




157
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享前面我们已经为大家介绍了如何从Oracle或MySQL迁移到openGauss的几个工具,那么,我们如何保证迁移后数据的正确性呢?接下来请让我为大家介绍今天的主角-DataChecker。
DataChecker介绍:
DataChecker是一个用Java语言编写的检验两个数据库间数据一致性的工具,其中部分架构和实现参考了阿里巴巴开源的数据迁移工具yugong。
代码仓:https://gitee.com/opengauss/openGauss-tools-datachecker
使用场景
一般情况下用于数据迁移完成之后的正确性校验。在将大量数据从一个数据库迁移至另一个数据库后,往往需要确定迁移过去的数据是否正确、完整。DataChecker就是用来检验两边数据库中的数据是否一致的工具。
实现原理
整个DataChecker的实现架构主要分为两部分:Extractor 和 Applier。

Extractor 即“提取器”,功能是提取源数据库中的数据(源数据库即为迁移前的数据库)。提取方式为顺序提取,按照数据在原表中的顺序分批提取出来。
Applier 即“实施器”,功能是根据Extractor提取出来的数据,在目标数据库(即迁移后的数据库)中找到对应的数据,进行字段逐一对比并返回结果。
使用方法
环境要求
操作系统
纯java开发,有bat和shell脚本,windows/linux均可支持。
jdk建议使用1.6.25以上的版本。
数据库
源库支持MySQL,后续将增加对Oracle的支持。
目标库仅支持openGauss数据库。
下载datachecker
可访问https://gitee.com/opengauss/openGauss-tools-datachecker 下载源码及编译完成的包。
自己编译:
git clone git@gitee.com:opengauss/openGauss-tools-datachecker.git
cd openGauss-tools-datachecker
mvn clean install -Dmaven.test.skip -Denv=release
若不想自己编译,clone下来的主目录有个target文件夹,里面有个DataChecker-1.0.0-SNAPSHOT.tar.gz,即为编译好的二进制包。
目录结构介绍
Target目录下的结构为:
/target
bin/
startup.bat
startup.sh
stop.sh
conf/
gauss.properties
logback.xml
lib/
logs/
bin目录下有两个文件,分别为windows和linux下的程序启动及停止文件startup.bat 和 startup.sh、stop.sh。
conf目录下也有两个文件,为配置文件,一般情况下只配置gauss.properties。
lib目录下存放的是运行所需的依赖文件。
Logs目录下存放的是运行之后的结果日志
修改配置
在/conf/ gauss.properties中修改配置。一般情况下,只需修改源库和目标库的地址信息、本次需要校验的表等基本信息,其他的可以使用默认值或灵活修改。
|
参数名字 |
参数说明 |
默认值 |
|
gauss.database.source.username |
源数据库的用户名 |
无 |
|
gauss.database.source.password |
源数据库的密码 |
无 |
|
gauss.database.source.type |
源数据库的类型 |
Mysql |
|
gauss.database.source.url |
源数据库的连接url,须遵循一定的格式 |
无 |
|
gauss.database.source.encode |
源数据库的编码格式 |
UTF-8 |
|
gauss.database.target.username |
目标数据库的用户名 |
无 |
|
gauss.database.target.password |
目标数据库的密码 |
无 |
|
gauss.database.target.type |
目标数据库的类型 |
OPGS(即openGauss) |
|
gauss.database.target.url |
目标数据库的连接url,须遵循一定的格式 |
无 |
|
gauss.database.target.encode |
目标数据库的编码 |
UTF-8 |
|
gauss.table.onceCrawNum |
extractor/applier每个批次最多处理记录数 |
1000 |
|
gauss.table.tpsLimit |
tps限制,0代表不限制 |
0 |
|
gauss.table.skipApplierException |
true代表当applier出现数据库异常时,比如约束键冲突,可对单条出异常的数据进行忽略 |
False |
|
gauss.table.white |
白名单。定义需要进行校验的表: 格式为schema.tablename组成,多个表可加逗号分隔。如想要校验一个schema下面的所有表,则填schema的名字即可 |
无 |
|
gauss.table.black |
黑名单,需要忽略的表。格式同gauss.table.white |
无 |
|
gauss.table.inc.tablepks |
需要进行校验的表的主键,方便加快校验速度。格式为:tablename1&pk1&pk2|tablename2&pk1 |
无 |
|
gauss.table.concurrent.enable |
多张表之前是否开启并行处理,如果false代表需要串行处理 |
true |
|
gauss.table.concurrent.size |
允许并行处理的表数 |
5 |
|
gauss.table.retry.times |
表校验出错后的重试次数 |
3 |
|
gauss.extractor.dump |
是否记录extractor提取到的所有数据 |
false |
|
gauss.extractor.concurrent.global |
extractor是启用全局线程池模式,如果true代表所有extractor任务都使用一组线程池,线程池大小由concurrent.size控制 |
false |
|
gauss.extractor.concurrent.size |
允许并行处理的线程数,需要先开启concurrent.enable该参数才会生效 |
30 |
|
gauss.applier.dump |
是否记录applier提取到的所有数据 |
false |
|
gauss.applier.concurrent.enable |
applier是否开启并行处理 |
true |
|
gauss.applier.concurrent.global |
applier是启用全局线程池模式,如果true代表所有applier任务都使用一组线程池,线程池大小由concurrent.size控制 |
false |
|
gauss.applier.concurrent.size |
允许并行处理的线程数,需要先开启concurrent.enable该参数才会生效 |
30 |
|
gauss.stat.print.interval |
统计信息打印频率. 频率为5,代表,完成5轮extract/applier后,打印一次统计信息 |
5 |
启动停止
Linux启动
sh startup.sh
Linux停止
sh stop.sh
windows启动
windows启动
windows停止
直接关闭终端即可。
日志说明
日志结构为:
/logs
summary/
summary.log
gauss/
table.log ${table}/
table.log
extractor.log
applier.log
check.log
gauss目录下的table.log为整个校验过程的总日志。
summary目录下的summary.log记录了所有校验结果为不正确的表名(即两边表的数据不一致)。
${table} 为各个表的表名,其下的table.log为该表的校验过程总日志,extractor.log为数据提取过程的总日志,applier.log为校验实施(数据对比)过程中的总日志。check.log记录了校验失败的具体某一行的数据。如没有出现check.log,则表示校验结果为正确。
使用实例
1. 数据库准备
在mysql数据库中名为“mysql”的schema下新建一个表如下:

假设数据迁移至openGauss之后,5条数据只成功迁移了4条,表现如下:

2. 配置 gauss.properties
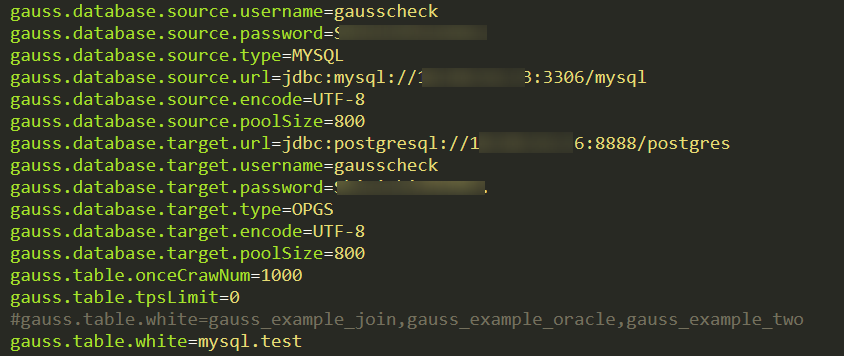
3. 运行startup.bat(startup.sh)

4. 查看日志
首先查看/logs/summary/summary.log,找到出错的表mysql.test

然后进入/logs/mysql.test/ 查看详情
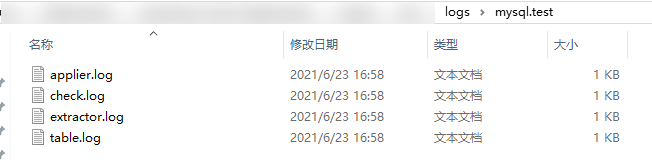
这里有四个日志文件,主要看check.log
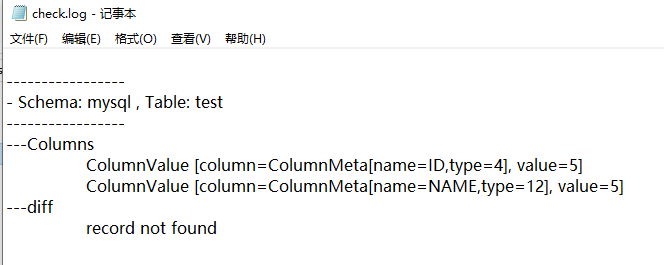
发现 id为5, name为5的这一条记录没有被成功迁移过去。

