


535
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享目录

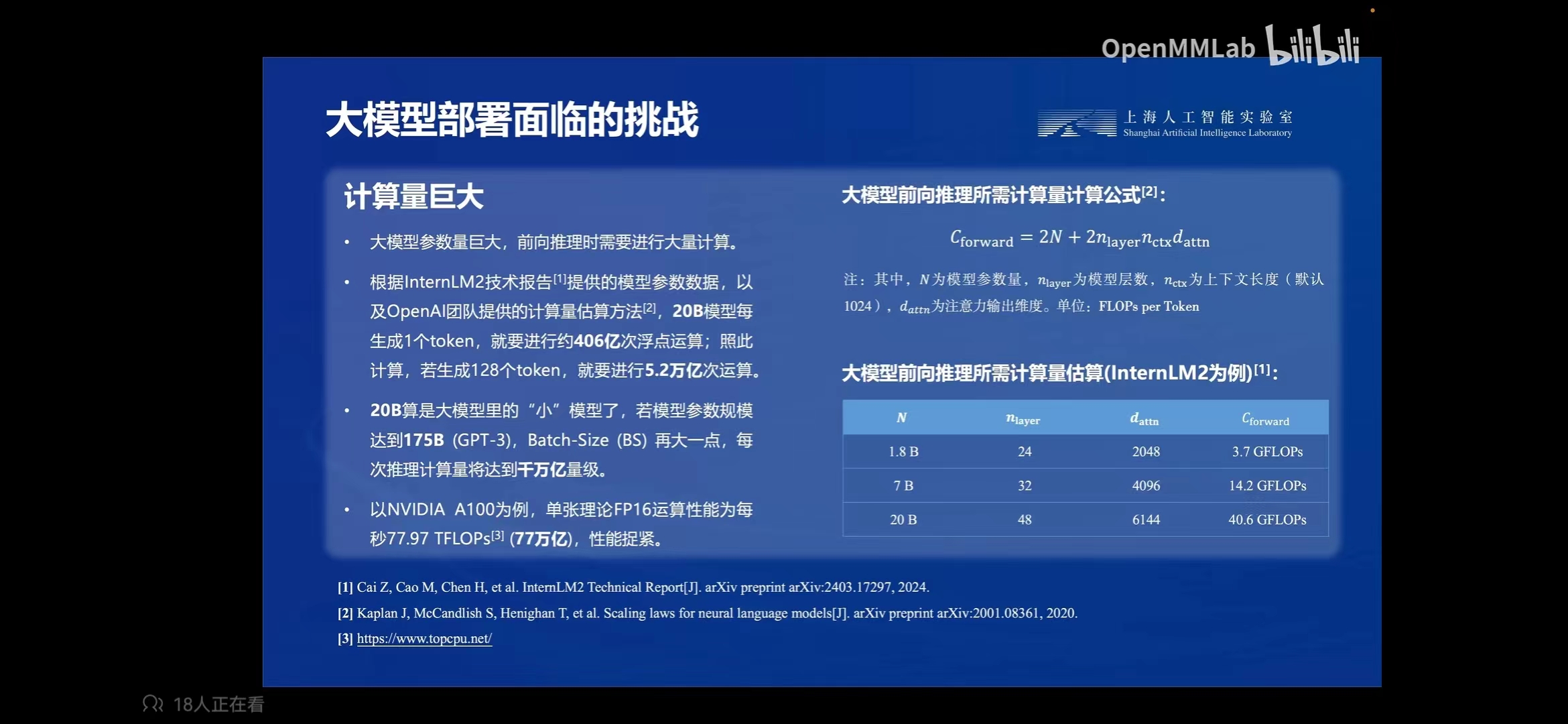
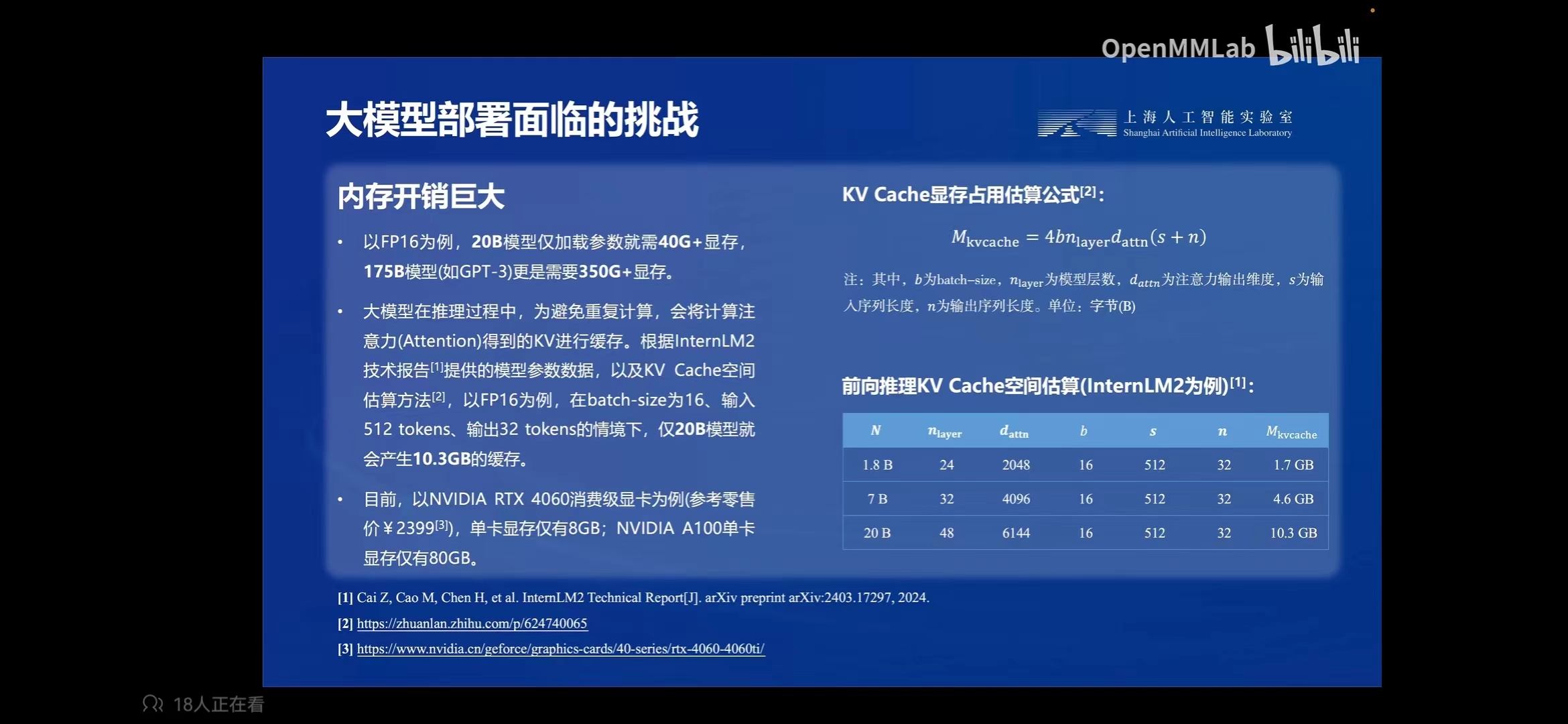
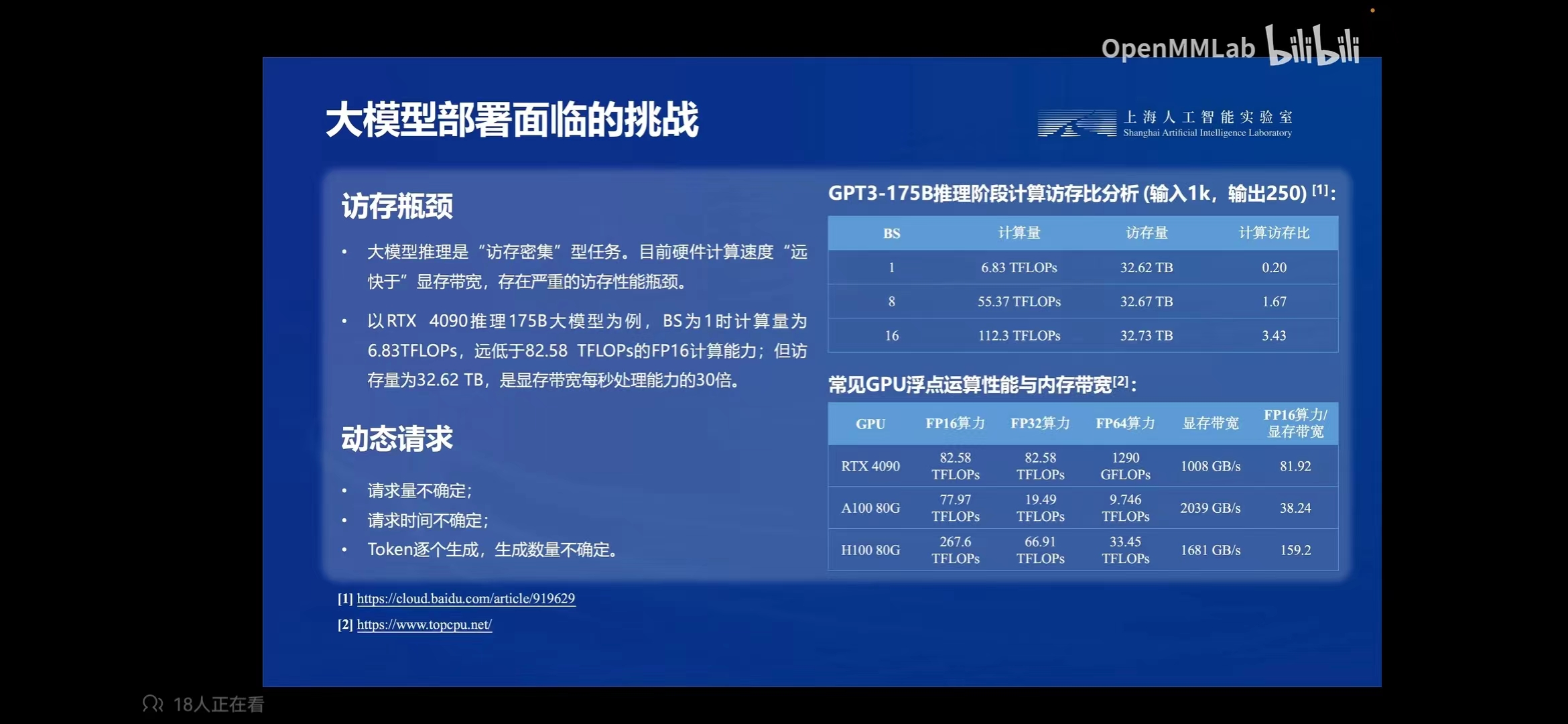
大模型部署面临的挑战 :

LMDeploy 由 MMDeploy 和 MMRazor 团队联合开发,是涵盖了 LLM 任务的全套轻量化、部署和服务解决方案。 这个强大的工具箱提供以下核心功能:
高效推理引擎 TurboMind:基于 FasterTransformer,我们实现了高效推理引擎 TurboMind,支持 InternLM、LLaMA、vicuna等模型在 NVIDIA GPU 上的推理。
交互推理方式:通过缓存多轮对话过程中 attention 的 k/v,记住对话历史,从而避免重复处理历史会话。
多 GPU 部署和量化:我们提供了全面的模型部署和量化支持,已在不同规模上完成验证。
persistent batch 推理:进一步优化模型执行效率。
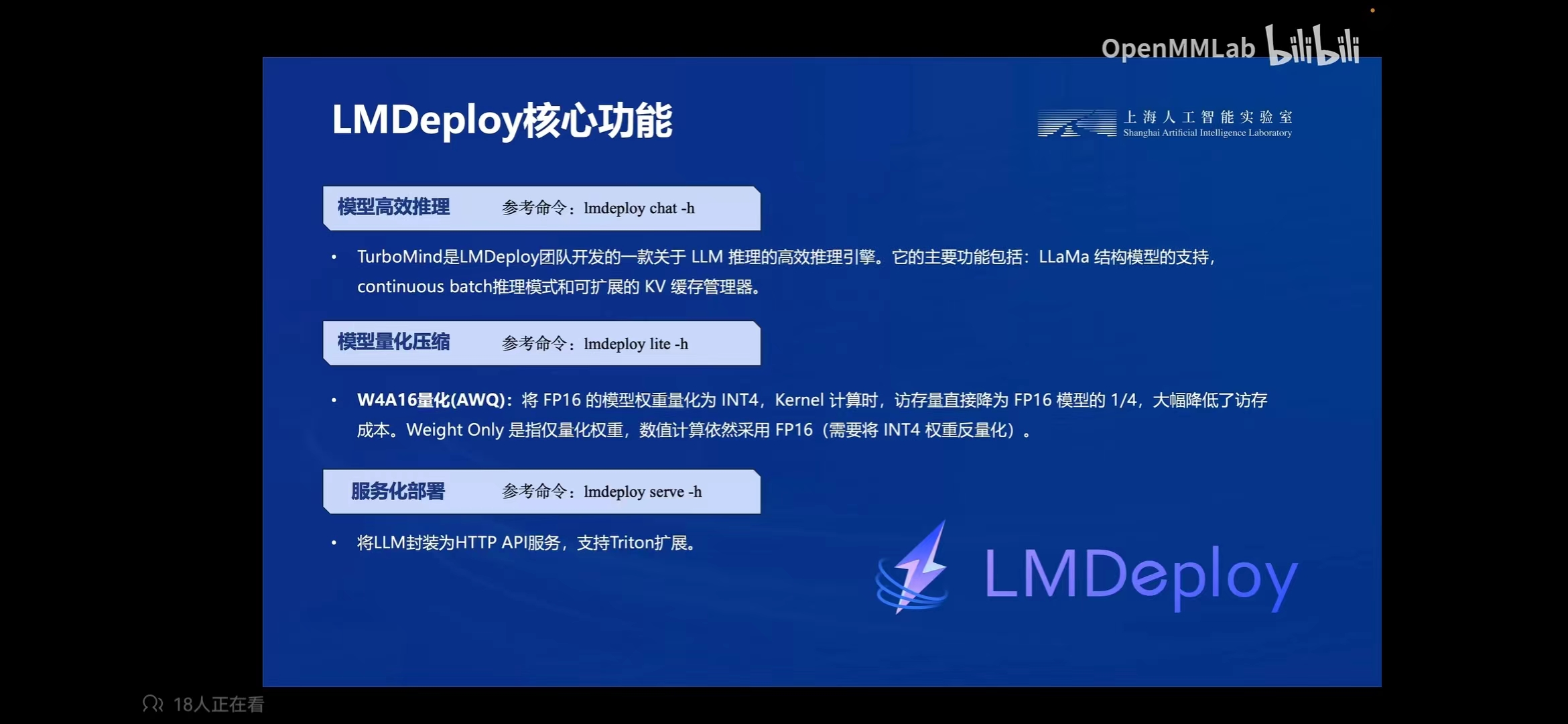
LMDeploy 支持 TurboMind 和 Pytorch 两种推理后端。运行lmdeploy list可查看支持模型列表
Note
W4A16 推理需要 Ampere 及以上架构的 Nvidia GPU
| 模型 | 模型并行 | FP16 | KV INT8 | W4A16 | W8A8 |
|---|---|---|---|---|---|
| Llama | Yes | Yes | Yes | Yes | No |
| Llama2 | Yes | Yes | Yes | Yes | No |
| SOLAR | Yes | Yes | Yes | Yes | No |
| InternLM-7B | Yes | Yes | Yes | Yes | No |
| InternLM-20B | Yes | Yes | Yes | Yes | No |
| QWen-7B | Yes | Yes | Yes | Yes | No |
| QWen-14B | Yes | Yes | Yes | Yes | No |
| Baichuan-7B | Yes | Yes | Yes | Yes | No |
| Baichuan2-7B | Yes | Yes | Yes | Yes | No |
| Code Llama | Yes | Yes | No | No | No |
| 模型 | 模型并行 | FP16 | KV INT8 | W4A16 | W8A8 |
|---|---|---|---|---|---|
| Llama | Yes | Yes | No | No | No |
| Llama2 | Yes | Yes | No | No | No |
| InternLM-7B | Yes | Yes | No | No | No |

