


113
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享作业基本信息
| 这个作业属于哪个课程 | 2401_CS_SE_FZU社区-CSDN社区云 |
|---|---|
| 要求 | 软件工程实践第二次作业-CSDN社区 |
| 作业目标 | 实现一个对巴黎奥运会赛程,奖牌个数和国家排名进行统计的程序 |
| 其他参考文献 | 《构建之法》 |
| PSP | Personal Software Process Stages | 预计耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| Estimate | 预估时间 | 10 | 10 |
| Development | 开发 | 600 | 660 |
| Analysis | 需求分析 | 15 | 20 |
| Design | Spec | 80 | 100 |
| Design Review | 设计复审 | 25 | 25 |
| Coding | 编码 | 240 | 240 |
| Code Review | 代码复审 | 35 | 60 |
| Test | 测试 | 30 | 60 |
| Reporting | 报告 | 35 | 40 |
| Size Measurement | 计算工作量 | 20 | 10 |
| Postmortem & Peocess Improvement Plan | 总结改进 | 25 | 20 |
| 合计 | 1125 | 1245 |
说来惭愧,在爬取数据方面,我浪费了大量时间,直到9号晚上才彻底解决,可谓是一波三折,一开始是想用正则表达式抓取核心的文本部分,但是发现抓取不了,发现是动态网页后,我试着用selenium解决,虽然抓到了核心的文本内容,但是项目需求中表明需要对抗团体赛需要列出国家,如果只是抓取文本,那么就无法处理国家名字这个问题
展示一下部分错误代码:
def get_info(str):
url = 'https://sports.cctv.cn/Paris2024/schedule/date/index.shtml?date=2024'+str
driver = webdriver.Chrome()
driver.get(url)
# 获取页面标题
print(driver.title)
html = driver.page_source
tree = etree.HTML(html)
#抓取tbody
tbody = tree.xpath("//tbody[@id='data_list']")
print(tbody)
# 检查是否定位到了 tbody
if tbody:
# 抓取所有 tr class="unstart end" 下的 td 元素文本
rows = tbody[0].xpath(".//tr[@class='unstart end']")
for row in rows:
# 获取当前 tr 下所有 td 元素的文本
texts = row.xpath("./td/text()")
print(texts)
file_name = str+".json"
with open("./data/{}".format(file_name), "a") as f:
for text in texts:
f.write(text+"\n")
在经过对动态网页的研究之后,我终于也是走上正道,使用了requests和正则表达式去爬取json部分,接下来我选择java作为语言,然后我导入Gson的jar包来辅助我的项目,用Gson来解析我的json数组,遍历他们的过程中,把字符串处理好放到对应的output.txt文件上
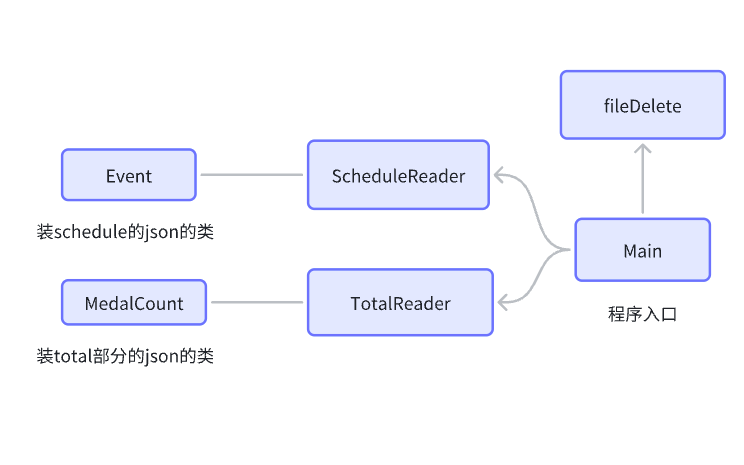
ScheduleReader类包含3个函数,scheduleExists用来判断文件是否存在,errorRead输出不存在情况下的内容,scheduleRead输出如果文件存在时的内容
# 基础API链接模板
api_url_template = 'https://api.cntv.cn/olympic/getOlyMatchList?startdate={}&t=jsonp&cb=OM&serviceId=2024aoyun&olyseason=2024S'
# 设置时间范围
start_period = datetime.strptime('20240724', '%Y%m%d')
end_period = datetime.strptime('20240811', '%Y%m%d')
# 生成日期列表
date_list = [start_period + timedelta(days=i) for i in range((end_period - start_period).days + 1)]
# 遍历日期列表
for current_day in date_list:
# 将日期格式化为字符串
formatted_date = current_day.strftime('%Y%m%d')
# 生成具体的API请求链接
request_url = api_url_template.format(formatted_date)
try:
# 发起HTTP请求获取数据
http_response = requests.get(request_url)
if http_response.status_code == 200:
# 提取出JSONP中的JSON内容
jsonp_response = http_response.text
json_str = re.search(r'OM\((.*)\)', jsonp_response).group(1) # 正则匹配并提取JSON部分
# 将提取的JSON字符串转为Python对象
parsed_json = json.loads(json_str)
public static void processLine(String line) {
if(line.equals("total")){
TotalReader reader = new TotalReader();
reader.totalRead();
}
if(line.contains("schedule")){
String[] parts = line.split(" ");
String date = parts[1];
System.out.println(date);
ScheduleReader reader = new ScheduleReader();
if(reader.scheduleExists(date)){
reader.scheduleRead(date);
}
if (!reader.scheduleExists(date)) {
reader.errorRead();
}
}
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonElement;
import com.google.gson.JsonObject;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class TotalReader {
public void totalRead() {
Gson gson = new Gson();
try {
String filepath = "./data/total.json";
String outputpath = "./output.txt";
// 读取JSON文件
FileReader reader = new FileReader(filepath);
JsonObject jsonObject = gson.fromJson(reader, JsonObject.class);
// 获取medalsList数组
JsonArray medalsList = jsonObject.getAsJsonObject("data").getAsJsonArray("medalsList");
// 将每个JSON对象转换为MedalCount对象并打印
for (JsonElement element : medalsList) {
MedalCount medalCount = gson.fromJson(element, MedalCount.class);
String str1 = "rank"+medalCount.getRank()+":"+medalCount.getCountryid();
String str2 = "gold:"+medalCount.getGold();
String str3 = "silver:"+medalCount.getSilver();
String str4 = "bronze:"+medalCount.getBronze();
String str5 = "gold:"+medalCount.getGold();
String str6 = "total:"+medalCount.getCount();
try (FileWriter fileWriter = new FileWriter(outputpath, true)) {
fileWriter.write(str1);
fileWriter.write(System.lineSeparator());
fileWriter.write(str2);
fileWriter.write(System.lineSeparator());
fileWriter.write(str3);
fileWriter.write(System.lineSeparator());
fileWriter.write(str4);
fileWriter.write(System.lineSeparator());
fileWriter.write(str5);
fileWriter.write(System.lineSeparator());
fileWriter.write(str6);
fileWriter.write(System.lineSeparator());
fileWriter.write("----");
fileWriter.write(System.lineSeparator());
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("rank"+medalCount.getRank()+":"+medalCount.getCountryid());
System.out.println("gold:"+medalCount.getGold());
System.out.println("silver:"+medalCount.getSilver());
System.out.println("bronze:"+medalCount.getBronze());
System.out.println("total:"+medalCount.getCount());
System.out.println("-----");
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public void scheduleRead(String filename) {
Gson gson = new Gson();
try {
// 读取JSON文件
String filepath = "./data/2024"+filename+".json";
FileReader reader = new FileReader(filepath);
JsonObject jsonObject = gson.fromJson(reader, JsonObject.class);
// 获取medalsList数组
JsonArray eventList = jsonObject.getAsJsonArray("data");
// 将每个JSON对象转换为MedalCount对象并打印
for (JsonElement element : eventList) {
String filePath = "./output.txt"; // 替换为你的文件路径
Event event = gson.fromJson(element, Event.class);
String time = event.getStartdate();
LocalTime localTime = LocalTime.parse(time, DateTimeFormatter.ofPattern("HH:mm"));
LocalTime now = localTime.plusHours(6);
String str1 = "time:"+now;
String str2 = "name:"+event.getItemcodename();
String str3 = "sport:"+event.getTitle();
String str4;
if(event.getAwayname()!=""&&event.getHomename()!=""){
str4=event.getAwayname()+"VS"+event.getHomename();
System.out.println(str4);
}else {
str4="";
}
String str5 = "venue:"+event.getVenuename();
String str6 = "----";
try (FileWriter fileWriter = new FileWriter(filePath, true)) {
fileWriter.write(str1);
fileWriter.write(System.lineSeparator());
fileWriter.write(str2);
fileWriter.write(System.lineSeparator());
if(str4.isEmpty()){
fileWriter.write(str3);
fileWriter.write(System.lineSeparator());
}else {
fileWriter.write(str3+" "+str4);
fileWriter.write(System.lineSeparator());
}
fileWriter.write(str5);
fileWriter.write(System.lineSeparator());
fileWriter.write(str6);
fileWriter.write(System.lineSeparator());
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("time:"+now);
System.out.println("name:"+event.getItemcodename());
System.out.print("sport:"+event.getTitle()+" ");
if(event.getAwayname()!=""&&event.getHomename()!=""){
System.out.print(event.getAwayname()+"VS"+event.getHomename());
}
System.out.println();
System.out.println("venue:"+event.getVenuename());
System.out.println("----");
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
使用json格式存储,配合处理json的jar包,比起txt效率更高
public void Test(){
try (FileWriter writer = new FileWriter("./input.txt", true)) { // true表示追加模式
for (int month = 7; month <= 8; month++) {
int startDay = (month == 7) ? 24 : 1;
int endDay = (month == 7) ? 31 : 31;
for (int day = startDay; day <= endDay; day++) {
String date = String.format("%02d%02d", month, day);
writer.write("schedule"+date + "\n");
writer.write("total\n");
}
}
System.out.println("日期生成完成并写入文件。");
} catch (IOException e) {
e.printStackTrace();
}
FileDelete fileDelete = new FileDelete();
fileDelete.deleteFile();
String filePath = "./input.txt"; // Path to the input file
try (BufferedReader reader = new BufferedReader(new FileReader(filePath))) {
String line;
while ((line = reader.readLine()) != null) {
processLine(line);
}
} catch (IOException e) {
e.printStackTrace();
}
}
通过这次学习,我学会了爬虫对动态网络和静态网络的不同处理,以及三个基本方法,正则表达式,bs和Xpath,还有requests和selenium框架的基本使用,在java中我学习了使用Gson处理json对象和json数组,序列化和非序列化的相互转换


