


39
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

“task_struct” 是 Linux 内核中的一个非常重要的数据结构,用于表示每个正在运行的进程或线程。每个进程或线程都有一个关联的 `task_struct` 结构,其中包含了有关该进程或线程的各种信息,用于管理和跟踪其状态、资源、进程上下文以及与其他进程之间的关系。
“task_struct” 结构包括大量字段,其中一些重要的字段包括:
1. 进程标识符(PID):“task_struct” 中包含了一个字段,用于存储进程的唯一标识符,即 PID。PID 是用于唯一标识每个进程的整数值。
2. 状态信息:`task_struct` 存储了进程的状态信息,如运行中、等待中、停止等,以便内核了解进程的当前状态。
3. 调度信息:进程的调度信息,如调度类别、优先级、时间片等,用于操作系统的进程调度器来管理进程的执行。
4. 资源管理信息:包括进程的资源限制、打开文件描述符、信号处理程序、内存映射、进程锁定信息等,用于控制和管理进程所需的资源。
5. 进程上下文信息:保存了进程的寄存器状态、堆栈指针、指令指针等,以便操作系统能够在进程切换时保存和还原进程的执行上下文。
6. 进程的父子关系:`task_struct` 存储了与其他进程的父子关系,以便构建进程树和进行进程间通信。
7. 进程信号信息:包括挂起的信号、挂起的信号处理程序等,用于处理进程接收到的信号。
8. 进程优先级和调度信息:包括进程的调度优先级,以便操作系统的调度器确定进程的执行顺序。
“task_struct” 在内核中的使用非常广泛,它是 Linux 内核中进程管理的核心数据结构。当操作系统创建新的进程、进行进程切换、执行系统调用、管理资源分配等任务时,`task_struct` 中的信息起着关键作用。因此,“task_struct” 是 Linux 内核中的一个重要数据结构,用于维护和管理操作系统中的所有进程和线程的状态和信息。
“fork()” 函数是一个用于创建新进程的系统调用,它会创建一个新的进程,该进程是调用进程的副本,继承了调用进程的大部分属性和状态。在 Linux 内核中,“fork()” 函数的实现实际上是基于 “sys_clone” 系统调用的,而 “sys_clone” 是在内核中完成新进程的创建的关键部分。
下面是 “fork()” 函数对应的内核处理过程,以及新进程是如何创建和修改 “task_struct” 数据结构的:
1. 当应用程序调用 “fork()” 函数时,它会触发相应的系统调用,即 “sys_fork”。
2. 在 “sys_fork” 中,内核首先为新的进程分配一个新的 “task_struct” 数据结构,即新的进程控制块(PCB)。
3. 内核会将父进程的 “task_struct” 数据结构复制到新分配的 “task_struct” 中,以便新进程继承父进程的大部分属性和状态。这包括进程标识符(PID)、资源限制、打开文件描述符、信号处理程序等等。
4. 新进程的状态被设置为就绪状态,以便在适当的时间点被内核调度执行。
5. 新进程的系统调用返回给父进程,而新进程的 PID 返回给父进程。父子进程之间现在拥有相同的内存映射,但这些映射是写时复制(Copy-On-Write,COW)的,因此它们共享物理内存,直到其中一个进程尝试对共享内存进行写操作,此时内核会为写操作的进程创建一个独立的物理内存副本。
“fork()” 函数在 Linux 内核中的处理过程包括创建一个新的 “task_struct” 数据结构,复制父进程的大部分属性和状态,设置新进程的状态为就绪,并返回新进程的 PID 给父进程。父子进程之间在内核中共享一些资源,直到其中一个进程尝试修改共享资源,此时内核会为修改操作的进程创建新的资源拷贝,以实现写时复制(COW)的行为。这使得新进程的创建非常高效,因为只有在需要时才会真正复制资源。
cd LinuxKernel
rm -rf menu
git clone https://github.com/mengning/menu.git
//如果git失败,解除ssl验证后,再次git即可,git config --global http.sslVerify "false"
cd menu
make rootfs
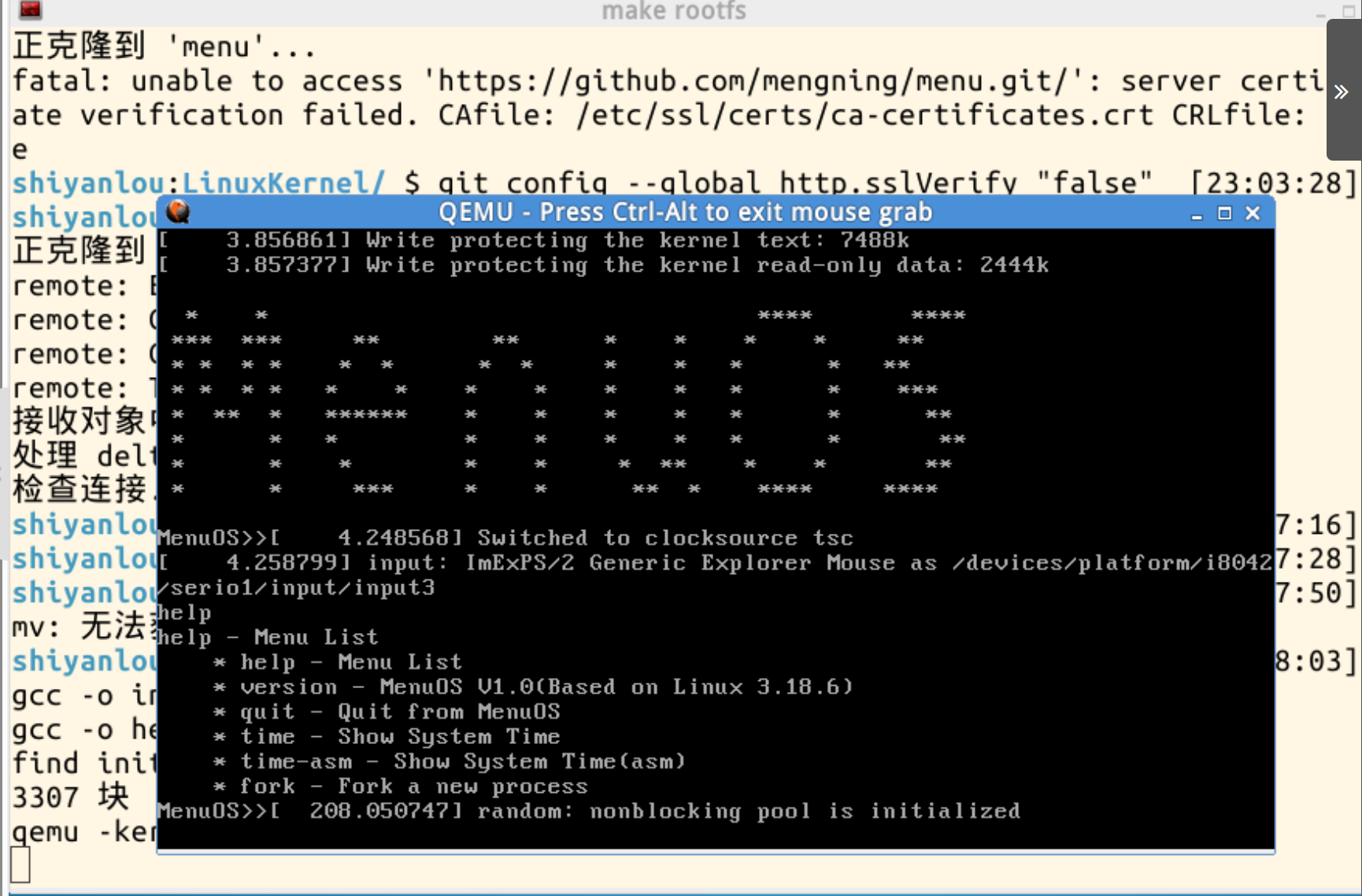
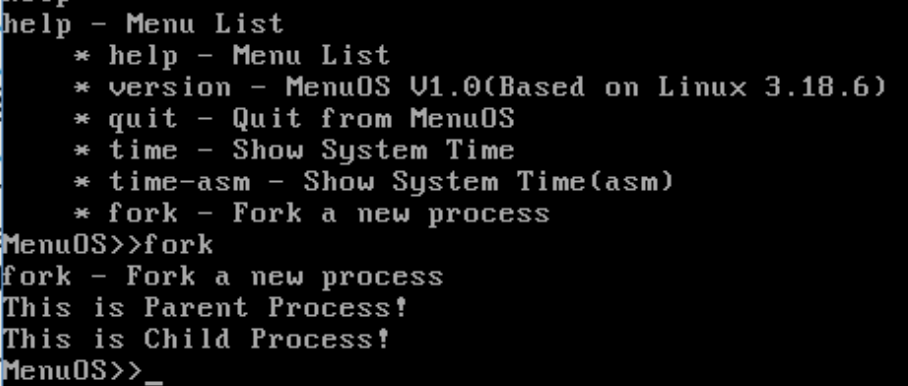
输入help命令后,执行fork,从图中可以看到fork函数创建了父进程与子进程。
通过增加-s -S启动参数打开调试模式;
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S
gdb vmlinux
// 打开gdb进行远程调试。
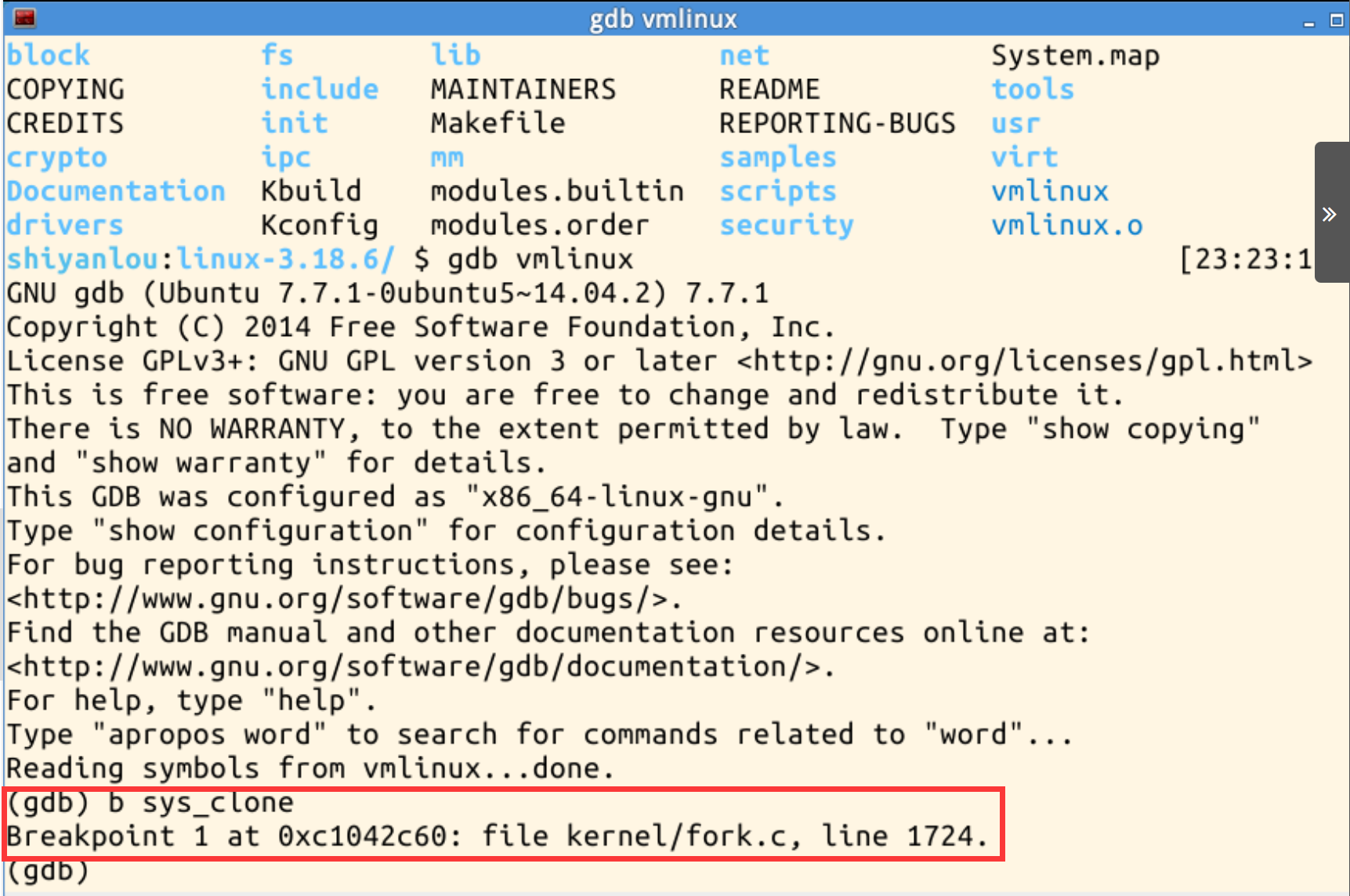
设置断点:
b sys_clone
b do_fork
b dup_task_struct
b copy_process
b copy_thread
b ret_from_fork
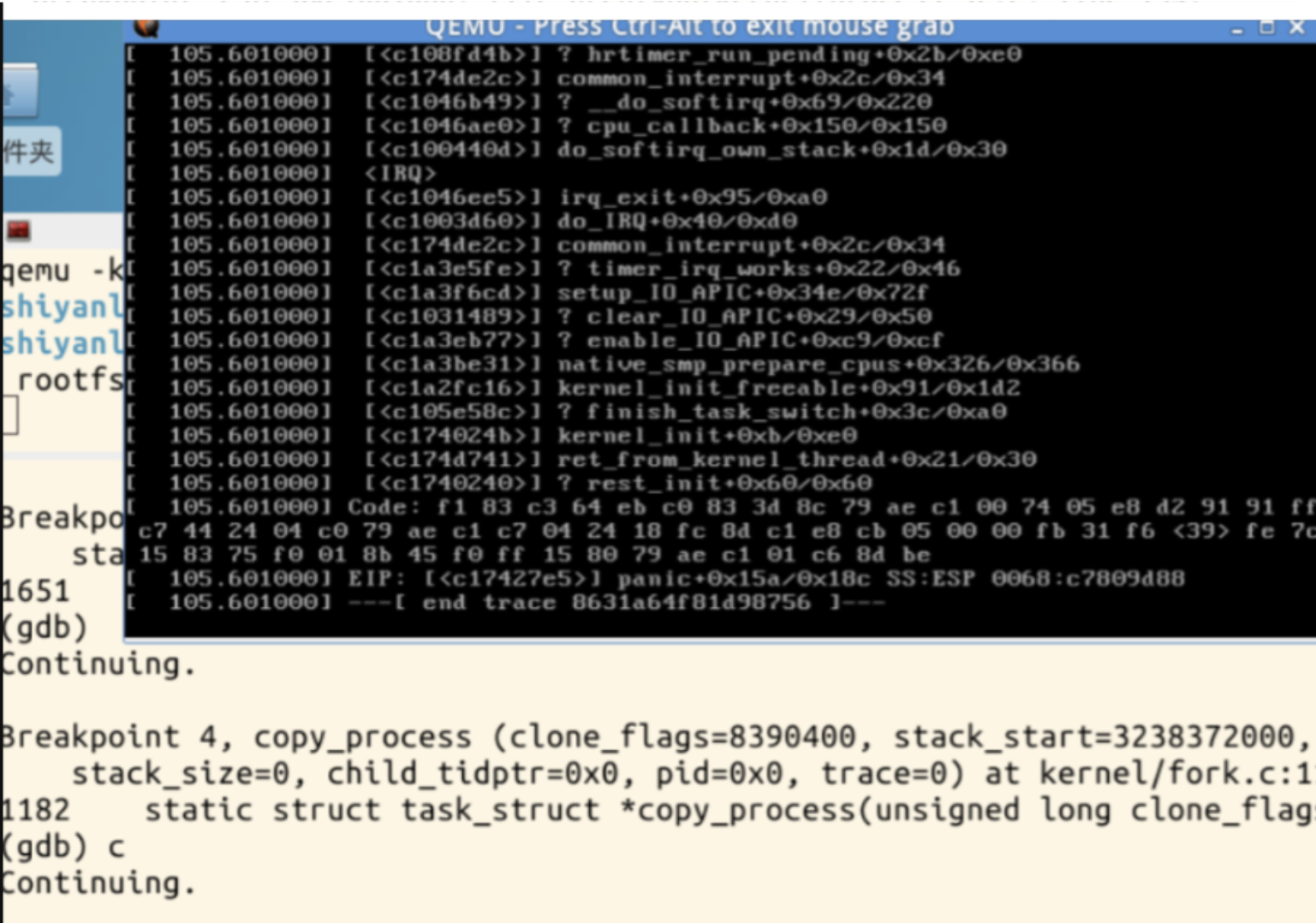
执行fork命令,停在了断点sys_clone处,按c继续执行,可以看到sys_clone的执行过程:
在内核中创建一个新进程的过程通常涉及多个函数和步骤,这些步骤可能会因操作系统的不同而有所变化,但通常会包括以下一般步骤:
1. 分配进程描述符:操作系统需要为新进程分配一个唯一的标识符,通常是一个进程描述符,用来存储有关该进程的信息。这通常涉及到分配内存和设置进程的状态信息。
2. 分配内存空间:为新进程分配一块内存空间,用来存储进程的代码、数据、堆栈等信息。这个步骤可能包括分配虚拟内存、物理内存的页面分配等。
3. 复制父进程的上下文:通常,新进程会继承一些父进程的属性,如文件描述符、环境变量等。这需要复制父进程的上下文信息。
4. 加载可执行文件:新进程通常需要加载一个可执行文件,这包括解析可执行文件的头部、分配内存、复制代码段和数据段到进程的内存空间等。
5. 初始化寄存器和堆栈:设置新进程的寄存器和堆栈,以便执行新进程的代码。这通常包括设置程序计数器(PC)以指向新进程的入口点,并设置堆栈指针(SP)。
6. 设置进程状态:将新进程的状态设置为就绪状态,以便调度程序可以在合适的时机运行它。
7. 将新进程添加到进程调度队列:操作系统通常会有一个进程调度队列,新进程将会被加入队列等待调度。
8. 调度新进程:调度程序会选择一个就绪状态的新进程来运行,将其上下文切换到CPU上。
9. 执行用户程序:新进程的代码开始在CPU上执行。
在Linux内核中,创建新进程通常涉及到函数调用,如`fork()`(创建子进程)、`exec()`(加载可执行文件)、`clone()`(创建轻量级进程)、`do_fork()`(创建新进程)等。这些函数会涉及到上述步骤的实现。具体的函数和步骤可能因操作系统的不同而有所不同,但上述步骤是一般的创建新进程的基本过程。
