


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享白箱测试是一种软件测试方法,测试人员在测试过程中了解和利用程序内部的结构和实现细节。它也被称为透明盒测试、玻璃盒测试或结构化测试,根据程序内部逻辑测试程序,检查程序中的每条通路是否按照预定要求正确工作(即穷举路径)。
为了保证测试的覆盖率,我们需要保证:
语句覆盖:测试用例确保每条语句至少执行一次。
分支覆盖:测试用例确保每个分支(如if和else)至少执行一次。
条件覆盖:测试用例确保每个条件表达式的所有可能结果(true和false)都至少执行一次。
路径覆盖:测试用例确保每一条可能的执行路径至少执行一次
边界值测试:测试边界值和特殊情况,例如最小和最大输入值、边界条件和异常情况。
在第三单元的测试中,要求我们自己实现Junit测试,这就是白箱测试,我们需要从自己编写测试程序和自己构造数据,这两方面都需要我们做到足够的覆盖率以及覆盖边界数据。
黑箱测试,测试人员在测试过程中不考虑程序内部的实现细节,只关注输入和输出之间的功能关系。
以下是黑箱测试的方法:
等价类划分:将输入数据划分为若干等价类,确保每个类至少有一个测试用例。
边界值分析:测试输入数据的边界值,特别是极限值和临界点,以发现边界条件下的错误。
因果图分析:通过因果图设计测试用例,分析输入条件之间的关系及其对输出的影响。
状态迁移测试:基于状态机模型,测试系统在不同状态下的行为及其状态迁移。
决策表测试:使用决策表描述不同输入组合及其对应的输出,确保所有可能的组合都被测试。
通过以上的分析,黑箱测试和白箱测试各有自己的特点。
白箱测试需要我们掌握代码内部的结构和实现方法,而黑箱测试不需要测试人员掌握内部的代码,但是需要尽量保证覆盖。白箱测试更加具有针对性,黑箱测试则需要大量的测试以发现代码的问题。
单元测试是针对程序模块(软件设计的最小单位)来进行正确性检验的测试工作。它的目的是在开发过程中尽早发现代码中的缺陷,并确保每个功能模块都能够独立地正常运行。
单元测试的每个测试只关注一个特定的功能单元,独立于其他测试,每次测试执行速度很快,通常只测试单个函数或方法。如果我们能够在写方法的同时及时为每个方法编写单元测试,那么我们可以在早期发现代码存在的问题。
功能测试是测试软件功能是否符合需求,通常采用黑箱测试方法。
功能测试的主要目的是确保软件在实际操作中能够按照预期执行各项功能,满足用户需求。
集成测试是软件测试的一种方法,用于验证不同组件、模块或子系统之间的集成是否正确、协同合作,并能够产生预期的结果。集成测试旨在检测和解决在组件集成过程中可能出现的问题。
在集成测试中,被测试的软件系统已经通过单元测试对各个组件进行了测试,并且这些组件已经通过了单元测试阶段。集成测试的目标是验证组件之间的接口、数据传递和交互是否正常,以及确保整个系统在集成后能够正确运行。
压力测试是一种软件测试方法,旨在评估系统在超出正常工作负载的极端条件下的表现。其目的是确定系统的稳定性和可靠性,识别性能瓶颈和潜在的崩溃点。
压力测试的主要目标是找出系统的瓶颈、性能问题和资源耗尽情况,并评估系统在负载增加时是否能够满足性能要求。这种测试方法可以揭示系统的弱点、性能限制和潜在的故障,为系统的优化和调整提供指导。
回归测试是软件测试的一种方法,用于确认在进行软件修改、修复或增加新功能后,原有功能是否仍然正常工作,以及新的修改是否引入了新的错误或问题。当对软件进行修改时,无论是修复缺陷、添加新功能还是进行系统配置变更,都存在可能引入新的错误或导致原有功能出现问题的风险。回归测试的目的是在进行修改后,重新运行既有的测试用例,以验证软件系统在修改后的版本中是否仍然具有预期的行为。回归测试确保软件在进行更新、修复、功能增强或性能改进后,依旧能够稳定地运行。
在第一次和第二次作业中,我们需要构造不同的人以及为不同的人添加关系,我在构造数据时直接使用的random函数,每次随机生成人的id和name,然后添加到network里,共生成100个人,然后再为人添加关系,并且生成随机的value,共生成4000多条关系,使得基本上每两个人之间都有关系,这样更容易测试出bug。
在第三次作业中,数据的构造就是在前两次作业的基础上添加消息和发送消息。我的构造方法是每添加一条新的关系就发送消息(在发送消息之前就先添加好关系),发送消息需要的次数每次是随机的,而且是双向的。除此之外,三种消息类型都要涉及,并且消息需要发送一部分,保留一部分。
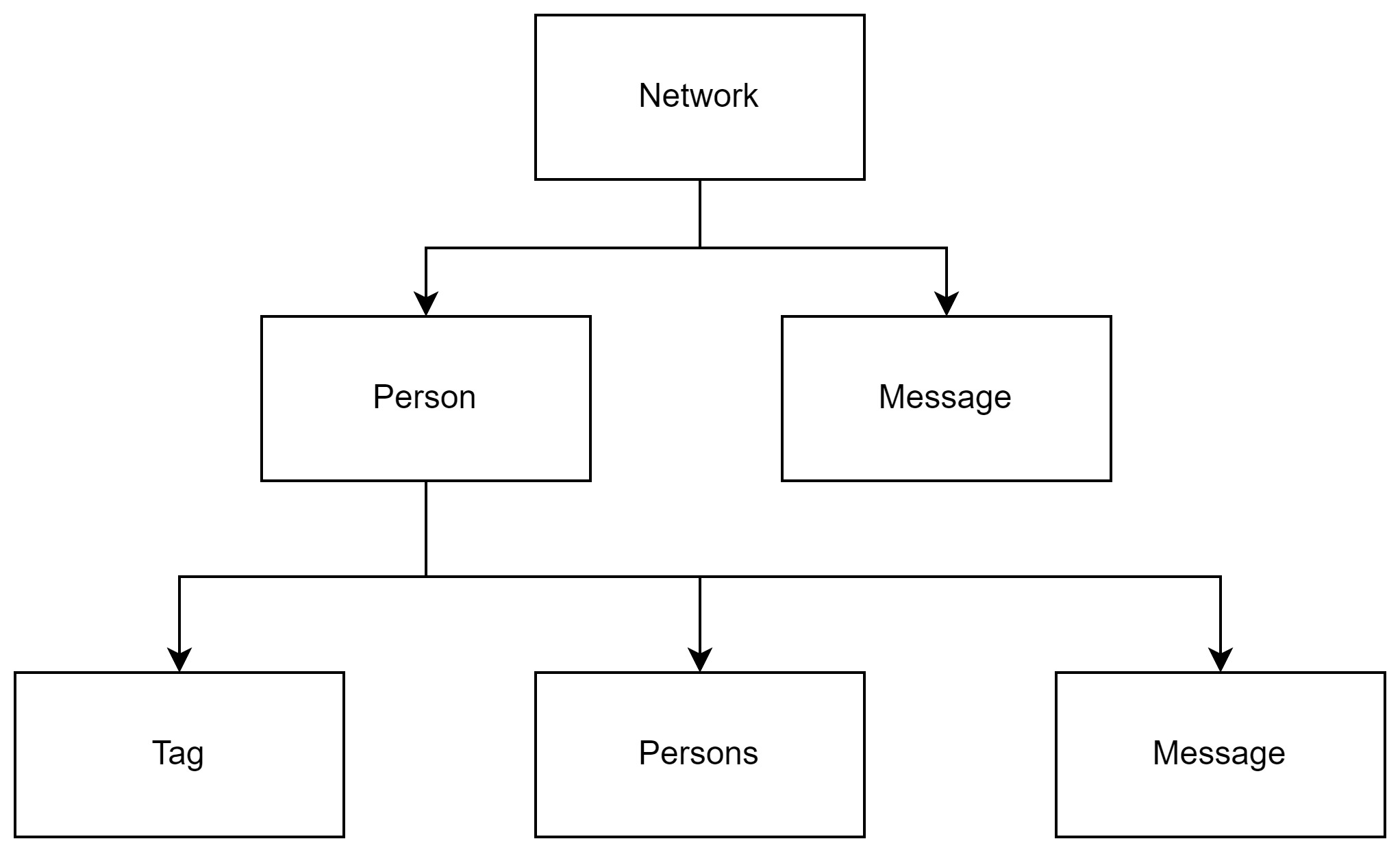
第三单元的整体架构是十分清晰的,network负责管理所有的Person和所有未发送的Message,每个Person负责管理自己的Tag和自己的熟人(Persons)以及自己的Messages,而Message有三种。
图模型的构建是比较简单的,只需要按照jml的规则就能构造出一个社交网络
而图模型的维护是比较复杂的。这里涉及两个问题:并查集的维护和最短路径的求解。
并查集是服务于queryBlockSum方法,用于查询连通块数量,并查集的查找可以通过路径压缩优化查找效率,并查集的合并可以通过按秩合并优化合并效率。而在我们的作业中,是存在删边操作的,而原始的并查集不支持删边操作,只能进行重建。为了提高性能,我在这里实现了一种写时复制的并查集,也就是设置脏位,只在查询时重建并查集。
至于最短路径的求解,我采用了dijkstra算法,为了提高性能, 使用优先队列存储待处理的节点和距离,按距离的升序排列。
以下是我的实现:
private int dijkstra(int startId, int targetId) {
PriorityQueue<int[]> pq = new PriorityQueue<>(Comparator.comparingInt(arr -> arr[1]));
for (Integer id : persons.keySet()) {
distances.put(id, Integer.MAX_VALUE);
}
distances.put(startId, 0);
pq.offer(new int[]{startId, 0});
while (!pq.isEmpty()) {
int[] current = pq.poll();
int currentId = current[0];
int distance = current[1];
if (currentId == targetId) {
return distance;
}
List<Person> neighbors = new ArrayList<>(
(((MyPerson) (persons.get(currentId))).getAcquaintance().values()));
for (Person neighbor : neighbors) {
int neighborId = neighbor.getId();
int newDistance = distance + 1;
if (newDistance < distances.get(neighborId)) {
distances.put(neighborId, newDistance);
pq.offer(new int[]{neighborId, newDistance});
}
}
}
return -2;
}
在第二次作业中的queryTagValueSum中,我没有维护ValueSum,而是直接采用了jml的O(n^2)算法,导致超时。
在这里我有一个误区,如果维护valueSum,那么需要在添加关系和修改关系的时候遍历tags,我起先并没有觉得这样会提高性能,所以没有优化。但是实际上这样是把计算valueSum的复杂度分摊出去了,对于程序整体是由好处的。而且我们在在添加关系和修改关系的时候本来就需要维护很多东西,实际上把维护ValueSum的工作放在添加和修改关系这里是顺带的事,并没有增加很多复杂度。而且只需要查找共同熟人的tags进行维护就可以,不需要遍历全局的tags,这也省下了不少时间
除此之外,还有一些其他的小优化能提高性能:将Person所管理的messages容器设置为LinkedList,network查询coupleSum是设置脏位。
对于规格与测试分离的理解:
规格与实现分离是指将规格说明与具体实现分开,以实现更好的灵活性、可维护性和可扩展性。通过本单元作业,我认识到了规格与实现分离的一些好处:
在第一次实验课中,我们就利用了jml进行了junit测试
在进行测试之前,我们需要理解规格信息和明确功能要求并且识别边界条件,通过这样的工作,我们理解了这个方法的功能,从而做好数据生成和测试的工作。
数据生成需要我们结合被测试代码的规格进行,虽然课程组要求我们不需要很强的数据点来判断错误,但并不意味着我们可以随便生成数据。如hw10需要我们生成尽量没有联系的特殊图,hw11要求我们生成含有四种message的数据点。
之后就是对着jml一条一条写测试代码,保证满足前置条件,将按照jml得到的结果和自己的代码实现所得到的结果进行比较,确保没有副作用的产生。
这个单元整体是比较轻松的,我也学到了不少东西,主要是对于图论算法的学习以及Junit的复习。但是我对于jml本身反而体会不太深刻,对于这种契约式编程还是不太适应。不管怎么说,在第三单元的写代码的过程中,还是锻炼了我的编程能力的。



