570
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
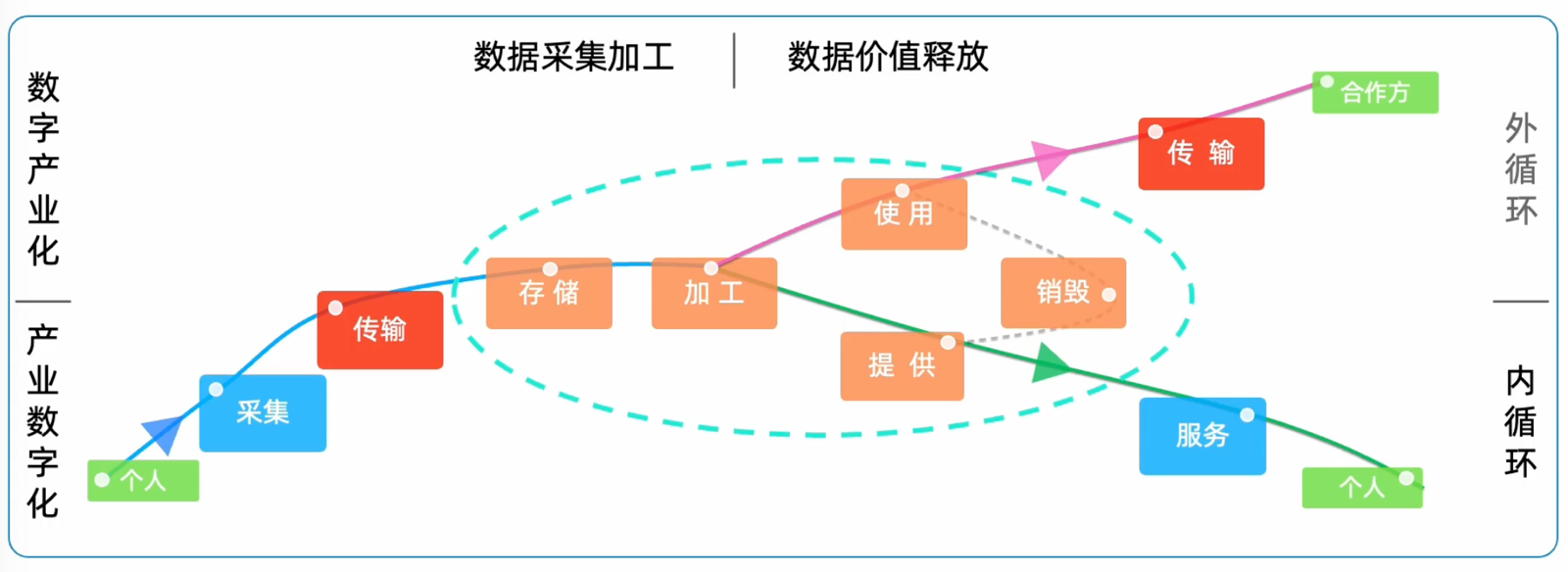
分享数据流转链路主要包括:采集、存储、加工、使用、提供、传输。
数据提供方收益:新增长点、资产入表、数据资本化。
内循环:数据持有方在自己的运维管控域内对自己的数据使用和安全拥有全责。
外循环:数据要素离开了持有方管控域,在使用方运维域,持有方依然拥有管控需求和责任。
数据使用方收益:业务提效、运营降本、扩大营收。

理想的良性循环如图所示:
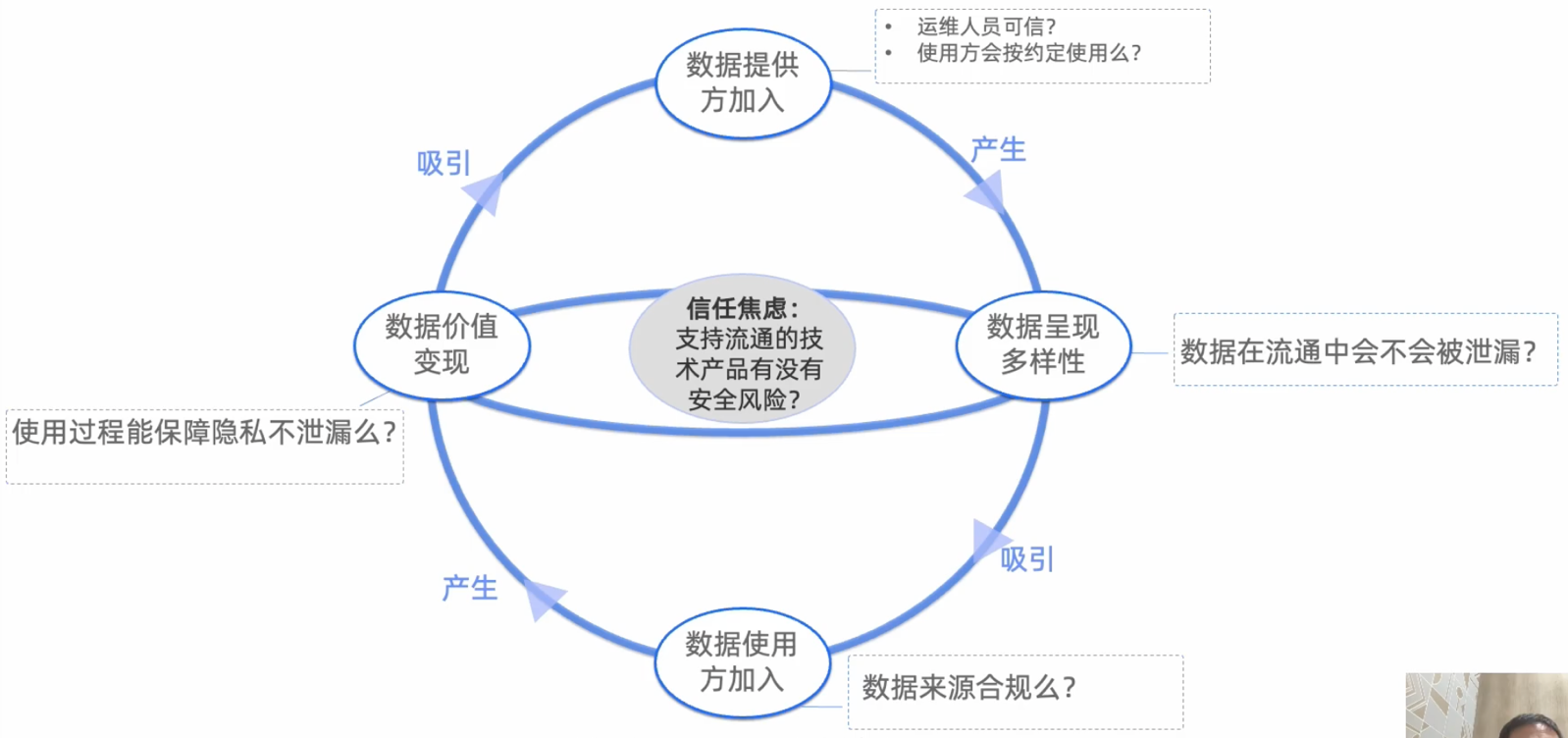
信任焦虑的关键问题之一:数据权属。
三权分置下,如何在数据流通过程中确保数据提供方的数据持有权和经营方的经营权,并防止数据被滥用,从而有效促进使用权流通?
三权分立的目的:期望将数据持有权和使用权分离。持有权被全面保护、使用权可以流通。
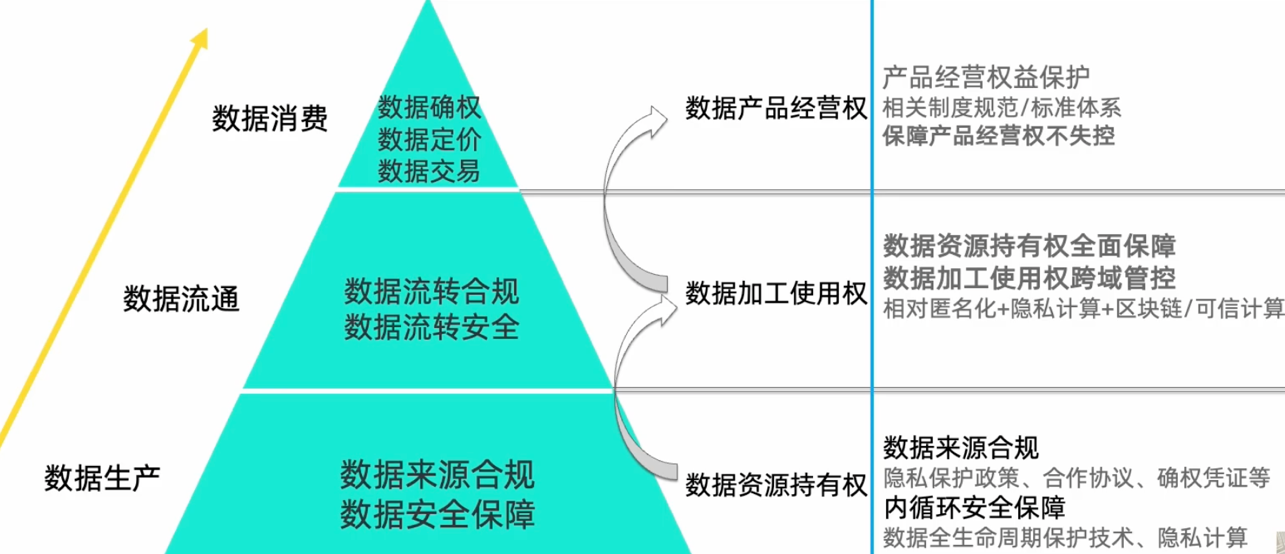
信任本质上是对不确定性和复杂性的依赖。
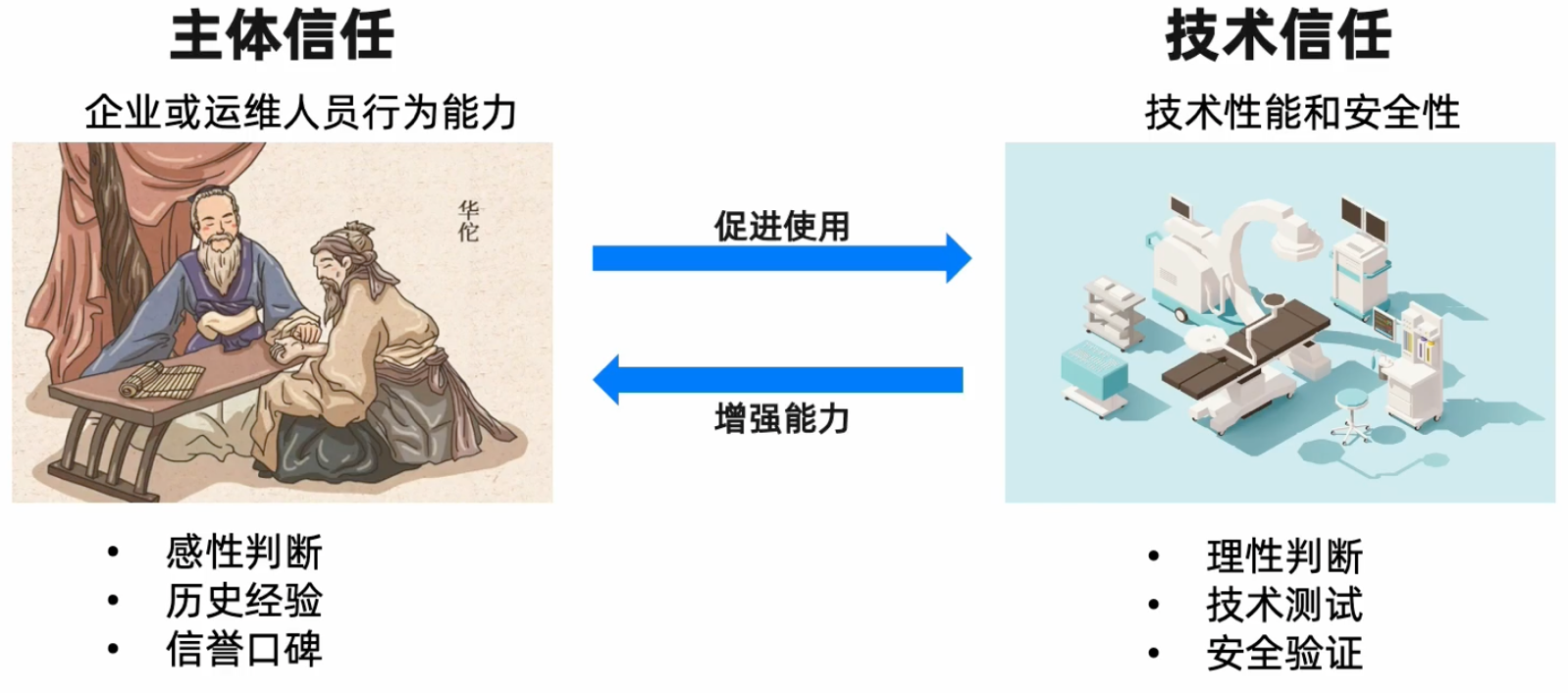
基于安全可信的技术信任体系是支撑全行业数据要素安全可控流转的基础。
如何构建安全可信的技术体系:包括匿名化技术、数据互联层面的隐私计算技术、控制层面的数据使用权的跨域管控。
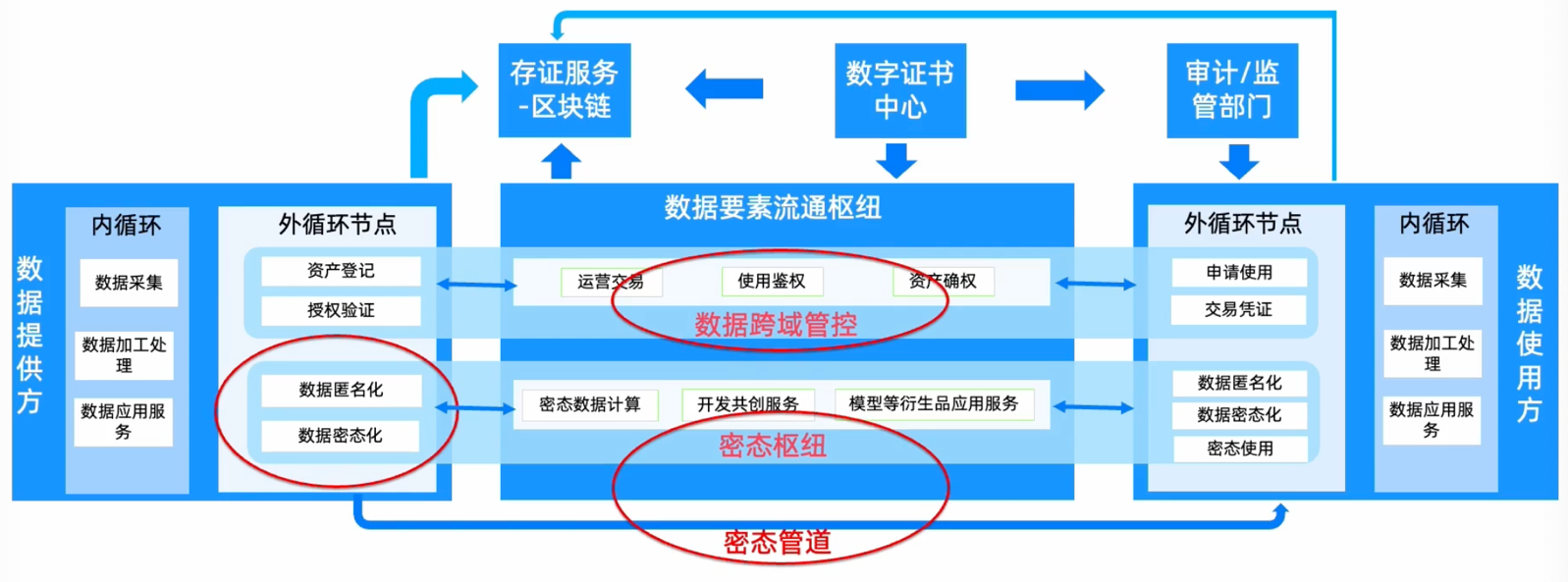
控制面:以区块链/可信计算 为核心支撑技术构建 数据使用权跨域管控层
数据面:以隐私计算 为核心支撑技术构建密态数联网,包括密态枢纽 与密态管道
技术信任的核心:完备的信任链

可信云PaaS:通过技术可信代替人员可信。
隐私计算技术主要是三分方面:
隐私计算产品需要通用的安全分级和测评方式
隐私计算需要通过开源降低门槛促进数据安全流通
隐语:其以安全、开放为核心设计理念,支持MPC、FL、 TEE 等主流隐私计算技术,融合产学研生态共创能力,助力隐私计算更广泛应用到Al、数据分析等场景中,解决隐私保护和数据孤岛等行业痛点。
隐语四大优势:
统一架构:隐语推出了行业首个明密文混合统一技术路线框架,同时支持联邦学习、多方安全计算、可信执行环境、可信密态等。
原生应用:隐语首创 Al/BI 密态编译器支撑了工业级的原生 SQL分析、原生 Al 训练/预测框架等复杂应用,保持用户熟悉的接口同时,引领行业密态计算走向更复杂、更具挑战的场景。
开放拓展:具备模块化设计、开放的接口、可扩展的数据存储等特点,硬件层/计算层/算法层等均支持开放拓展。灵活易集成,能够快速匹配业务变化及技术发展需求。
性能卓越:既能支持业务在早期 PoC 阶段的快速迭代,也具备PoC 验证成功后的大规模生产能力,可支持十亿级求交、千万级建模。其性能己经过金融/医疗/保险/政务等多个行业场景的实战淬炼。
开源前多轮安全验证: