社区
Oracle 高级技术
帖子详情
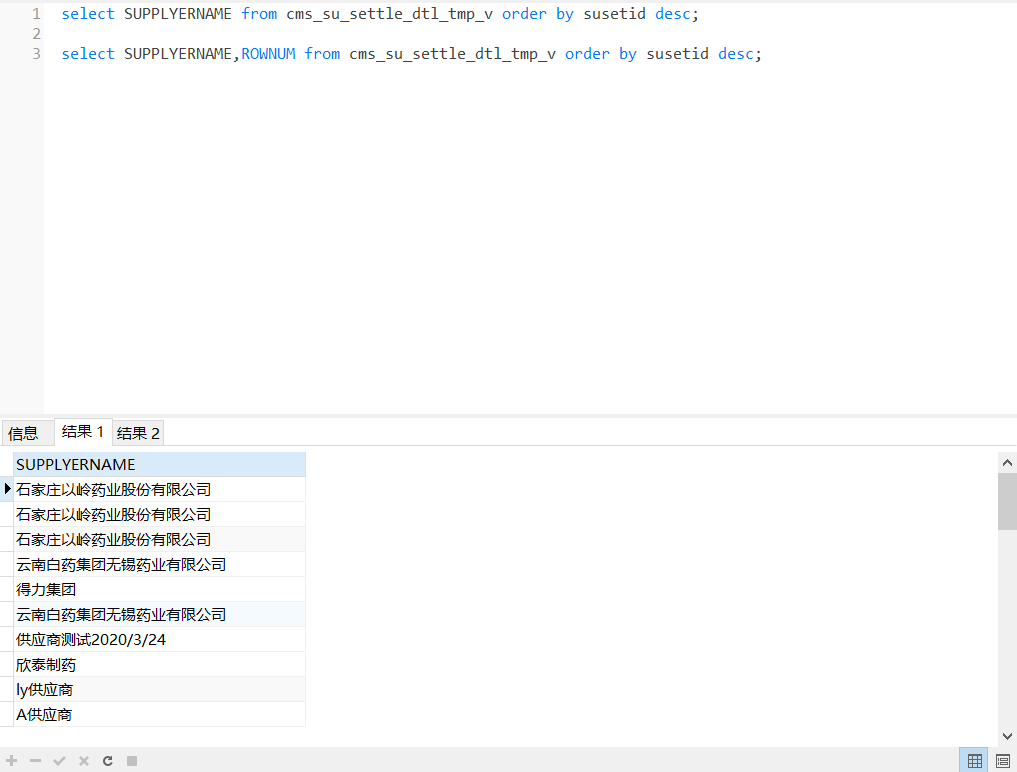
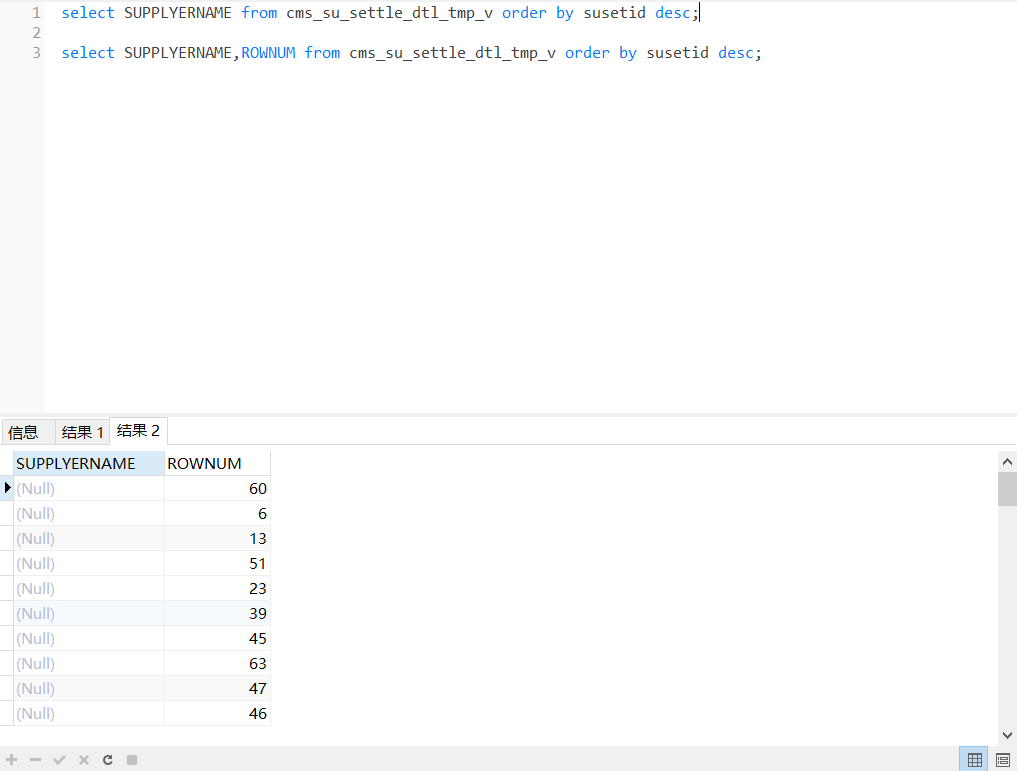
oracle查询,添加rownum后,列数据丢失
过往迷烟
2024-03-05 15:37:43
...全文
324
回复
打赏
收藏
oracle查询,添加rownum后,列数据丢失
[图片]
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
解决
oracle
使用
row
num
排序分页排序字段不唯一导致分页错误
2019独角兽企业重金招聘Python工程师标准>>> ...
从SQL注入到系统提权:
Oracle
与PostgreSQL
数据
库攻防实战详解
SQL注入作为Web安全领域最经典的漏洞之一,其本质在于攻击者通过构造恶意输入,篡改后端
数据
库
查询
逻辑,从而绕过应用程序的预期行为。其原理在于应用程序未对用户输入进行充分的过滤和校验,将输入
数据
与SQL指令进行了拼接,导致
数据
库引擎错误地执行了攻击者注入的代码。这项技术的危害远不止
数据
泄露,它往往是攻击链的起点,为后续的权限提升(提权)打开大门。在实战中,攻击者利用
数据
库的特定功能(如文件读写、命令执行)结合系统配置弱点,可以实现从
数据
库层到操作系统层的横向移动与权限突破。本文聚焦于
Oracle
和Postg
Oracle
- 常用窗口函数,SUM / AVG开窗实现累计统计
/ 使用 LocalDate,MyBatis-Plus 3.4.3+ 原生支持 private String productType;// 窗口计算字段(非
数据
库
列
,但需映射) private BigDecimal cumAmount;// 构造函数、getter/setter 省略... }// 使用 LocalDate,MyBatis-Plus 3.4.3+ 原生支持 private String productType;
MINUS与EXCEPT:
数据
库集合差运算原理与生产级应用指南
集合差运算是关系代数中用于识别
数据
差异的核心操作,对应SQL标准中的EXCEPT(
Oracle
称MINUS),其本质是基于元组哈希比对的去重差集计算,而非算术减法。该操作天然支持跨表、跨库的
数据
一致性校验,在ETL对账、用户流失分析、风控设备比对等场景中具备O(n+m)时间复杂度优势。理解其哈希构建-探测-去重三阶段执行机制、NULL语义陷阱、
列
类型兼容性约束及内存模型,是规避ORA-01790、性能劣化与误判风险的关键。本文结合
Oracle
、PostgreSQL、ClickHouse等多引擎实践,解析如何
SQL集合运算符实战避坑指南:UNION、INTERSECT、EXCEPT正确用法
SQL集合运算符是关系
数据
库中实现
数据
合并、交集与差集的基础能力,其底层基于关系代数中的集合操作原理,直接影响
数据
一致性与
查询
性能。理解UNION去重机制、INTERSECT对NULL的三值逻辑处理、以及EXCEPT与NOT EXISTS的执行效率差异,是保障千万级报表准确性的关键技术前提。在多源
数据
融合、AB测试归因、用户重合分析、权限模型验证等高频场景中,错误选用UNION而非UNION ALL可能导致性能下降3倍以上,而忽略NULL或类型兼容性则会引发线上
数据
事故。本文聚焦工程落地细节,覆盖跨
数据
库兼
Oracle 高级技术
3,499
社区成员
18,709
社区内容
发帖
与我相关
我的任务
Oracle 高级技术
Oracle 高级技术相关讨论专区
复制链接
扫一扫
分享
社区描述
Oracle 高级技术相关讨论专区
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享