


1,388
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享这篇文章最初发表在 NVIDIA 技术博客上。有关此类的更多内容,请参阅最新的 数据中心/云端 新闻和教程。
NVIDIA 与富士通和 Wind River 合作,使 NTT DOCOMO 能够在其日本网络中推出首个 GPU 加速商业开放式 RAN 5G 服务。这使其成为世界上第一家部署 GPU 加速商用 5G 网络的电信公司。
这个公告是一个重要的里程碑,因为电信行业正在努力解决数十亿美元的问题,即推动性能、总拥有成本(TCO)和能源效率的提高。该解决方案释放了 Open RAN 的灵活性、可扩展性和供应链多样性承诺。
DOCOMO 及其合作伙伴已确认,该解决方案基于富士通的虚拟化集中式单元(vCU)和虚拟化分布式单元(vDU),以及 NVIDIA Aerial 平台和 Wind River 的分布式云平台。
5G 开放式 RAN 解决方案是首个使用 NVIDIA Aerial 平台进行电信商业部署的 5G vRAN。该平台汇集了用于 5G、AI 框架、加速计算基础设施以及长期软件支持和维护的 NVIDIA Aerial vRAN 堆栈。它为电信运营商提供了创新和转型的新功能。
我们与供应商 Fujitsu 和 Wind River 合作,使用 NVIDIA Aerial 平台为 DOCOMO 的 5G 网络提供高性能、高蜂窝密度和灵活性,从而更好地利用其网络,降低 TCO,降低功耗。
DOCOMO 指出,与基于专有解决方案的标准网络相比,此新解决方案可将 TCO 降低 30%,将网络设计利用率提高 50%,并将基站功耗降低 50%。
截至 2023 年 7 月,DOCOMO 为来自 2 万多个基站的 2200 多万 5G 用户提供服务,5G 覆盖 815 多个城市。它使用了来自四家供应商的 29 种类型的无线电单元(RU)和来自三家供应商的 8 种类型的 CU。vRAN 的引入有望扩大 5G 网络的容量和覆盖范围。
虽然混合和匹配不同供应商产品的能力有望提高开放式 RAN 网络的灵活性和可扩展性,但它给运营商带来了两个主要问题:
DOCOMO 已启动 OREX 作为一个开放式 RAN 服务品牌,以应对开放 RAN 面临的挑战。该项目于 2021 年 2 月启动,富士通、NVIDIA 和 Wind River 在 OREX 下合作开发了基于富士通 vDU 和 vCU 的 5G vRAN 解决方案。
该解决方案使用以下组件:
这是第一个提供符合 NTT DOCOMO 性能和互操作性要求的商业直播 5G vRAN 的供应商联盟。
NVIDIA Aerial 平台包括用于物理(PHY)层 1(L1)的 NVIDIA Aviation vRAN 堆栈软件,以及 NVIDIA Converged Accelerator 及其组合数据处理器( DPU )和 GPU ,用于计算密集的 L1 工作负载的硬件加速。这使其成为世界上第一个商用部署的 DPU 和 GPU 加速(即 NVIDIA 加速)5G 开放式 RAN,以提供可扩展、灵活和经济高效的网络。
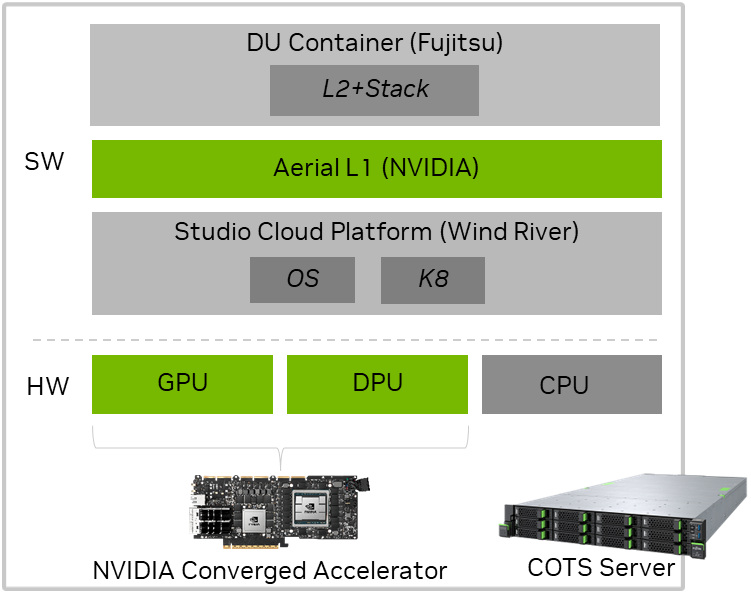 图 1。NTT DOCOMO 部署的 NVIDIA 加速 5G vRAN 堆栈
图 1。NTT DOCOMO 部署的 NVIDIA 加速 5G vRAN 堆栈
NVIDIA 正在通过无线框架、人工智能框架和加速计算基础设施的组合推动电信行业的创新。这使得能够利用云经济开发高性能、完全软件定义和人工智能原生网络(图 2)。
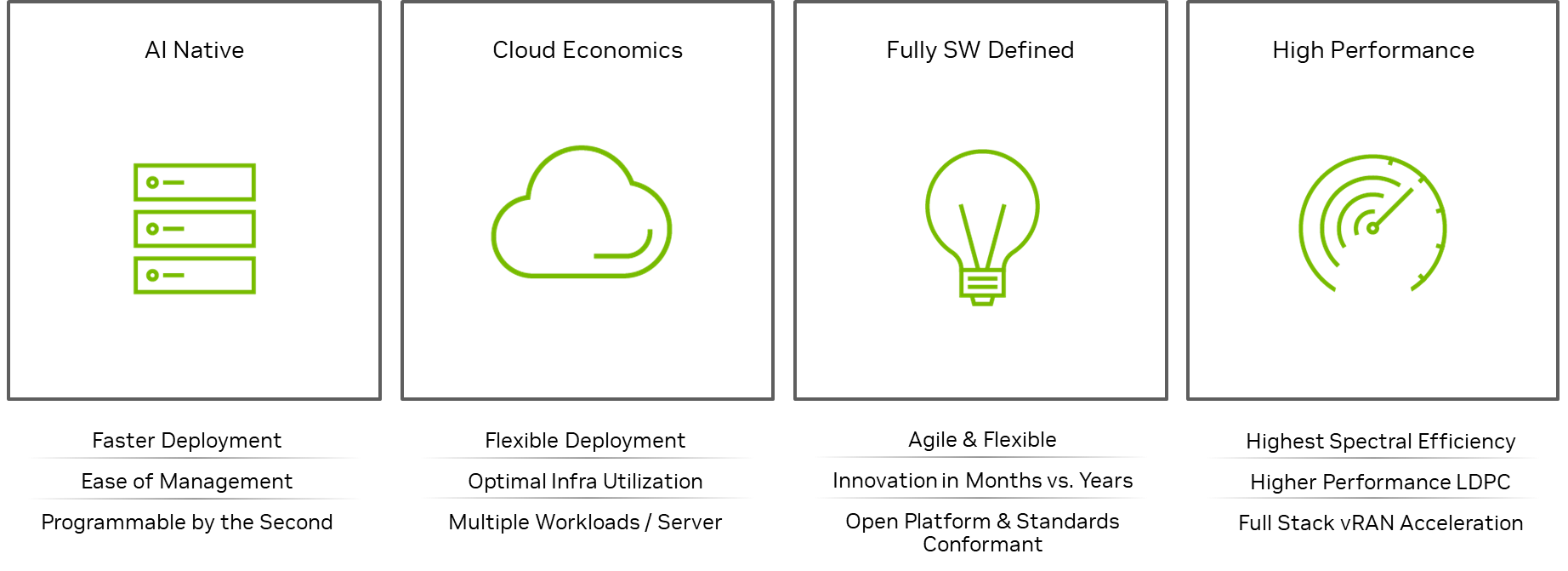 图 2: NVIDIA 全栈 5G vRAN 带来 RAN 创新优势
图 2: NVIDIA 全栈 5G vRAN 带来 RAN 创新优势
加速计算基础设施由 CPU 、 DPU 和 GPU 的组合以及一系列 NVIDIA 认证的 COTS 硬件服务器组成。
NVIDIA Aerial 是一个拥有软件、硬件和支持的平台,可在无线细分市场提供创新。它汇集了用于 5G、AI 框架、其他无线框架、加速计算基础设施和长期软件支持的 NVIDIA Aerial vRAN 堆栈。
得益于这种行业成形的硬件、软件以及商业级软件堆栈的长期支持和维护的结合,这为 5G 网络带来了新的性能阈值。
该平台的关键组件如下:
这是一个用于构建高性能、100%软件定义、云原生 5G vRAN 的应用程序框架,采用 O-RAN 7.2-x 拆分。 NVIDIA Aerial vRAN 堆栈具有高度灵活性和可扩展性,可为 L1 提供高性能。
NVIDIA Aerial 采用了以 GPU 为中心的方法,并依赖于两个显著的子组件:
cuBB 提供 GPU 加速的 5G L1 处理。它通过将所有 PHY 层处理保持在高性能 GPU 内存内,提供了高吞吐量和高效率。cuBB SDK 还包括针对 NVIDIA GPU 进行优化的 5G L1 高 PHY 加速库 cuPHY。cuPHY 通过使用 GPU 的巨大计算能力和高度并行性,提供了无与伦比的可扩展性。
NVIDIA DOCA GPU NetIO 通过在 GPU 存储器和 DPU 使用直接存储器存取(DMA)技术,提高了内联硬件加速的性能。
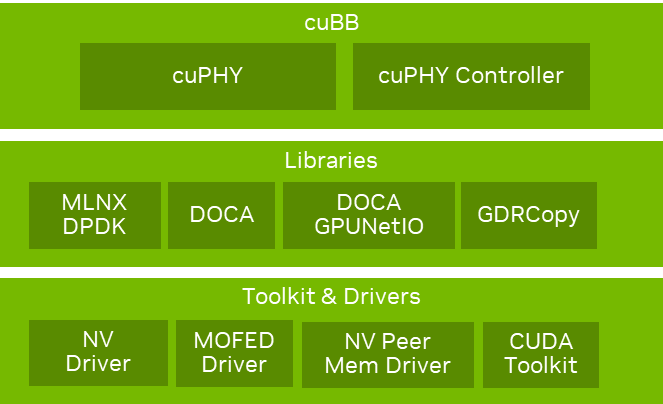 图 3。 NVIDIA Aerial vRAN 堆栈,用于完整的 L1 PHY 加速
图 3。 NVIDIA Aerial vRAN 堆栈,用于完整的 L1 PHY 加速
这是 vRAN 的处理引擎,由 CPU 、 DPU 和 GPU 以及 COTS 硬件服务器组成。
NVIDIA Aerial vRAN 堆栈的性能,尤其是计算密集型 L1,取决于其部署的硬件选择。 NVIDIA 为 5G 网络部署提供了两种硬件选项。它们的比较性能如下表 1 所示。
x86 和 NVIDIA 聚合加速器
此选项将 NVIDIA DPU 和 GPU 的性能与 x86 CPU 服务器相结合,为 5G vRAN 提供最大性能。
GPU 和 DPU 的集成将所有前端增强型公共无线电接口(eCPRI)数据业务引入 GPU 中,而数据路径中没有 CPU 。这是一个完整的内联 L1 卸载,因此该解决方案通过避免在主机 PCIe 接口上的替代系统中 CPU 和硬件加速器之间来回传输 eCPRI 数据来实现高性能。
数据进入 GPU 后,得益于 GPU’架构的大规模并行性,优化了基站系统的处理能力。这带来了改进的 RU 容量和处理能力,提供了高质量的通信环境,并且可以处理高负载数据处理以及天线技术的未来改进。
NVIDIA Grace Hopper 和 NVIDIA BlueField DPU
NVIDIA Grace Hopper 超级芯片融合了基于 Arm 架构的 NVIDIA 格雷斯 CPU 和高性能 NVIDIA Hopper GPU 。 BlueField DPU 有助于以与 NVIDIA Converged Accelerator 类似的方式从完全内联 L1 卸载中获得相同的性能。
然而,性能的最大提升来自于使用 NVIDIA NVLink-C2C 为 5G vRAN 等工作负载提供 CPU + GPU 相干内存模型的加速。
NVIDIA NVLink-C2C 是 NVIDIA 存储器相干、高带宽和低延迟互连。它提供高达 900 GB/s 的总带宽:比加速系统中常用的 x16 PCIe Gen5 通道高 7 倍的带宽。
有了 NVLink-C2C 内存一致性, CPU 和 GPU 线程都可以同时透明地访问 CPU 和 GPU 驻留内存,使 RAN 能够优化其如何处理 CPU GPU 上的 eCPRI 数据。
| X86+ NVIDIA 聚合加速器 (参考 AX800) | 格蕾丝 Hopper + BlueField 3 (参考 GH200) | |
| 多达 10 个 4T4T 峰值单元=相当于每个 2U 服务器 36 Gbps | 配置* | 多达 20 个 4T4T 峰值单元=相当于每个 2U 服务器 72 Gbps |
| 3.2 倍 (36 Gbps) | 5G 性能* | 6.4 倍 (72 Gbps) |
| 50 倍 (0.59 推断/秒) | LLM* (美洲驼 65B) | 284 倍 (1.71 推断/秒) |
| 1.3 倍 (34 W/Gbps) | 5G 能效* | 2.5 倍 (19 W/Gbps) |
| 1X (PCIE) | CPU – GPU 带宽* | 9 倍 (C2C) |
*相对于 100 MHZ、4T4R、4DL/2UL 的 X86 5G SKU,估计了相对性能。PCIE Gen5,2U 服务器
表 1: NVIDIA 聚合加速器与 NVIDIA Grace Hopper 在 5G vRAN 中的性能比较
NVIDIA Aerial 平台为电信运营商提供全栈、载波级、硬化和成熟的 5G 解决方案,并提供 10 年的长期支持和维护。这种级别的运营商级支持为电信公司使用该平台进行现场或商业部署提供了可靠性和弹性保证。
NTT DOCOMO 使用 NVIDIA 5G 平台进行的 5G 开放式 RAN 网络的商业部署是电信行业的一个重要里程碑。它展示了基于 GPU 的加速功能,用于计算密集型 L1 PHY 处理。
这种新网络具有改进的性能、灵活性和可扩展性,加上更高的蜂窝密度,显著提高了能源效率,并降低了 TCO。该网络的交付为蜂窝 RAN 中广泛采用基于 GPU 的加速铺平了道路。
DOCOMO 及其在 OREX 的合作伙伴正在共同努力,向全球运营商社区推广符合开放式 RAN 的多供应商 5G vRAN。在日本的商业部署符合 OREX 的愿景,使其成员能够在商业上验证其解决方案,然后将其推广到全球其他运营商。
NVIDIA 继续与 DOCOMO 和其他合作伙伴合作,支持世界各地的运营商部署高性能、节能、软件定义的商用 5G vRAN。



