


1,404
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享这篇文章最初发表在 NVIDIA 技术博客上。有关此类的更多内容,请参阅最新的 数据中心/云端 新闻和教程。
Spark RAPID ML 是一个开源 Python 包,它可以使 NVIDIA GPU 加速 PySpark MLlib。它提供了与 PySpark MLlib DataFrame API 兼容,并在使用支持的算法进行训练时加速。想要了解更多信息,请查看 新的 GPU 库降低 Apache Spark ML 的计算成本。
PySpark MLlib DataFrame API 的兼容性意味着它可以更容易地融入现有的 PySpark ML 应用程序,最多只需更改包导入。K-means 算法如下所示。更改包导入是使用此库启用 GPU 加速所需的唯一额外步骤。
PySpark MLlib
from pyspark.ml.clustering import KMeans kmeans_estm = KMeans()\ .setK(100)\ .setFeaturesCol("features")\ .setMaxIter(30) kmeans_model = kmeans_estm.fit(pyspark_data_frame) kmeans_model.write().save("saved-model") transformed = kmeans_model.transform(pyspark_data_frame)
Spark RAPID ML
from spark_rapids_ml.clustering import KMeans kmeans_estm = KMeans()\ .setK(100)\ .setFeaturesCol("features")\ .setMaxIter(30) kmeans_model = kmeans_estm.fit(pyspark_data_frame) kmeans_model.write().save("saved-model") transformed = kmeans_model.transform(pyspark_data_frame)
在 GPU 加速的 Databricks 的 AWS 托管 Spark 服务上,在三节点 Spark 集群中运行的基准测试套件中使用支持的算法进行培训,与基于 CPU 的 PySpark MLlib 相比,证明了显著的时间和成本优势。具体而言,这实现了7 倍到 100 倍的加速(取决于算法)和成本节约增加 3 倍至 50 倍。此外,Spark RAPID ML 库建立在经过验证、高度优化的 RAPID cuML GPU 加速 ML 库之上。
Spark RAPID ML 的初始版本支持 GPU 加速的 PySpark MLlib 算法的一个子集,RAPID cuML 中有现成的对应算法,包括线性回归,随机森林分类、随机森林回归、k-均值和主成分分析。此外,它还包括一个 PySpark DataFrame API,用于精确 k 最近邻居(k-NN)的 cuML 分布式实现,以便使用熟悉的 API 将此有用的算法轻松地结合到 Spark 应用程序中。
这个 Spark RAPID ML 23.08 版本发布 包括用于三种新算法的 GPU 加速 PySpark MLlib API:
逻辑回归是一种广为人知的机器学习(ML)分类算法,它将有限值类别变量的条件概率分布建模为特征向量的广义线性函数(例如 softmax 或 sigmoid 和线性函数)。
23.08 版本包括 PySpark MLlib 的 GPU 加速版本分类后勤回归和分类物流回归模型支持加速拟合和转换。这最初用于二元分类(二项式逻辑回归)和 L2 正则化,并计划为即将发布的版本提供全面支持(例如,弹性网络正则化和多类分类)。
与之前发布的算法相比,支持加速逻辑回归更为复杂。与以前版本中的算法不同,cuML 中没有现成的分布式实现可供利用。
因此,第一步是对基于 L-BFGS 的逻辑回归优化算法(也在 Spark MLlib 中使用)进行单 GPU 加速的 cuML 进行多节点多 GPU(MNMG)扩展。为此,该团队遵循了其他 cuML 分布式实现的设计模式,其设计类似于以 GPU 优化为中心的消息传递接口(MPI)NVIDIA 集体通讯库(NCCL)。
我们对 Spark RAPIDSML 的实现进行了使用 PySpark Barrier RDD 和 MLlib API 兼容性的自举分层(见图 1)。与之前发布的算法一样,这种设计使 GPU 加速的分布式实现能够以优化 GPU 利用率的方式并通过 GPU 之间的最佳可用互连来执行通信。其中包括以太网或更高性能的互连,如NVLink和 InfiniBand。
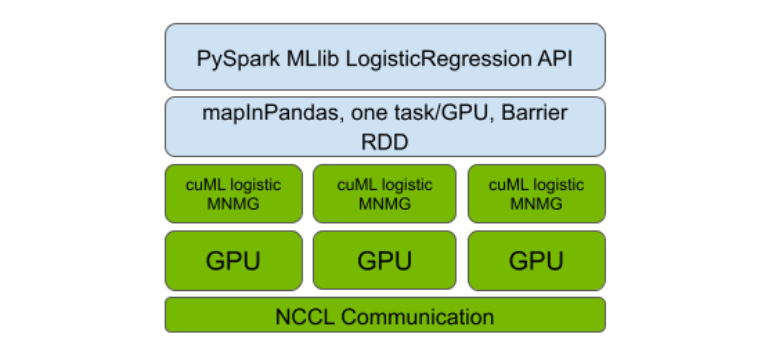 图 1。Spark RAPID ML 和新添加的 cuML MNMG 分布式逻辑回归实现的集成
图 1。Spark RAPID ML 和新添加的 cuML MNMG 分布式逻辑回归实现的集成
用于先前发布的算法的基准设置也用于比较 GPU 加速的 Spark RAPID ML 逻辑回归与基于 CPU 的 Spark ML 版本。PySpark RAPID MLlib 实现比 PySpark MLlib CPU 实现快 6 倍,成本效益高 3 倍。
这些基准测试在 Databricks 托管的 AWS Spark 服务上的三个节点 Spark 集群(一个驱动程序,两个执行器)中运行,硬件配置如下。
基准测试在一个 3000 功能的 12GB 合成数据集上运行,该数据集使用 scikit 学习合成数据生成例程生成,并以 Parquet 格式存储在 Amazon S3 上。请注意,运行时用于从 AmazonS3 加上 fit 方法执行的端到端数据加载,spark rapids 插件用于加速 GPU 运行的数据加载。
如果您想了解更多信息,包括与此基准测试相关的脚本,请访问 NVIDIA/spark-rapids-ml GitHub。另外,您可以参考示例 Jupyter 笔记本,它演示了如何使用加速的 LogisticRegression API。
交叉验证是一种众所周知的算法,用于优化模型或训练算法超参数,这些超参数不是由核心训练算法本身直接调整的,例如逻辑回归中的正则化参数。PySpark MLlib 长期以来一直通过调优来支持它。CrossValidator 类。
由于 Spark RAPID ML 的 MLlib API 兼容性,支持的加速算法估计器类可以开箱即用地进行 PySpark CrossValidator 超参数调整。与 CPU 训练的交叉验证相比,它提供了加速和成本效益,与 CPU 情况相比,这与单个训练运行的 GPU 不相上下。然而,对于超参数值的每次变化,它都会重复地将数据从 CPU 复制到 GPU,这是低效的。
这种过度复制是 GPU 计算中已知的性能瓶颈。对于 Spark RAPID ML 来说,这一点更为明显,因为这些副本也存在于 JVM 执行器和 Python 工作器之间的本地套接字连接上。
为了消除这种低效性,Spark RAPID ML 现在包括一个专门的PySpark 本地 CrossValidator 的版本,它与 MLlib API 兼容。它只向 Python 工作人员和 GPU 复制一次数据,而在给定的交叉验证倍数内,超参数值会发生变化。
Spark RAPID ML 专用 CrossValidator 在单独的训练和评估 Spark 阶段训练和评估所有模型的测试超参数值,每个阶段复制一次数据。图 2 显示了时间线跟踪,显示了 PySpark MLlib 和 Spark RAPID ML CrossValidator 版本的副本模式以及训练和评估计算步骤。
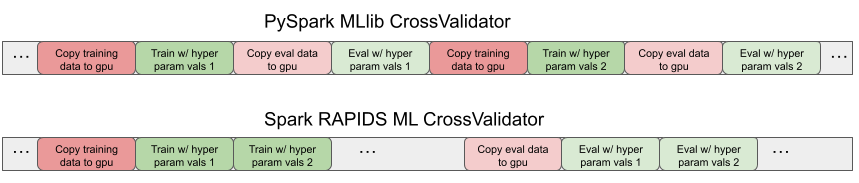 图 2:Spark RAPID ML CrossValidator 消除了冗余数据副本
图 2:Spark RAPID ML CrossValidator 消除了冗余数据副本
我们的团队对新的专业 CrossValidator 类进行了三倍交叉验证的基准测试,每个 GPU 加速了四个超参数值的 RandomForest 分类器,随机森林回归和线性回归。我们观察到在 GPU 加速实现上的 CrossValidator 的基线之上有 2 倍的加速 。
请注意,当考虑与纯 CPU 交叉验证的总体比较时,这种加速会乘以由于核心训练算法的 GPU 实现而导致的现有加速因子。
访问 GitHub 上的 NVIDIA/spark-rapids-ml 获取示例 Jupyter 笔记本,该笔记本展示了兼容 Spark MLlib API 的加速交叉验证程序。
UMAP 是一种最先进的非线性降维算法,它在将结构从高维数据捕获到计算的低维表示或嵌入中是非常有效的。它可以用于简化下游 ML 任务,如分类和聚类,或用于可视化。
该算法涉及计算密集型步骤,以在原始高维空间中获得低维嵌入,如 k 近邻(k-NN),并对嵌入上的随机图进行迭代交叉熵优化。因此,它是 GPU 加速的自然候选者,并已在 cuML 库中实现,这比原始的 CPU 实现更优秀。
在最新的 Spark RAPID ML 版本中,UMAP 加入了精确的 k-NN,作为 cuML 中的非 MLlib 加速算法,该算法封装在 PySpark MLlib API 中,可轻松集成到 Spark 应用程序中。设计如图 3 所示。
UMAP 估计器的拟合方法实现是单节点的,并且对完整数据集的随机样本进行操作以创建包括该随机样本及其嵌入的 UMAP 模型。UMAP 模型的变换方法然后以可扩展的分布式方式将嵌入扩展到数据集的其余部分。
它针对原始随机样本和模型中捕获的嵌入使用 k-NN 和交叉熵优化。该实现克服了 Spark 中的序列化限制,实现了大模型大小(许多 GB)。
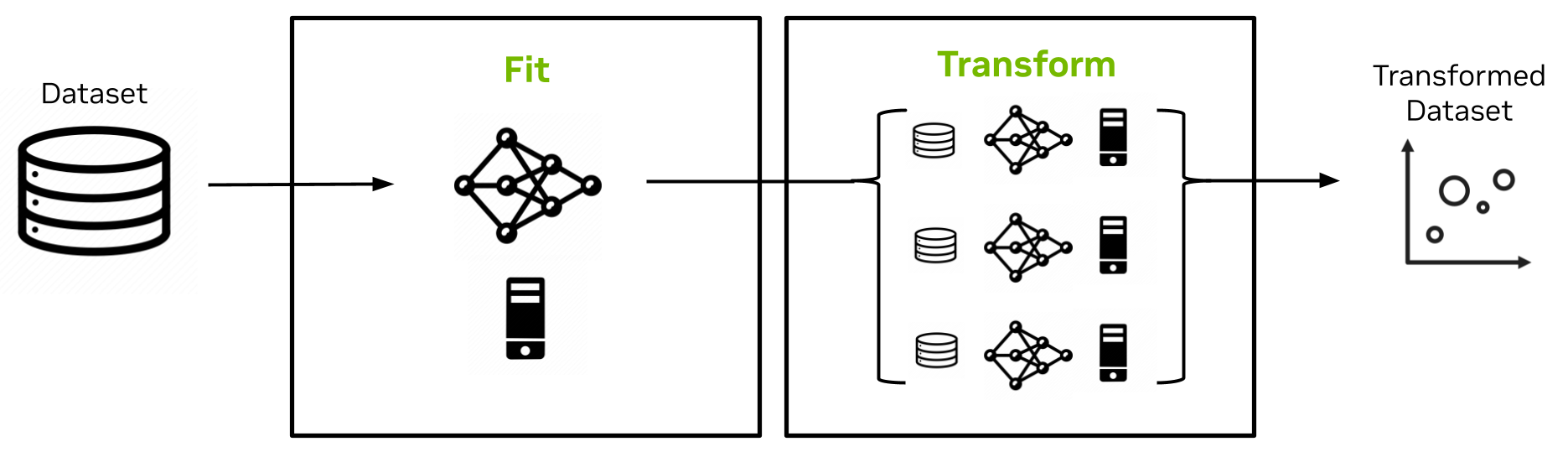 图 3。Spark RAPID ML UMAP 适配和转换实现
图 3。Spark RAPID ML UMAP 适配和转换实现
请访问 GitHub 上的 NVIDIA/spark-rapids-ml Jupyter 笔记本,查看在 Spark 上演示 GPU 加速的 UMAP 示例。如果想了解更多关于 API 的详细信息,请参阅 UMAP 文件。
有了 Spark RAPID ML 及其不断增长的功能,您可以通过一行代码的更改大大加快 Spark ML 应用程序的速度,同时降低计算成本。Spark RAPID ML 的最新版本将 GPU 加速的这些好处扩展到了逻辑回归和交叉验证。此外,GPU-accelerated UMAP 现在可与 PySpark MLlib API 一起使用,以便在 Spark ML 应用程序中更容易采用。
欢迎访问 NVIDIA/spark-rapids-ml 在 GitHub 上的 Spark RAPID ML 源代码 和 文档,并 提供反馈。您也可以查看 如何开始使用 Spark RAPID ML 的资源。



