



1,040
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享这是我参加朝闻道知识分享大赛的第三篇文章
(1) 函数:是组织好的,可重复使用的,用来使用特定功能的代码段。
# 需求:统计字符串的长度,且不使用内置函数len()
str1="itheima"
str2="itcast"
str3="python"
def my_len(data):
count=0
for i in data:
count+=1
print(f"字符串{data}的长度是{count}")
my_len(str1)
my_len(str2)
my_len(str3)
结果:
字符串itheima的长度是7
字符串itcast的长度是6
字符串python的长度是6
(1) 语法:
def 函数名(传入参数):
函数体
return 返回值
(2) 函数的调用: 函数名(传入参数)
def say_hi():
print("hello")
say_hi()
结果:
hello
(3) 注意:
(1) 传入参数的功能是:在函数进行计算的时候,接受外部(调用时)提供的数据。
# 定义相加的函数
def add(x,y):
result=x+y
print(f"{x}+{y}的计算结果是:{result}")
# 调用函数,传入被计算的2个数字
add(5,6)
结果:
5+6的计算结果是:11
(1) 语法:
def 函数名(传入参数):
函数体
return 返回值
变量 = 函数(参数)
# 定义一个函数,完成两数相加的功能
def add(a,b):
result=a+b
return result
# 返回结果后,还想输出一句话 return后面的代码都不会执行了
print("我完事了")
# 函数的返回值,可以通过变量去接收
r=add(2,2)
print(r)
结果:
4
(2) 函数返回值之None类型
# 返回None类型
def say_hi():
print("Hello")
res=say_hi()
print(res)
print(type(res))
结果:
Hello
None
<class 'NoneType'>
# None用于if判断
def check_age(age):
if age>18:
return "SUCCESS"
else:
return None
result=check_age(16)
if not result:
# 进入if表示result是None值,也就是False
print("未成年,不可以进入")
结果:
未成年,不可以进入
(1) 给函数添加说明文档,辅助理解函数的作用。
(2) 语法:
def func(x,y):
"""
函数说明
:param x:形参x的说明
:param y:形参y的说明
:return:返回值的说明
"""
函数体
return 返回值
# 定义函数,进行文档说明
def add(x,y):
"""
# 自动补全
add函数可以接收2个参数,进行两数相加的功能
:param x: 形参x表示相加的其中一个数字
:param y: 形参y表示相加的另一个数字
:return: 返回值是两数相加的结果
"""
result=x+y
print(f"两数相加的结果是:{result}")
return result
(3) 在PyCharm编写代码是,可以通过鼠标悬停,查看调用函数的说明文档。

(1) 定义:函数的嵌套调用指的是一个函数里面又调用了另一个函数。
# 定义函数func_b
def func_b():
print("----2----")
# 定义函数func_a,并在内部调用func_b
def func_a():
print("----1----")
# 嵌套调用func_b
func_b()
print("----3----")
func_a()
结果:
----1----
----2----
----3----
(2) 如果函数a中,调用了另一个函数b,那么先把函数b中的任务都执行完毕后才会回到上次函数a执行的位置,完成后,继续执行函a剩余的内容。
(1) 变量作用域指的是变量的作用范围(变量在哪里可用,在哪里不可用),主要分为两类:局部变量和全局变量。
(2) 局部变量:定义在函数体内部的变量,即只在函数体内部生效。作用:在函数体内部,在函数运行时临时保存数据,当函数调用完成之后,立刻销毁了局部变量。
# 演示局部变量
def test_c():
num=100
print(num)
test_a()
# 出了函数体,局部变量就无法使用了
# print(num)
(3) 全局变量:指的是在函数体内、外都能生效的变量。如果有一个数据,在函数a和函数b中都要使用,就可以将这个数据存储在一个全局变量中。定义这个变量在函数的外部。
# 演示全局变量
num=200
def test_a():
print(f"test_a:{num}")
def test_b():
print(f"test_b:{num}")
test_a()
test_b()
print(num)
结果:
test_a:200
test_b:200
200
(4) global关键字:可以在函数内部声明变量为全局变量。
# 使用global关键字,在函数内声明变量为全局变量
num=200
def test_a():
print(f"test_a:{num}")
def test_b():
global num
num=500
print(f"test_b:{num}")
test_a()
test_b()
print(num) # 输出的是500
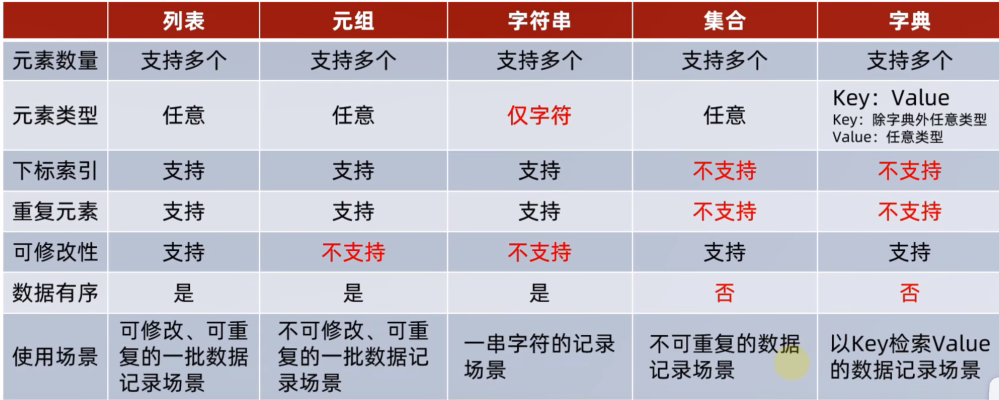
(1) 数据容器:一个容器可以容纳多份数据。
(2) 定义:一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素,每一个元素,可以是任意类型的数据,如字符串、数字、布尔等。
(3) 数据容器根据特点的不同,如:
分为5类,分别是:列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict)。
(1) 基本语法:
列表内的每一个数据,称之为元素。以[ ] 作为标识,列表内每一个元素之间用逗号, 隔开。
# 定义一个列表list
name_list=["itheima","itcast","python"]
print(name_list)
print(type(name_list))
my_list=["itheima",666,True]
print(my_list)
print(type(my_list))
结果:
['itheima', 'itcast', 'python']
<class 'list'>
['itheima', 666, True]
<class 'list'>
(2) 注意:
# 定义一个嵌套的列表
my_list2=[[1,2,3],[4,5,6]]
print(my_list2)
print(type(my_list2))
结果:
[[1, 2, 3], [4, 5, 6]]
<class 'list'>
(3) 列表的下标(索引):使用[ ]


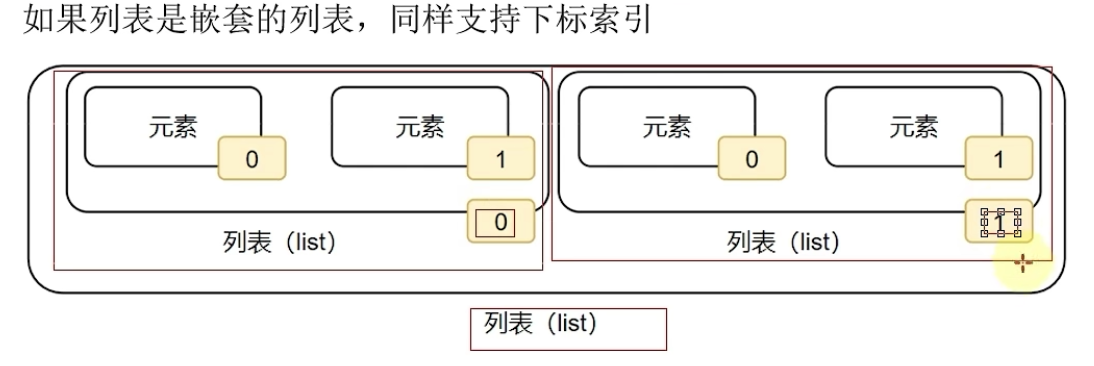
# 列表[下表索引],从前向后,从0开始,每次+1 从后向前,从-1开始,每次-1
print(my_list[0]) # Tom
print(my_list[1]) # Lily
print(my_list[2]) # Rose
# 错误示范:通过下标索引取出数据,一定不要超出范围
# print(my_list[3]) # 超出范围,数组越界
# 通过下标索引取出数据(倒序取出)
print(my_list[-1]) # Rose
print(my_list[-2]) # Lily
print(my_list[-3]) # Tom
# 取出嵌套列表的元素
my_list = [[1,2,3],[4,5,6]]
print(my_list[1][1]) # 5
(4) 列表的常用操作(方法):
在Python中,如果将函数定义为class(类)的成员,那么函数会称之为:方法。
方法和函数功能一样,有传入参数,有返回值,只是方法的使用格式不同:
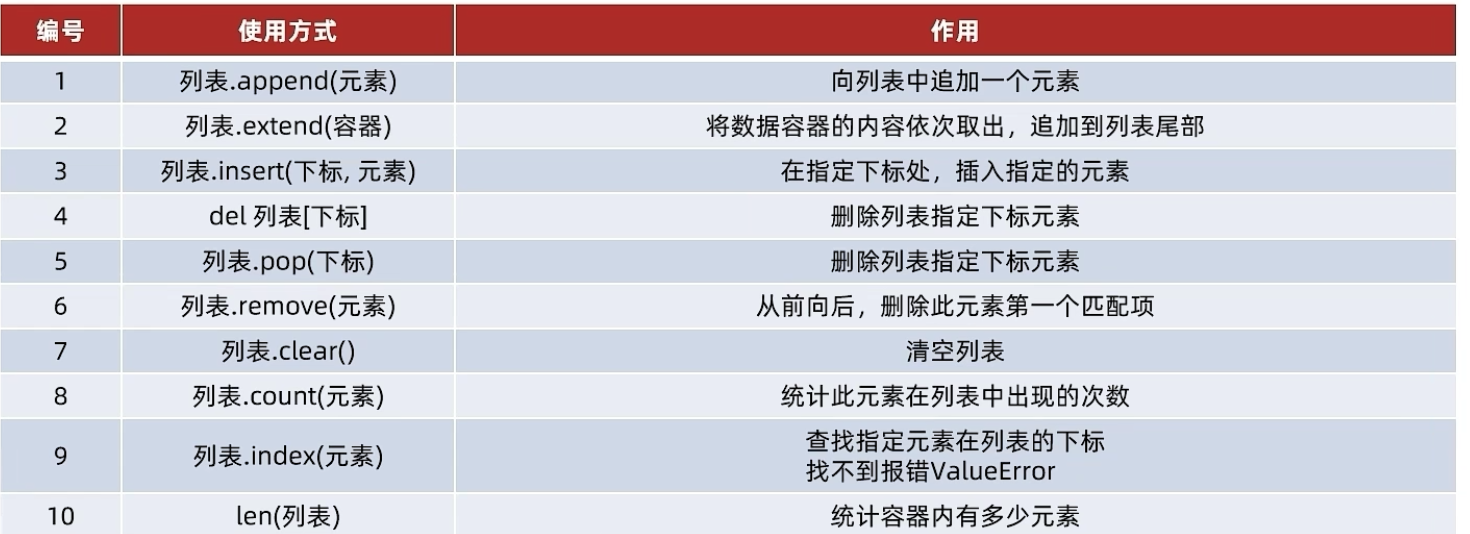
① 列表的查询功能(方法):
查找某元素的下标:查找指定元素在列表的下标,如果找不到,报错ValueError。
—— **语法:列表.index(元素)**。index就是列表对象(变量)内置的方法(函数)。
统计列表内,有多少元素:
—— **语法:len(列表)**。
② 列表的修改功能(方法):
修改特定位置(索引)的元素值:直接对指定下标(正向、反向下标均可)的值进行重新赋值(修改)。
—— 语法:列表[下标] = 值。
插入元素:在指定的下标位置,插入指定的元素。
—— **语法:列表.insert(下标,元素)**。
追加元素:将指定元素,追加到列表的尾部。
—— **语法1:列表.append(元素)**。
—— **语法2:列表.extend(其他数据容器)**。将其它数据容器的内容取出,依次追加到列表尾部。
删除元素:
—— **语法1:del 列表[下标]**。
—— **语法2:列表.pop(下标)**。
删除某元素在列表中的第一个匹配项:
—— **语法:列表.remove(元素)**。
清空列表内容:
—— **语法:列表.clear( )**。
统计某元素在列表内的数量:
—— **语法:列表.count(元素)**。
(5) 列表的特点:
(6) 列表的遍历:
① while循环:定义一个变量表示下标,从0开始,循环条件为下标值<列表的元素数量,使用列表[下标]的方式取出。
def list_while_func():
"""
使用while循环遍历列表的演示函数
:return: None
"""
mylist=["传智教育","黑马程序员","Python"]
index=0
while index<len(mylist):
element=mylist[index]
print(f"列表的元素{index+1}:{element}")
index+=1
list_while_func()
② for循环:从容器内,依次取出元素并赋值到临时变量上。在每一次的循环中,我们可以对临时变量(元素)进行处理。
def list_for_func():
"""
使用for循环遍历列表的演示函数
:return: None
"""
mylist=[1,2,3,4,5]
for element in mylist:
print(f"列表的元素有:{element}")
list_for_func()
③ 两者对比:
(1) 列表是可以修改的,如果想要传递的信息不被篡改,就需要元组。
元组一旦定义完成,就不可修改。
(2) 基本语法:定义元组使用小括号,且使用逗号隔开各个数据,数据可以是不同类型的
t1=(1,"Hello",True)
t2=()
t3=tuple()
print(f"t1的类型是:{type(t1)},内容是:{t1}")
print(f"t2的类型是:{type(t2)},内容是:{t2}")
print(f"t3的类型是:{type(t3)},内容是:{t3}")
# 定义单个元素的元组
t4=("hello",)
print(f"t4的类型是:{type(t4)},内容是:{t4}")
结果:
t4的类型是:<class 'tuple'>,内容是:('hello',)
# 元组的嵌套
t5=((1,2,3),(4,5,6))
print(f"t5的类型是:{type(t5)},内容是:{t5}")
结果:
t5的类型是:<class 'tuple'>,内容是:((1, 2, 3), (4, 5, 6))
(3) 元组的下标(索引):同列表list一样
(4) 元组的相关操作:
# 元组内容不可以修改,但是元组中的列表可以
t6=(1,2,["itheima","itcast"])
t6[2][0]="tef"
t6[2][1]="redf"
print(f"t6的内容是:{t6}") # t6的内容是:(1, 2, ['tef', 'redf'])
(5) 元组的特点:
(1) 定义:字符串是字符的容器,一个字符串可以存放任意数量的字符。每一个字符就是一个元素,每一字符也有下标索引。
(2) 字符串的下标(索引):和其他容器一样:列表、元组一样,字符串也可以通过下标进行访问。
(3) 同元组一样,字符串是一个:无法修改的容器。字符串的相关操作:
# replace方法
new_my_str=my_str.replace("it","程序")
print(f"将字符串{my_str},进行替换之后得到:{new_my_str}")
结果:
将字符串itheima and itcast,进行替换之后得到:程序heima and 程序cast
# split方法
my_str="hello python itheima and itcast"
my_str_list=my_str.split(" ") #按照空格划分,返回一个列表
print(f"将字符串{my_str}进行分割后,得到:{my_str_list},类型是:{type(my_str_list)}")
结果:
将字符串hello python itheima and itcast进行分割后,得到:['hello', 'python', 'itheima', 'and', 'itcast'],类型是:<class 'list'>
# strip方法
my_str=" itheima and itcast "
new_my_str=my_str.strip() #不传入参数,去除首尾空格
print(f"字符串{my_str}进行strip后,结果是:{new_my_str}")
my_str="12itheima and itcast21"
new_my_str=my_str.strip("12")
print(f"字符串{my_str}进行strip(‘12’)后,结果是:{new_my_str}")
# 并不是完全按照12来的,只要满足其中任意均可去除,实质上是按照每个字符来去除
结果:
字符串 itheima and itcast 进行strip后,结果是:itheima and itcast
字符串12itheima and itcast21进行strip(‘12’)后,结果是:itheima and itcast
(4) 字符串的特点:
(5) 字符串大小比较:
(1) 集合最主要的特点就是:不支持元素的重复(自带去重功能),并且内容无序。
(2) 基本语法:和列表、元组、字符串等定义基本相同:
# 定义集合
my_set={"传智教育","黑马程序员","itheima","传智教育","黑马程序员","itheima","传智教育","黑马程序员","itheima"}
my_empty_set=set() #定义空集合
print(f"my_set的内容是:{my_set},类型是:{type(my_set)}") # 不能重复,内容无序
print(f"my_empty_set的内容是:{my_empty_set},类型是:{type(my_empty_set)}")
结果:
my_set的内容是:{'itheima', '传智教育', '黑马程序员'},类型是:<class 'set'>
my_empty_set的内容是:set(),类型是:<class 'set'>
(3) 因为集合是无序的,所以集合不支持:下标索引访问。但是集合和列表一样,是允许修改的。
集合的常用操作 —— 修改
# 取出2个集合的差集
set1={1,2,3}
set2={1,5,6}
set3=set1.difference(set2)
print(set3) #{2,3} 集合1有而集合2没有的
# 消除2个集合的差集
set1.difference_update(set2)
print(set1) # {2,3} 没有了1,删除了相同的
print(set2) # {1, 5, 6} 集合2不变
# 2个集合合并
set1={1,2,3}
set2={1,5,6}
set3=set1.union(set2)
print(set3) # {1, 2, 3, 5, 6} 去重,只保留一个1
(4) 集合的特点:
(1) 使用字典,实现用Key取出Value的操作。定义:同样使用{},不过存储的是一个个的:键值对。
(2) 基本语法:
(3) 字典数据的获取:字典同集合一样,不可以使用下标索引,但是字典可以通过Key值来取得对应的Value。
# 从字典中基于Key获取Value
my_dict1={"王力宏":99,"周杰伦":88,"林俊杰":77}
score1=my_dict1["周杰伦"]
print(f"周杰伦的分数是:{score1}")
结果:
周杰伦的分数是:88
(4) 字典的嵌套:字典的Key和Value可以是任意数据类型(Key不可以为字典)。这就表明,字典是可以嵌套的。
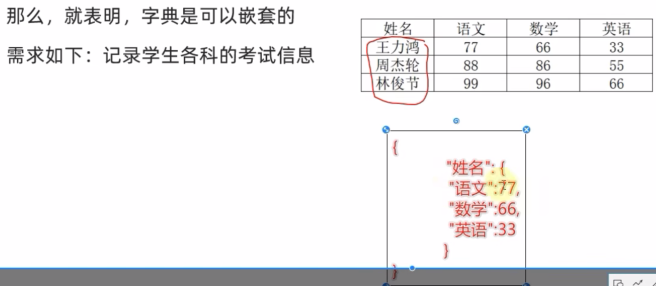
# 定义嵌套字典
stu_score_dict = {
"王力宏":{
"语文":77,
"数学":66,
"英语":33
},"周杰伦":{
"语文":88,
"数学":86,
"英语":55
},"林俊杰":{
"语文":99,
"数学":96,
"英语":66
}
}
print(f"学生的考试信息是:{stu_score_dict}")
# 从嵌套字典中获取数据
# 查看周杰伦的语文成绩
zhou_chinese=stu_score_dict["周杰伦"]["语文"]
print(f"周杰伦的语文成绩是:{zhou_chinese}")
# 查看林俊杰的英语成绩
lin_english=stu_score_dict["林俊杰"]["英语"]
print(f"林俊杰的英语成绩是:{lin_english}")
结果:
学生的考试信息是:{'王力宏': {'语文': 77, '数学': 66, '英语': 33}, '周杰伦': {'语文': 88, '数学': 86, '英语': 55}, '林俊杰': {'语文': 99, '数学': 96, '英语': 66}}
周杰伦的语文成绩是:88
林俊杰的英语成绩是:66
(5) 字典的特点:
(6) 字典的常用操作:
my_dict={"周杰伦":99,"林俊杰":88,"张学友":77}
# 新增元素
my_dict["张信哲"]=66
print(f"字典经过新增元素后,结果:{my_dict}")
# 更新元素
my_dict["周杰伦"]=33
print(f"字典经过更新元素后,结果:{my_dict}")
# 删除元素
zhou_score=my_dict.pop("周杰伦")
print(f"字典中被移除了一个元素,结果:{my_dict},周杰伦的考试分数:{zhou_score}")
# 清空元素
my_dict.clear()
print(f"字典被清空了,内容是:{my_dict}")
# 获取全部的key
my_dict={"周杰伦":99,"林俊杰":88,"张学友":77}
keys=my_dict.keys()
print(f"字典的全部keys是:{keys}")
# 遍历字典
# 方式1:通过获取全部的key来完成遍历
for key in keys:
print(f"字典的key是:{key} ",end="")
print(f"字典的value是:{my_dict[key]}")
# 方式2:直接对字典进行for循环
for key in my_dict: # 每一次循环取出的就是key
print(f"字典的key是:{key} ", end="")
print(f"字典的value是:{my_dict[key]}")
# 统计字典内的元素数量,len()函数
num=len(my_dict)
print(f"字典中的元素数量是:{num}")
结果:
字典经过新增元素后,结果:{'周杰伦': 99, '林俊杰': 88, '张学友': 77, '张信哲': 66}
字典经过更新元素后,结果:{'周杰伦': 33, '林俊杰': 88, '张学友': 77, '张信哲': 66}
字典中被移除了一个元素,结果:{'林俊杰': 88, '张学友': 77, '张信哲': 66},周杰伦的考试分数:33
字典被清空了,内容是:{}
字典的全部keys是:dict_keys(['周杰伦', '林俊杰', '张学友'])
字典的key是:周杰伦 字典的value是:99
字典的key是:林俊杰 字典的value是:88
字典的key是:张学友 字典的value是:77
字典的key是:周杰伦 字典的value是:99
字典的key是:林俊杰 字典的value是:88
字典的key是:张学友 字典的value是:77
字典中的元素数量是:3
(1) 序列是指:内容连续、有序,可以使用下标索引的一类数据容器。列表、元组、字符串,均可以视为序列。
(1) 切片:从一个序列中,取出一个子序列。
(2) 语法:序列[起始下标:结束下标:步长]。 —— 表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列。
# 对list切片,从1开始,4结束,步长1
my_list=[0,1,2,3,4,5,6]
result1=my_list[1:4:1] # 步长默认是1,所以可以省略不写
print(f"结果1:{result1}")
# 对tuple进行切片,从头开始,到最后结束,步长1
my_tuple=(0,1,2,3,4,5,6)
result2=my_tuple[:] #起始和结束不写,表示从头到尾,步长为1可以省略
print(f"结果2:{result2}")
# 对str进行切片,从头开始,到最后结束,步长为2
my_str="0123456"
result3=my_str[::2]
print(f"结果3:{result3}")
# 对str进行切片,从头开始,到最后结束,步长-1
my_str="0123456"
result4=my_str[::-1] # 等同于将序列反转了
print(f"结果4:{result4}")
# 对列表进行切片,从3开始,到1结束,步长-1
my_list=[0,1,2,3,4,5,6]
result5=my_list[3:1:-1]
print(f"结果5:{result5}")
# 对元组进行切片,从头开始,到尾结束,步长-2
my_tuple=(0,1,2,3,4,5,6)
result6=my_tuple[::-2]
print(f"结果6:{result6}")
结果:
结果1:[1, 2, 3]
结果2:(0, 1, 2, 3, 4, 5, 6)
结果3:0246
结果4:6543210
结果5:[3, 2]
结果6:(6, 4, 2, 0)
(1) 遍历
(2) 统计功能
(3) 通用转换功能
(4) 通用排序功能
# 进行容器排序
my_list=[3,1,2,5,4]
my_tuple=(3,1,2,5,4)
my_str="bdcefga"
my_set={3,1,2,5,4}
my_dict={"key3":1,"key1":2,"key2":3,"key5":4,"key4":5}
print(f"列表对象的排序结果:{sorted(my_list,reverse=True)}")
print(f"元组对象的排序结果:{sorted(my_tuple)}")
print(f"字符串对象的排序结果:{sorted(my_str)}")
print(f"集合对象的排序结果:{sorted(my_set)}")
print(f"字典对象的排序结果:{sorted(my_dict)}")
结果:
列表对象的排序结果:[5, 4, 3, 2, 1]
元组对象的排序结果:[1, 2, 3, 4, 5]
字符串对象的排序结果:['a', 'b', 'c', 'd', 'e', 'f', 'g']
集合对象的排序结果:[1, 2, 3, 4, 5]
字典对象的排序结果:['key1', 'key2', 'key3', 'key4', 'key5']


