


3,499
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享psn_no 是人员编码,adm_time开始时间,dscg_time是结束时间。
data_flag=1 代表第一次 ,data_flag= 2 是判断 间隔天数的标识:第一个结束 dscg_time 和下一个开始adm_time 在7天内就已经打上标识2 。
要实现的效果:
1-2-2-2 这样是一个循环,假如有4笔,那么前面3笔的金额查询出来是0 ,第四笔是四笔金额的总和。
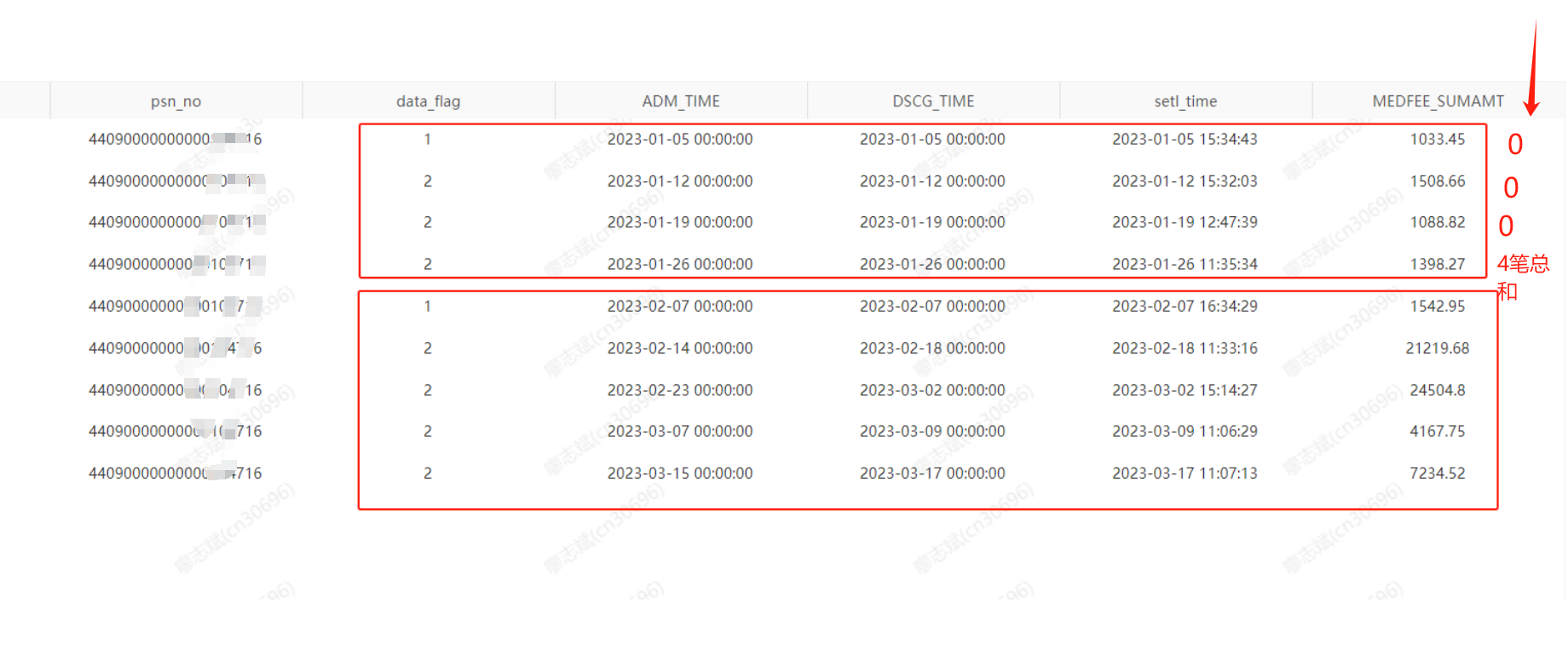
详细的数据如下所示:
| aaaa_ID | PSN_NO | DATA_FLAG | ADM_TIME | DSCG_TIME | SETL_TIME | MEDFEE_SUMAMT |
| 405980817 | 44090000000100036217 | 1 | 2023-01-05 00:00:00 | 2023-01-12 00:00:00 | 2023-01-12 09:47:35 | 12291.08 |
| 410737192 | 44090000000100036217 | 2 | 2023-01-17 00:00:00 | 2023-01-19 00:00:00 | 2023-01-19 10:30:25 | 1850.25 |
| 422482094 | 44090000000100036217 | 2 | 2023-01-23 00:00:00 | 2023-02-14 00:00:00 | 2023-02-14 12:54:10 | 52681.82 |
| 425364684 | 44090000000100036217 | 2 | 2023-02-17 00:00:00 | 2023-02-18 00:00:00 | 2023-02-19 15:14:21 | 2013.53 |
| 435666204 | 44090000000100036217 | 2 | 2023-02-24 00:00:00 | 2023-03-07 00:00:00 | 2023-03-07 15:30:22 | 22769.61 |
| 441676558 | 44090000000100036217 | 2 | 2023-03-10 00:00:00 | 2023-03-16 00:00:00 | 2023-03-16 10:05:09 | 7769.22 |
| 447502965 | 44090000000100036217 | 2 | 2023-03-18 00:00:00 | 2023-03-24 00:00:00 | 2023-03-24 13:18:29 | 9812.16 |
| 401433858 | 44090000000100104716 | 1 | 2023-01-05 00:00:00 | 2023-01-05 00:00:00 | 2023-01-05 15:34:43 | 1033.45 |
| 406356898 | 44090000000100104716 | 2 | 2023-01-12 00:00:00 | 2023-01-12 00:00:00 | 2023-01-12 15:32:03 | 1508.66 |
| 410873471 | 44090000000100104716 | 2 | 2023-01-19 00:00:00 | 2023-01-19 00:00:00 | 2023-01-19 12:47:39 | 1088.82 |
| 412334514 | 44090000000100104716 | 2 | 2023-01-26 00:00:00 | 2023-01-26 00:00:00 | 2023-01-26 11:35:34 | 1398.27 |
| 418143146 | 44090000000100104716 | 1 | 2023-02-07 00:00:00 | 2023-02-07 00:00:00 | 2023-02-07 16:34:29 | 1542.95 |
| 424794687 | 44090000000100104716 | 2 | 2023-02-14 00:00:00 | 2023-02-18 00:00:00 | 2023-02-18 11:33:16 | 21219.68 |
| 432317606 | 44090000000100104716 | 2 | 2023-02-23 00:00:00 | 2023-03-02 00:00:00 | 2023-03-02 15:14:27 | 24504.8 |
| 436897652 | 44090000000100104716 | 2 | 2023-03-07 00:00:00 | 2023-03-09 00:00:00 | 2023-03-09 11:06:29 | 4167.75 |
| 442594251 | 44090000000100104716 | 2 | 2023-03-15 00:00:00 | 2023-03-17 00:00:00 | 2023-03-17 11:07:13 | 7234.52 |
| 402770656 | 44090000000110139486 | 1 | 2023-01-06 00:00:00 | 2023-01-07 00:00:00 | 2023-01-07 12:19:54 | 14396.19 |
| 407062811 | 44090000000110139486 | 2 | 2023-01-13 00:00:00 | 2023-01-13 00:00:00 | 2023-01-13 13:24:15 | 1279.48 |
| 411249484 | 44090000000110139486 | 2 | 2023-01-19 00:00:00 | 2023-01-20 00:00:00 | 2023-01-20 10:10:50 | 12382.39 |
| 412594383 | 44090000000110139486 | 2 | 2023-01-27 00:00:00 | 2023-01-27 00:00:00 | 2023-01-27 12:01:17 | 1348.63 |
| 416389347 | 44090000000110139486 | 2 | 2023-02-03 00:00:00 | 2023-02-04 00:00:00 | 2023-02-04 10:32:47 | 15114.52 |
| 419880756 | 44090000000110139486 | 2 | 2023-02-10 00:00:00 | 2023-02-10 00:00:00 | 2023-02-10 13:35:10 | 1100.48 |
| 400305121 | 44090000003104703599 | 1 | 2022-12-28 00:00:00 | 2022-12-28 00:00:00 | 2023-01-04 10:15:38 | 5096.44 |
| 405254244 | 44090000003104703599 | 2 | 2023-01-04 00:00:00 | 2023-01-04 00:00:00 | 2023-01-11 09:51:50 | 1055.69 |
| 405706562 | 44090000003104703599 | 2 | 2023-01-11 00:00:00 | 2023-01-11 00:00:00 | 2023-01-11 16:39:01 | 1431.76 |
| 410271347 | 44090000003104703599 | 2 | 2023-01-18 00:00:00 | 2023-01-18 00:00:00 | 2023-01-18 14:15:03 | 1871.97 |
| 412134683 | 44090000003104703599 | 2 | 2023-01-25 00:00:00 | 2023-01-25 00:00:00 | 2023-01-25 12:26:37 | 1058.01 |
| 415410691 | 44090000003104703599 | 2 | 2023-02-01 00:00:00 | 2023-02-02 00:00:00 | 2023-02-02 11:55:34 | 6225.7 |
| 419027308 | 44090000003104703599 | 2 | 2023-02-08 00:00:00 | 2023-02-08 00:00:00 | 2023-02-09 09:48:31 | 1156.43 |
| 427731815 | 44090000003104703599 | 2 | 2023-02-15 00:00:00 | 2023-02-15 00:00:00 | 2023-02-23 10:57:08 | 5328.31 |
