


93
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享课程:《Python程序设计》
班级: 2242
姓名: 周昭一
学号:20224205
实验教师:王志强
实验日期:2024年5月14日
必修/选修: 专选课
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
课代表和各小组负责人收集作业(源代码、视频、综合实践报告)
例如:编写从社交网络爬取数据,实现可视化舆情监控或者情感分析。
例如:利用公开数据集,开展图像分类、恶意软件检测等
例如:利用Python库,基于OCR技术实现自动化提取图片中数据,并填入excel中。
例如:爬取天气数据,实现自动化微信提醒
例如:利用爬虫,实现自动化下载网站视频、文件等。
例如:编写小游戏:坦克大战、贪吃蛇、扫雷等等
注:在Windows/Linux系统上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
编写爬虫,爬取微博评论,实现舆情可视化
1)选择一个希望爬取的微博页面,打开评论区。

2)鼠标单击右键,在弹窗中点击“检查”,打开检查窗口,在第一横栏中点击“网络”。开始录制屏幕中显示的评论,在“网络”窗格下方的“名称”栏会显示出已录制的评论名称,点击一项名称,在“标头”(headline)栏下找到“请求URL” "user-agent" "cookie" "accept" "accept-encoding" "accept-language" "referer"等信息。
分别粘贴在代码里面,组成请求头。如图所示。



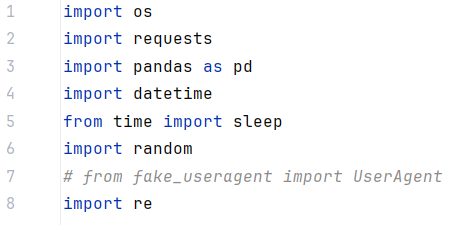
3)导入部分所需的Python库,包括os, requests, pandas, datetime, time, random, 这些库分别用于文件操作、网络请求、数据分析、时间处理、延时以及模拟浏览器请求头。
4)使用requests.get()发送访问请求,解析返回的json数据,提取评论信息,并处理异常情况。

5)对每个微博ID,初始化max_id为'0',循环爬取指定页数的评论数据;同时,根据当前页数和max_id构建请求URL,设置请求头,模拟浏览器访问。
注意:每次请求前后加入随机延时,避免因频繁请求被服务器封禁。

6)使用“def”定义辅助函数。
trans_time()函数:用于将微博返回的时间戳(GMT格式)转换为标准日期时间格式。
tran_gender()函数:根据性别标签('m'或'f')转换为中文表示。

7)使用正则表达式清洗评论文本,整合所有评论数据到DataFrame,然后写入CSV文件,注意处理文件是否存在的情况以决定是否写入表头,以实现数据清洗与存储。

8)最后的if name == 'main':块确保当主函数直接运行时,执行指定微博ID的评论爬取,输入我需要爬取的微博ID,然后调用get_comments()函数。
注意:微博ID需要在微博手机端上查看。方法:打开该微博窗口,在右上角三个点”更多选项“处点击,选择下方”复制链接“,即可复制到本条微博链接,,链接最后的一段5035843484127782就是我需要的微博ID,如我需要的微博链接为https://weibo.com/2803301701/5035843484127782%E3%80%82

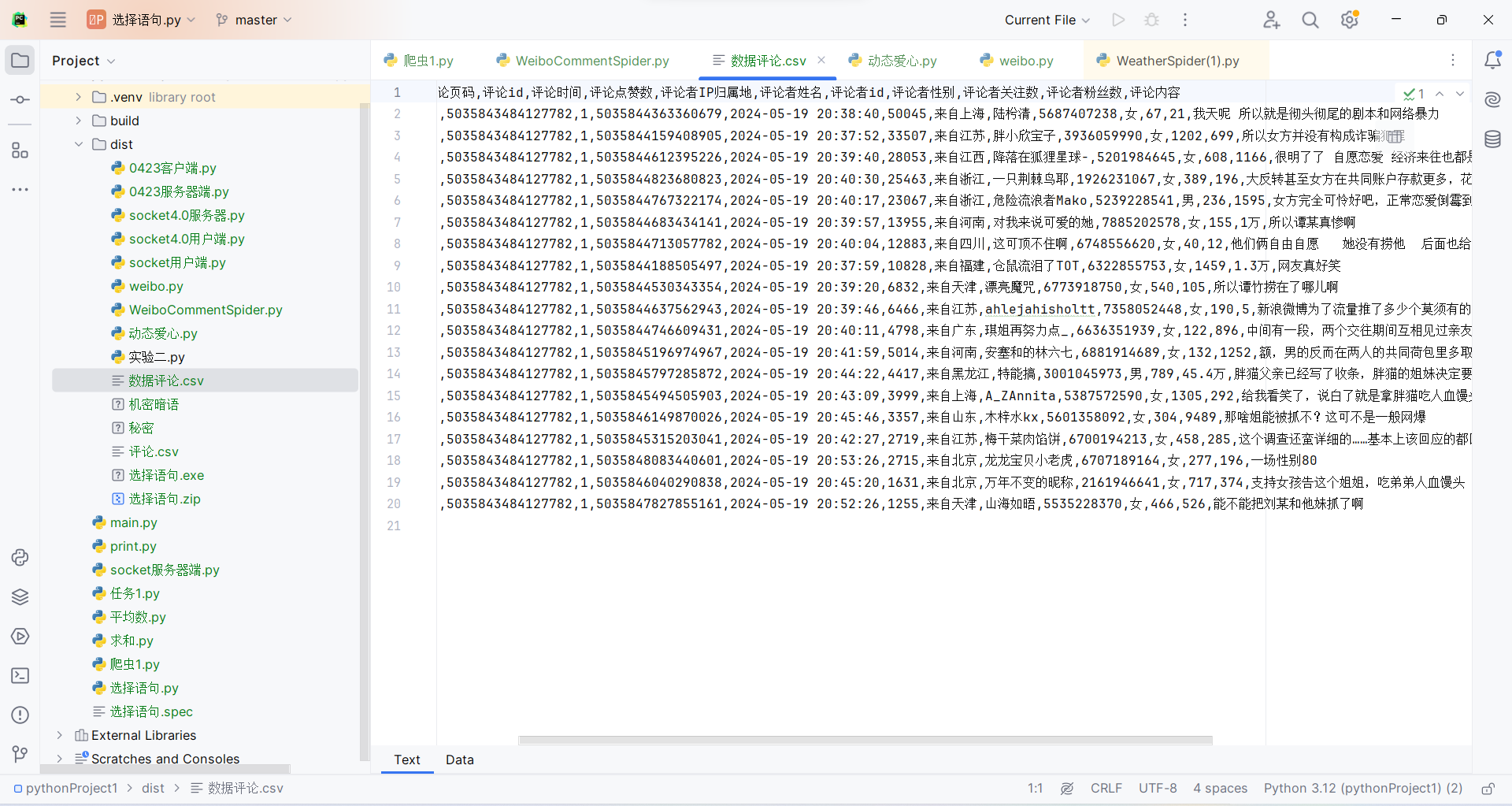
9)运行该代码。运行成功,可以成功访问该URL并生成.csv文件,打开文件,包括评论内容,评论人的ID,评论时间,IP归属地等等。同时,在根目录文件夹中可以找到评论数据的生成文件,用WPS打开即为表格,实现数据可视化。

以下是代码运行视频。
以下是源代码。
import os
import requests
import pandas as pd
import datetime
from time import sleep
import random
# from fake_useragent import UserAgent
import re
def trans_time(v_str):
"""转换GMT时间为标准格式"""
GMT_FORMAT = '%a %b %d %H:%M:%S +0800 %Y'
timeArray = datetime.datetime.strptime(v_str, GMT_FORMAT)
ret_time = timeArray.strftime("%Y-%m-%d %H:%M:%S")
return ret_time
def tran_gender(gender_tag):
"""转换性别"""
if gender_tag == 'm':
return '男'
elif gender_tag == 'f':
return '女'
else: # -1
return '未知'
def get_comments(v_weibo_ids, v_comment_file, v_max_page):
"""
爬取微博评论
:param v_weibo_id: 微博id组成的列表
:param v_comment_file: 保存文件名
:param v_max_page: 最大页数
:return: None
"""
for weibo_id in v_weibo_ids:
# 初始化max_id
max_id = '0'
# 爬取前n页,可任意修改
for page in range(1, v_max_page + 1):
wait_seconds = random.uniform(0, 1) # 等待时长秒
print('开始等待{}秒'.format(wait_seconds))
sleep(wait_seconds) # 随机等待
print('开始爬取第{}页'.format(page))
if page == 1: # 第一页,没有max_id参数
url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id_type=0'.format(weibo_id, weibo_id)
else: # 非第一页,需要max_id参数
if str(max_id) == '0': # 如果发现max_id为0,说明没有下一页了,break结束循环
print('max_id is 0, break now')
break
url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id_type=0&max_id={}'.format(weibo_id,
weibo_id,
max_id)
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
"cookie": "__bid_n=1855e52f83c12780664207; FEID=v10-766d48bf476a5b99a31684e6d4b74c98b4d133a2; __xaf_fpstarttimer__=1672634141361; __xaf_thstime__=1672634141910; __xaf_fptokentimer__=1672634142056; _T_WM=91010151027; SCF=AhqqhuU0eySfXjT2vmQ5faXpqgHtzG0tpXf6Jh1xOrIiSqjsMXmKh4wsNBFg5ejqRMTI93-xSbS-Uduk_s4NRK8.; SUB=_2A25O5c7uDeRhGedI4lIU8C3PwzyIHXVqKdKmrDV6PUJbktAKLUz1kW1NVoZ-2WIGRSgsp51DeFB9dxRhRboM7px_; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WhWcVXRXvfX3iep9.M98zpA5JpX5K-hUgL.Fo2c1K5fehe01h52dJLoIE2LxK.LBK.LB-eLxK-L1KeLBKH7wPxQdcRLxKnLB-qLBoBt; ALF=1678330814; FPTOKEN=p16283+PpnoduGibvvEpa7Jm1K1HU2NhkUXcqTuOwltTEKQJhsj3jOo/s/CWN8838ew7/ie6v2DLIYzTNLo40f3l05g4fFF+kjYdomw3o20ziaJMA4VJXMtzUBj6vAo3zxEa+LfqjEUYQuqn3G1gHwOdB2At9OvAubnkHHfZSzJJo0v+TLKcmjTLExJW/OjHZyhR9bRoWqV/1ENZHuxKvsn7tn+pgwC2n28Q/ez8zMNkj6X0huMuaBeNA8HoQ8FuWjoyrXps7wwbRbBv8z4mumRRoqiXEOSOsASflCjKw6gkfJJ5oHmoh1hx43ugVTZqxpYLivp8aCToqFu/clIex5bB2b0WQdp59i9E1KqEiwRN6jxPjhl7EKQlruQclvFYRExGOw5KMKGZy/0CNraMcw==|PfOWxrz13V2fvzp/rEoL/lSANYW4voaw2PHjpWZ/njY=|10|b67122b33a5e1ebb87032fafdc0126ba; XSRF-TOKEN=eceae9; WEIBOCN_FROM=1110006030; mweibo_short_token=87f071037d; MLOGIN=1; M_WEIBOCN_PARAMS=oid=4865363672566456&luicode=10000011&lfid=102803&uicode=20000061&fid=4865363672566456",
"accept": "application/json, text/plain, */*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7",
"referer": "https://m.weibo.cn/detail/{}".format(weibo_id),
"x-requested-with": "XMLHttpRequest",
"mweibo-pwa": '1',
}
r = requests.get(url, headers=headers) # 发送请求
print(r.status_code) # 查看响应码
# print(r.json()) # 查看响应内容
try:
max_id = r.json()['data']['max_id'] # 获取max_id给下页请求用
datas = r.json()['data']['data']
except Exception as e:
print('excepted: ' + str(e))
continue
page_list = [] # 评论页码
id_list = [] # 评论id
text_list = [] # 评论内容
time_list = [] # 评论时间
like_count_list = [] # 评论点赞数
source_list = [] # 评论者IP归属地
user_name_list = [] # 评论者姓名
user_id_list = [] # 评论者id
user_gender_list = [] # 评论者性别
follow_count_list = [] # 评论者关注数
followers_count_list = [] # 评论者粉丝数
for data in datas:
page_list.append(page)
id_list.append(data['id'])
dr = re.compile(r'<[^>]+>', re.S) # 用正则表达式清洗评论数据
text2 = dr.sub('', data['text'])
text_list.append(text2) # 评论内容
time_list.append(trans_time(v_str=data['created_at'])) # 评论时间
like_count_list.append(data['like_count']) # 评论点赞数
source_list.append(data['source']) # 评论者IP归属地
user_name_list.append(data['user']['screen_name']) # 评论者姓名
user_id_list.append(data['user']['id']) # 评论者id
user_gender_list.append(tran_gender(data['user']['gender'])) # 评论者性别
follow_count_list.append(data['user']['follow_count']) # 评论者关注数
followers_count_list.append(data['user']['followers_count']) # 评论者粉丝数
df = pd.DataFrame(
{
'max_id': max_id,
'微博id': [weibo_id] * len(time_list),
'评论页码': page_list,
'评论id': id_list,
'评论时间': time_list,
'评论点赞数': like_count_list,
'评论者IP归属地': source_list,
'评论者姓名': user_name_list,
'评论者id': user_id_list,
'评论者性别': user_gender_list,
'评论者关注数': follow_count_list,
'评论者粉丝数': followers_count_list,
'评论内容': text_list,
}
)
if os.path.exists(v_comment_file): # 如果文件存在,不再设置表头
header = False
else: # 否则,设置csv文件表头
header = True
# 保存csv文件
df.to_csv(v_comment_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
print('结果保存成功:{}'.format(v_comment_file))
if __name__ == '__main__':
weibo_id_list = ['5035843484127782', ] # 指定爬取微博id,可填写多个id
max_page = 1 # 爬取最大页数
comment_file = '数据评论.csv'
# 如果结果文件存在,先删除
if os.path.exists(comment_file):
os.remove(comment_file)
# 爬取评论
get_comments(v_weibo_ids=weibo_id_list, v_comment_file=comment_file, v_max_page=max_page)
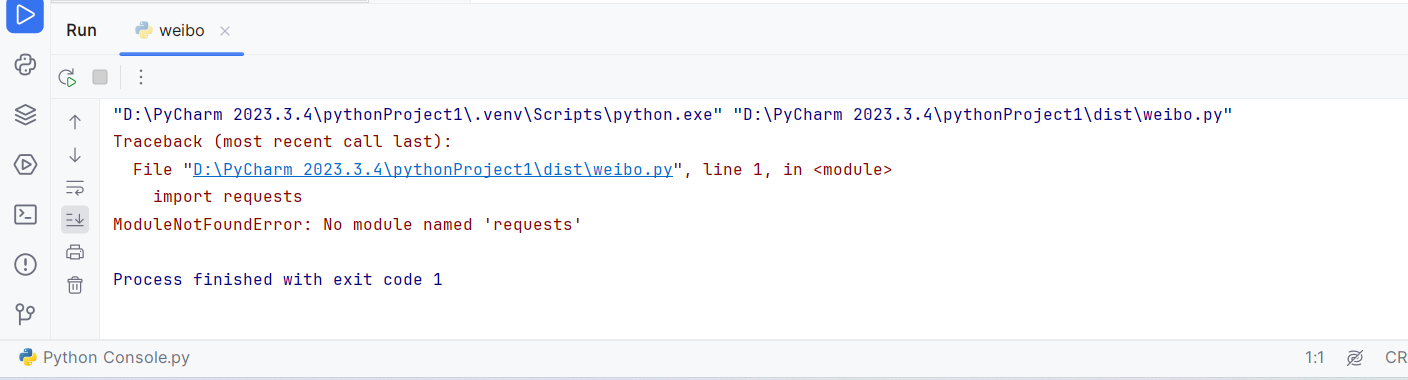




在编写爬虫程序的过程中,由于一开始没有太跟上老师的上课节奏,导致我后续自己实践的时候难度非常大。我自行在B站上查找了多个教学视频,结合CSDN上的一些经验分享,进行实际操作,还是阻碍重重,遇到了诸多问题,这让我一开始有点灰心。但是在找对思路后,加上同学的帮助,我获益良多,最后编写的代码运行成功。当表格文件以不到两秒的时间在我的文件夹里生成出来的时候,我激动地点开表格,看到评论内容,评论人的ID,评论时间,IP归属地等信息明明白白地在我眼前如群蚁排衙,我突然觉得信息空间所能施展拳脚的空间着实广阔,这也坚定了吾将上下而求索的决心。
学习一项全新的技能,就像是在一个陌生的世界里探索的过程。我是第一次接触Python的小白,对这个陌生的世界充满了好奇与想象。事实上,在本次Python选修课中,不论是制作简易计算器,还是学习编写Socket,抑或是爬虫的应用,对于第一次接触这个领域的我来说都需要一次又一次的尝试,需要不断地试错,修正,再试错,再修正。
在制作简易计算器的过程中,我感受到原来使用计算机语言编写代码并进行应用就像是我坐在电脑前,与电脑对话。我想通过python写出什么样的代码,实现什么样的功能,都必须用计算机能听懂的语句来输入。这帮助我更深入地去理解计算机在进行运算时的底层逻辑,原来我们日常生活中使用的非常简单的计算器操作在计算机语言中也并非如此容易。同时,在查阅资料的过程中,我还发现了制作更精良、外形更美观的使用Python编写计算器程序的教程,日后我也打算尝试深入学习,让这个简易的计算器骨骼变得有血有肉、栩栩如生。
在编写Socket的过程中,我体验到了用代码转变为讯息传递工具的奇妙,也了解到原来通信是需要服务器端和客户端两方之间传递的。那么我不禁思考,我们平常使用的微信、QQ等实时通讯工具是不是也需要两个客户分别把自己索要传达的信息上传到服务器端,然后才能从服务器端发出呢?诸如此类的联想帮助我打开了信息世界的窗口。
在编写爬虫程序的过程中,由于一开始没有太跟上老师的上课节奏,导致我后续自己实践的时候难度非常大。我自行在B站上查找了多个教学视频,结合CSDN上的一些经验分享,进行实际操作,还是阻碍重重,遇到了诸多问题,这让我一开始有点灰心。但是在找对思路后,加上同学的帮助,我获益良多,最后编写的代码运行成功。
最后实验成功时的喜悦远远超越了过程中举步维艰的困难,这门课程让我深入了解了 Python 简洁而强大的语法。从基础的数据类型到复杂的控制结构,每一个知识点都构建起了我编程能力的基石。通过实际的代码编写和项目实践,我逐渐掌握了如何运用 Python 解决各种问题。课程中的实践项目让我将所学知识应用到实际场景中,锻炼了我的问题解决能力和逻辑思维。
这门 Python 课程在帮助我掌握了一门实用的编程语言的同时,更培养了我的编程思维和解决问题的能力。我相信这些技能将在未来的学习和工作中发挥重要作用,我也期待着能运用 Python 创造更多有价值的成果。人生苦短,我爱Python!
