



34,876
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享表结构
ID int,items varchar(50),addDate datetime
数据如下表
| id | items | addDate |
| 1 | 01,09,11,33,44,55 | 2024-01-01 |
| 2 | 09,22,31,34,35,80 | 2024-01-01 |
现给出字符串 09,33,要求查询出字符串09,33在items中出现的个数,第一行包含2个(09,33),第二行包含1个(09)
不明白SQL要如何实现?如果能用存储过程特来实现也可以。特来请教,感谢!

要在 SQL Server 中查询出 items 字段中某些特定字符串(如 09,33)出现的次数,可以使用 CHARINDEX 函数以及 STRING_SPLIT 函数结合一些逻辑来实现。由于 items 字段是以逗号分隔的字符串,你可以逐行拆分并检查是否包含所需的字符,然后统计匹配的次数。
以下是实现查询的思路,SQL 语句以及如何通过存储过程来实现的两种方式。
ID,
value AS Item, -- 每个拆分后的单项
addDate
使用 STRING_SPLIT 函数将 items 列中的字符串拆分为独立的元素。
CROSS APPLY 允许对每一行执行拆分操作。
使用 WHERE 过滤出只包含 09 和 33 的项。
最后使用 COUNT(*) 统计每一行中匹配项的个数。
2. 使用存储过程来实现
如果你想通过存储过程实现,可以将上述查询封装到一个存储过程中。下面是一个示例存储过程:
CREATE PROCEDURE CountStringOccurrences
@searchString VARCHAR(50) -- 查询的目标字符串,如 '09,33'
AS
BEGIN
-- 将目标字符串拆分为单个元素
DECLARE @temp TABLE (Item VARCHAR(10));
INSERT INTO @temp
SELECT value FROM STRING_SPLIT(@searchString, ',');
-- 统计匹配次数
WITH Splitted AS (
SELECT
ID,
value AS Item,
addDate
FROM YourTable
CROSS APPLY STRING_SPLIT(items, ',')
)
SELECT
ID,
COUNT(*) AS MatchCount
FROM Splitted
WHERE Item IN (SELECT Item FROM @temp)
GROUP BY ID;
END;
执行存储过程时,传入查询的字符串 09,33,如:
EXEC CountStringOccurrences '09,33';
解释:
存储过程接受一个包含逗号分隔的字符串。
STRING_SPLIT 将目标字符串和表中的 items 列都拆分为独立元素。
通过比较两个集合中的元素,计算匹配的个数。
这样就可以灵活地查询出每一行包含目标字符串的次数。
(不知道对不对,我也不懂)



--测试数据
if not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T([id] int,[items] nvarchar(37),[addDate] Date)
Insert #T
select 1,N'01,09,11,33,44,55','2024-01-01' union all
select 2,N'09,22,31,34,35,80','2024-01-01'
Go
--测试数据结束
DECLARE @str NVARCHAR(50)='09,33'
SELECT id,t2.items,COUNT(1) AS 次数
FROM
(
SELECT *
FROM #T
JOIN
(SELECT * FROM STRING_SPLIT(@str, ',') t) t1
ON CHARINDEX(',' + t1.value + ',', ',' + items + ',') > 0
) t2
GROUP BY t2.id,t2.items
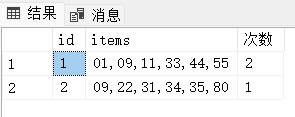
最早期是 charIndex,但是charIndex只能1对多,不能多对多,数据入库的时候都是逗号分隔,charindex只能where charindex(','+33+',',items)>0 吧?
我我我我第一次领这么大红包,我我我我

SELECT
id,
(LENGTH(items) - LENGTH(REPLACE(items, '09', '')))/(LENGTH('09')) AS count_09,
(LENGTH(items) - LENGTH(REPLACE(items, '33', '')))/(LENGTH('33')) AS count_33
FROM myTable
WHERE FIND_IN_SET('09', items) > 0 OR FIND_IN_SET('33', items) > 0;
不考虑效率的话,两个like

