558
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
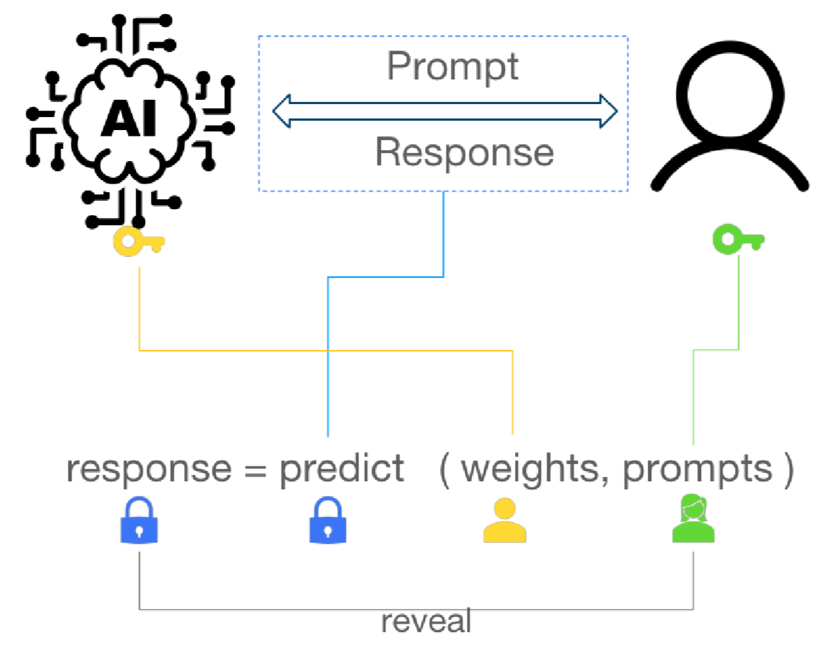
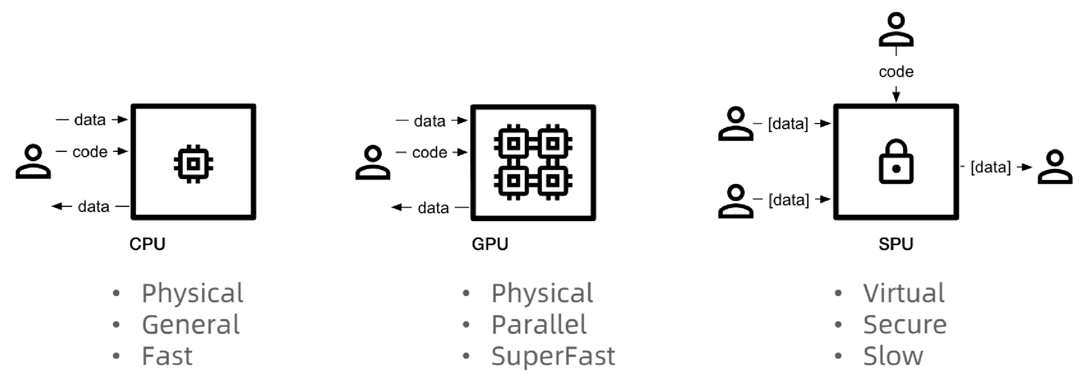
分享这种方法确保了模型和用户提示词的双重保护。

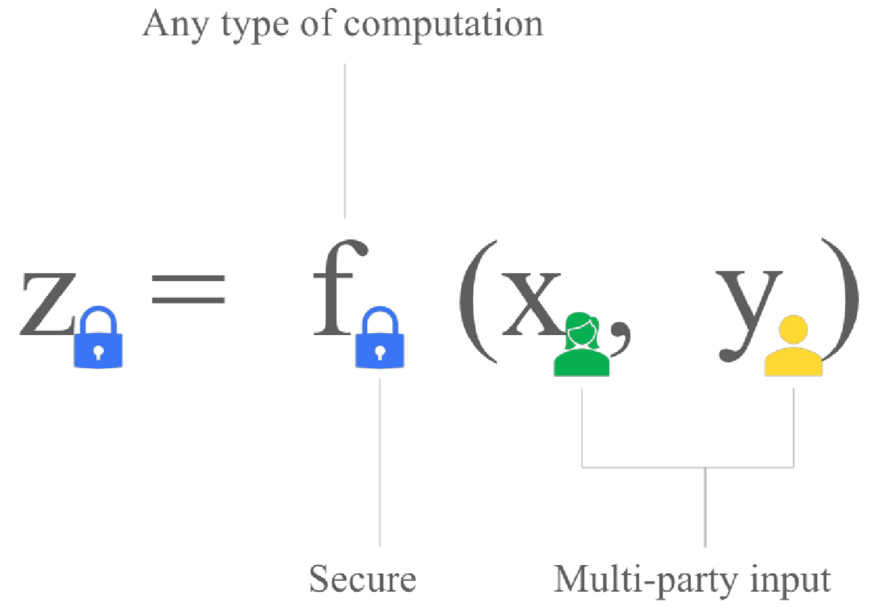
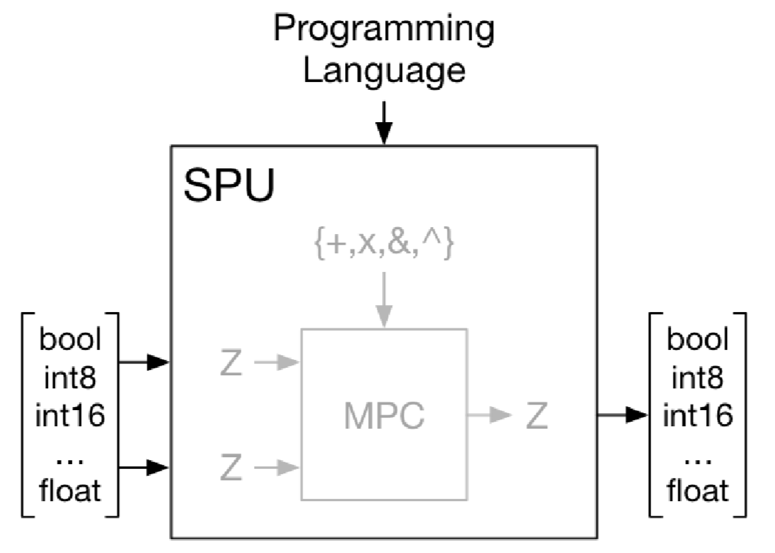
图示展示了一个安全计算函数 f(x, y),接受多个输入(例如来自不同方的输入),并产生一个安全输出 z。
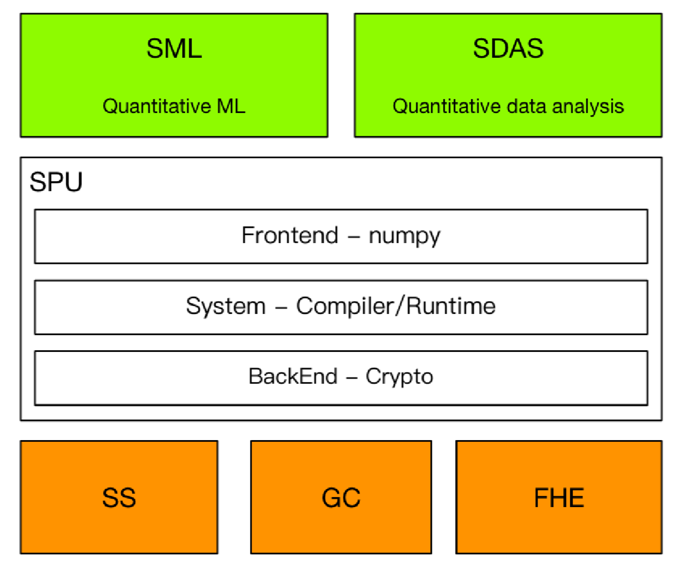
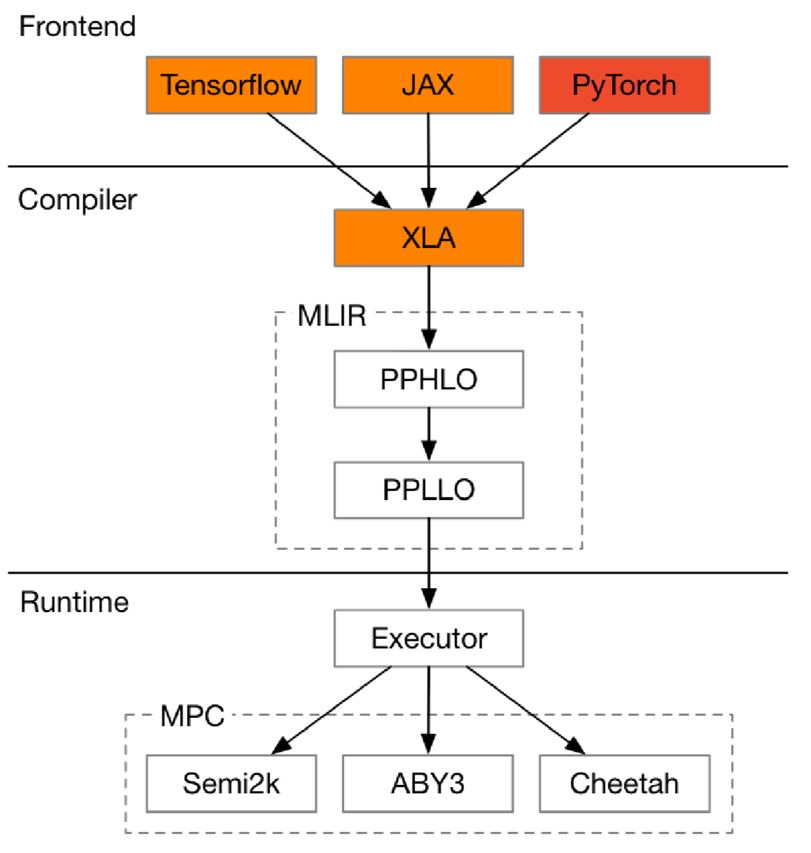
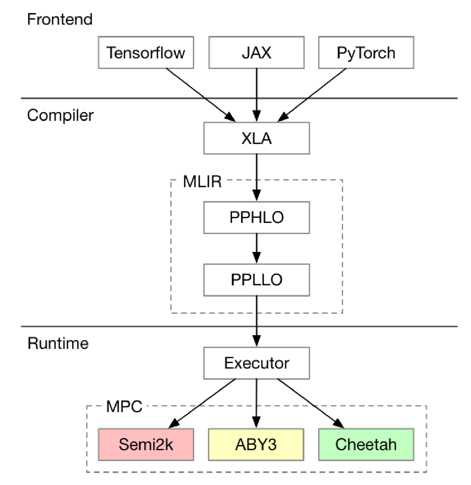
原生支持主流AI前端:支持TensorFlow、JAX、PyTorch等主流AI框架,降低了学习成本,并能复用AI前端的能力,例如自动求导。
负责将高层次的AI框架代码转化为低层次的中间表示(Intermediate Representation, IR),再进行优化和生成机器可执行的代码。
MPC(多方计算)协议:支持多种协议如Semi2k、ABY3、Cheetah,用于不同的安全计算需求。
支持隐私保护领域的IR,优化和降低特定领域的计算复杂度。复用AI编译器的部分优化,提升隐私计算的性能。
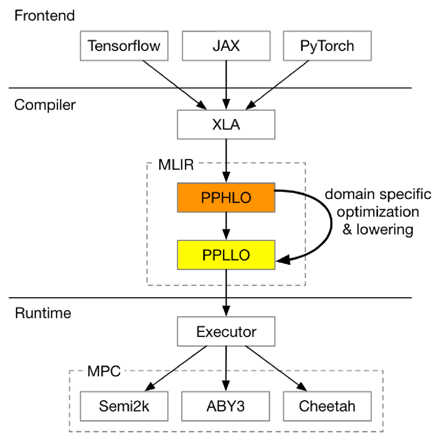
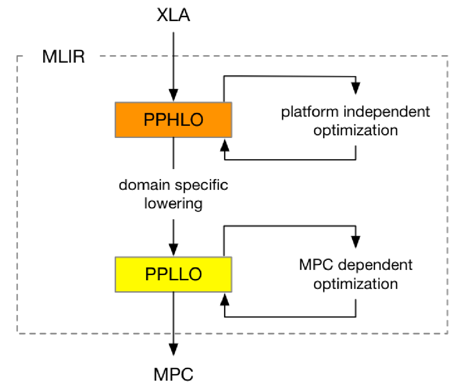
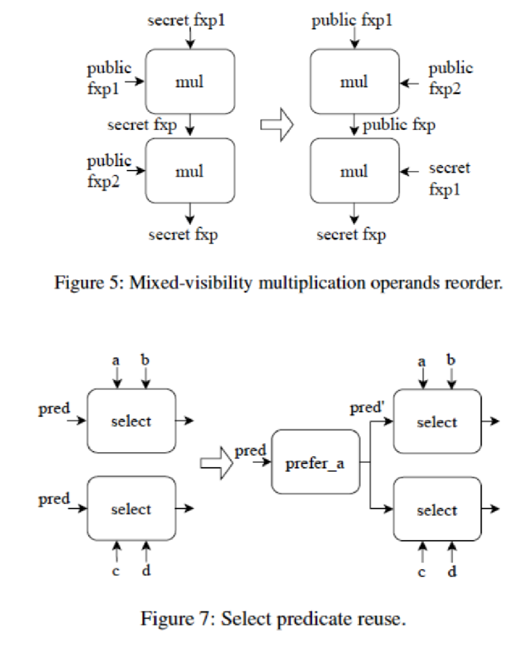
从高层次IR(PPHLO)到低层次IR(PPLLO)的转换过程,包含特定领域优化和MPC依赖的优化。混合可见性乘法操作数重排序:优化公有和私有数据之间的乘法顺序,提高计算效率。选择谓词重用:优化选择操作,减少不必要的计算。
(1)并行模型支持
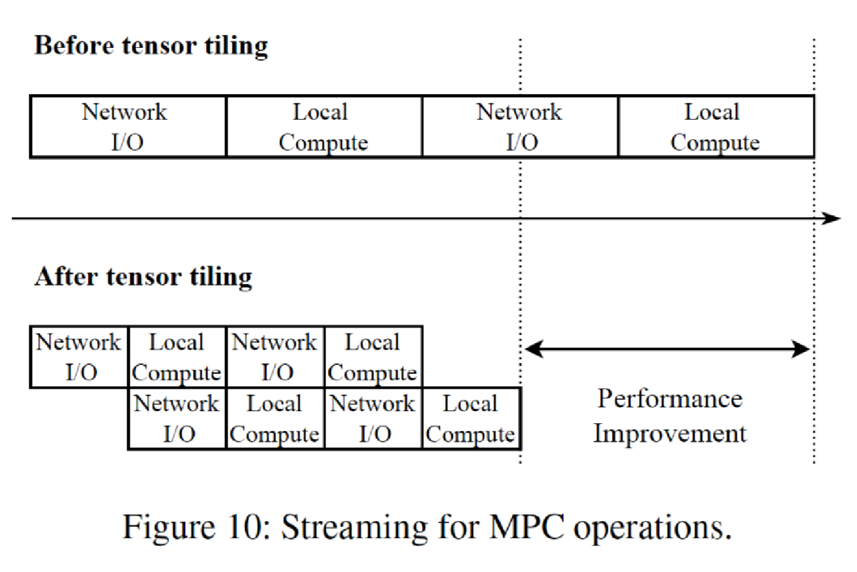
张量分块:通过将张量划分成小块进行并行处理,提高MPC操作的性能。
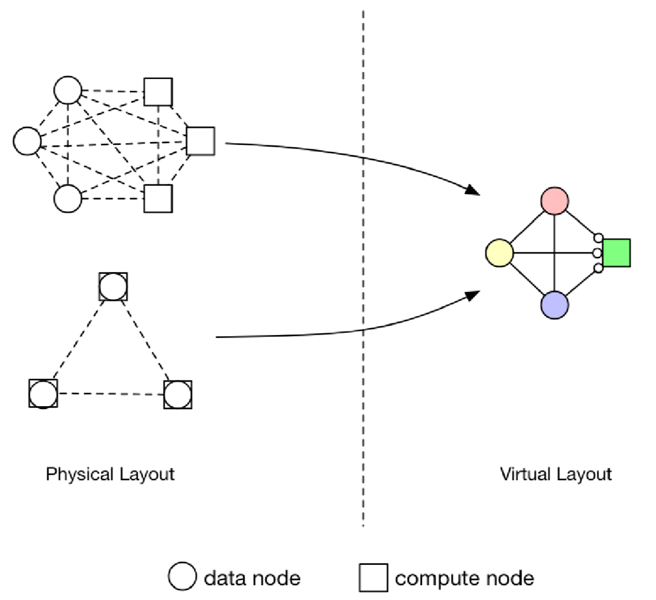
支持面向虚拟设备编程和一次书写多处执行的部署模式。通过物理布局和虚拟布局的结合,实现数据节点和计算节点的高效分配和管理。
代码示例1: 随机数生成和比较函数
功能: 在不同设备上生成随机数,并在SPU上进行比较。
示例代码:
import numpy as np
import jax.numpy as jnp
import spu.utils.distributed as ppd
def rand():
return np.random.randint(100, size=(1,))
def compare(x, y):
return jnp.maximum(x, y)
# 生成随机数
x = ppd.device("P0")(rand)()
y = ppd.device("P1")(rand)()
# 在SPU上进行比较
z = ppd.device("SPU")(compare)(x, y)
# 显示结果
print(f"reveal {ppd.get(z)}")
代码示例2: GPT2密态预测
功能: 使用GPT2模型进行文本生成,并在SPU上执行。
示例代码:
def text_generation(input_ids, params, token_num=10):
config = GPT2Config()
model = FlaxGPT2LMHeadModel(config=config)
for _ in range(token_num):
outputs = model(input_ids=input_ids, params=params)
next_token_logits = outputs[0][0, -1, :]
next_token = jnp.argmax(next_token_logits)
input_ids = jnp.concatenate([input_ids, jnp.array([[next_token]])], axis=1)
return input_ids
def run_on_spu():
input_ids = tokenizer.encode("I enjoy walking with my cute dog", return_tensors='jax')
input_ids = ppd.device("P1")(lambda x: x)(input_ids)
params = ppd.device("P2")(lambda x: x)(pretrained_model.params)
output_ids = ppd.device("SPU")(text_generation)(input_ids, params)
return ppd.get(output_ids)
(4)修改SPU配置文件
基本使用:通过修改SPU配置文件,无需代码改动即可更改安全协议。
配置示例:
"SPU": {
"kind": "SPU",
"config": {
"node_ids": ["node:0", "node:1", "node:2"],
"runtime_config": {
"protocol": "ABY3",
"field": "FM64"
}
}
}
多层级Profiling: 提供详细的函数执行时间和次数,帮助优化性能。
全栈追踪: 支持全栈追踪,便于问题定位。
明文运行调试: 提供明文运行模式,方便调试和测试。
Profiling示例:
[Profiling] function predict, execution took 0.423396238s ...
Detailed pphlo profiling data:
- pphlo.multiply, executed 1 times, duration 0.053121456s
- pphlo.broadcast, executed 1 times, duration 2.485e-06s
- pphlo.dot, executed 1 times, duration 0.35661242s
- ...