


122
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享| 这个作业属于哪个课程 | 2302软件工程 |
|---|---|
| 这个作业要求在哪里 | 团队作业——alpha冲刺 |
| 团队名称 | 智创未来队 |
| 团队置顶集合随笔链接 | 智创未来队——置顶集合随笔 |
| 这个作业的目标 | 记录测试安排、测试工具使用、测试心得体会与综合概述 |
| 其他参考文献 | 《构建之法》 |
| 学号 | 姓名 | 测试内容 |
|---|---|---|
| 222100421 | 林宜斌 | 测试后端登录接口、 用户认证接口、 知识库接口 |
本次测试的数据使用 python 编码来获取
安装以下Python库:
pymysql 对应数据库的连接器,用于连接数据库并获得faker安装命令如下:
pip install pymysql faker
步骤1:连接数据库
编写Python脚本以连接MySQL数据库:
import pymysql
def connect_to_db():
try:
connection = pymysql.connect(host='localhost',
user='root',
password='password',
database='cloud',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
return connection
except Exception as e:
print(f"Error connecting to the database: {e}")
return None
步骤2:通过表名获取表结构
# 获取表结构的函数
def get_table_structure(connection, table_name):
with connection.cursor() as cursor:
query = f"DESCRIBE `{table_name}`"
cursor.execute(query)
return cursor.fetchall()
# 打印表结构信息
for table, structure in tables_structure.items():
print(f"Structure for {table}:")
for column in structure:
print(f" {column['Field']}: {column['Type']}")
步骤3:根据表结构生成对应的数据
使用faker库为每个表生成1万条模拟数据:
fake.word() 生成fake.paragraph() 生成# 生成对应表的对应数据
# 对表中的 varchar 类型 可以使用 fake.word() 生成
# 对表中的 text 类型 可以使用 fake.paragraph() 生成
def generate_faker_data(table_structure, num_records):
data = []
for _ in range(num_records):
record = {}
for column in table_structure:
if column['Field'] == 'id':
value = random.getrandbits(22)
elif column['Type'] == 'varchar(255)':
value = fake.word()
elif column['Type'] == 'text':
value = fake.paragraph()
elif column['Type'] == 'datetime':
value = fake.date_time_between(start_date='-2y', end_date='now').date()
elif column['Field'] == 'del_flag':
value = 0
elif column['Field'] == 'userId':
value = random.getrandbits(12)
else:
value = None
record[column['Field']] = value
data.append(record)
return data
** 步骤4:将数据以csv结构写入文件**
def write_to_csv(data, table_name, file_path):
with open(file_path, 'w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
writer.writeheader()
writer.writerows(data)
** 步骤5: 编写main函数**
def main():
db_connection = connect_to_db()
print("hello here!")
if db_connection:
tables = ['knowledge', 'knowledge_page', 'page', 'sys_auth', 'sys_role', 'sys_role_auth', 'sys_user', 'sys_user_role', 'user_knowledge']
for table_name in tables:
table_structure = get_table_structure(db_connection, table_name)
faker_data = generate_faker_data(table_structure, 1000)
file_path = f"C:\\Users\\asus\\Desktop\\data\\{table_name}.csv" # CSV文件将被保存在这里
write_to_csv(faker_data, table_name, file_path)
print(f"Data for {table_name} has been written to the CSV file.")
db_connection.close()
else:
print("Failed to connect to the database.")
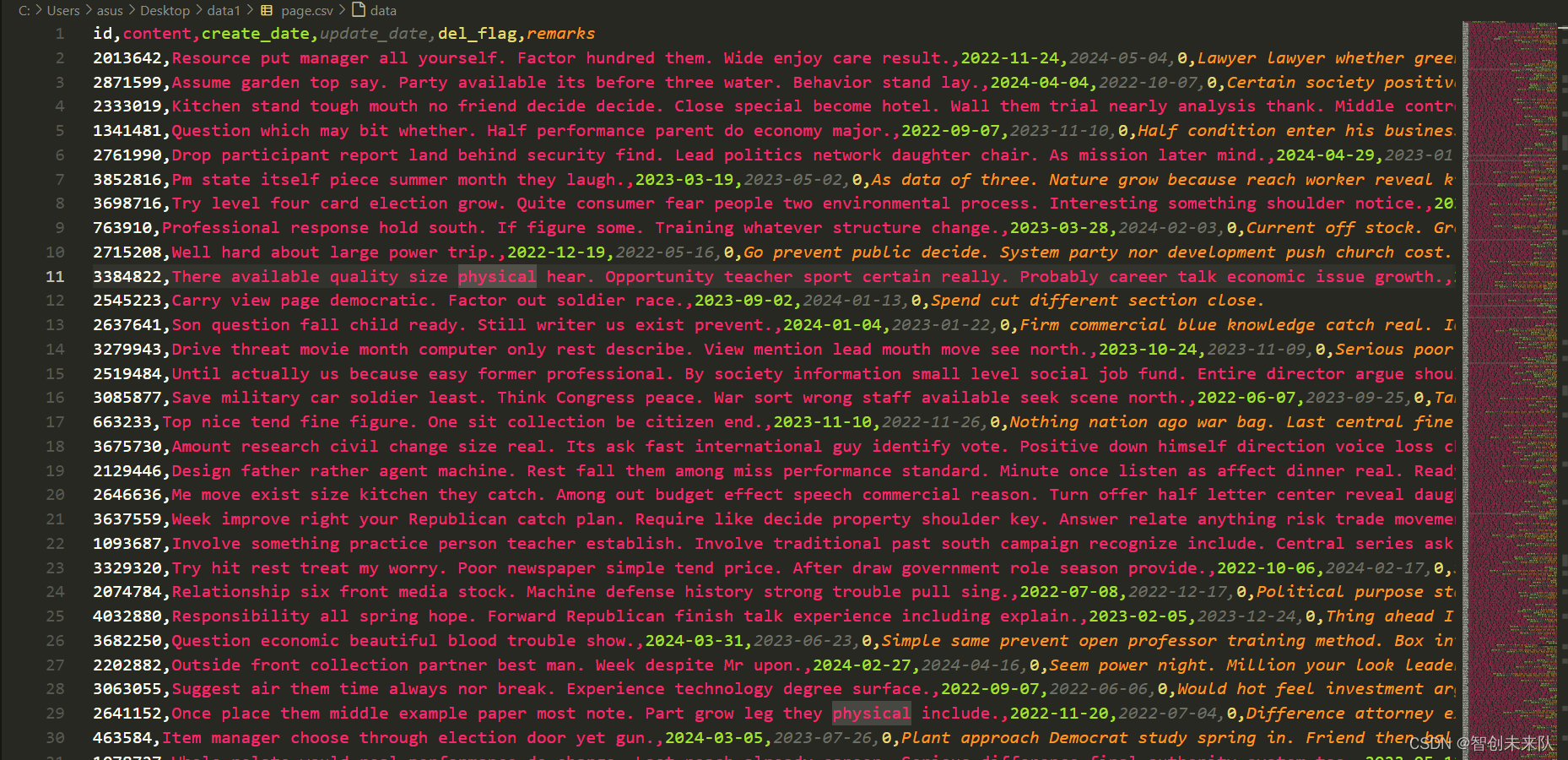
Number of Threads (Users): 在 JMeter中,线程组代表了一定数量的虚拟用户,设置为期望的并发用户数,如50.
Ramp-Up Period: 设置所有用户启动的时间间隔,如60秒。这样,JMeter 将逐渐增加并发用户数,避免一开始就对服务器造成过大压力。
Loop Count: 设置用户执行请求的次数。如果设置为1,每个用户将只执行一次请求。
步骤 1: 启动 JMeter,配置请求的基本信息
通过命令行窗口启动JMeter 应用程序,添加消息头管理器,与所有线程组同级,可以为所有线程组使用。设置键值对Content-Type: application / json; charset=utf-8,明确请求体的类型为json。

步骤 2: 创建线程组
在 JMeter 主界面,右键点击测试计划,选择“添加” -> “线程(用户)” -> “线程组”,可以根据要测试的不同接口设置多个不同的线程组。这里设置了投票线程组、登录线程组、和用户与运动员信息请求线程组。
步骤 3: 配置线程组
在线程组中,设置虚拟用户数(线程数)为,Ramp-Up Period(所有用户启动的时间间隔)为10秒,循环次数为每个用户20次。
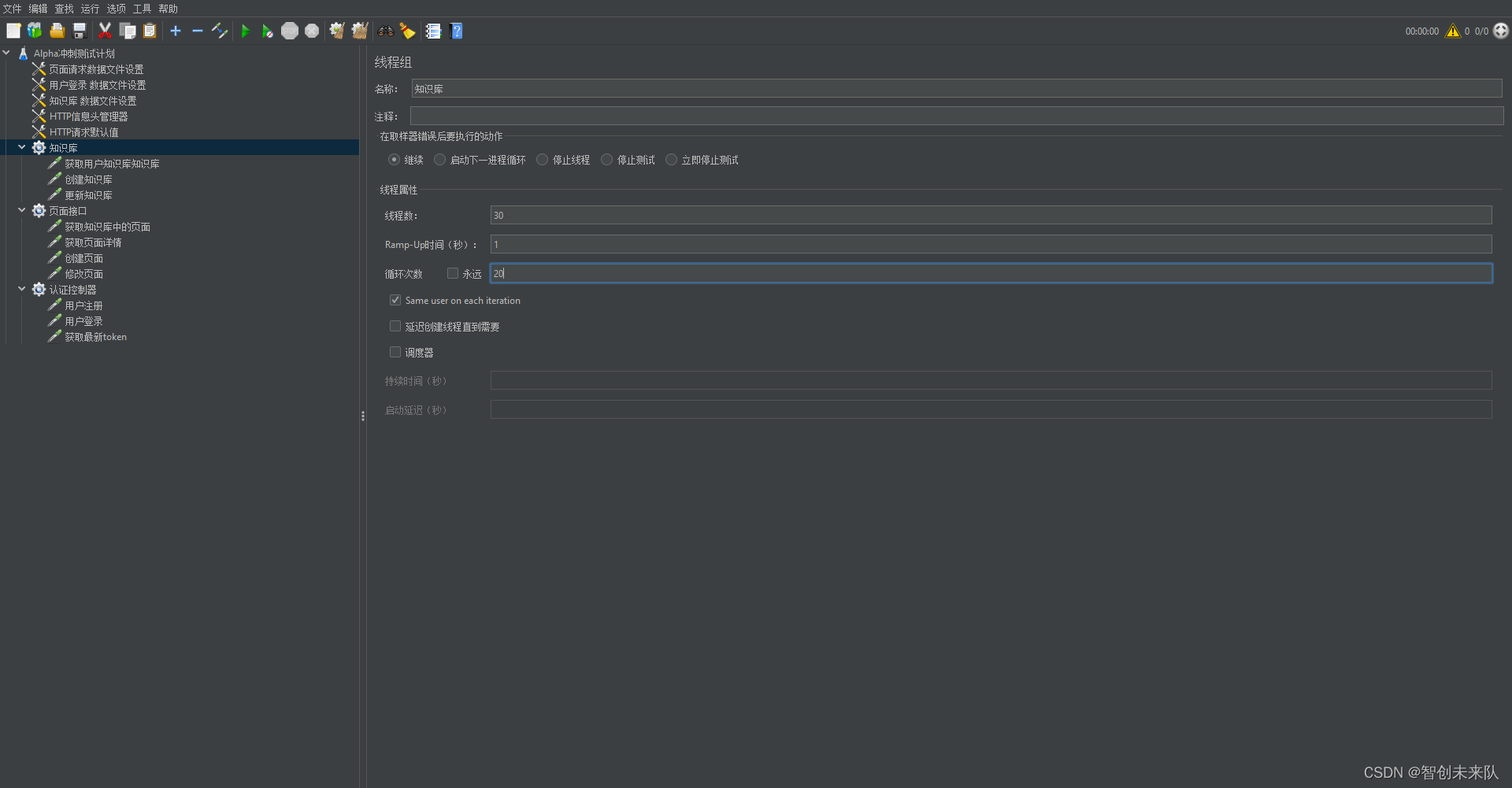
** 步骤 4: 添加 HTTP 请求**
/page 或 /page/detail/${pageId}。
步骤 5: 导入csv数据文件
在进行测试时,经常需要模拟具有不同属性的大量用户。例如,在测试用户登录功能时,我们可能需要不同的用户名和密码组合来模拟真实世界的使用场景。在测试获取用户信息的请求时,我们需要不同的用户ID来模拟真实的使用场景。为了实现这一点,JMeter 支持使用 CSV 数据文件来动态设置测试参数。
为什么使用 CSV 文件?
导入 CSV 文件的步骤
准备 CSV 文件:创建一个 CSV 文件,其结构与测试需求相匹配。例如,测试登录功能,CSV 文件包含以下列:username,password,CSV文件在数据准备阶段生成好了。
配置 CSV Data Set Config元件:
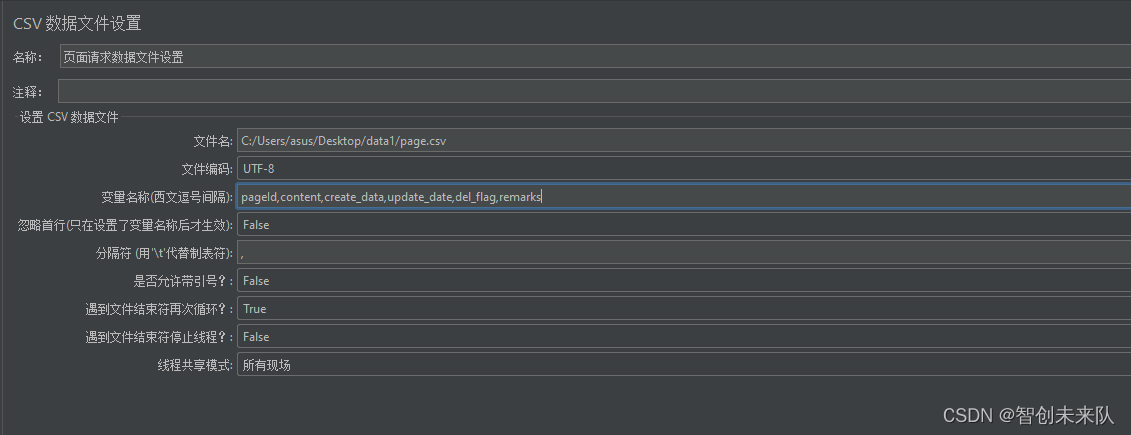
在 测试计划中,右键点击 选择“添加” -> “配置元件” -> “CSV Data Set Config”。找到想要使用 CSV 文件添加到设置中。
填写 CSV Data Set Config:
Filename:填写 CSV 文件的路径和文件名。
Variable Names:指定一个变量名,如 id,content,它将用于在 HTTP 请求中引用 CSV 文件中的数据,可以根据需求来引用
Delimiter:设置 CSV 文件中使用的分隔符,默认为逗号 ,。
Sharing Mode:设置为 “All threads share CSV files” 允许所有线程共享 CSV 文件。
引用 CSV 数据:
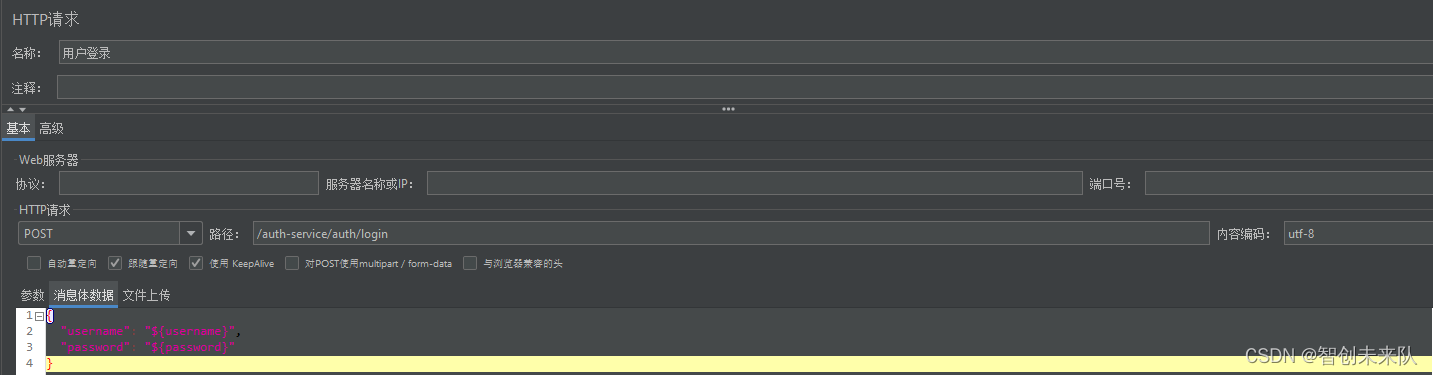
在 HTTP 请求的“参数”部分,添加新的参数,其值使用 ${variableName} 语法引用 CSV 文件中的数据。例如/page/detail/${pageId}。请求体中数据则设置成这样: {"password": "${password}", "username": "${username}"}。JMeter会自动解析前面设置的csv文件,提取出变量值,拼接到各个请求中。
运行测试:
启动 JMeter 测试,观察到测试使用 CSV 文件中的数据来动态替换参数。
步骤 6: 设置 HTTP 请求参数、请求体数据
在 HTTP 请求下方的参数部分,添加所需的参数。如登录请求中 { "username": "${username}", "${password}": "123456"},同样通过${varName}来引用csv数据文件中的内容。在请求体中也通过这样的方法添加数据。
步骤 7: 添加监听器
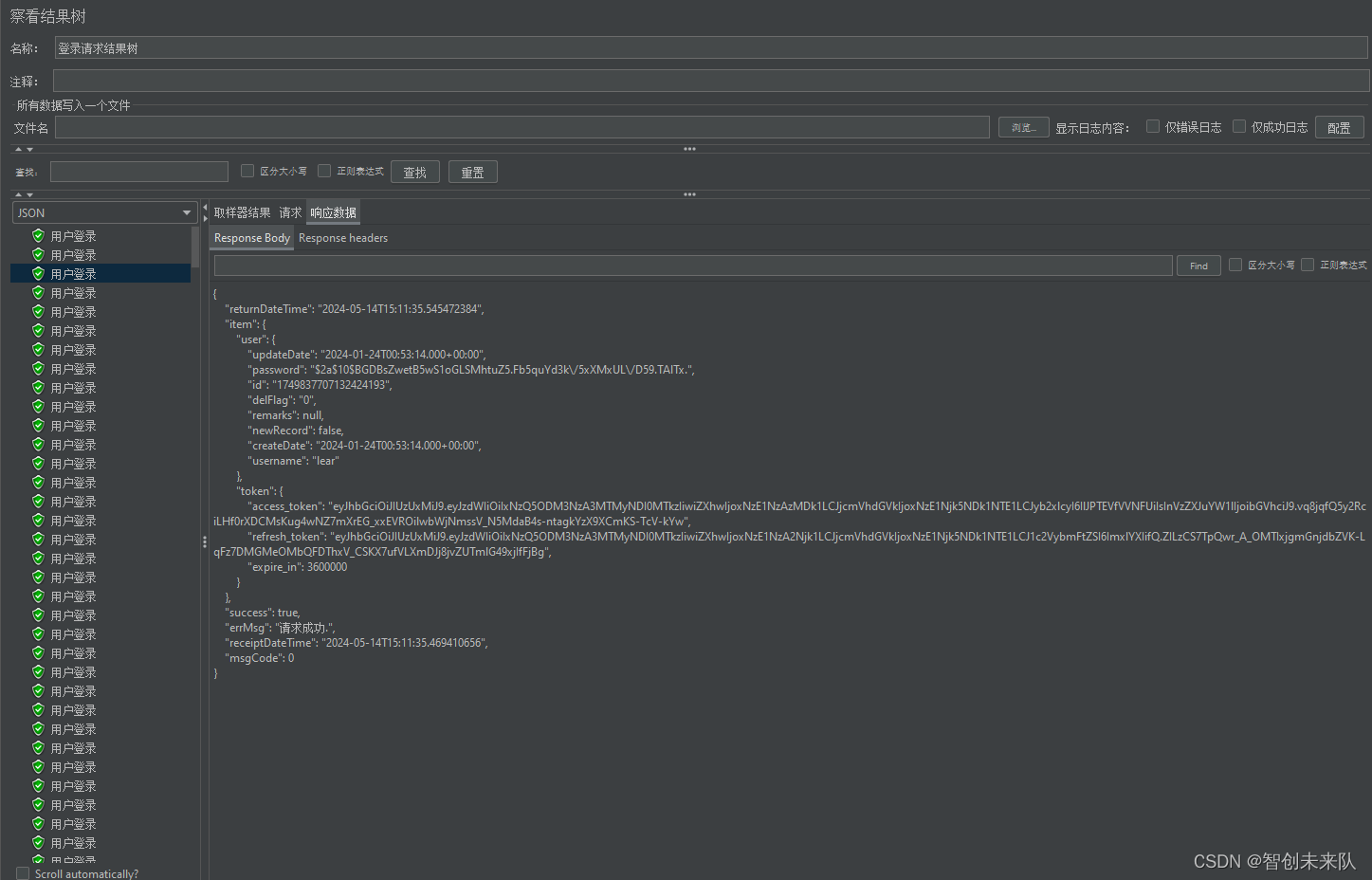
监听器用于展示测试结果。右键点击线程组或测试计划,选择“添加” -> “监听器”,可以添加“查看结果树”等。点击运行可以查看每个请求的详细情况,如请求信息、响应信息等。
请求默认值
请求头信息管理器
csv格式文件设置
...
测试计划
|-- 线程组
|-- HTTP 请求(登录)
|-- HTTP 请求(投票)
|-- 监听器(查看结果树)
|-- 监听器(图形结果)
点击运行按钮执行对应的请求操作,点击生成的结果树来查看具体的某个请求的情况。
用户登录请求汇总报告:

用户认证请求汇总报告:

获取用户知识库汇总报告
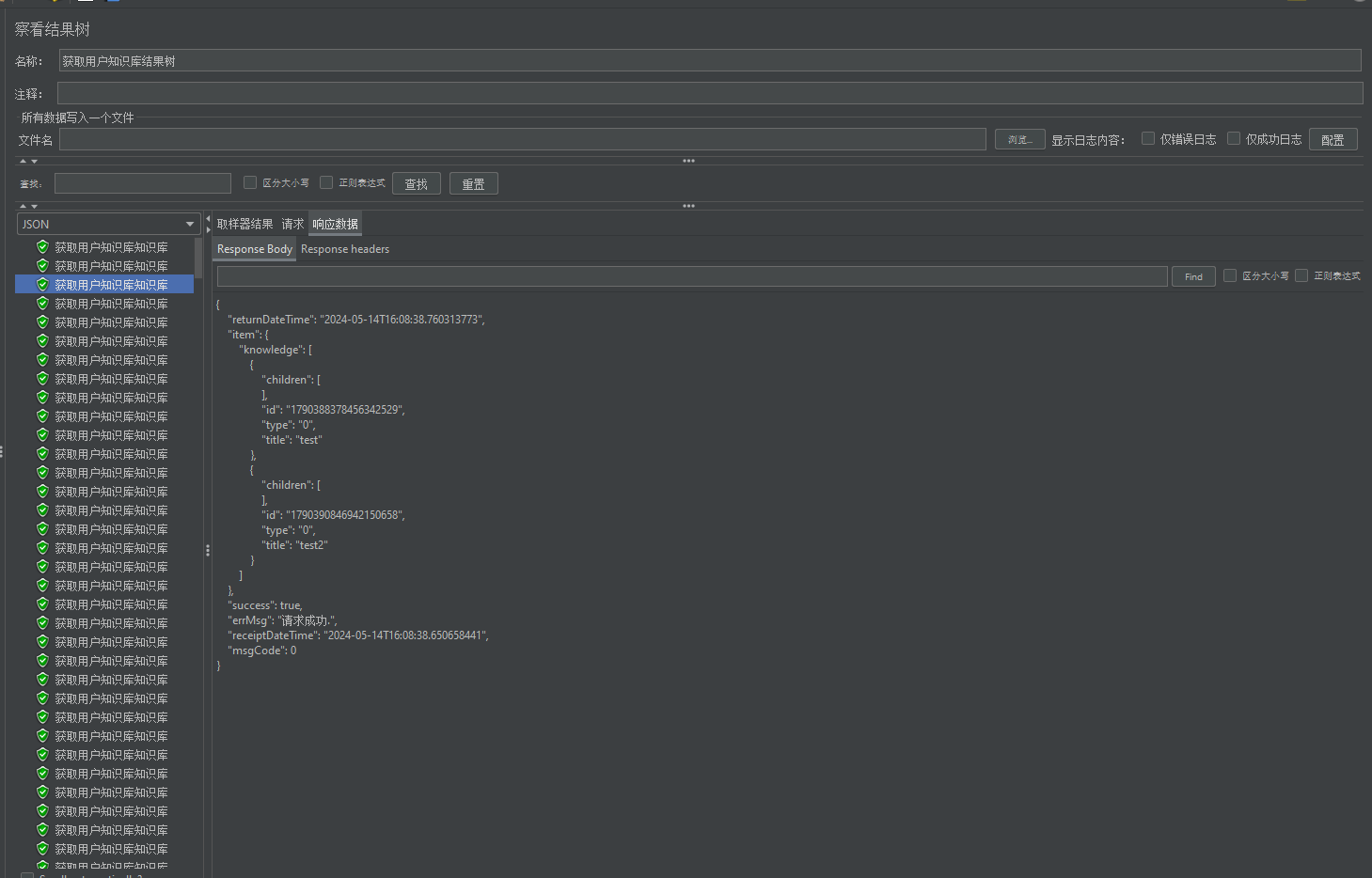

页面请求汇总报告

经过本次软件系统的测试,我们团队验证了系统的各个关键组件,包括后端服务、数据库交互等。测试结果表明,系统在较高负载情况下依然保持了良好的稳定性和响应速度。
展望未来,我们计划进一步完善测试流程与自动化测试方法以提高测试的覆盖率和效率。同时,我们也将探索持续集成和持续部署的最佳实践,确保开发和测试的无缝对接。通过实施测试驱动开发(TDD)策略,我们将测试工作与编码过程结合,从源头上保证代码质量,减少后期的维护成本。
JMeter 是一个强大的开源测试工具,它通过模拟多种用户请求来对后端服务进行性能、压力和稳定性测试。在测试过程中,可以利用 JMeter 的丰富元件来设计测试场景,监控关键性能指标,并使用断言来验证响应的正确性。JMeter 支持结果分析和报告生成,可以帮助团队测试系统稳定性、识别性能瓶颈,进行调试优化,并确保后端服务的持续性能和质量。


