




136,205
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享一、问题描述
某次python脚本爬取某网站https地址时,程序运行报错:ImportError: urllib3 v2.0 only supports OpenSSL 1.1.1+, currently the 'ssl' module is compiled with 'OpenSSL 1.1.0h 27 Mar 2018'. See: https://github.com/urllib3/urllib3/issues/2168

二、处理
Python urllib 库用于操作网页 URL,并对网页的内容进行抓取处理。上述报错是因为当前的urllib3中的版本与请求所需的不匹配,当前版本过低,需要升级,执行如下安装即可:
pip3 install urllib3==1.26.15 -i https://pypi.tuna.tsinghua.edu.cn/simple
urllib 包包含了以下几个模块:
urllib.request:打开和读取 URL。
urllib.error:包含 urllib.request 抛出的异常。
urllib.parse:解析 URL。
urllib.robotparser:解析 robots.txt 文件。
各子模块用法如下:
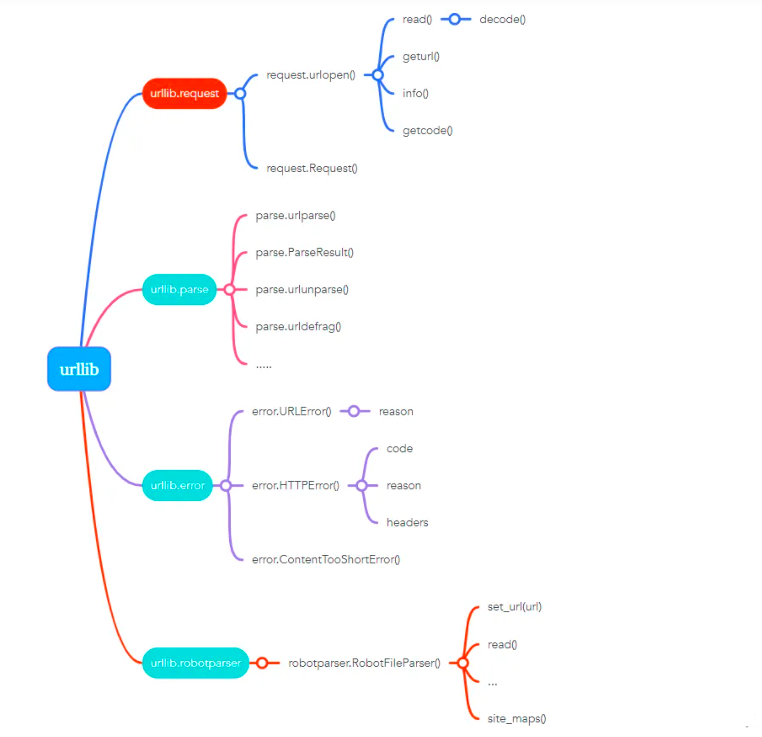
另外,正如上文脚本中代码片段,还需要引入.request,我们抓取网页一般需要对 headers(网页头信息)进行模拟,否则网页很容易判定程序为爬虫,从而禁止访问。这时候需要使用到 urllib.request.Request 类:
urllib.request 定义了一些打开 URL 的函数和类,包含授权验证、重定向、浏览器 cookies等。另外还有一个常用方法,urlopen
urllib.request 可以模拟浏览器的一个请求发起过程。
