


110
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享课程:《Python程序设计》
班级: 2324
姓名: 许鹏坤
学号:20232401
实验教师:王志强
实验日期:2024年5月15日
必修/选修: 公选课
Python综合实践
使用爬虫爬取每日资讯,并实现自动化微信发送资讯
此次实验主要完成以下两个功能:
为了便于获取需要的资讯信息,过滤掉其他无关信息,本实验选取了Scrapy框架,通过框架的整体结构和内嵌的XPath筛查定位功能来对网页信息进行定位获取。

为了实现Python与微信界面的交互,并且避免被微信认定为机器人进而导致被封号的惨烈结局,本实验使用了Python包pyautogui来模拟人为光标操作,借助微信截屏坐标显示功能,获取微信完全展开时预选位置的坐标,并设定每步操作的等待时间为0.5s,进行响应时间较长的操作后程序将会休眠2s来等待响应。
本实验还使用了Python包pyperclip来解决pyautogui中无法输入中文的问题。pyperclip可以模仿键盘操作,将字符串直接输入剪贴板,再模拟粘贴操作,即可完成中文的输入
为解决两个模块的信息传递问题,本实验将两个功能分别放在最底层目录的两个.py中,在爬虫文件中先将爬虫爬取的信息由列表转化为字符串,通过utf-8编码写入文件,再在微信发送文件中读取文件信息并解码,转化为字符串后被递送至剪贴板
在本实验进行之前应当首先初步学习Scrapy框架。
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。
Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
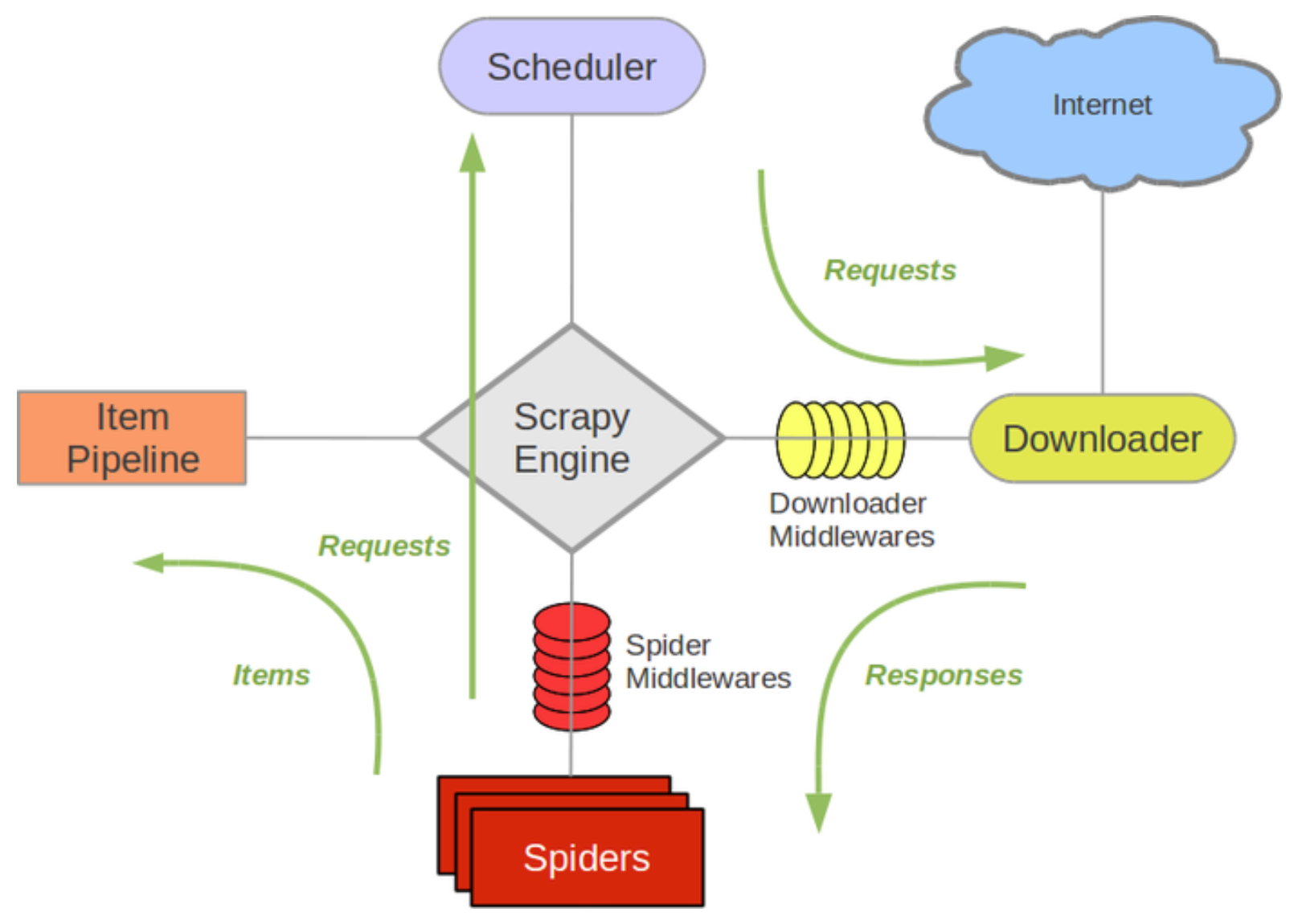
Scrapy的基本工作原理如下图所示
如果要使用Scrapy需要进行安装、项目建立、爬虫生成:
pip install scrapy
scrapy startproject mySpider
scrapy genspider cctv "cctv.cn"
setting.py:
# Scrapy settings for DailyNews project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = "DailyNews"
SPIDER_MODULES = ["DailyNews.spiders"]
NEWSPIDER_MODULE = "DailyNews.spiders"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537",
'Accept': "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
'Accept-Language': "en",
}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# "DailyNews.middlewares.DailynewsSpiderMiddleware": 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# "DailyNews.middlewares.DailynewsDownloaderMiddleware": 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
"DailyNews.pipelines.DailynewsPipeline": 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = "httpcache"
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"
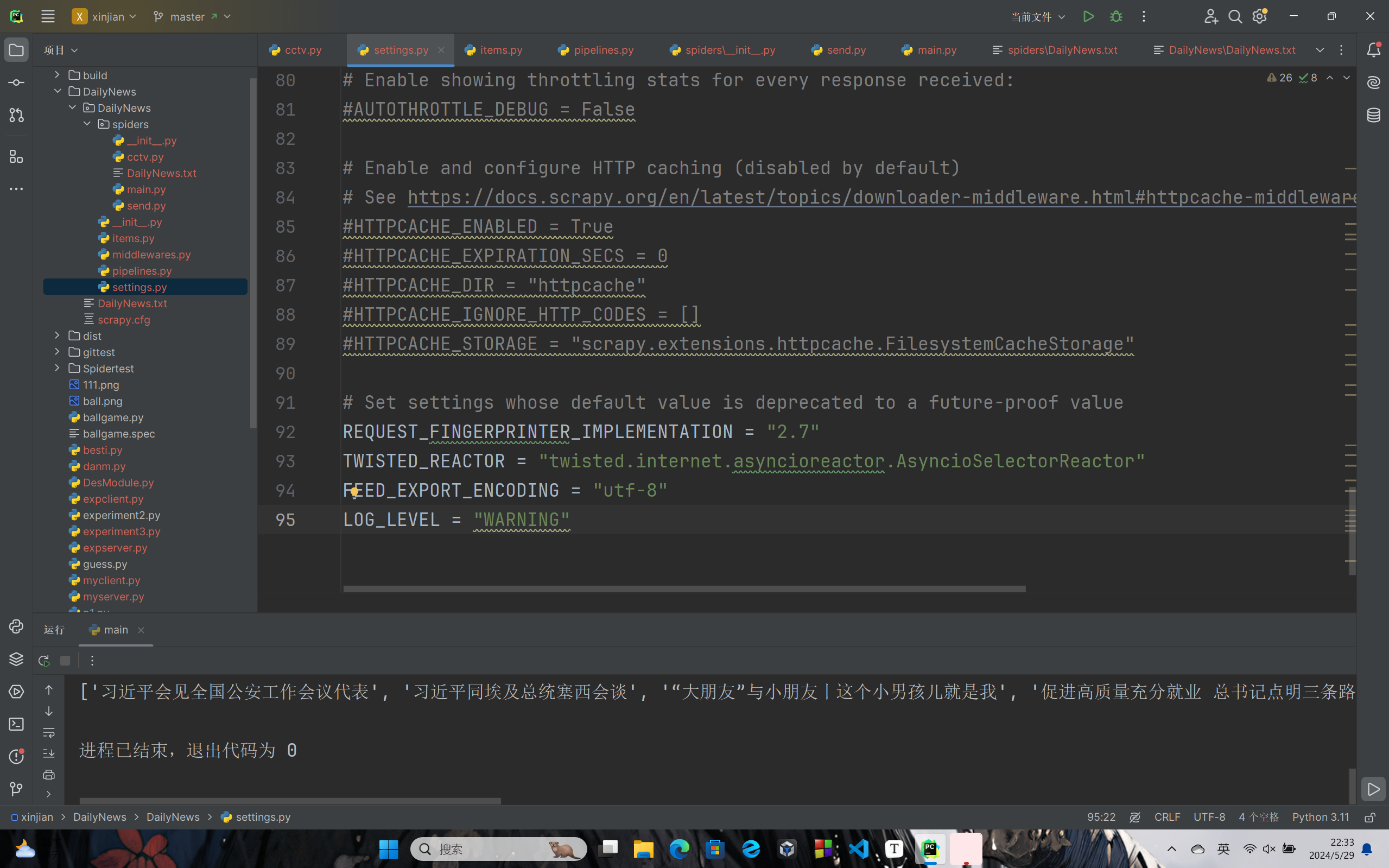
# Set settings whose default value is deprecated to a future-proof value
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
LOG_LEVEL = "WARNING"
通过以上设置,可以伪装访问请求头,解决网站拒绝访问的问题,还可以避免打印出日志信息
items.py:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class DailynewsItem(scrapy.Item):
# define the fields for your item here like:
content = scrapy.Field()
通过以上设置,可以创建出包含所需信息的Item对象
pipelines.py:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import csv
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class DailynewsPipeline:
# def __init__(self):
# self.f=open('DailyNews.txt','w',encoding="utf-8",newline='')
# self.file_name=['content']
# self.writer=csv.DictWriter(self.f,fieldnames=self.file_name)
# self.writer.writeheader()
def process_item(self, item, spider):
# self.writer.writerow(dic(item))
print(item)
return item
# def close_spider(self,spider):
# self.f.close()
piplines中预编写了将信息写入.csv文件中的代码,读者可以自取
爬虫文件cctv.py:
import scrapy
from DailyNews.items import DailynewsItem
class CctvSpider(scrapy.Spider):
name = "cctv"
allowed_domains = ["cctv.com"]
start_urls = ["https://www.cctv.com/"]
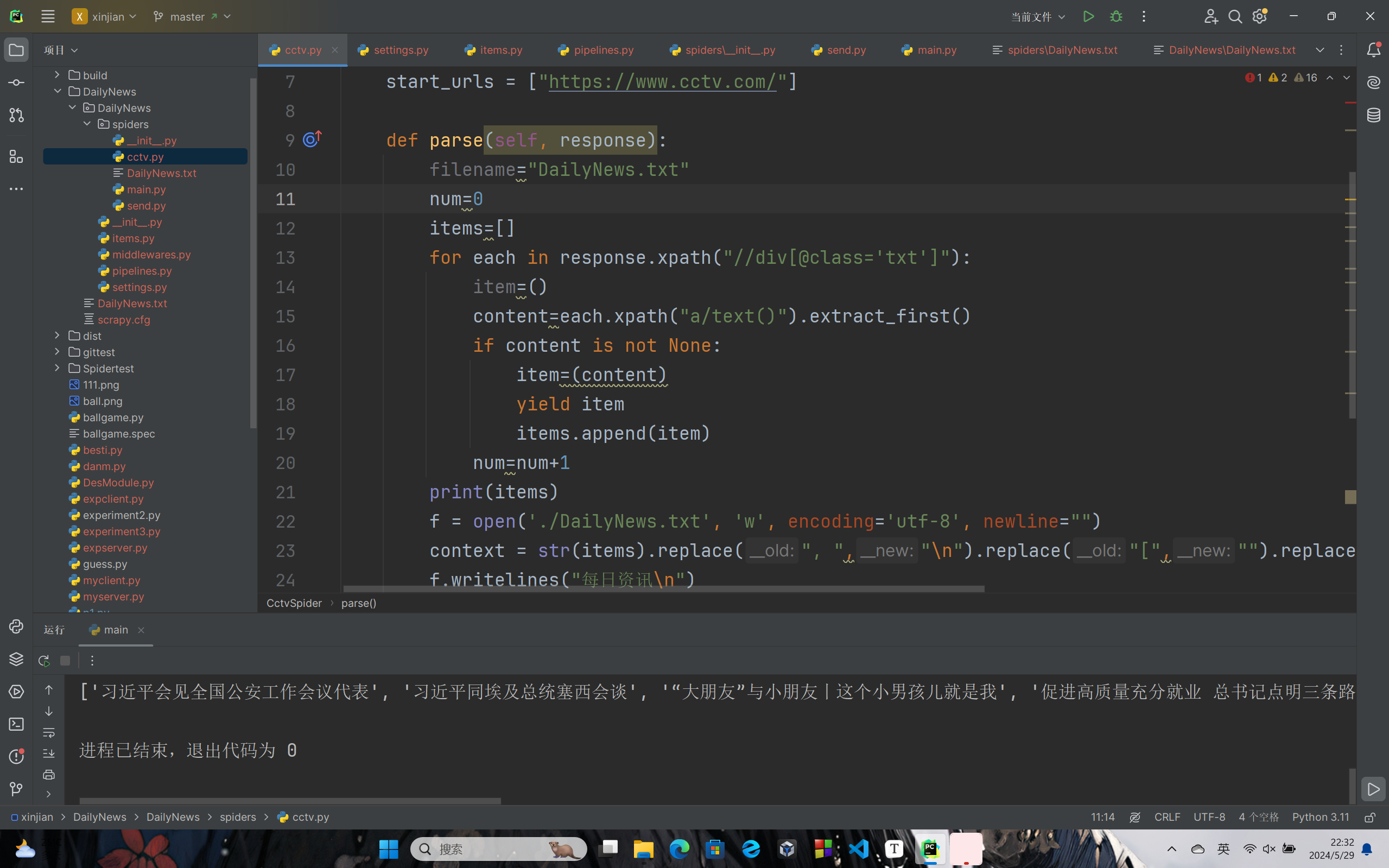
def parse(self, response):
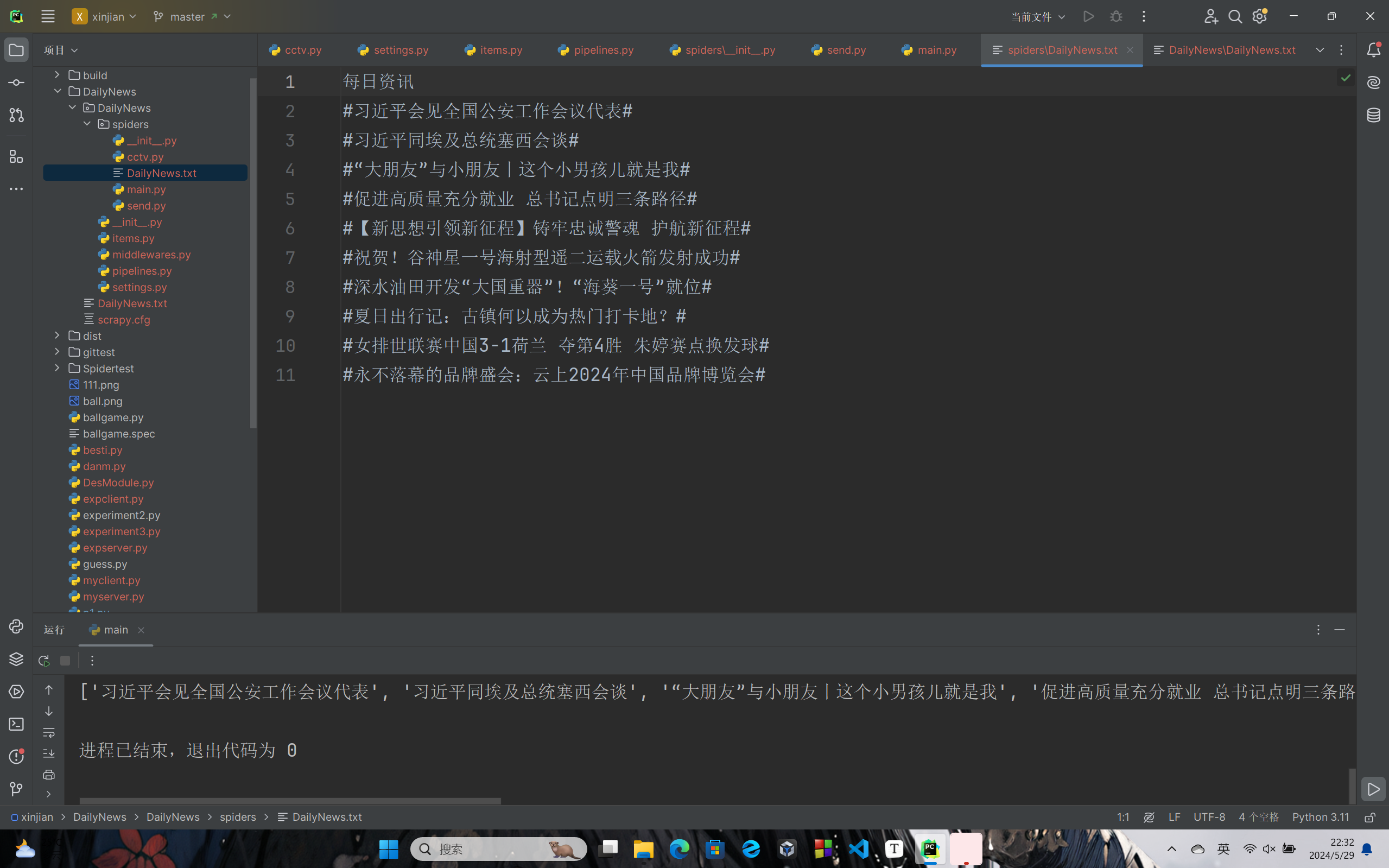
filename="DailyNews.txt"
num=0
items=[]
for each in response.xpath("//div[@class='txt']"):
item=()
content=each.xpath("a/text()").extract_first()
if content is not None:
item=(content)
yield item
items.append(item)
num=num+1
print(items)
f = open('./DailyNews.txt', 'w', encoding='utf-8', newline="")
context = str(items).replace(", ","\n").replace("[","").replace("]","").replace("'","#")
f.writelines("每日资讯\n")
f.writelines(context)
f.close()
return items
cctv.py文件既实现了信息的爬取,也将列表转化为字符串,去掉了无用信息,添加了标题,完成了分行,以utf-8编码的形式写入了文件。
微信发送文件send.py:
import pyautogui
import pyperclip
import os
import time
pyautogui.FAILSAFE=False
pyautogui.PAUSE=0.5
f=open("./DailyNews.txt","r",encoding="utf-8")
content=f.read()
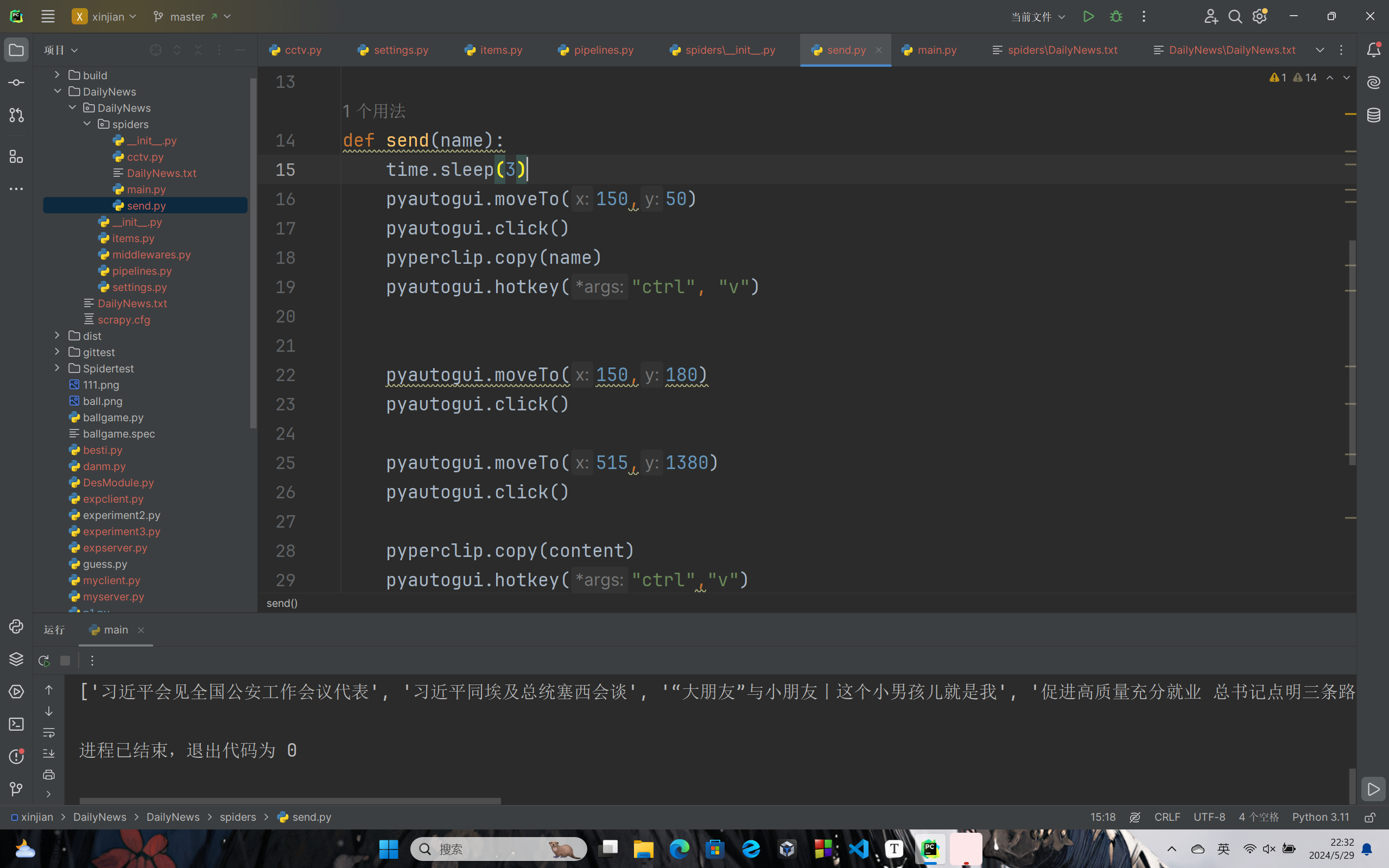
def send(name):
time.sleep(3)
pyautogui.moveTo(150,50)
pyautogui.click()
pyperclip.copy(name)
pyautogui.hotkey("ctrl", "v")
pyautogui.moveTo(150,180)
pyautogui.click()
pyautogui.moveTo(515,1380)
pyautogui.click()
pyperclip.copy(content)
pyautogui.hotkey("ctrl","v")
pyautogui.press("enter")
return None
send("/*联系人名称*/")
这里将发送功能做成了函数,方便选取多位联系人进行发送
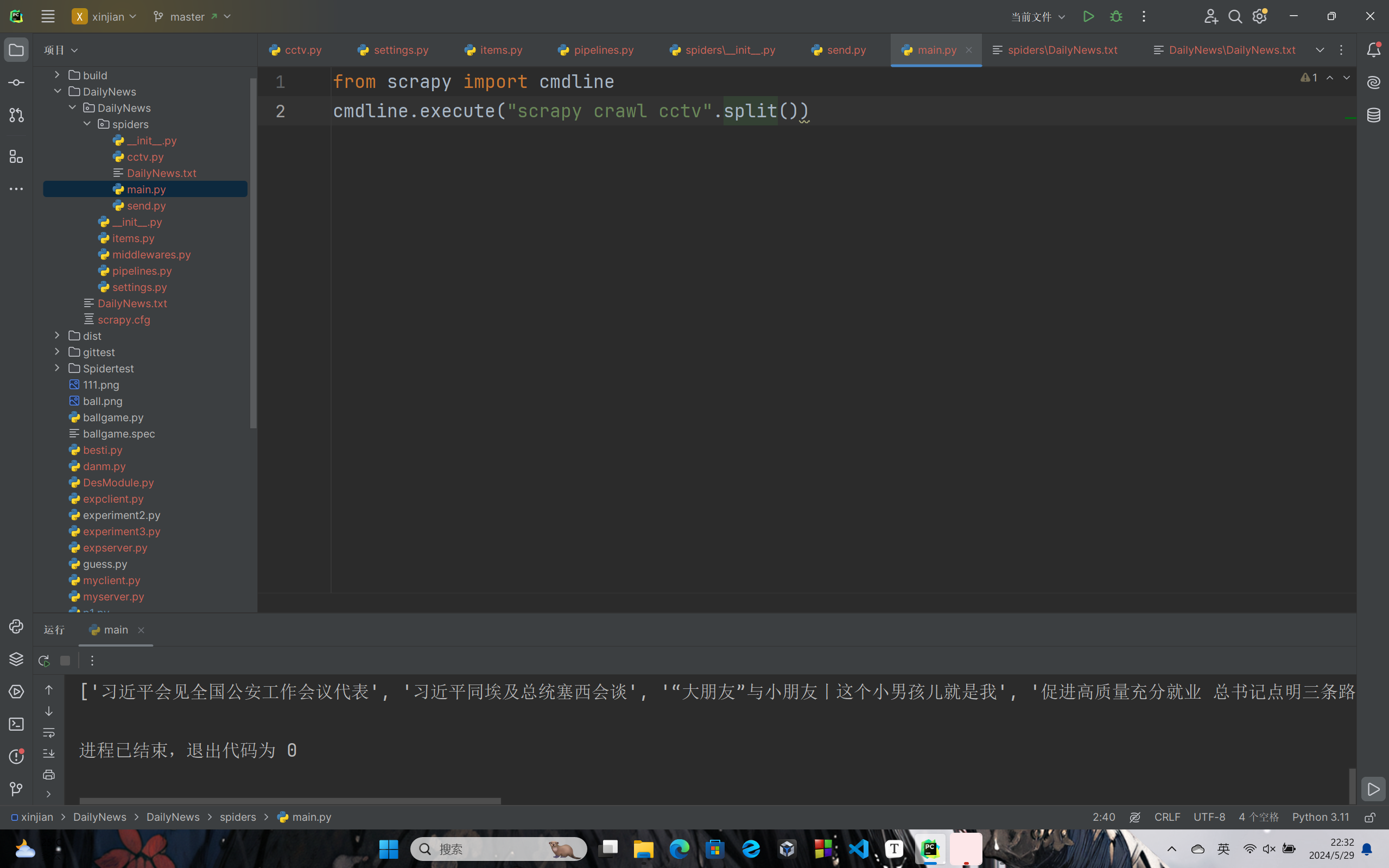
运行函数main.py:
from scrapy import cmdline
cmdline.execute("scrapy crawl cctv".split())
如果没有运行函数的话,需要再命令行中手动输入scrapy crawl cctv,根据实际经验总结,这行命令应该会执行cctv.py文件所在目录的所有文件
使用注意事项

utf-8编码的方式进行读写操作Python具有非常强大的库和开源的框架,但是在掌握了Python的基本语法之后有时并不能很好地利用这些库和框架,原因在于对函数的理解以及跨文件类的调用等不熟悉,以及不善于审阅代码和注释,不清楚其具体功能是什么,但是使用新库和新框架的探索过程还是非常有意思的,尤其当程序跑通之后会非常舒畅,同时感慨于某个库某个框架的强大。
善于学习和利用Python中的库和框架无疑会给程序设计和编写带来巨大的便宜和效率,今后要掌握对新库和新框架的学习方法。
Python是面向对象的语言,不同于C语言的面向过程,这给我们带来一种全新的思路,即分门别类的思想,这样的思维模式其实是更有助于我们将某项任务进行拆分,或者可以说模块化,一定程度上可以提高程序设计的效率,在改动时也能很大程度上避免牵连到其他代码,并且Python有不断更新的、强大的库作为支撑,无疑可以让老练的程序员如虎添翼。
在整个课程的教学上逻辑也十分清晰,令我印象最深的其实是关于Socket编程原理,通过一张图将整个逻辑顺序理清。老师教学方式也比较轻松幽默,为我们打开了Python世界的大门,希望老师可以延续教学质量和教学方法,不断引领更多同学踏上Python坦途。

