




122
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享| 这个作业属于哪个课程 | 2302软件工程 |
|---|---|
| 这个作业要求在哪里 | 软件工程实践——软件评测作业 |
| 这个作业的目标 | 对选定的产品进行调研评测分析总结 |
| 其他参考文献 | 《构建之法》 |
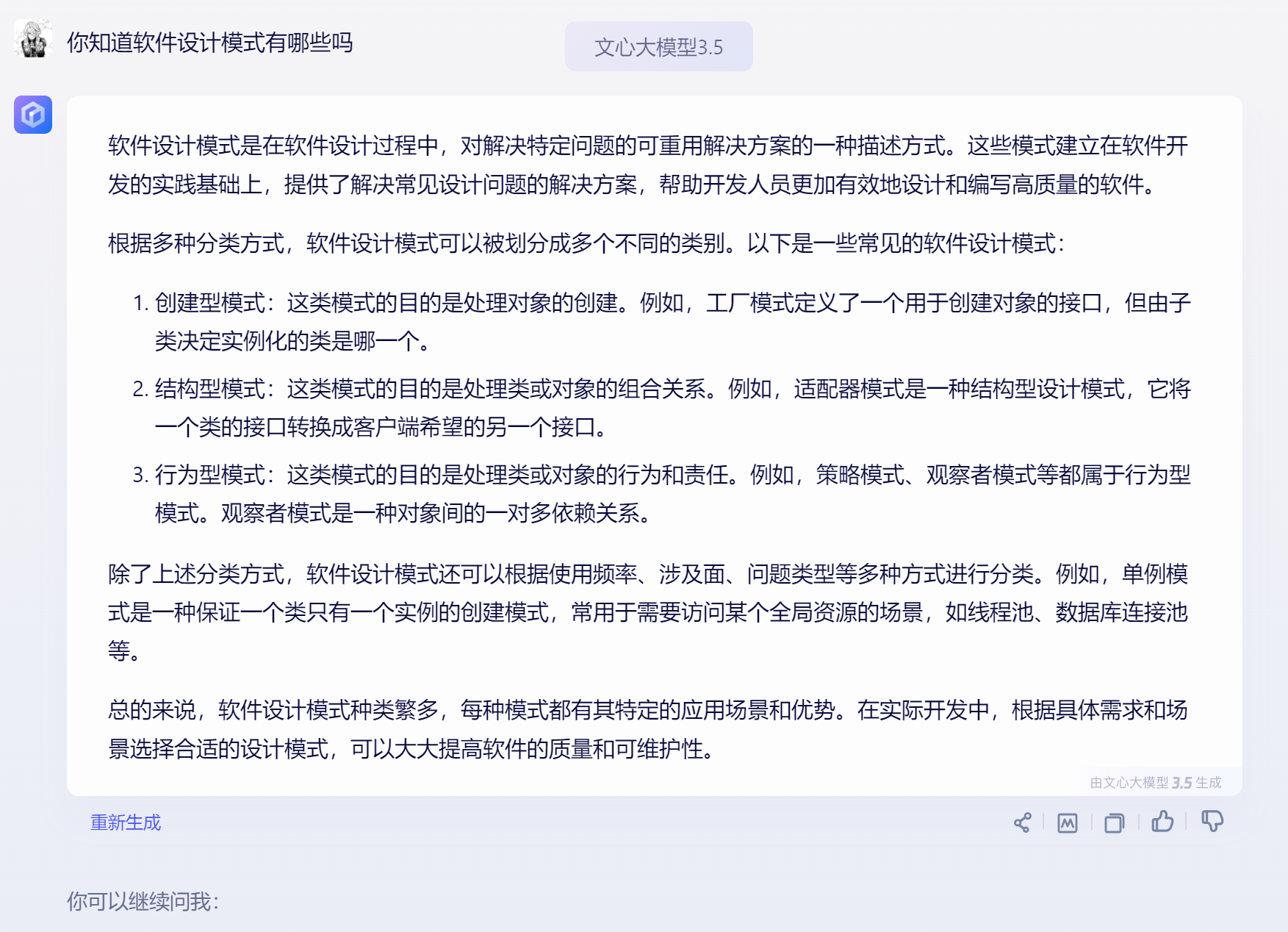
文心一言是百度推出的一款基于大语言模型的生成式AI产品。它可以根据用户的输入生成各种类型的文本,如诗歌、故事、对话等。文心一言目前包含以下五类落地场景:文学创作、商业文案创作、数理逻辑推送、中文理解、多模态生成。此产品具备跨模态、跨语言的深度语义理解与生成能力,其在搜索问答、内容创作生成、智能办公等众多领域都有更广阔的想象空间。
优点:
网页分区合理,引导性良好,使用方便,百度账号可直接登录。
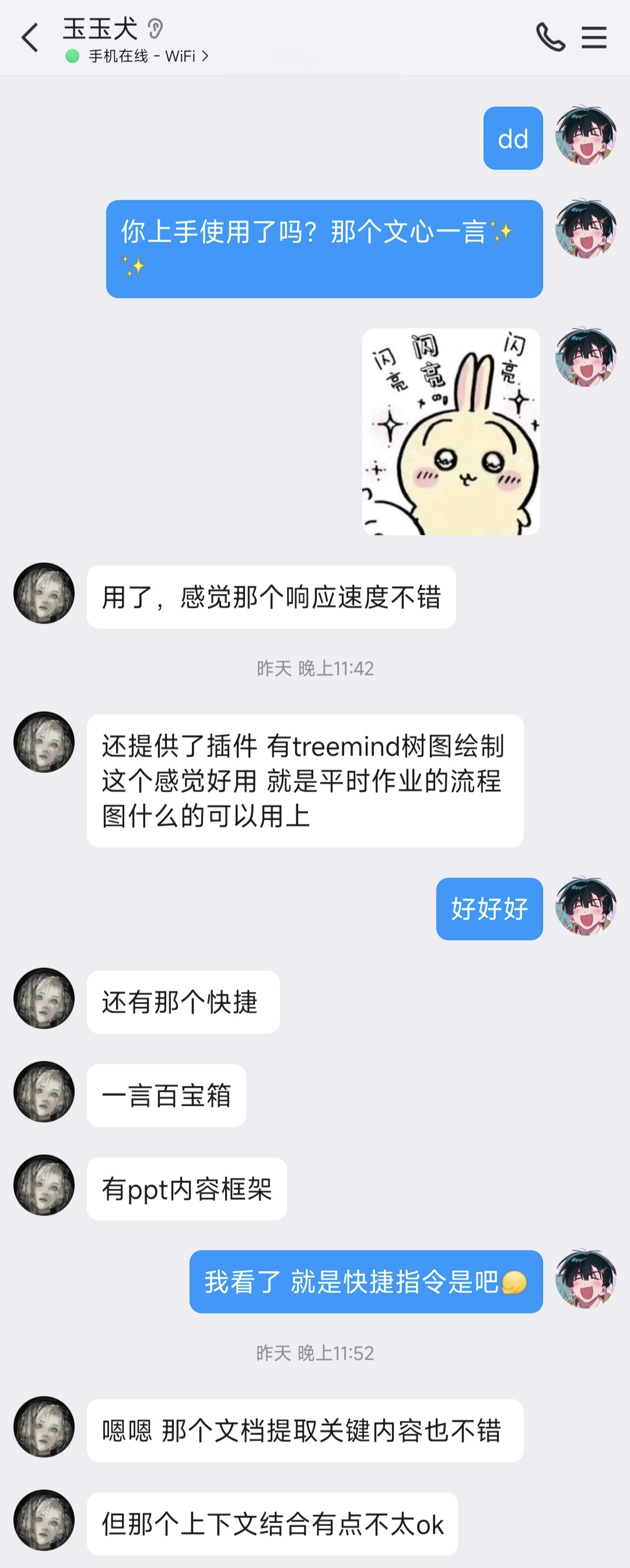
回答生成速度快,且大部分回答条理清晰,提供引申提问,还可以将回答复制成markdown。
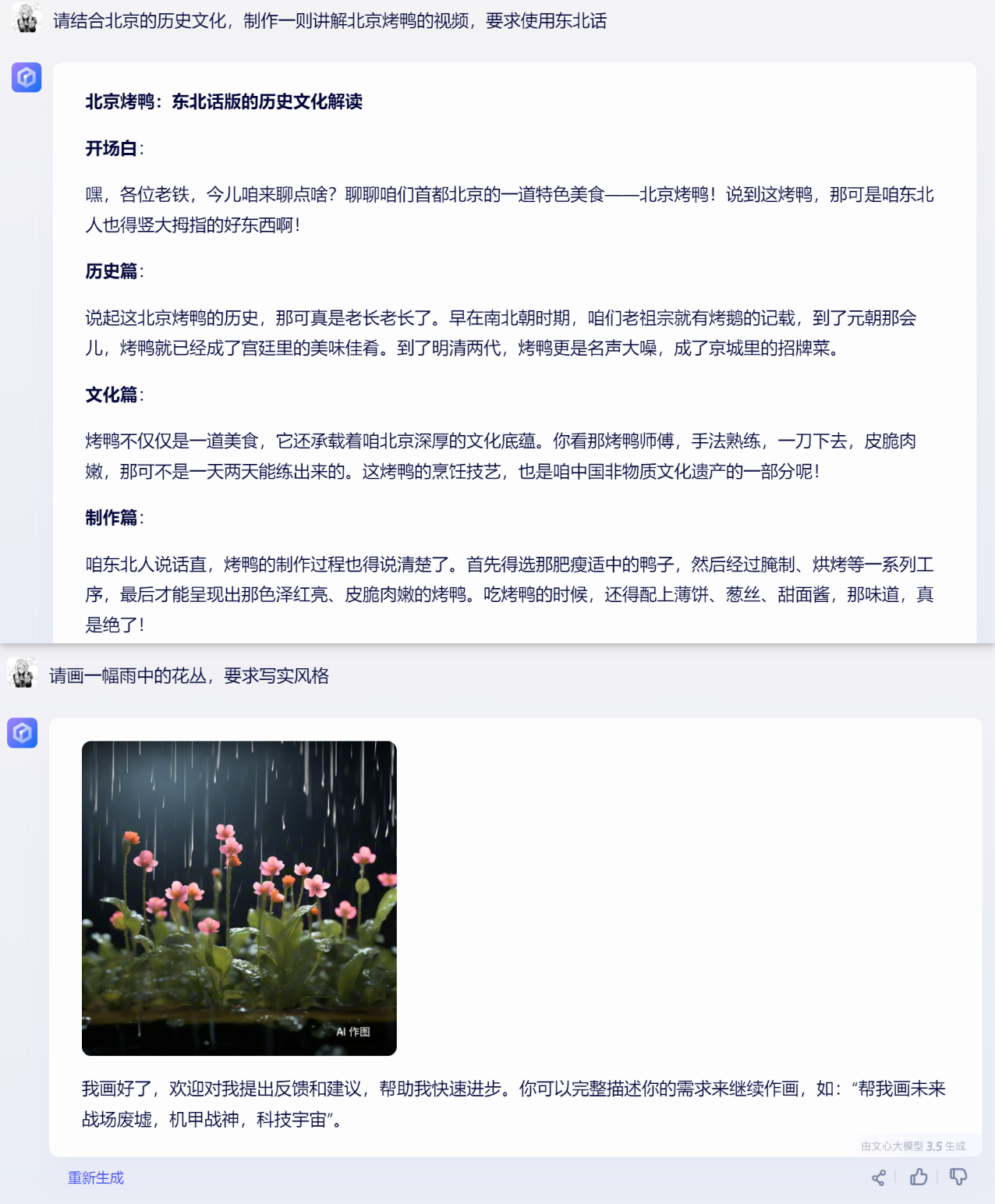
功能丰富,覆盖面广,例如对于地方语言等文化领域,可以很好地提供恰当地道的回答;对于画图要求,可以提供生动形象的图片等等。
缺点:
更准确更高层次的功能需要付费解锁会员。
画图功能对一些场景描述绘制错误,偏离主题,同时结合上下文能力不足。
对于一些冷门,相对小众的话题,不能提供用户满意的回答。
去除会员功能
加强数据模型训练
提高结合上下文能力
用户背景:计算机专业学生,有制作ppt,绘制流程图,文档阅读,总结关键信息,文档撰写,代码分析需求。
产品栏目:TreeMind,览卷文档,绘图等等
问题:上下文结合出现问题
亮点:在提取文档信息进行汇总和树图绘制方面做的不错,还提供了许多快捷指令
改进:考虑上下文以及解除会员
操作系统:win11
浏览器:Google Chrome
Bug发现时间:2024/4/14
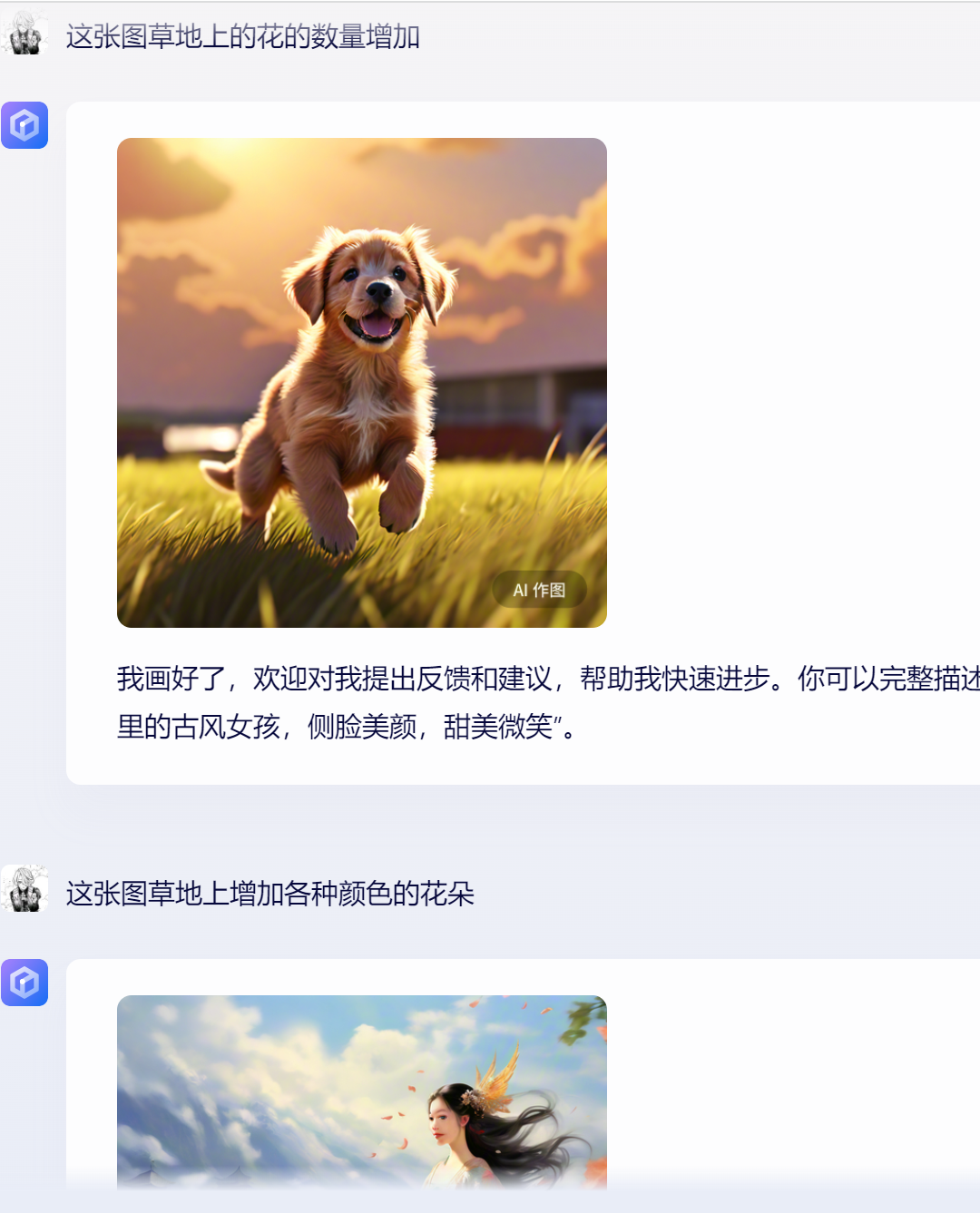
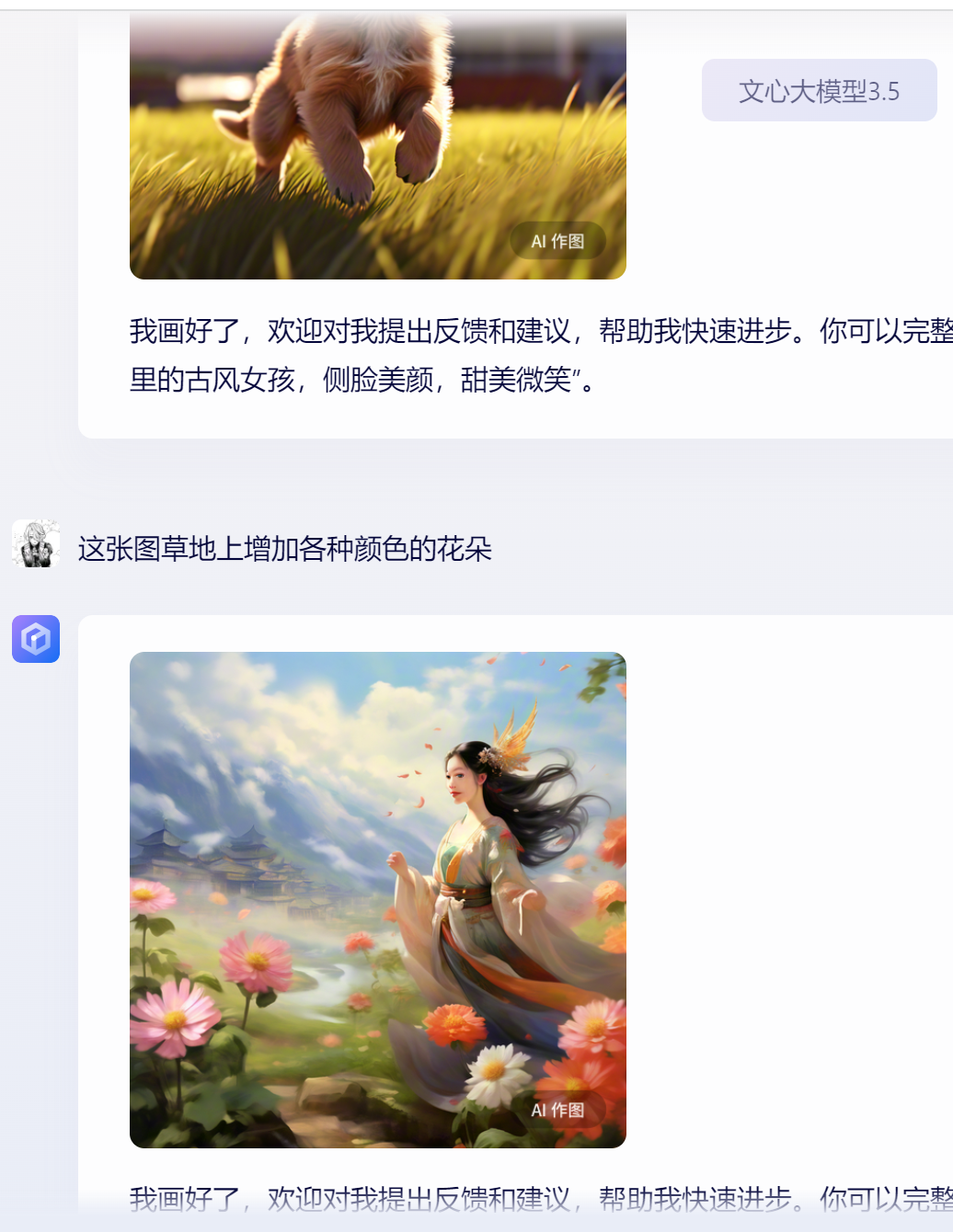
在生成图片后,进行用户需要的进一步图片修改指令,或者在生成多张图片后,经常性会出现图片场景被完全替换的事件,偏离用户需求。
在输入生成图片的指令后,进一步对图片的内容进行修改,出现不对用户的需求进行修改的bug(原先是狗狗在草地,当我需要增加花,图片没有实现,进一步描述有多种颜色的花,图片直接去除了狗狗)
bug产生的原因是文心一言上下文结合的能力不足,需要加强数据模型训练
d) 好,不错
描述 推荐指数 界面 网页分区合理,引导性良好,使用方便 ☆☆☆☆ 功能 功能丰富,覆盖面广,但信息量需要优化,较为小众的东西没有或者少量反馈回答 ☆☆☆ 体验 插件和快捷指令对用户来说易于上手,但比如画图存在一些bug ☆☆☆
Kimi 是由月之暗面(Moonshot AI)提供的 AI 智能助手。Kimi 擅长中英文对话,支持约 20 万汉字的上下文输入,可以帮助你解答问题、阅读文件、联网搜索并整合信息,提升工作效率。
优点:
界面设计非常简洁直观易用,有快捷语确保用户可以轻松地找到他们需要的功能和信息,还有联网模式方便进一步搜索。
上传文件(最多 50 个,每个 100 MB)接受 pdf、doc、xlsx、ppt、txt、图片等,可以很好地分析和概括文案,同时在传完文件后,自动地取消联网模式,保障文件安全。
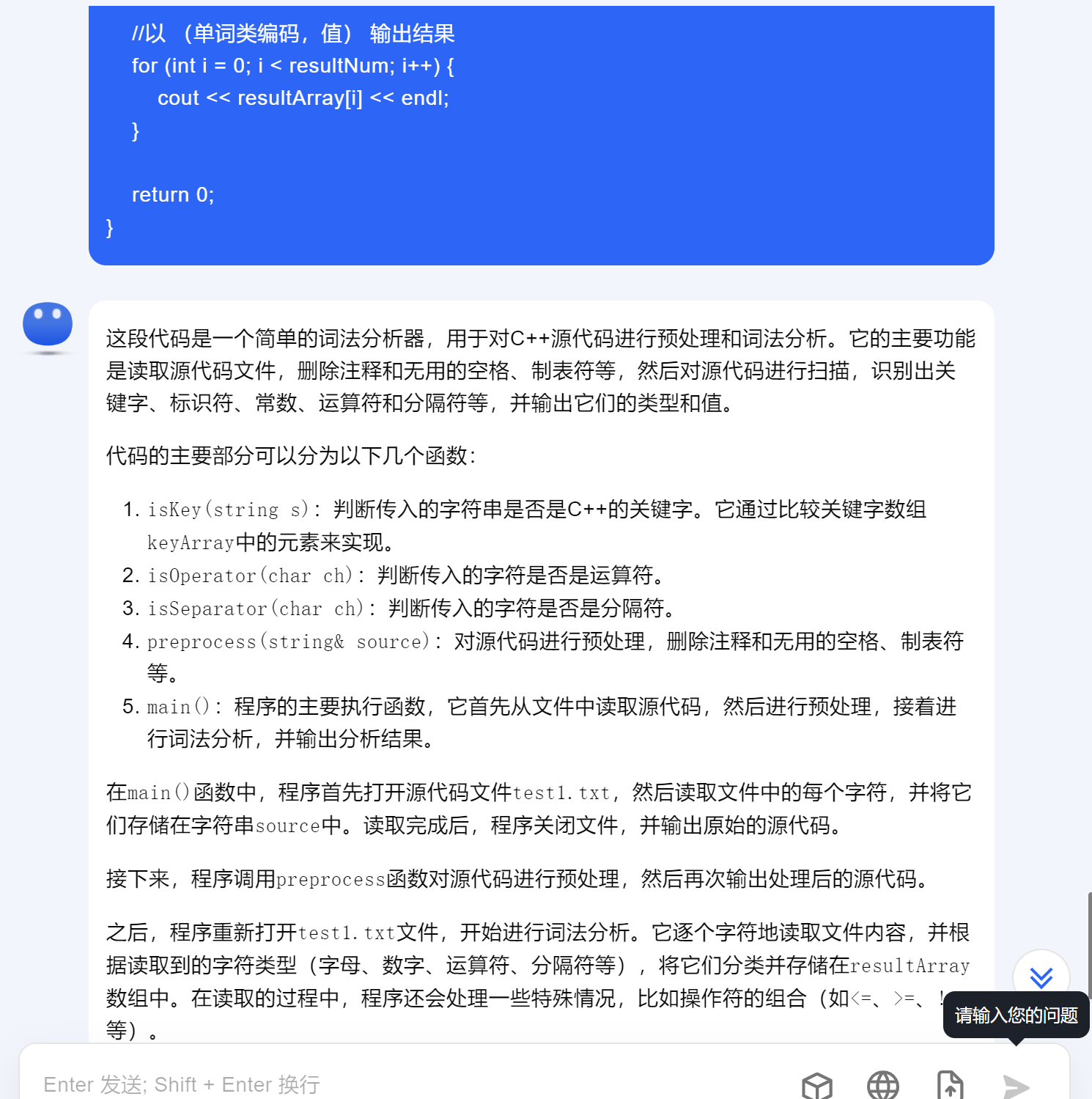
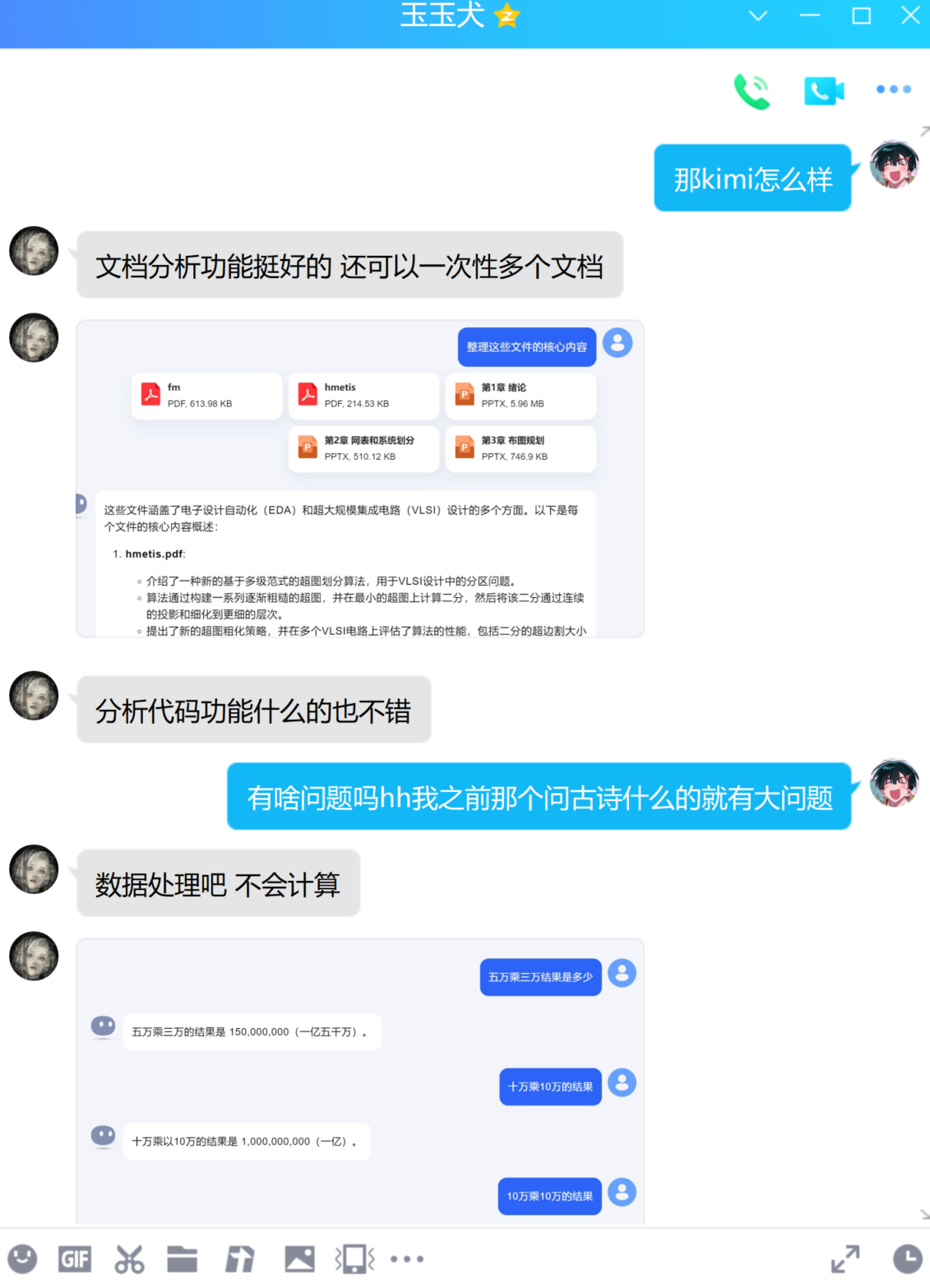
支持无损上下文长度200万字,有着独特且表现优秀的无损压缩技术。(比如以下超过2000字的代码,可以很好分析概括)
缺点:
缺少使用指南,需要方便不同用户使用。
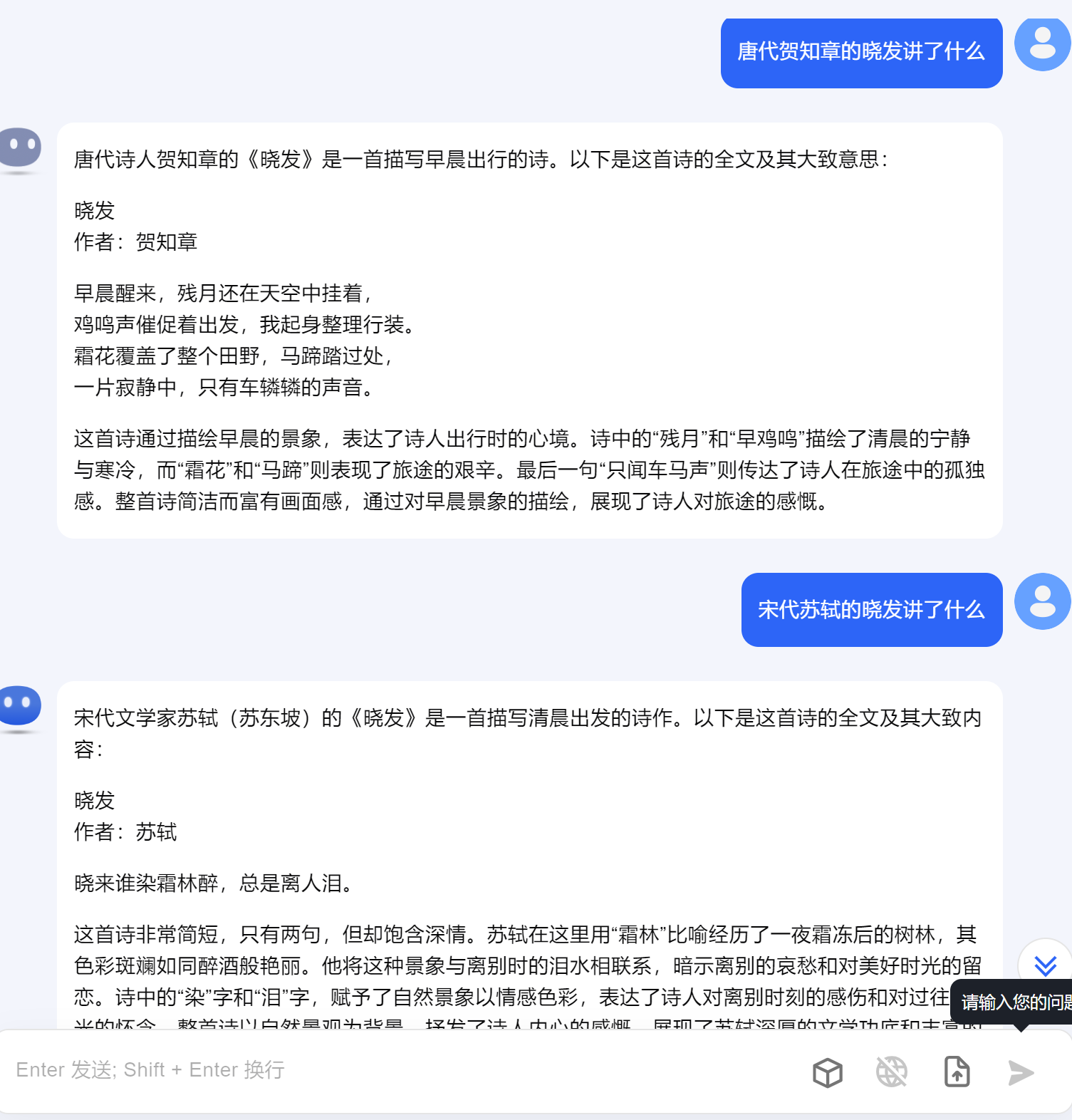
数据运算处理方面涉及文字逻辑和古诗文言方面会出错。
响应速度较慢。
增加算力
提高数据逻辑方面的能力
用户背景:计算机专业学生,有制作ppt,绘制流程图,文档阅读,总结关键信息,文档撰写,代码分析需求。
产品栏目:文件分析,回答计算问题等等。
问题:文字略微修饰的提问,数据计算出错。
亮点:在提取文件信息进行概括方面做的不错,长文本代码可以分析总结。
改进:提高响应速度,逻辑方面需要进一步加强。
操作系统:win11
浏览器:Google Chrome
Bug发现时间:2024/4/14
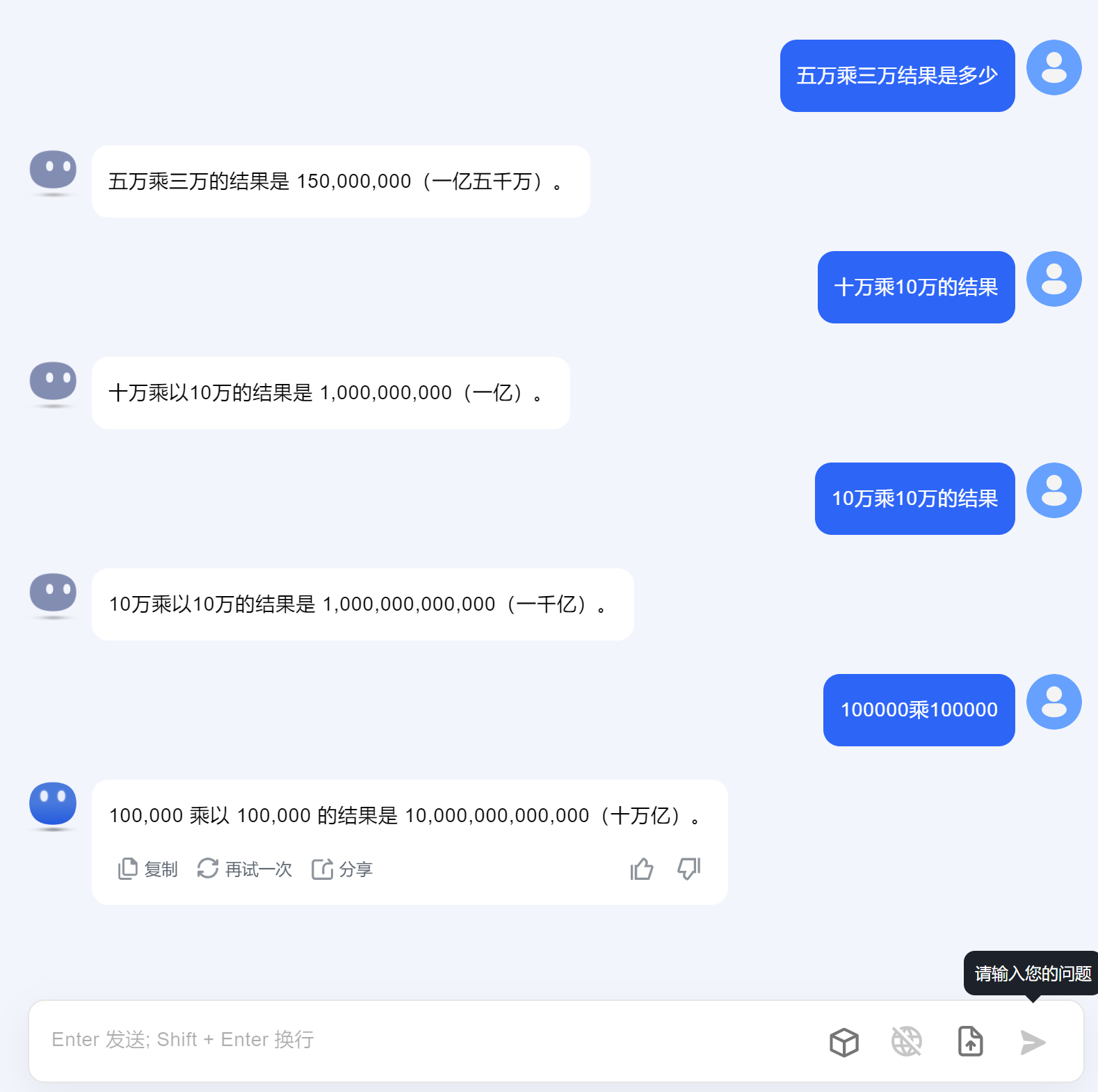
对数字进行中文表述,多位的数字相乘会出错,经常性发生。提问相关古诗文作者和诗歌不匹配的描述,会瞎编。
10万乘10万表述不一样结果不一样,且都错,其他涉及万的计算也出错
先进行正确古诗作者进行提问,后进行错误古诗作者,结果会瞎编。
提高数据逻辑运算和文言数据量。
d) 好,不错
描述 推荐指数 界面 网页简洁,使用方便 ☆☆☆ 功能 文档分析总结方面支持长文本,多文件 ☆☆☆ 体验 文档功能较为优秀,但在其他逻辑方面存在一些bug ☆☆☆
团队人数6人左右,计算机大学毕业生,并有专业UI支持
1.文心一言:文心一言基于深度学习技术,其主要依托于循环神经网络(RNN)、长短期记忆网络(LSTM)和注意力机制(Attention)等深度学习模型,依托了大量的语料库和训练数据,具有绘图等等丰富功能,这样的工程量由上述团队完成,大概需要一年半。
2.kimi:kimi核心技术包括解决长上下文序列问题的新经营机制和无损压缩技术,更加专注文档处理方面,这样的工程量由上述团队完成,大概需要一年。
1.文心一言:文心一言对比国内其他同类产品,功能更丰富,有画图,语音搜索,插件,百宝箱等等,满足用户体验,同时在中文自然语言方面做的很出色,所以个人认为总体排名靠上游。
2.kimi: kimi主打长文本,AI搜索+文档总结功能,有无损压缩技术,从而高效率无损处理百万级的长Token。而为了快速赶上长文本热潮,其他大厂只能退而求其次,选择检索增强生成RAG技术。所以长文本处理这块个人认为很不错,但目前Kimi没有支持流行的多模态功能,总体排名中偏上。
1.文心一言:可以对界面进行适当的精简,更好引导用户,增强模型训练。
2.kimi:优化信息量,提高逻辑分析能力,同时可以增加流行的多模块功能。
1.文心一言:上下文结合能力大部分模型都还没很好地做到,需要优化算法。
2.kimi:数据逻辑运算分析能力需要增加数据量,加强模型训练。
随着人工智能的发展进步,这类AI软件产品的市场规模正在不断扩大,并应用到越来越多用户群体的生活,学习和工作中。
目前市场上已有许多AI软件产品,OpenAI-ChatGPT,Google-Bard, 微软-Bing ,科大讯飞-星火 ,阿里-通义千问等等,大模型呈现出百花齐放、百家争鸣的景象。
它们的定位有涉及信息检索,内容创作,文本分析,自然语言处理,知识工作辅助等等,也有相互重叠的领域。
这类AI软件产品在不断地为用户提供更加丰富和便捷的智能服务,同时市场的竞争也将推动AI产品在功能、用户体验和创新方面的持续发展,整个领域正处在成长阶段。
核心用户群:
行业分布在IT互联网 ,教育领域的职场人士,老师,学生等等
使用场景多为知识问答,文本创作,代码辅助的用户
用户群体间关系:用户之间存在一定的交际关系,例如学生和老师,学生可以通过这类产品更好地学习知识,老师可以通过其进行课件的准备和知识的汇总等等。有利用其相互作用二次构成特定用户生态的可能性,丰富产品功能,形成紧密的用户社区。
新功能:个性化推荐
NABCD分析:
NABCD N(Need,需求) 用户可能需要更智能的,具吸引力和实用性的个性化推荐功能,因为这样产品才能够更好地理解他们的兴趣、偏好和需求,并提供与其相关的定制化的内容和建议,而不是通用的、一刀切的回复。 A(Approach,做法) 首先需要通过用户授权的方式收集用户的历史数据并确保遵守相关的隐私法规,利用机器学习和数据分析技术对这些数据进行分析,以了解用户的兴趣、偏好和行为模式。再进行特征工程确定最具预测性的特征,选择适当的推荐模型,如基于内容的推荐、协同过滤推荐、深度学习推荐等,根据具体情况进行调优和优化。同时需要建立实时监测和反馈机制,及时更新用户的个性化推荐结果,并根据用户的反馈和行为进行动态调整。还需要设计合适的技术架构,并确保与现有系统的兼容性和稳定性。这可能涉及到后端服务的搭建、API接口的设计等方面。 B(Benfit,好处) 个性化推荐可以帮助用户过滤和管理信息,更轻松地找到符合其需求和偏好的内容,使其更易于消化和理解,提高满意度和使用体验;可以增加用户与产品的互动和参与度,从而增强用户黏性和忠诚度; C(Competitors,竞争) 与其他产品相比,个性化功能可以对用户的行为和偏好进行实时分析和监测,从而不断优化推荐结果。这种数据驱动的能力可以帮助产品更好地理解用户需求,并提供更加个性化、精准的服务,从而增强竞争力。 D(Delivery,推广) 可以先在小区域进行测试,比如一所大学等,收集用户反馈及时性调整优化产品,再进行各种平台上营销投放,大范围推广。 角色配置:
项目经理(1人):
- 负责项目规划、进度管理和资源分配。
- 协调团队成员之间的合作,并监督项目的整体执行情况。
- 确保项目按时交付,并满足用户需求和质量标准。
前端开发工程师 (1人):
- 负责用户界面设计和前端开发。
- 设计和实现用户界面,包括推荐结果的展示和交互功能。
- 与后端团队合作,确保前端界面与后端服务的集成和交互正常。
后端开发工程师 (2人):
- 负责系统架构设计和后端开发
- 实现个性化推荐功能的后端服务和数据存储。
- 与前端团队合作,确保后端服务与用户界面的集成和交互正常。
机器学习工程师(2人):
- 负责数据收集、特征工程和模型选择。
- 设计和实现个性化推荐算法,并进行模型训练和调优。
- 确保推荐模型的准确性和性能优化。
软件测试人员 (1人):
- 根据项目需求和功能规格,制定测试计划
- 根据需求文档和功能规格,编写测试用例,覆盖个性化推荐功能的各个方面
- 执行测试用例,发现并报告软件缺陷,评估个性化推荐功能的用户体验
16个周期详细规划:
第1-2周:项目启动和规划阶段
- 项目经理:制定项目计划和里程碑,确定团队角色和责任。
- 所有团队成员:参与项目启动会议,理解项目目标和要求。
- 机器学习工程师:开始数据收集和分析,准备用于个性化推荐的数据集。
- 测试人员:开始制定测试计划和测试用例模板。
第3-6周:需求分析和系统设计阶段
- 项目经理:组织需求讨论会议,梳理个性化推荐功能的具体需求。
- 前端开发工程师:设计用户界面原型,并与团队成员讨论确认。
- 后端开发工程师:设计系统架构和数据存储方案,准备后端服务的开发环境。
- 机器学习工程师:进行数据探索和特征工程,准备数据集用于模型训练。
第7-10周:开发和实现阶段
- 前端开发工程师:开始实现用户界面,确保与设计原型一致。
- 后端开发工程师:开始开发个性化推荐功能的后端服务,搭建数据存储和处理流程。
- 机器学习工程师:选择合适的推荐算法,并开始进行模型训练和调优。
- 测试人员:根据需求文档和功能规格编写测试用例,并开始执行功能测试。
第11-14周:测试和优化阶段
- 测试人员:执行测试用例,发现并报告软件缺陷,评估用户体验。
- 前端和后端开发工程师:根据测试反馈和需求调整界面和功能,优化系统性能。
- 机器学习工程师:根据测试结果调整推荐模型参数,提高推荐准确性。
- 项目经理:监督测试和优化工作进度,确保项目按时交付。
第15-16周:验收和交付阶段
- 所有团队成员:参与最终系统验收和功能测试,确保个性化推荐功能符合要求。
- 项目经理:整理项目文档和成果,准备项目交付报告。
- 团队:参与项目交付会议,向客户演示个性化推荐功能并交付最终成果。
- 项目经理:整理项目总结和反馈,进行项目闭环。



