


93
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享# 20234212 2022-2023-2 《Python程序设计》综合实践
课程:《Python程序设计》
班级: 2342
姓名: 童德昌
学号:20234212
实验教师:王志强
实验日期:2024年4月22日
必修/选修: 公选课
## 1.实验内容
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
课代表和各小组负责人收集作业(源代码、视频、综合实践报告)
例如:编写从社交网络爬取数据,实现可视化舆情监控或者情感分析。
例如:利用公开数据集,开展图像分类、恶意软件检测等
例如:利用Python库,基于OCR技术实现自动化提取图片中数据,并填入excel中。
例如:爬取天气数据,实现自动化微信提醒
例如:利用爬虫,实现自动化下载网站视频、文件等。
例如:编写小游戏:坦克大战、贪吃蛇、扫雷等等
注:在Windows/Linux系统上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
## 2. 实验过程及结果
1.安装必要的Python库
我们需要安装pytesseract库来进行OCR识别,以及pandas和openpyxl库来操作Excel文件。此外,还需要安装PIL或Pillow库来处理图片。
2.配置Tesseract路径
我们需要额外安装Tesseract OCR引擎,并指定Tesseract的安装路径,以便pytesseract库能够找到它。
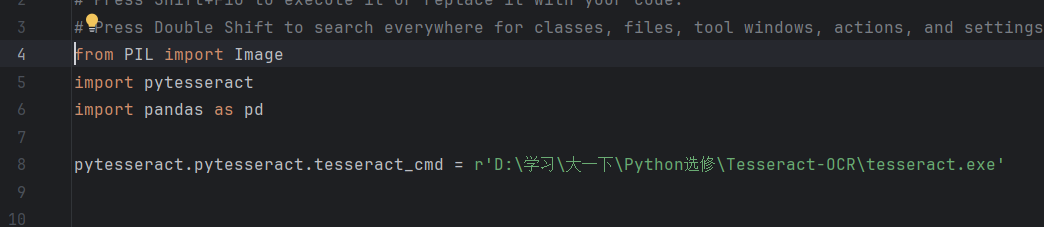
3.加载图片并进行OCR识别
使用PIL或Pillow库加载图片,然后使用pytesseract进行文字识别。
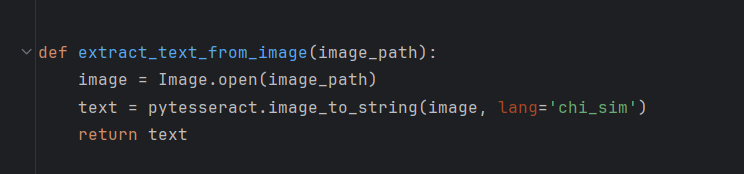
4.数据清洗与整理
提取出的文本可能包含不需要的信息,如换行符、空格等。你可能需要对其进行清洗和格式化,以便将其转换为结构化的数据。

5.将数据填入Excel
使用pandas库创建一个DataFrame,然后将清洗后的数据填入DataFrame,并保存到Excel文件中。
6.创建主文件
通过main()函数的使用,使得程序逻辑通畅。
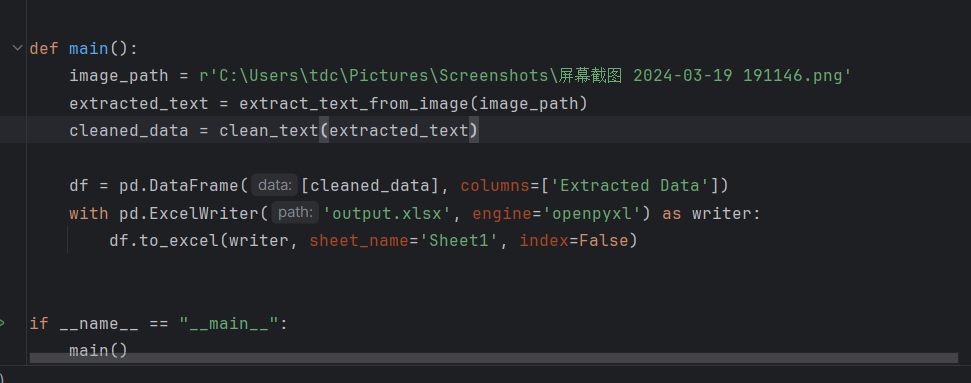
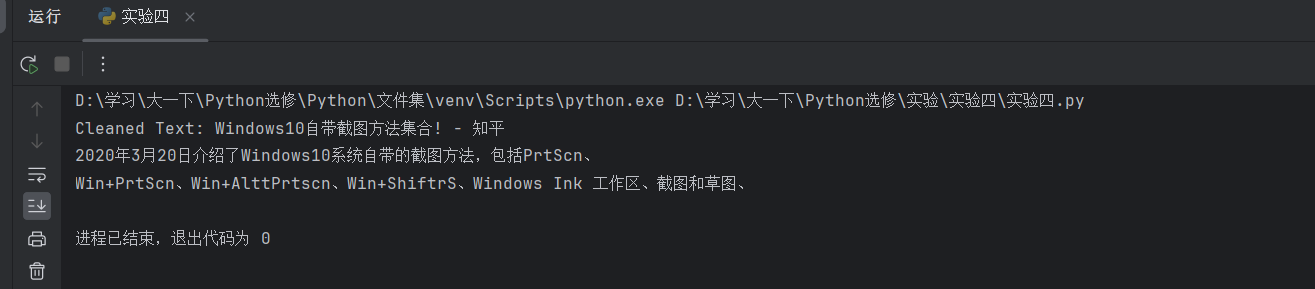
7.运行与结果
被截取图片:

结果:
##3.问题
1.对于该技术不了解
通过上网查阅资料与案例加深理解。
2.报错:‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated \UXXXXXXXX escape
查阅资料,发现在文件夹中复制地址时,文件夹中的地址是用 \ 来分隔不同的文件夹,而Python识别地址时只能识别用 / 分隔的地址。通过在字符串前加上r或R解决。
具体解决方法为:image_path = r'C:\Users\tdc\Pictures\Screenshots\屏幕截图 2024-03-19 191146.png'
3.代码运行后,控制台未显示提取的文本
未添加打印输出的语句print()。
具体解决方法为:print("Cleaned Text:", cleaned_text)
4.运行后未截取中文
Tesseract-OCR 安装时,未加载识别中文所需的语言数据。经过重新安装后仍未解决。通过AI工具查找问题,发现未指定中文。
具体解决方法为:text = pytesseract.image_to_string(img, lang='chi_sim')
## 源代码
from PIL import Image
import pytesseract
import pandas as pd
pytesseract.pytesseract.tesseract_cmd = r'D:\学习\大一下\Python选修\Tesseract-OCR\tesseract.exe'
def extract_text_from_image(image_path):
image = Image.open(image_path)
text = pytesseract.image_to_string(image, lang='chi_sim')
return text
def clean_text(text):
cleaned_text = text.replace(r'\n', ' ').strip()
print("Cleaned Text:", cleaned_text)
return cleaned_text
def main():
image_path = r'C:\Users\tdc\Pictures\Screenshots\屏幕截图 2024-03-19 191146.png'
extracted_text = extract_text_from_image(image_path)
cleaned_data = clean_text(extracted_text)
df = pd.DataFrame([cleaned_data], columns=['Extracted Data'])
with pd.ExcelWriter('output.xlsx', engine='openpyxl') as writer:
df.to_excel(writer, sheet_name='Sheet1', index=False)
if __name__ == "__main__":
main()
## 4.资料(部分)
(1)CSDN:Python报错:‘unicodeescape‘ codec can‘t decode bytes in position 2-3: truncated \UXXXXXXXX escape 链接:Python报错:‘unicodeescape‘ codec can‘t decode bytes in position 2-3: truncated \UXXXXXXXX escape-CSDN博客
(2)CSDN:Tesseract-OCR下载和安装,Python-OCR使用 链接:Tesseract-OCR下载和安装,Python-OCR使用_tesseract-ocr python 下载-CSDN博客
(3)天工AI:问题3、4的完全解决。
## 5.实验感想
这次实验相较于前三次实验,难度提升了不止一个档次,在做这次实验时,我时常需要查阅资料,但当我将其一点点的搭建起来时,一种成就感油然而生。事实上,本次实验既是对我们本学期所学的综合性检测,也是让我们实践自身所学与能力的平台。就我而言,这次实验加深了我对于Python的实用性的认识,也体会到以Python为代表的编程是如何改变我们的学习与生活。
## 6.结课感想
不知不觉,一个学期临近尾声,我依稀还记得,在选修Python时那种好奇与期待,但经过12周的学习后,我发现Python的学习并不如我所料想得一帆风顺,而是有重重风浪阻碍着我的前进。但所幸,Python的学习是一个渐进的过程,在期间,有数个“岛屿”可供我们暂时停靠修整,以便更好在学海中遨游。而更为幸运的是,有王志强老师这样优秀且具备耐心的好老师在托举着挣扎于学海的我们,无论我们有什么样的学习问题,都可以向他求助,并且能得到详尽而又生动的回答。或许在未来的某一天,我们已经忘记Python课上的具体内容,但对于Python的那份探求之情铭记于心。
至于建议,我希望能够自编新教材,统一购买的教材使用率还是太低了。同时,可以增加课堂上的互动频率,避免部分学生未能跟上进度。
