


110
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享课程:《Python程序设计》
班级: 202222
姓名: 刘璟瑜
学号:20222207
实验教师:王志强
实验日期:2024年5月20日
必修/选修: 公选课
(1)实验要求
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
本次我的实验内容是
(1)用爬虫爬取猫眼电影热映表,在txt文档中打印输出
(2)根据电影类型(如爱情、动作)等制作词云图,以此分析最近那种电影类型最热门
一、爬虫爬取猫眼电影
(1)获取网页地址,根据网页开发者模式中网页元素内容,设置请求头,来伪装成客户端向服务器请求数据
![]()
url = 'https://www.maoyan.com/board'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'
}
(2)发送请求,使用request模块进行数据请求
requ = requests.get(url=url, headers=headers).text # <Response [200]>数据请求成功
(3)数据解析
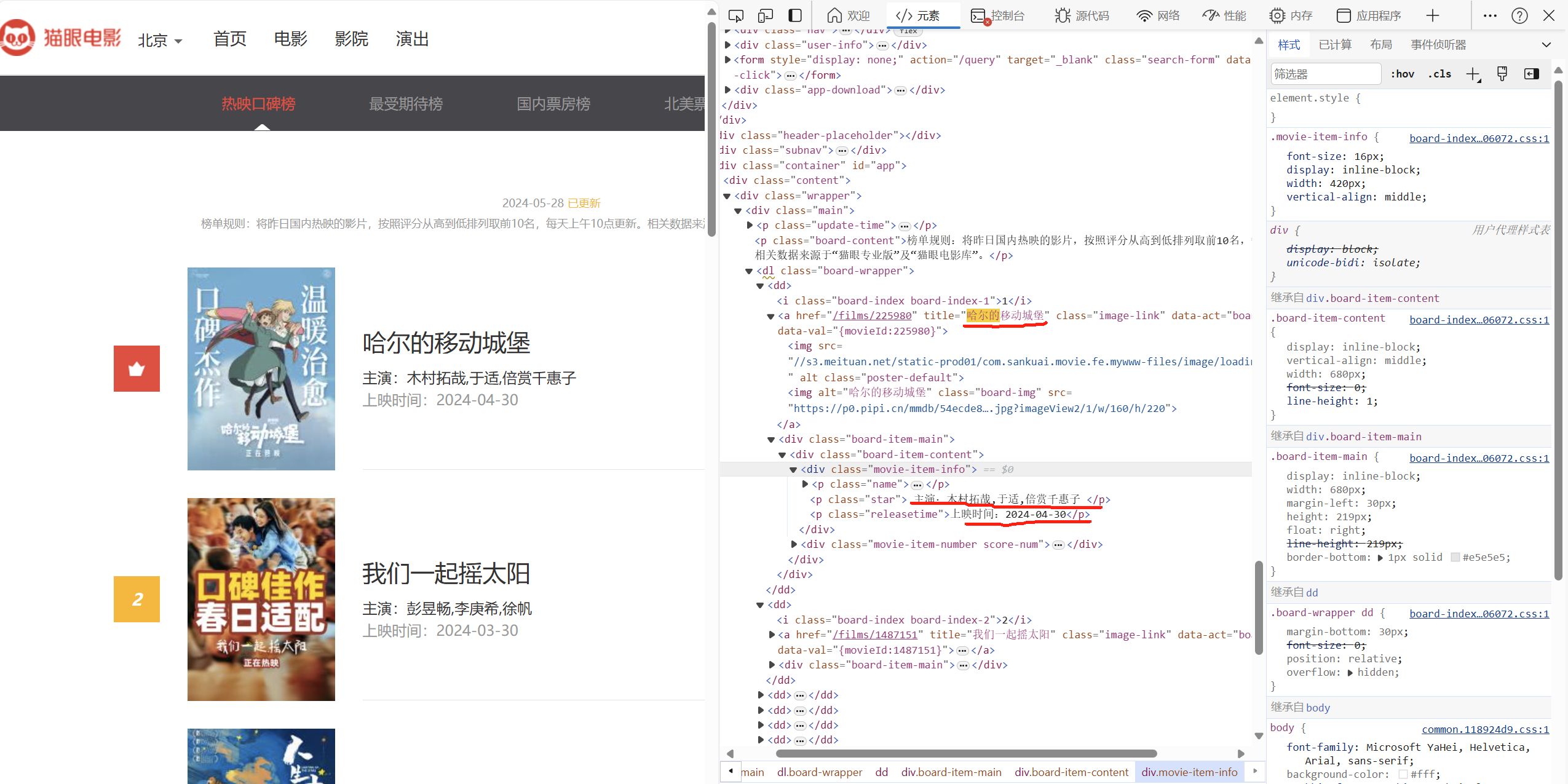
使用parsel模块可以解析我们获得的html代码,并通过xpath路径的设置获得我们需要的内容,在我的代码中,我爬取了每个电影的名字,主演,上映时间内容
sel = parsel.Selector(requ) # <Selector query=None data='<html lang="en"><head><meta charset="...'>
dd_list = sel.xpath('//body/div[4]/div/div/div/dl/dd')
# print(dd_list)
for dd in dd_list:
name = dd.xpath('.//div/div/div/p[1]/a/text()').get() # 电影名字
star = dd.xpath('.//div/div/div/p[2]/text()').get().strip() # 主演
time = dd.xpath('.//div/div/div/p[3]/text()').get().strip() # 上映时间
打印输出查看爬取是否正确:
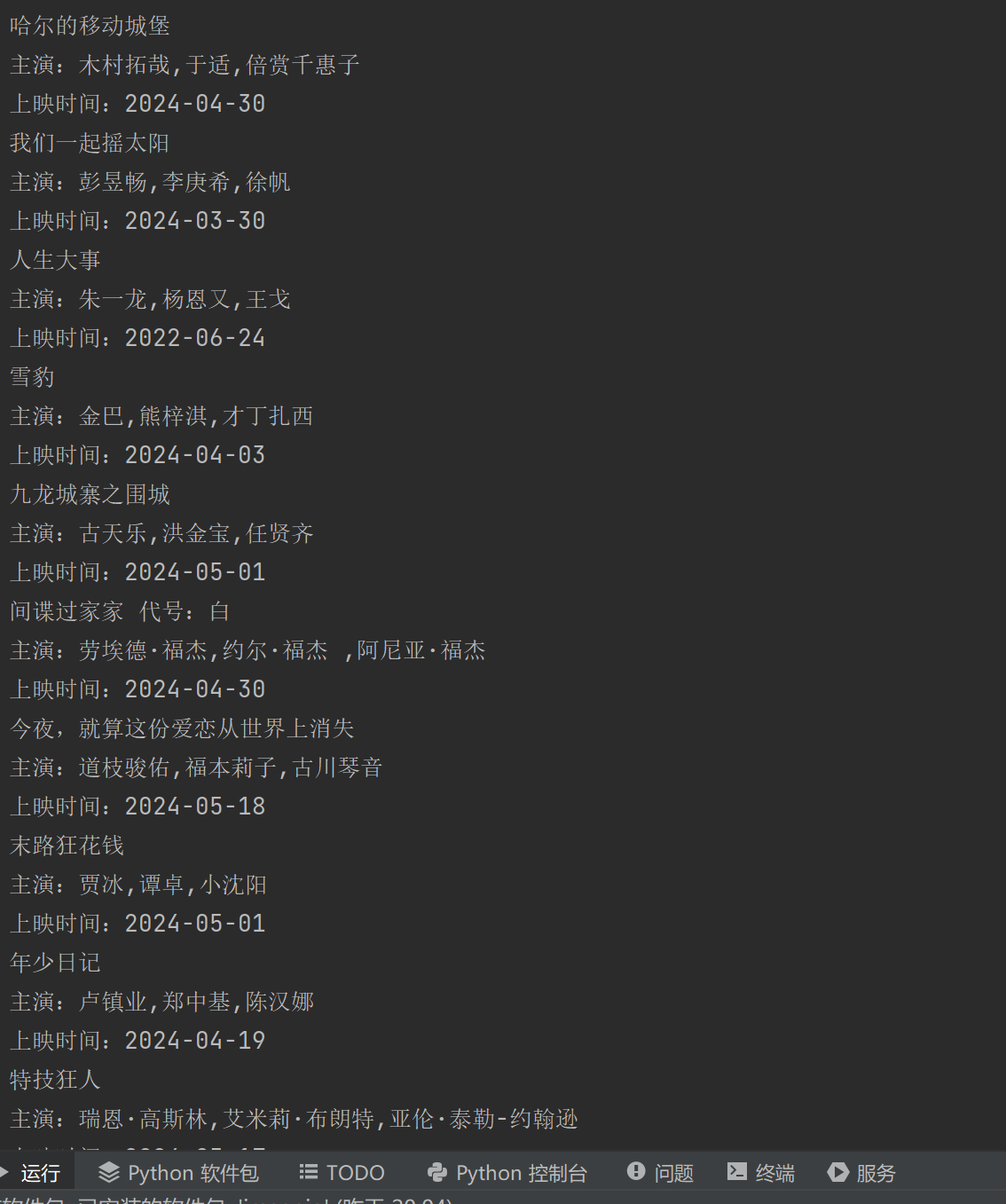
除此之外,我还爬取了每个榜单中电影的链接,原本是希望爬取每个电影详细的分类,来进行词云图的制作,但是猫眼在网页跳转之后似乎设置了反爬机制,我写的爬虫代码爬取的结果都是一个空的列表[],所以我只能更改实验计划,将实验内容改为爬取榜单上的电影内容并打印在txt文档中显示出来
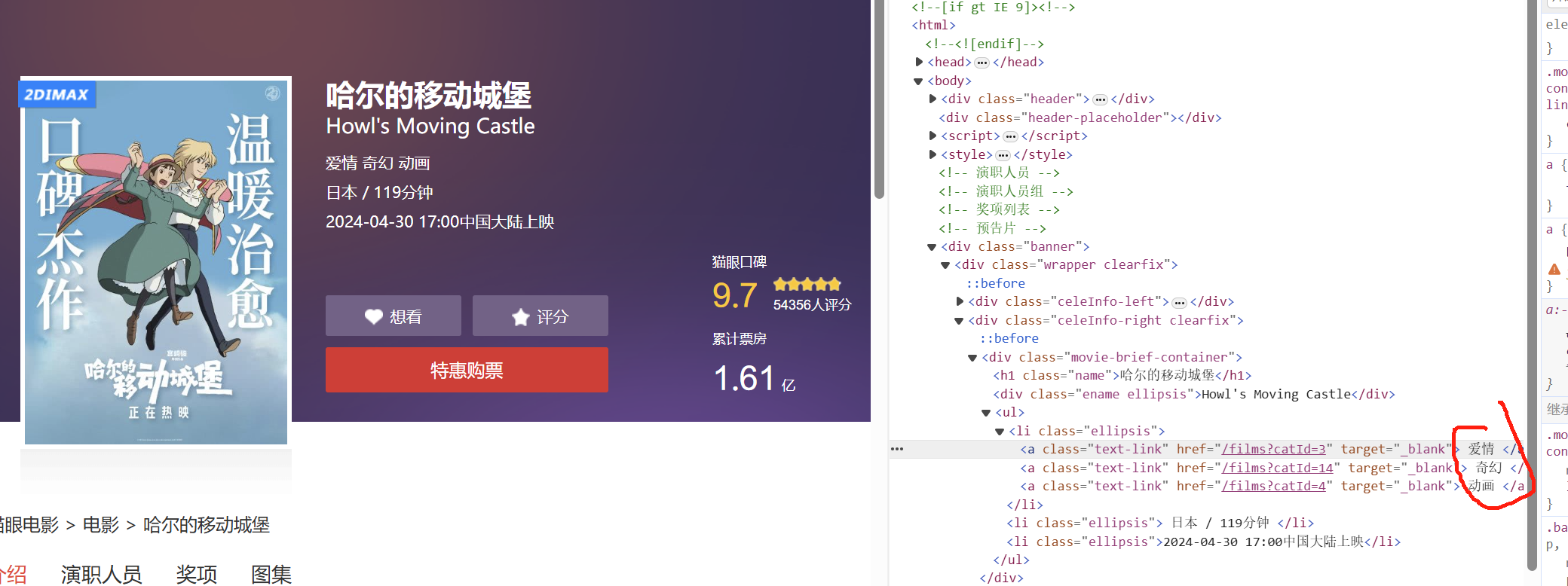
爬取的每个电影的链接,将其设置为新的url并发送请求,进行数据解析后发现解析的html文件并不是我想要的网页代码,怀疑网页使用了反爬技术,获得的html代码中并不包含我所要的内容,爬取该部分内容失败。
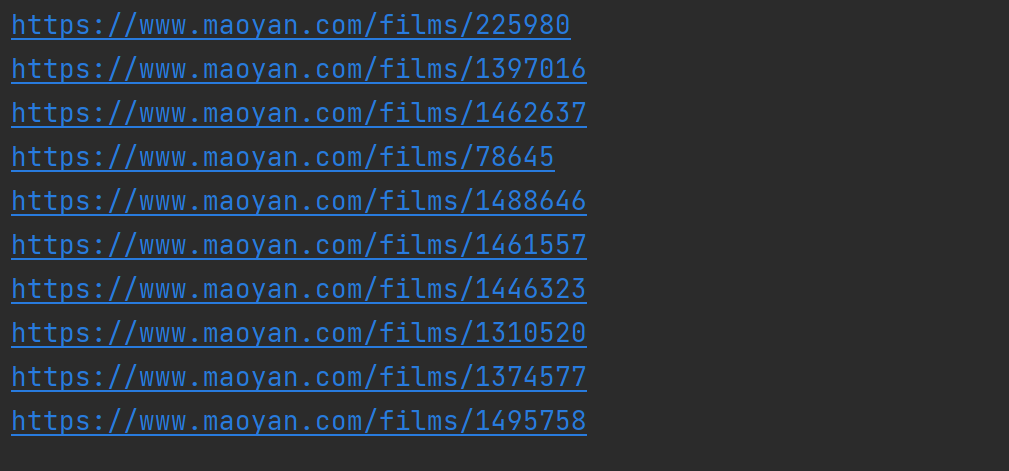
(4)将爬取的内容保存在榜单.txt文件内,查看文件内容,发现爬取成功
with open('榜单.txt', mode='a', encoding='utf-8') as fp:
fp.write(name + star + time+'\n')

二、制作词云图
由于无法爬取到电影的类型,所以我只能手敲一个包含全部电影类型的txt文件,
(1)读取文件内容

f = open('name.txt', mode='r', encoding='utf-8')
txt = f.read()
(2)使用jieba模块进行中文分词,并合并相关字符串
txt_list = jieba.lcut(txt)
txt_str = ' '.join(txt_list)
(3)读取图片,其中使用imageio模块解析图片内容,用来做词云图的背景,并设置词云图的格式

img = imageio.imread('111.JPG')
word = wordcloud.WordCloud(
width=1000,
height=800,
background_color='black',
font_path='msyh.ttc',
mask=img
)
(4)最后,根据分词后的内容填充词云图并将词云图以PNG的格式输出。
word.generate(txt_str)
word.to_file('1111.png')
print('保存成功')

1.爬取的数据中有空格部分:
解决方法:使用python自带的strip函数,可以去除爬取的字符串的前导和空白字符
2.爬取跳转链接的网页文件,发现爬取内容为空的列表,与实际内容并不相符
解决方法:怀疑网页使用了反爬功能,尝试过更改新的请求头但依然没有作用,通过上网搜索发现也许可以通过代理iP等方式来反爬,但过于复杂,在本次的实验中我未能成功实行。
3.有时无法爬取内容
解决方法:可能是由于网站的反爬机制,发现只要重新刷新网页再运行代码,就可以爬取目标内容
4.词云图的内容需要类似关键字的高重复词组,但爬取的内容为语句段不够精简且概括
解决方法:使用中文分词库jieba,可以将词语精确的分开,消除冗余词语的影响
爬虫技术是指利用计算机程序自动获取互联网信息的技术。通常情况下,爬虫技术被用于从网页中提取数据、链接或其他信息,并将这些信息存储或进一步处理。爬虫基本流程一般都需要过HTTP或其他协议向目标网站发送请求,获取网页内容。然后对对获取的网页内容进行解析,提取出需要的信息,最后对实验数据进行处理
在本次实验中,我是实现了使用爬虫爬取猫眼视频的热门电影榜单,学习并实现了爬虫对前10热门电影相关内容的爬取,包括电影名、主演、上映时间等,并结合wordcloud库对于电影的类型进行词云图的制作,以此来分析最近最热门的电影类型是什么,在此期间学习了很多新的py模块,也通过使用对他们的大概功能有所了解,爬虫实验的编写让我第一次感觉学习的内容在网络上可以实现出来,让人非常自豪和喜悦,但我一定会注意相关事项,绝不触碰法律的红线。
python以前在我眼中跟人工智能和大数据有关,似乎是一门很高级的语言让人望而生畏,在上个学期我就陪着同学来体验过王志强老师的py课,给我留下了深刻的印象,也让我暗暗下定决心这学期一定要抢到Py课,这学期的py课结束后我发现,相较于C语言、JAVA等计算机语言,Python语言更显得实用与简便。它是一门非常有潜力的高级语言,在字符串上的处理,相对于其他程序有更多的便利。不仅如此,Python语言的库也很多,正因为它强大的库,让编程变得不再艰难。python的可拓展性是如此之高,也让我再次感受到他是一门多么有前景的语言。刚接触Python时,学会的代码print<“hello world!”>和print<"人生苦短,我用Python!">让我对这门课产生了极大兴趣,在这之后,不论是丰富的知识,还是老师幽默风趣的讲述,都让Python这门课程更加的吸引我。在后面几次Python课程的学习中,老师在课上讲得比较快,课上有时会跟不上,但是在课后也能够及时的去弥补不足,还是能够对Python学习的更多。虽然这几个月下来,我对Python的学习也仅仅只是它的基础方面,但Python的强大,也是足足地吸引着我。我希望自己能够在不断地学习中,将Python学习的更加好。
课程内容很丰富,但是放在一个学期每周三节课也感觉有点不够讲,感觉老师如果有时间和精力的话,可以将python课在细分几个子晚课,基础的用来给同学们打牢基础,还有一些高级的内容比如数据库,爬虫等每个都可以放在高阶的另一门python课上,就是将原本的python课分为基础课和进阶课,这样可以帮助同学们更好的掌握这门语言更细致的内容。
也可以设置一些跟python内容相关的编程比赛,来鼓励同学们更多的将所学内容运用到实践中,体会python语言的强大,提高同学们的学习兴趣。

