


65,211
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
import urllib.request
from lxml import etree
import os
def create_request(page):
if page == 1:
url = 'https://sc.chinaz.com/ppt/pptbeijing.html'
else:
url = 'https://sc.chinaz.com/ppt/pptbeijing' + str(page) + '.html'
headers = {'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
return request
def get_content(request):
try:
respond = urllib.request.urlopen(request)
content = respond.read().decode('utf-8')
return content
except Exception as e:
print('请求错误')
def down_load(content):
tree = etree.HTML(content)
name_list = tree.xpath('//img[@class="lazy"]/@alt')
src_list = tree.xpath('//img[@class="lazy"]/@src')
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
url = 'http:' + src
urllib.request.urlretrieve(url=url, filename='./img/' + name + '.jpg')
if __name__ == '__main__':
start_page = int(input('请输入起始页数'))
end_page = int(input('请输入结束页数'))
for page in range(start_page, end_page + 1):
request = create_request(page)
content = get_content(request)
down_load(content)
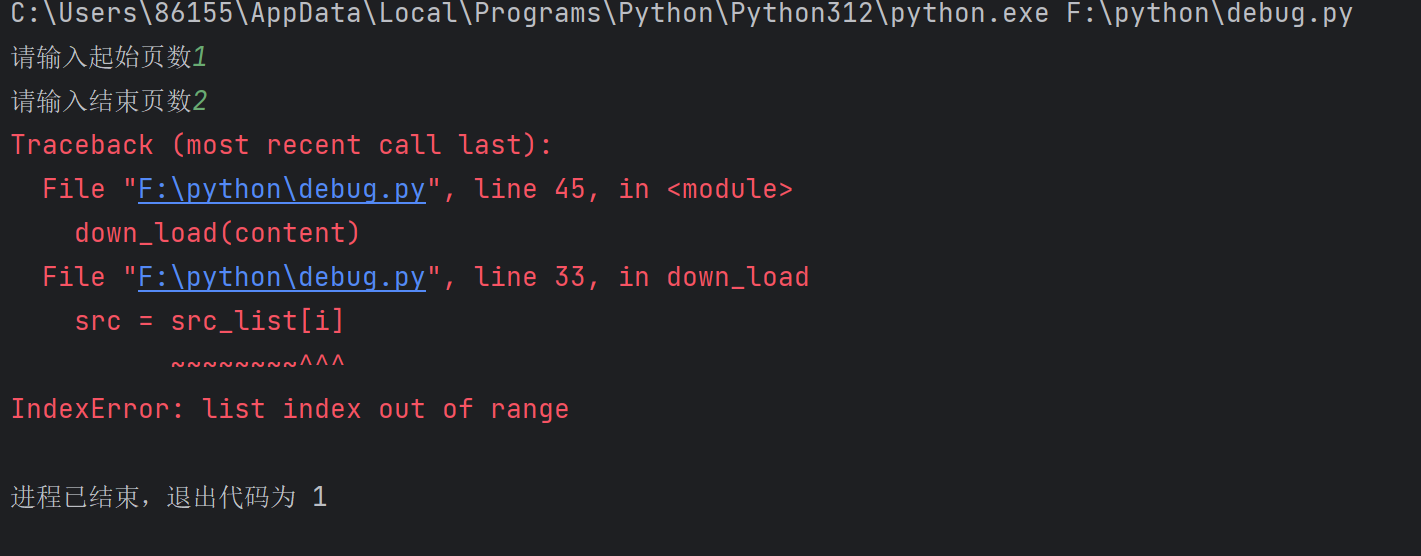
为什么执行时一直显示这些错误

越界了,就是说src_list中的元素个数小于你循环中的i



