


558
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
本周开启隐语的第四次课程学习,关于隐语的安装部署及简单体验。

对于隐私计算开发以及业务生成场景使用,提供两种不同的模式:
(1)仿真模式,包括单机仿真以及集群仿真。
仿真模式具备很多优势。在这点上,业内的隐私计算厂商基本都有提供,但隐语可能在
这方面体验感会更好一些,投入了更多的资源去完善。
a. 成本低
开发者:在仿真模式下,开发者可以在单机或集群环境中模拟生产环境,进行调试
和测试,避免了直接在真实数据上操作的高成本和高风险。
使用者:可以在仿真模式下熟悉平台的功能和操作流程,而无需承担数据泄露或系
统故障的风险。
b. 高效调试
开发者:可以在仿真模式下快速迭代开发和测试代码,查找和解决问题,提升开发
效率。
使用者:可以快速验证其应用程序或流程在仿真环境中的表现,确保在投入生产前
已经过充分测试。
c. 安全性
开发者:仿真模式下使用的是模拟数据或脱敏数据,降低了实际数据泄露的风险。
使用者:在进行功能测试和性能测试时,无需担心实际数据的安全性问题。
(2)生产模式,多机部署执行。更加注重安全性以及真实环境。
a. 安全增强
开发者:生产模式下所有参与方都需要执行代码,并且平台提供了额外的安全增强措
施,如数据加密、访问控制等,确保数据传输和处理的安全性。
使用者:在生产模式下,用户的数据得到了严格保护,符合企业和行业的安全标准和
合规要求。
b. 高可靠性
开发者:生产模式经过严格测试和验证,能够在高负载下稳定运行,确保系统的可
靠性和可用性。
使用者:生产模式提供了可靠的计算和存储服务,能够处理大规模数据和复杂计算
任务,保证业务的连续性和稳定性。
c. 真实场景
开发者:在生产模式下,可以在真实数据和真实环境中验证和优化算法和模型,提
升模型的准确性和适用性。
使用者:能够在实际业务场景中使用平台的功能,获得真实有效的计算结果,推动
业务决策和发展。


隐语在多系统方面的支持做的还挺不错,包括常见的linux系统、macOS系统,以及支持windows内置的WSL2 linux子系统。python的版本要求是3.8及以上,隐私计算行业公开的资料看,普遍厂商都将python升级到了3.10之后,一方面出于漏洞修复考虑,另一方面基于性能考虑。
隐私计算一旦包含了tensorflow、pytorch等第三方包,一般docker镜像的大小会扩大到2-3G,业内厂商,比如蓝象提出一种空中安装的方式来提供安装服务,一开始可以是一个小的包,需要安装的全部服务的时候才会将所有的requirements都安装。因为你如果只是想要安全求交服务,完全没必要安装大且重的联邦学习模块的内容。类似富数等厂商,与隐语一样,可以提供lite的安装部署包,体积较小,适合轻量化部署。这种也是行业服务机构过程中衍生出来的共识。

隐语提供了多种安装方式,包括docker镜像、pypi、源码等。一般来说,docker镜像部署是最一步到位和简单的,包含了运行应用所需的所有依赖和环境配置,无论是在开发、测试还是生产环境,使用 Docker 都能确保应用运行的一致性。这个也是业内目前看,最普遍采用的方案。其他诸如pypi安装、源码安装,更适合开发者用来研发和调试。不过只要下载docker镜像的速度能保证的基础上,个人还是更推荐使用docker的安装模式,简单方便。
隐语是基于 RayFed 实现,RayFed 是 Ray 框架的一个扩展,用于实现跨集群的分布式计算。因此,理解 Ray 的使用和分布式调度是理解隐语的关键。以下是如何从 Ray 的使用来理解隐语的使用和分布式调度的详细说明:
Ray 任务:Ray 允许用户定义并行任务,这些任务可以在不同的节点上执行。每个任务都是一个独立的计算单元,可以由 Ray 调度器分配到集群中的任意节点。
Actor 模式:Ray 中的 Actor 是一个有状态的计算单元,能够维护状态并处理消息。Actors 可以在不同节点之间通信,从而实现复杂的分布式应用。
资源隔离:Ray 通过定义资源(如 CPU、内存等)来管理任务和 Actor 的资源分配。用户可以指定每个任务或 Actor 需要的资源,Ray 会根据资源情况调度这些任务。
自动扩展:Ray 支持自动扩展,可以根据任务的负载动态增加或减少节点,以优化资源利用和任务执行效率。
对象存储:Ray 提供了分布式对象存储(Plasma),允许任务之间共享数据。数据可以存储在内存中,提供高效的读写性能。
任务依赖:Ray 允许用户定义任务之间的依赖关系,调度器会根据依赖关系自动安排任务的执行顺序。
隐语基于 RayFed 实现,RayFed 扩展了 Ray 的能力,使其能够支持跨集群的分布式计算。以下是如何理解隐语的使用和分布式调度:
联邦学习任务:隐语支持跨多个集群的联邦学习任务。每个参与方可以在自己的集群中运行任务,RayFed 会负责调度这些任务并协调它们之间的通信。
安全计算任务:隐语支持安全多方计算(MPC)任务,这些任务需要在多个参与方之间进行数据交换和计算。RayFed 提供了安全的通信通道,确保数据在传输过程中不被泄露。
资源分配:隐语可以基于 Ray 的资源管理机制,为每个参与方分配合适的计算资源。用户可以指定每个参与方需要的资源,RayFed 会根据集群的资源情况进行调度。
负载均衡:RayFed 能够根据任务的负载情况动态调整资源分配,确保计算任务能够高效执行。
数据隔离与共享:在隐语中,不同参与方的数据是隔离的,但计算任务可以通过安全协议共享必要的数据。RayFed 利用 Ray 的对象存储和消息传递机制,确保数据在不同参与方之间安全传输和处理。
数据依赖管理:隐语可以管理计算任务之间的数据依赖,确保任务按照正确的顺序执行。RayFed 会根据任务的依赖关系自动安排执行计划。

单机仿真就是在自己当前本地,启动一个ray节点,来执行相应的计算任务。这个例子是在本地节点启动两个角色,alice和bob。执行的是PYU,也就是python的明文计算单元。
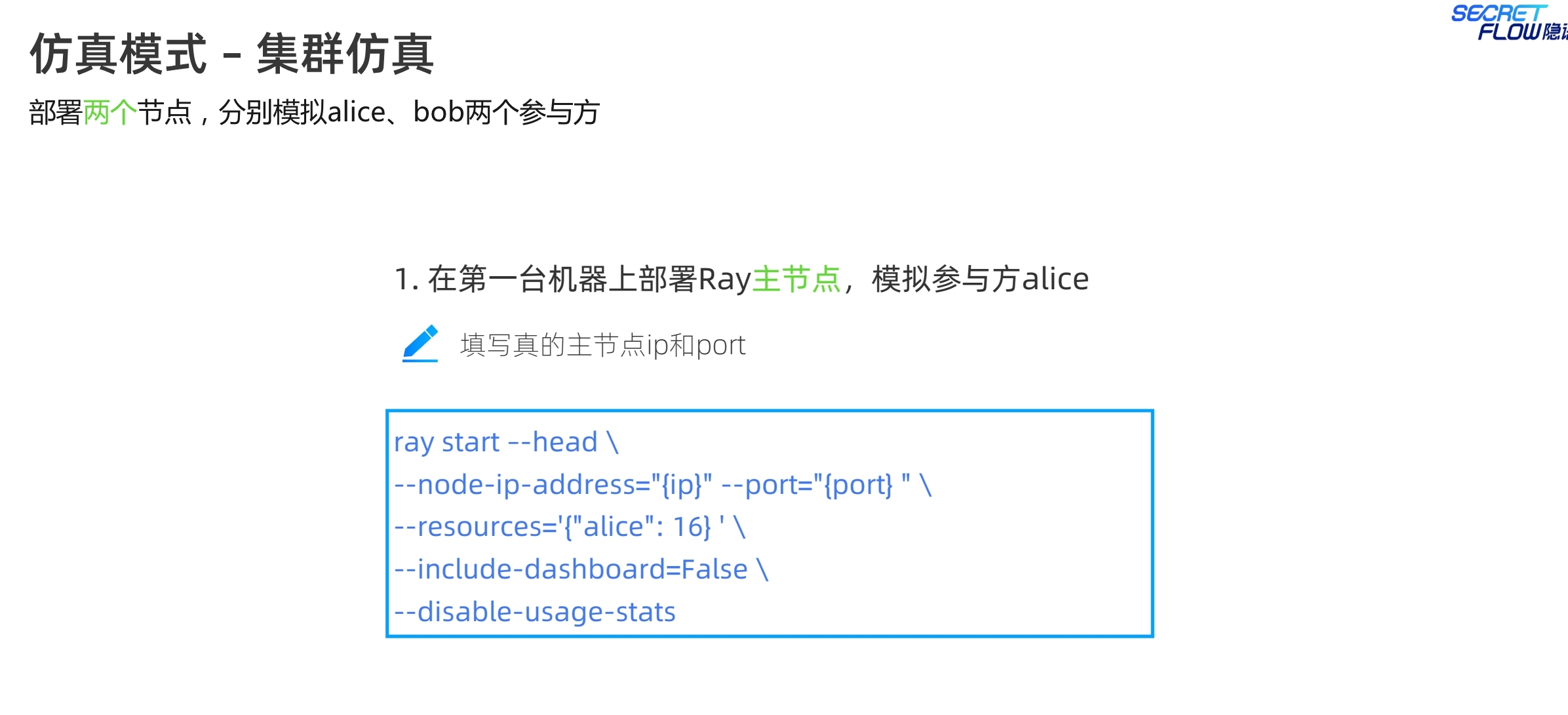


集群仿真,是指部署两个节点,两台机器上部署,应该也可以支持在一台机器上,通过不同端口模拟两台机器,在第一台机器上部署ray的主节点,也就是ray head,指定ip、port、资源等信息,另一台则部署从节点,注意从节点的address这里写的是主节点的通信地址。服务启动完成后,执行python代码,address改成对应主节点的ip和端口。

之前都是PYU的明文执行单元。现在创建spu的密态设备计算单元,在cluster集群配置信息,需要填写实际的alice和bob的通信地址,指定对应的mpc协议和整型碎片长度等一些必要的配置信息,这里选的是semi2k协议。然后初始化spu的集群信息。这种mpc启动模式在业内应该基本统一,没什么大的区别。从通信网络看,需要注意spu的端口,需要有别于ray的端口号。这里之所以采用不同的端口号,个人猜测是可能基于不同任务的功能分离或者安全性层面考虑,ray主要用于任务调度、资源管理和分布式计算。SPU 负责安全计算任务,如安全多方计算(MPC)等。SPU 的端口号用于安全计算任务的通信和数据交换。
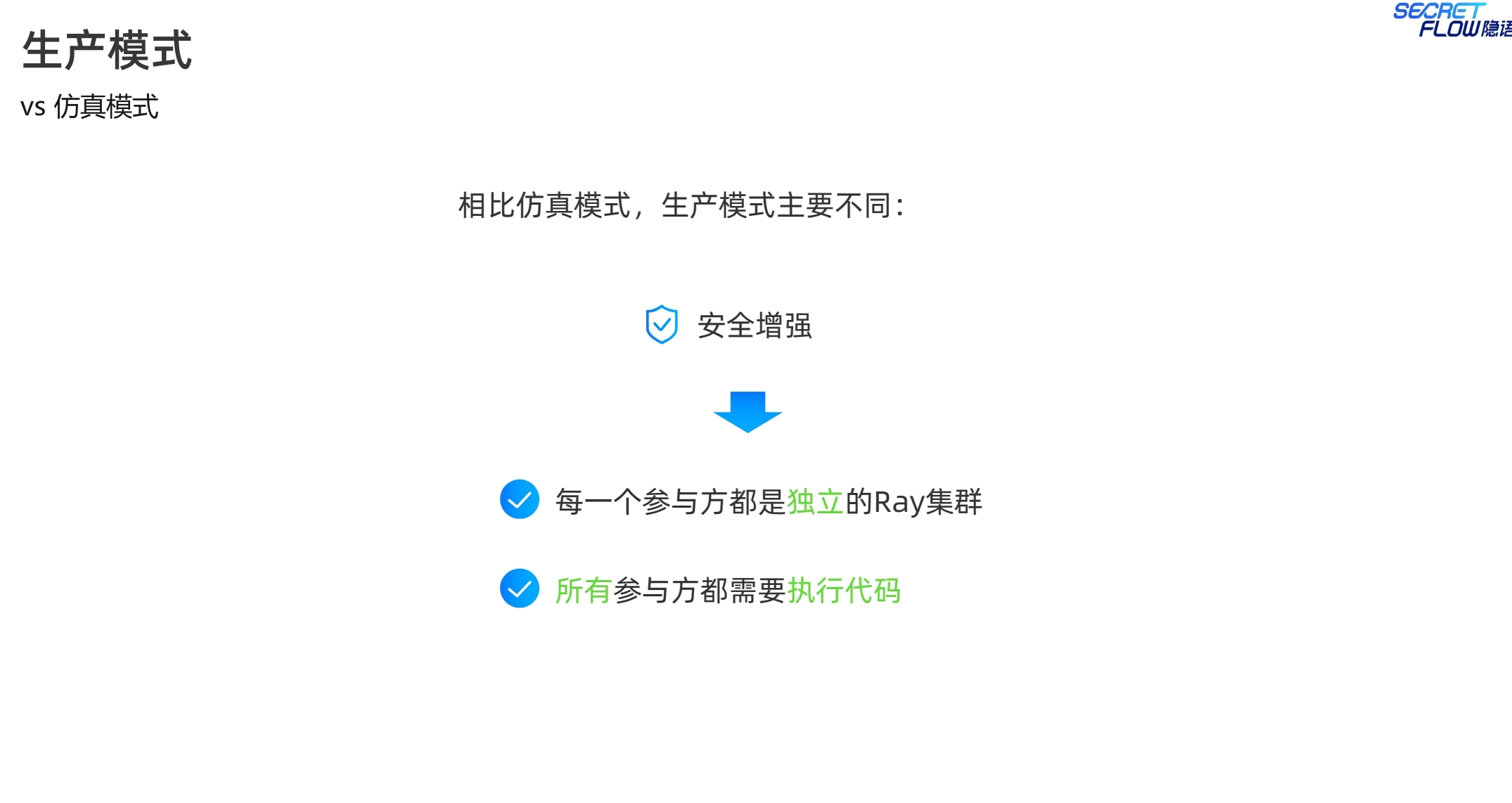
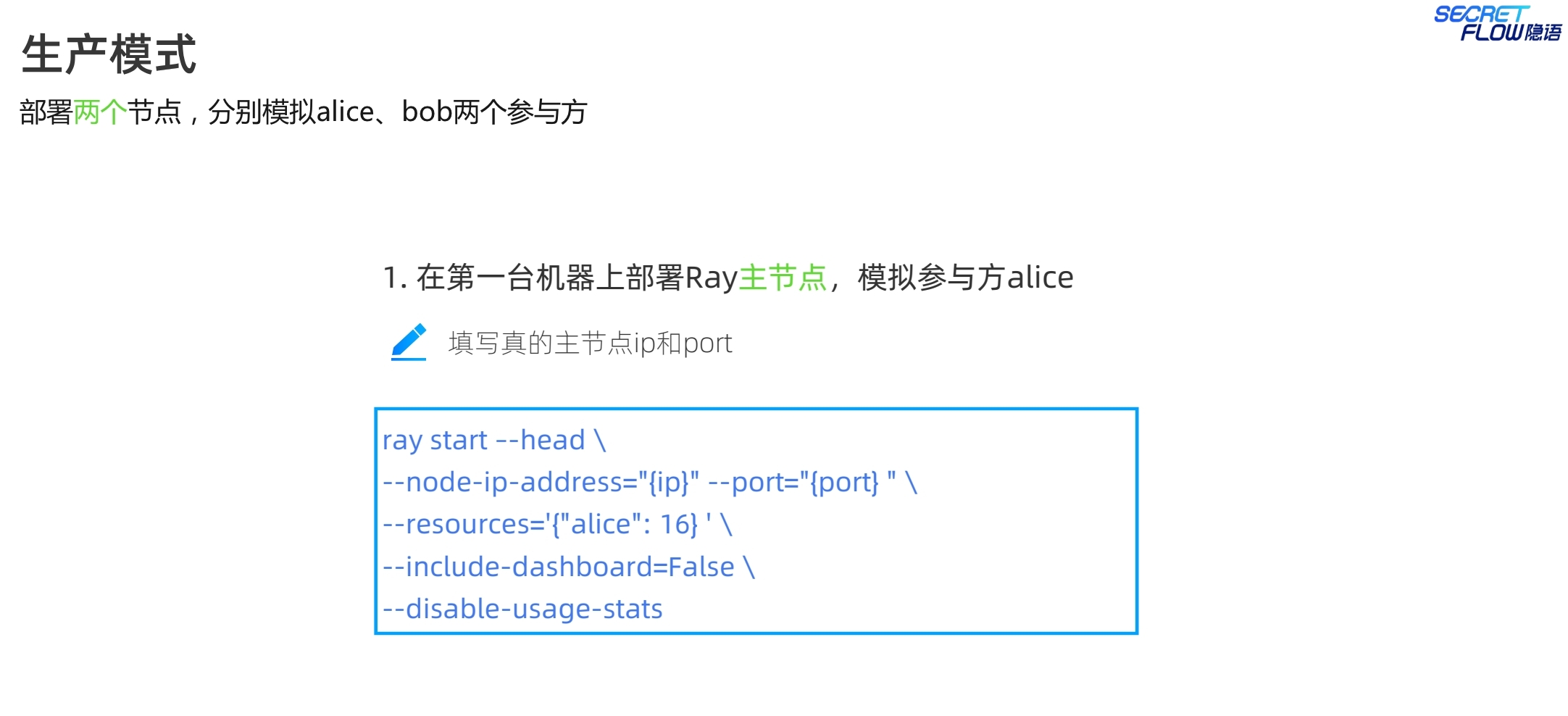
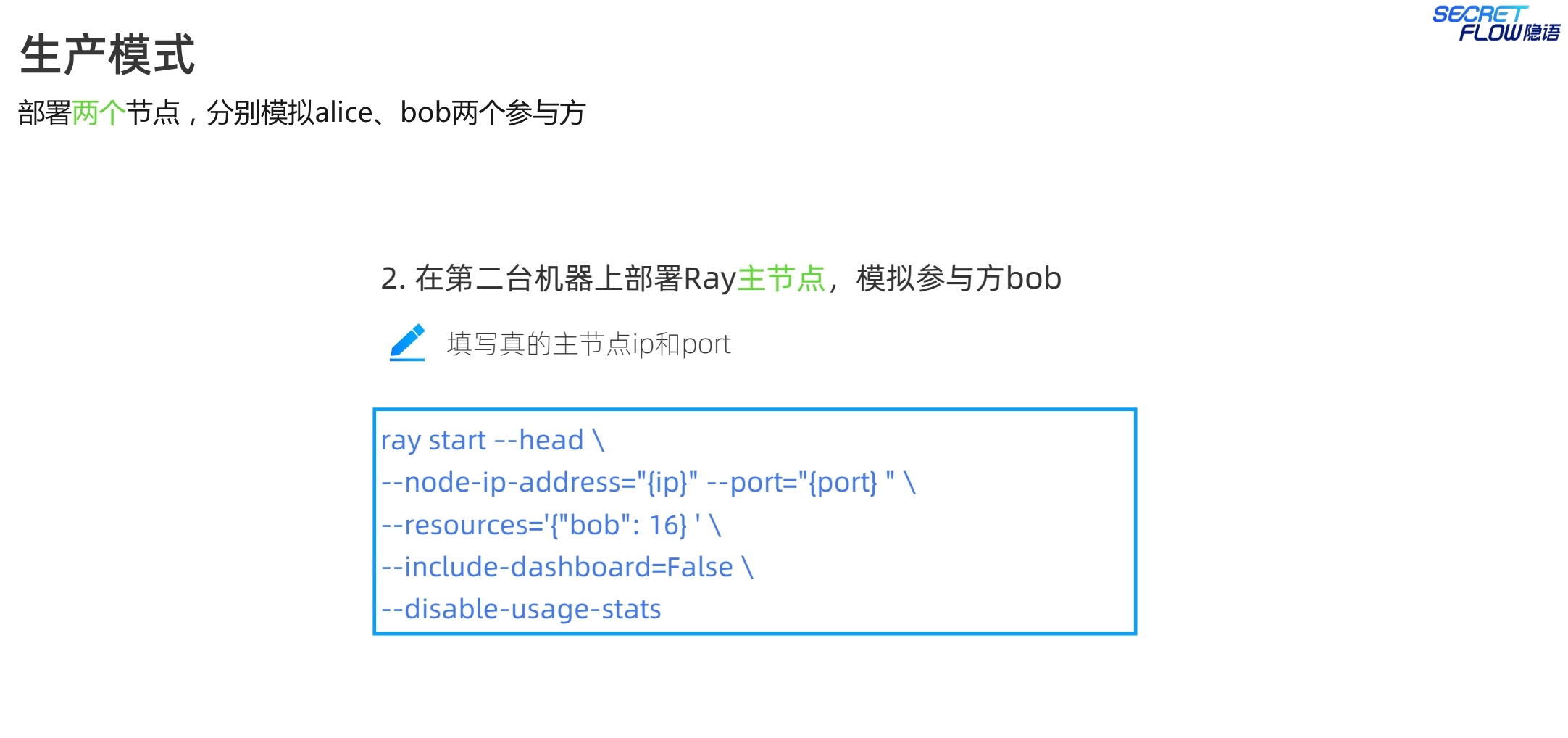
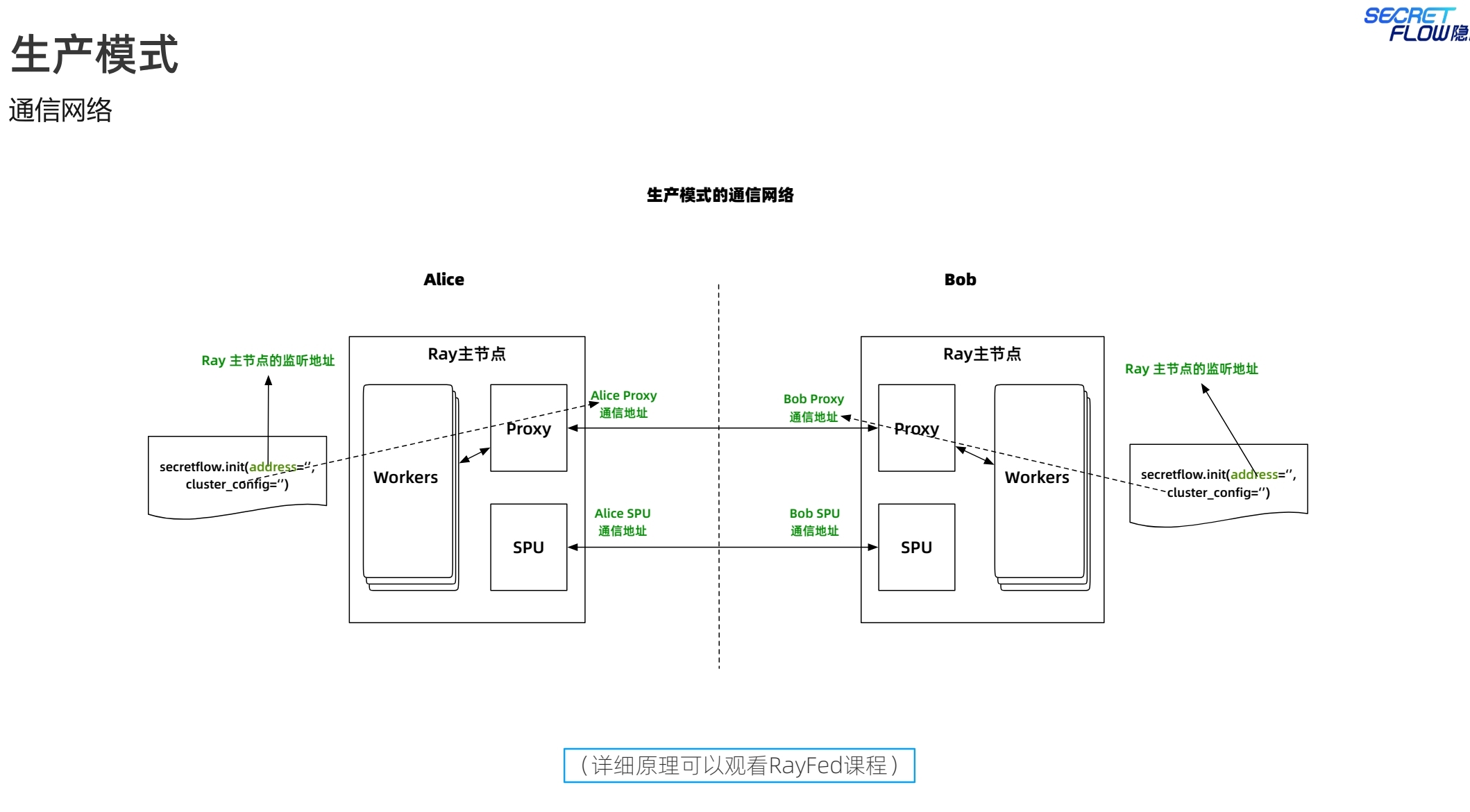
注意生产模式的启动指令与仿真模式的差别,生产模式下,各个节点都是一个完整的ray集群,因此启动指令中都是ray start --head。
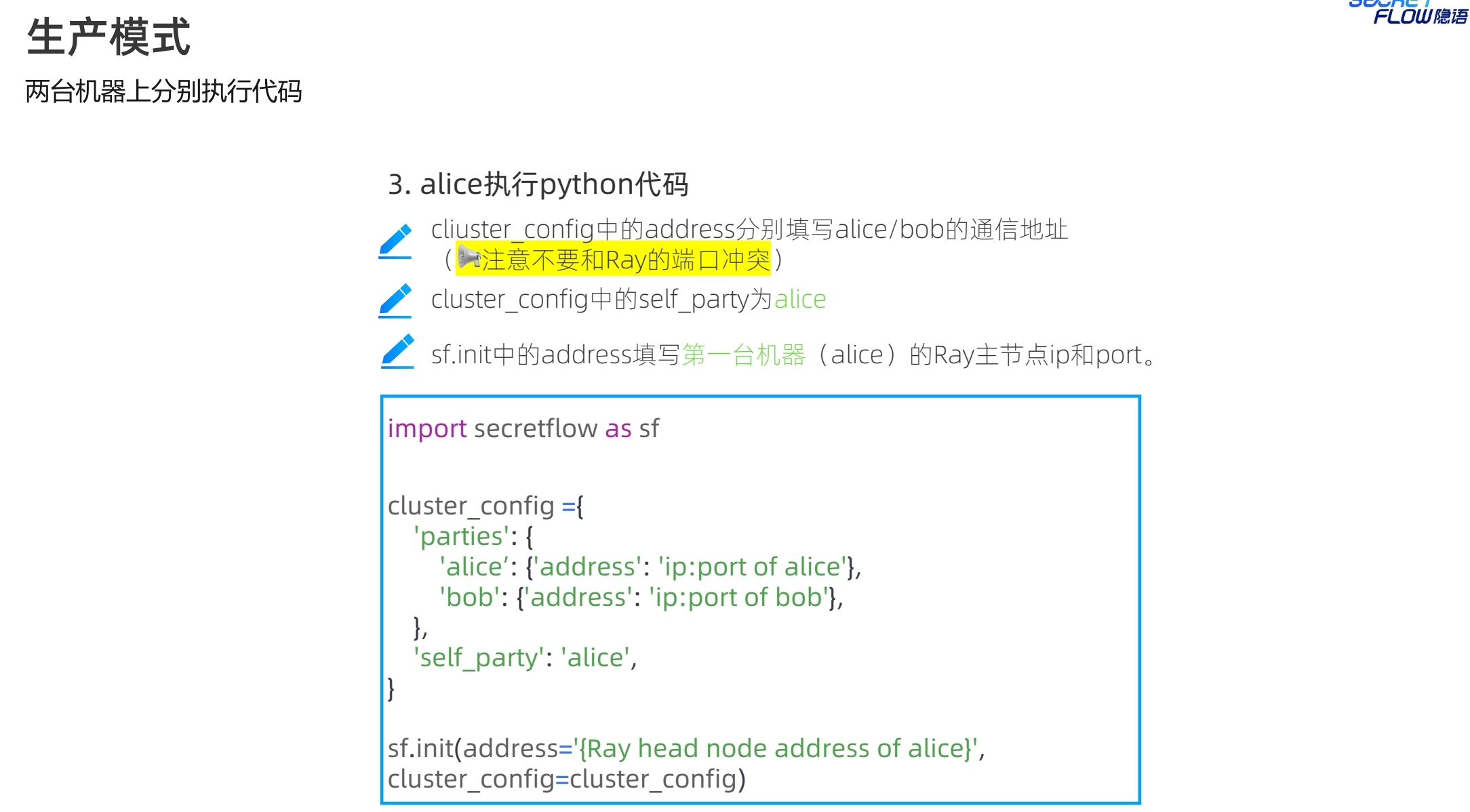
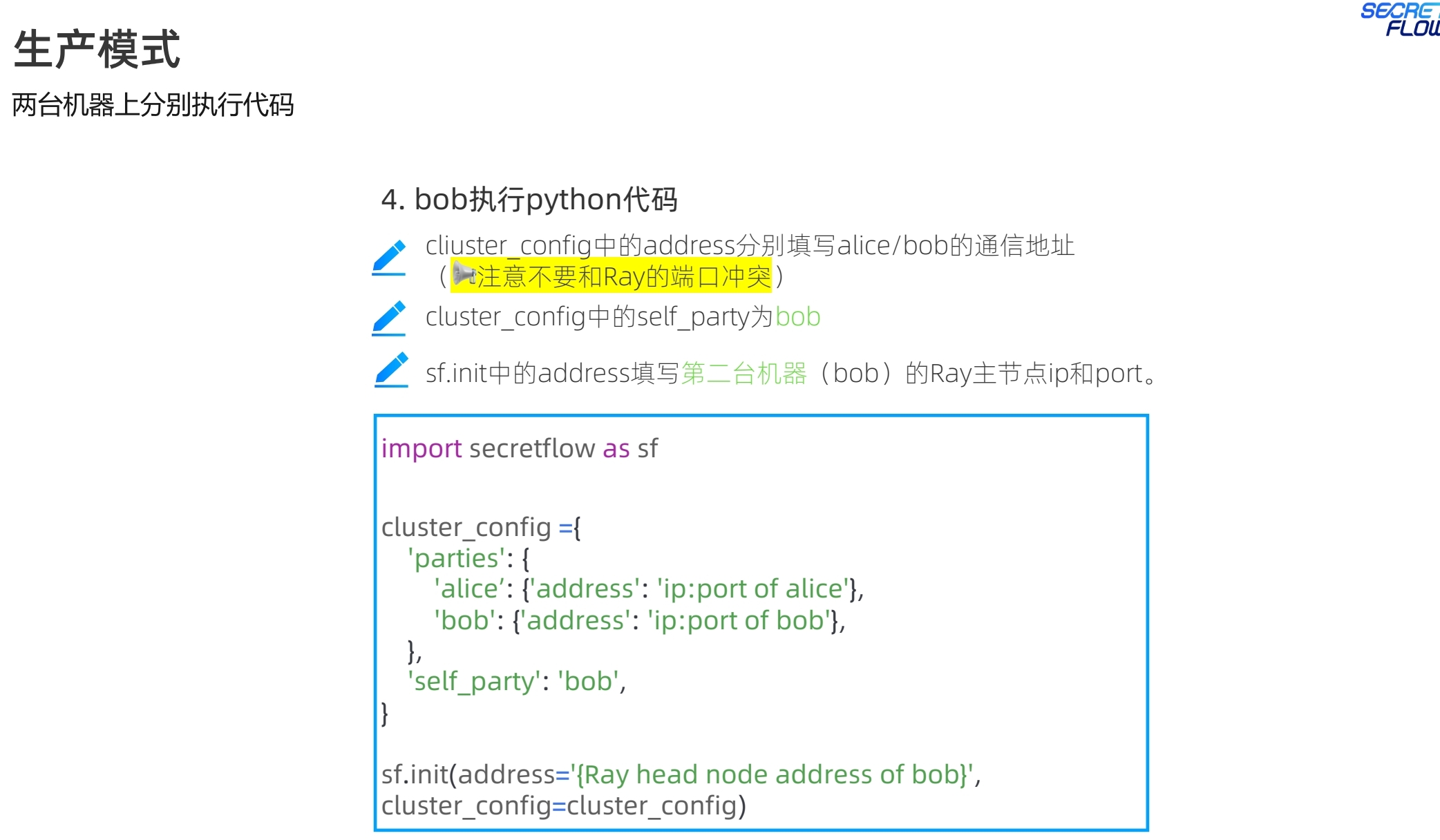
生产模式下,多了self_party的参数设置,用于区分节点角色。init的address是self_party的ray head节点地址。

SPU的设置与仿真模式差别不大,注意区分端口号不要冲突,否则会带来网络通信相关的报错。说实话,端口号的管理也是一个累人的活。不过隐语提供了kuscia来解决。从生产模式的通信网络看:
Ray:负责分布式任务调度和资源管理,主要在集群内部节点之间进行通信。
Proxy:充当通信代理,确保不同计算节点之间的安全、可靠通信。
SPU:执行安全计算任务,确保涉及敏感信息的数据处理过程中的隐私和安全。
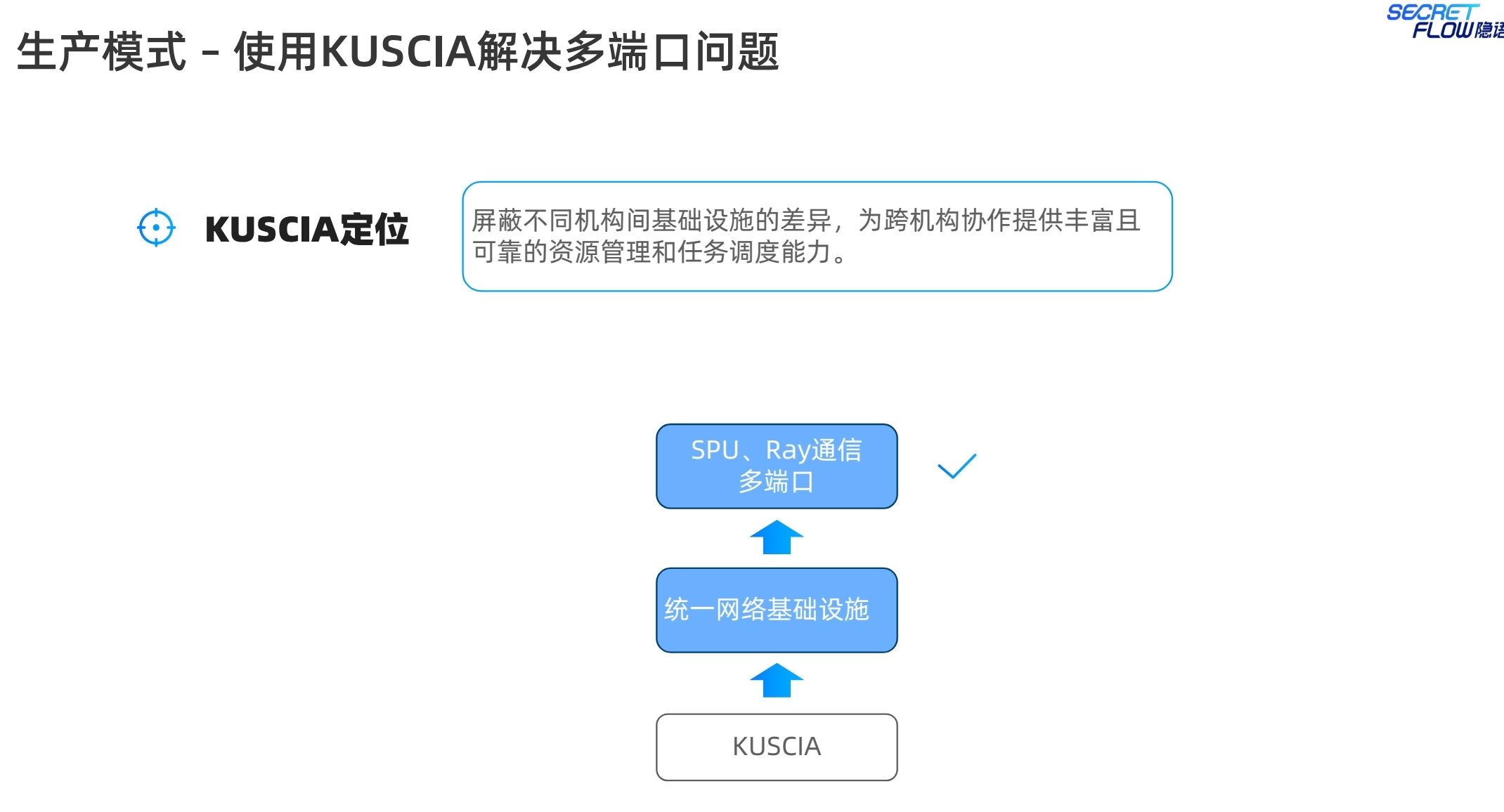
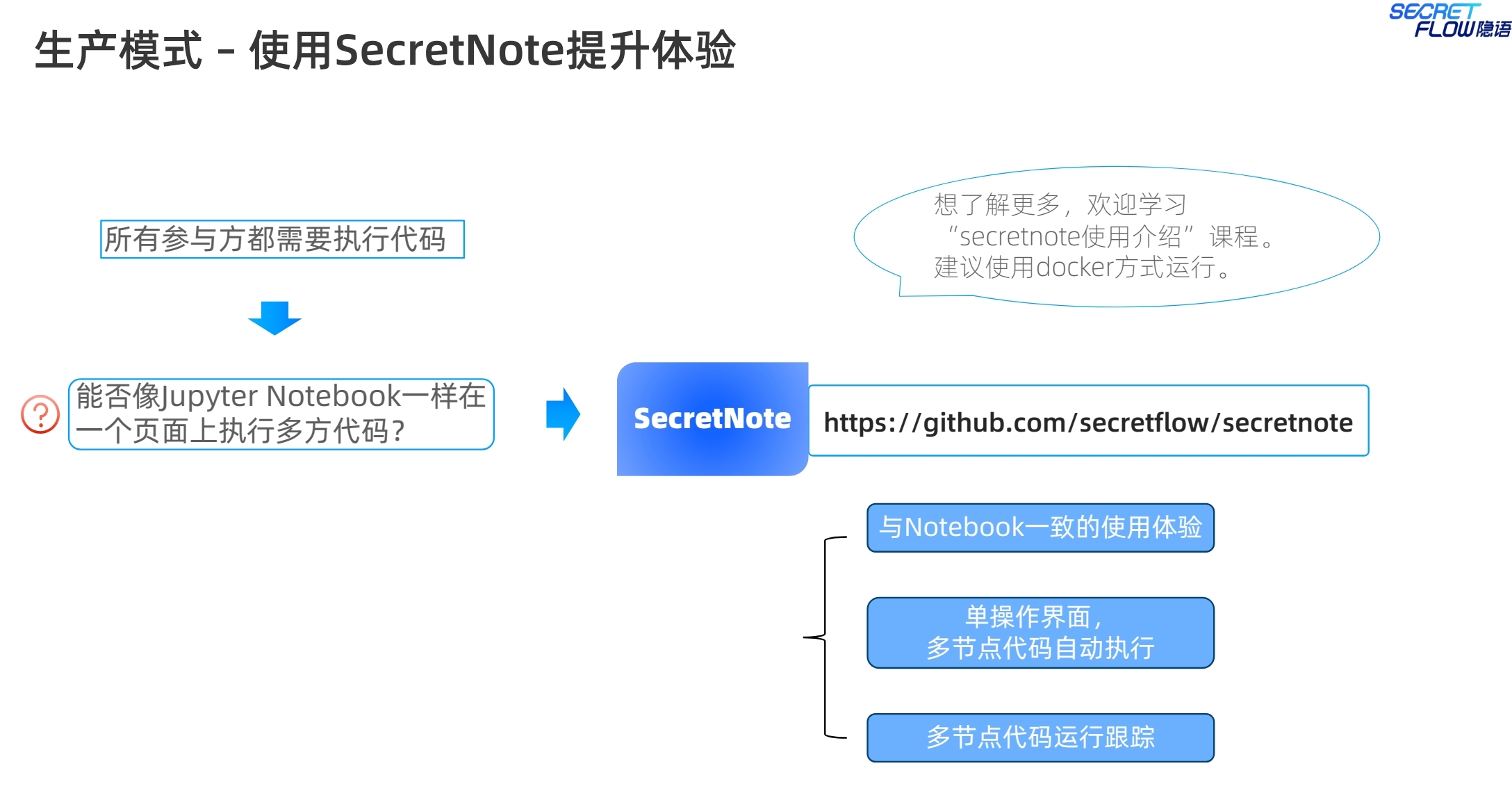
另外也介绍了一下secretnote的使用,类似于notebook的编程体验。这个业内也有一些厂商提供该功能,隐语做了更多的用户体验的适配。

分布式框架,业内普遍采用ray,可能也是一种共识。也许以后会有更优秀的框架取代ray,拭目以待。从隐语的设计来看,保持了对于使用其他可替代分布式框架的能力,架构还是蛮优秀的。

