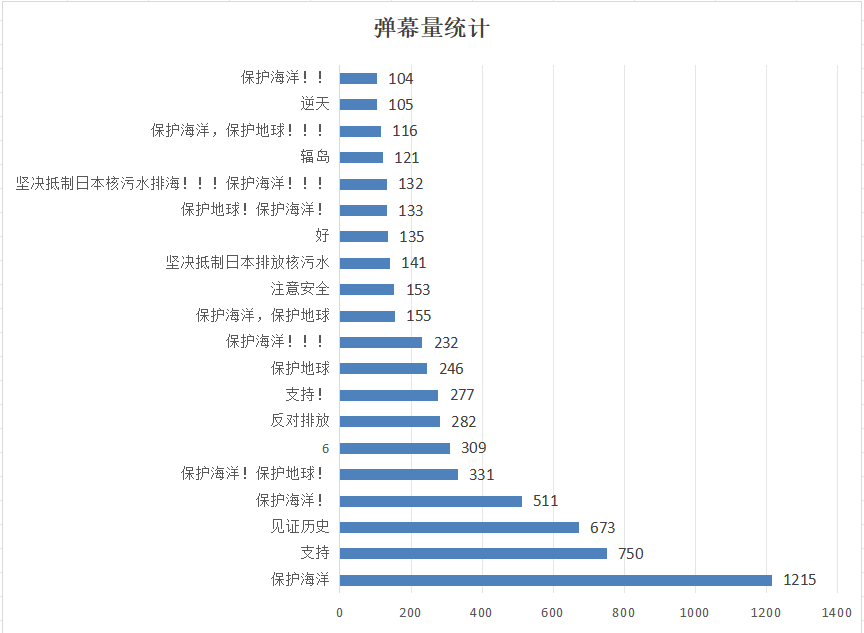
弹幕的词云可视化页面展示:

词云图绘制代码如下:
def get_wordcloud():
stylecloud.gen_stylecloud(file_path='danmu.txt',
icon_name='fas fa-globe',
palette='colorbrewer.diverging.Spectral_11',
background_color='black',
gradient='horizontal',
font_path='msyh.ttc',
custom_stopwords=["保护海洋","见证历史"],
size=2048,
output_name='弹幕.png')
)
首先从完成的体验来讲,这次任务可以说是相当有趣,很符合我过去对于计算机专业的部分想象——全自动爬取数据,手指在键盘上敲打就能够爬取这么庞大的数据,这一次是爬取b站弹幕视频,这让我非常期待未来深入学习Python之后爬取一些文本、图片、音频和视频(合法爬取)并打包;另外Python语言也是我很早之前就了解但是一直没有展开学习的脚本语言,这一次任务也让我半正式地开始了Python学习之路。
其次,谈谈这一次任务的完成过程,由于过去从未学习过Python,所以这一次任务对我来说是相当具有挑战性的,我得在十天之内从“Hello World”都不会输出的Python小白进化成能够完成一个小小项目的码农。初步学习Python之后,我的第一想法就是Python真是太方便了——变量不用定义;有一堆库可以用,种类繁多,功能全面;交互性强,和之前学的C/C++完全不一样。后来学习爬虫相关知识,了解request库,re(正则表达式)库,BeautifulSoup(爬虫解析)库的基本运用,在B站、csdn和知乎找了无数个教程,见识各种各样的代码风格,最终糅合成了这一个爬取B站弹幕数据代码。
最后,这次任务虽然艰巨但是意义非凡,这次作业让我浅尝到了Python带来的魅力,我也坚信我能够在这一学期的软件工程学习上面学到更多知识,完成写出一款小程序、制作一个APP、搭建一个服务器这些我小时候就一直想尝试的东西。


