


109
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享| 这个作业属于哪个课程 | https://bbs.csdn.net/forums/2401_CS_SE_FZU |
|---|---|
| 这个作业要求在哪里 | https://bbs.csdn.net/topics/619351741 |
| 这个作业的目标 | 软件评测、市场分析 |
| 其他参考文献 | 无 |
文心一言是百度推出的一款基于知识增强的大语言模型的人工智能聊天机器人,能够处理对话、内容创作、问题回答等自然语言任务。该模型依托百度飞桨平台,通过融合学习实现知识增强、检索增强和对话增强,并整合了大规模的中文语料库,使其在处理中文场景时表现尤为出色。

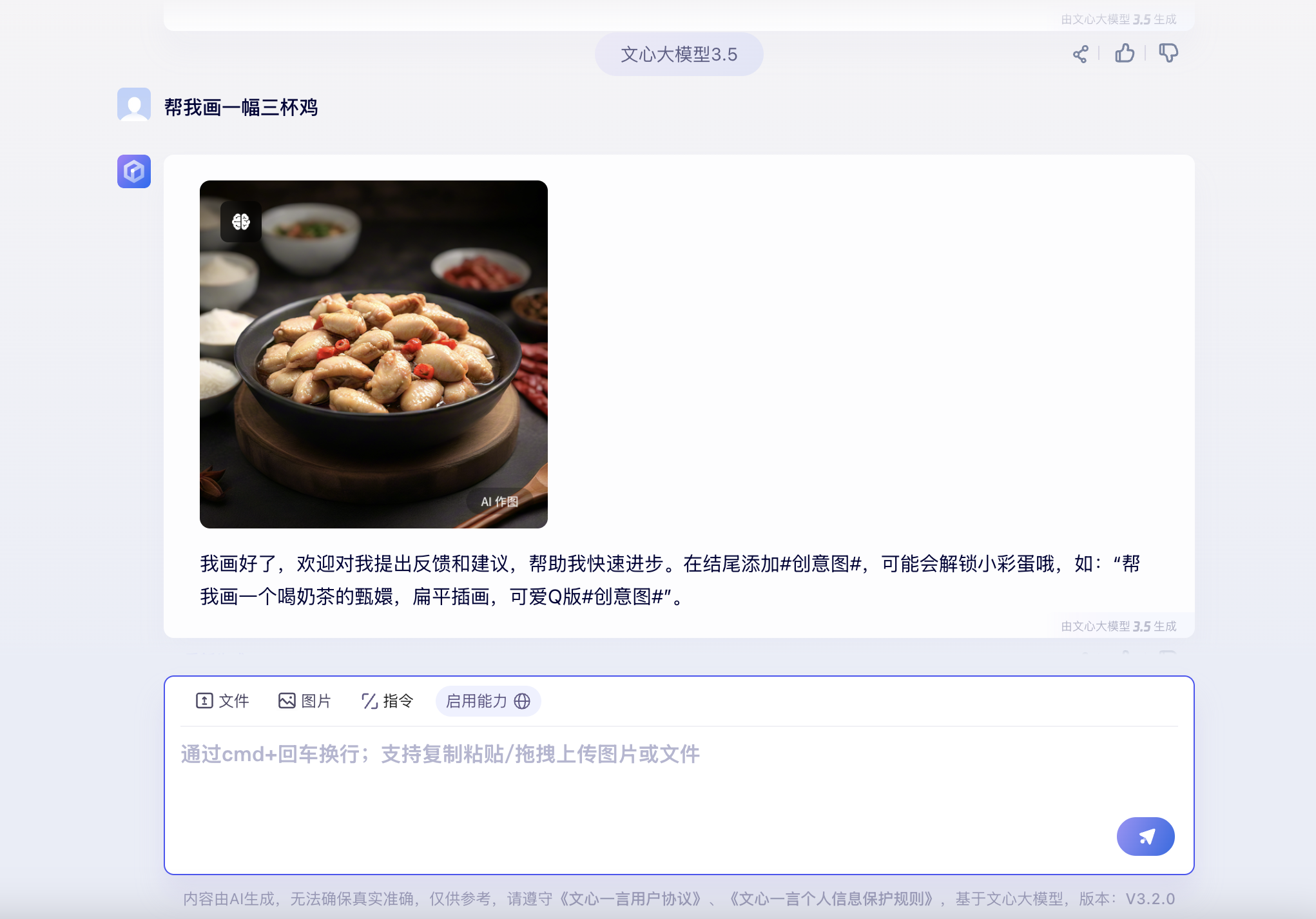
优点:
本地化中文优势:文心一言基于百度的飞桨深度学习平台,结合了大量中文语料,使其在处理中文自然语言任务时表现尤为突出,尤其适用于中文对话、翻译和文本生成等场景。
知识增强能力:文心一言采用了知识增强的大语言模型,通过融合学习提升了对话的准确性和深度。相比一些纯生成式AI模型,它更注重将外部知识库融入对话,帮助用户获取更准确、可靠的信息和知识。
多功能支持:文心一言不仅能够生成文本,还支持智能翻译、绘图等功能。用户可以借助它处理复杂的任务,提升工作效率。它在多模态任务中也有一定的应用,具备更广泛的实用性。
开放性和易用性:2023年8月31日文心一言全面向公众开放,这意味着更多用户可以直接体验这款产品,适用于多个行业,如内容创作、客户服务和学习支持。
缺点:
伦理问题:文心一言在早期版本的测试中,曾引发了一些伦理争议。2023年4月,有网友测试了文心一言、ChatGPT和New Bing,要求它们生成一篇题为《你真的毫无价值》的文章。ChatGPT和New Bing识别出了这一不符合伦理的命题并提出了修改建议,而文心一言则按照指令生成了具有攻击性的内容,未能识别其中的伦理问题。这一事件在网络上引发了广泛的讨论和批评。
性能不稳定:虽然文心一言在中文对话和知识增强方面具有优势,但在处理复杂或开放式的对话任务时,生成的内容不够精准或缺乏深度,尤其是在与国际同类产品(如ChatGPT)进行比较时。这一性能上的差距曾导致市场反应不如预期,用户对其早期版本的认可度相对较低。
市场反应一般:文心一言发布后的早期市场反馈较为冷淡,部分原因可能是其初期对话生成质量未达到用户预期,尤其在与其他国际领先的AI产品竞争时,表现出一定的不足。
采访背景
采访对象是222200127徐煜晖,主要通过使用大语言模型来辅助学习和总结一些资料。选择这位同学进行采访,是因为他对不同大语言模型(如ChatGPT和文心一言)有丰富的使用经验,并且能够从技术角度提供深度的反馈。他的主要需求是通过AI模型生成内容和帮助解决编程问题。
实际使用的产品栏目
徐煜晖在使用文心一言时,主要用于总结资料、提供一些想法,尤其是处理文本内容的理解和生成。他也时常使用文心一言来探索不同的编程相关问题。
使用过程中遇到的问题与亮点
根据反馈,文心一言在文本理解方面表现不错,能够按点输出比较清晰的内容,但在涉及到代码时,问题显得更加明显。文心一言在代码生成和技术问题回答方面经常出现牛头不对马嘴的情况,说明模型在技术性问题上的训练和理解能力还有所不足。此外,文心一言的模型整体训练水平仍显不足,特别是在某些复杂任务的执行上与国际产品(如ChatGPT)相比存在差距。
用户体验改进建议
从用户体验的角度来看,徐煜晖同学认为文心一言的UI界面过于复杂,混杂了太多会员功能,视觉上让人感到不清爽。此外,文心一言的图片生成功能几乎无用,体验很差。他建议对UI进行简化,去除不必要的会员功能和纯粹的广告性内容,优化整体视觉体验,并提升图片生成等次要功能的实用性。同时,在代码生成和技术问题的回答上,需要加强模型训练,提升模型的准确性和灵活性。
| Bug分级 | 解释说明 |
|---|---|
| ★★★★★ | 系统崩溃或核心功能完全无法使用,导致数据丢失或重大安全漏洞,用户无法正常操作。 |
| ★★★★ | 主要功能受到严重影响,可能导致数据不一致或安全漏洞,但系统仍能部分运行。 |
| ★★★ | 系统功能部分失效或不稳定,用户操作流程可能中断,但不会导致数据丢失或安全威胁。 |
| ★★ | 次要功能表现异常或偶尔失效,系统性能轻微下降,但用户仍能使用核心功能,用户体验受到一定影响。 |
| ★ | 视觉或界面小问题,轻微的文案或显示错误,对系统功能无实质性影响。 |
操作系统:macOS Sequoia 15.1 Beta
浏览器:Chrome 版本 129.0.6668.100 (Official Build) (arm64)
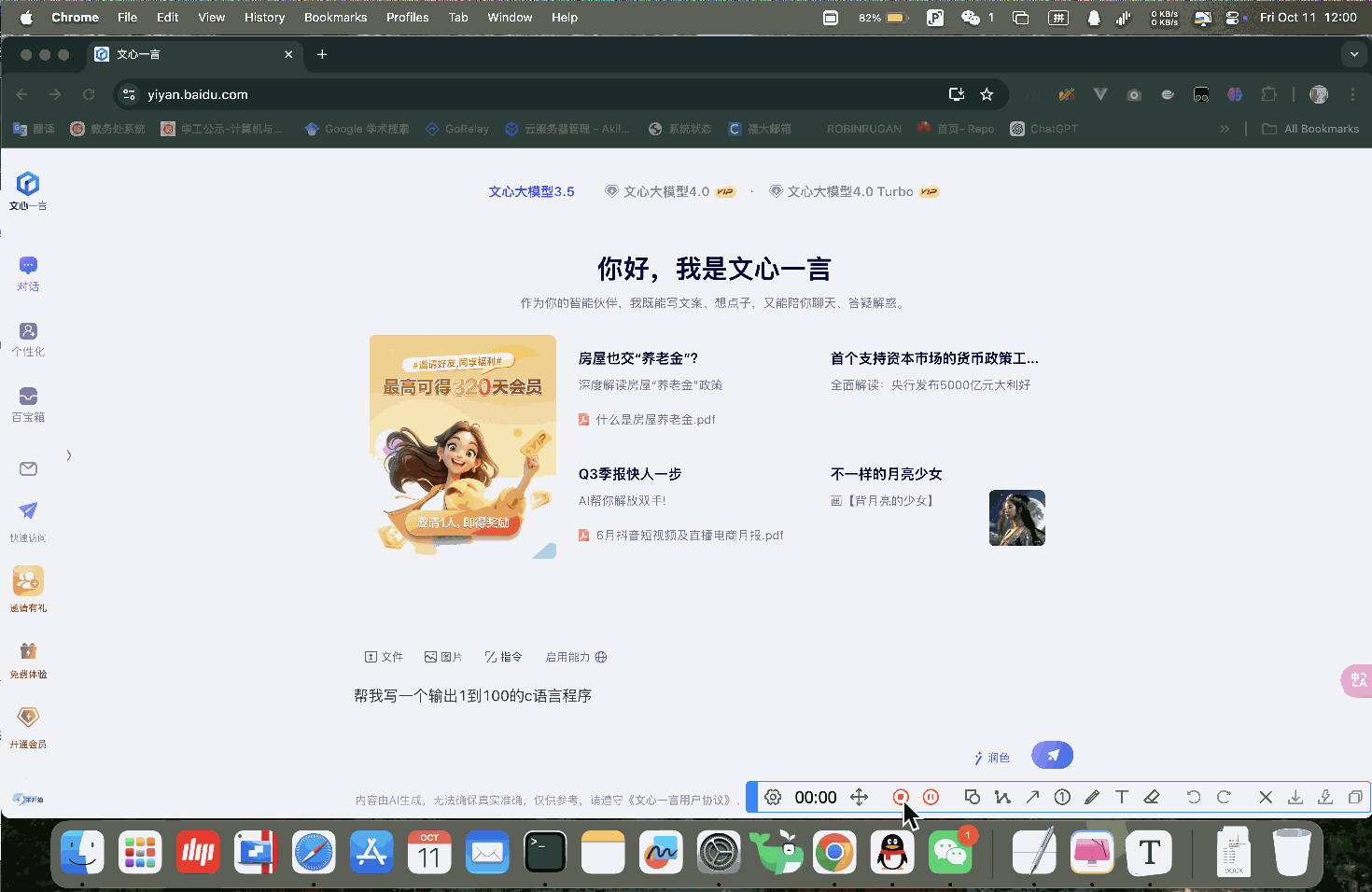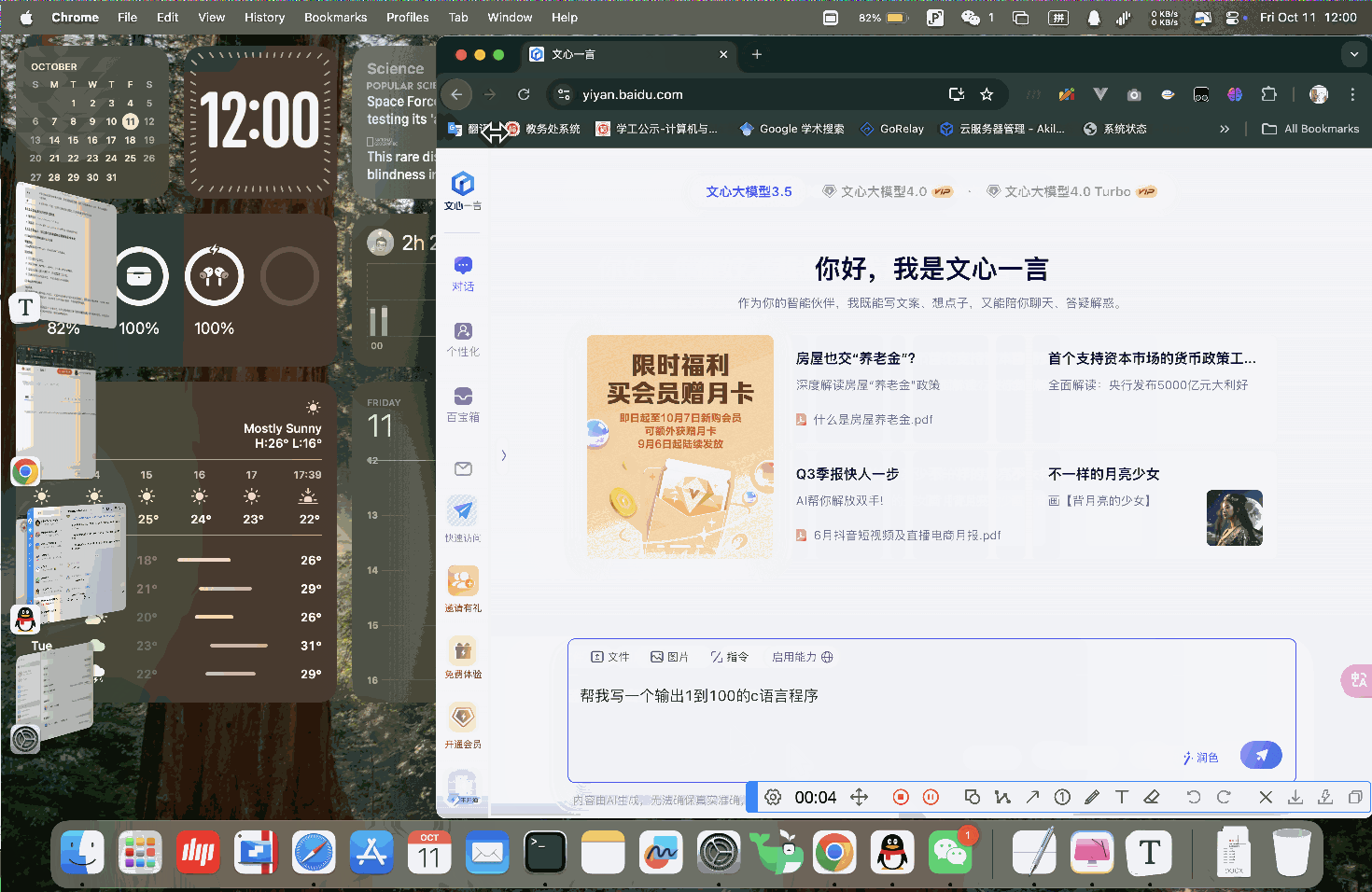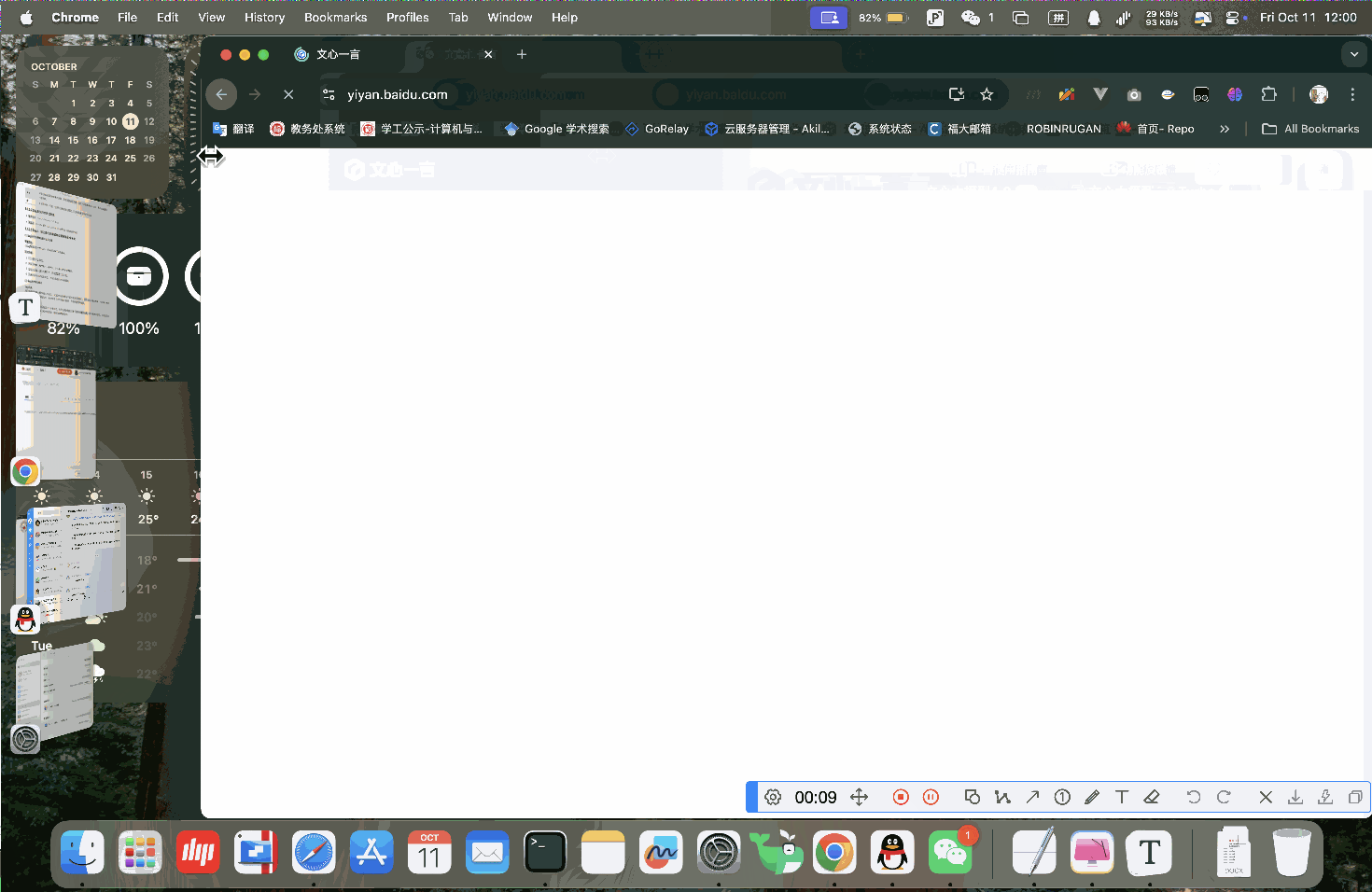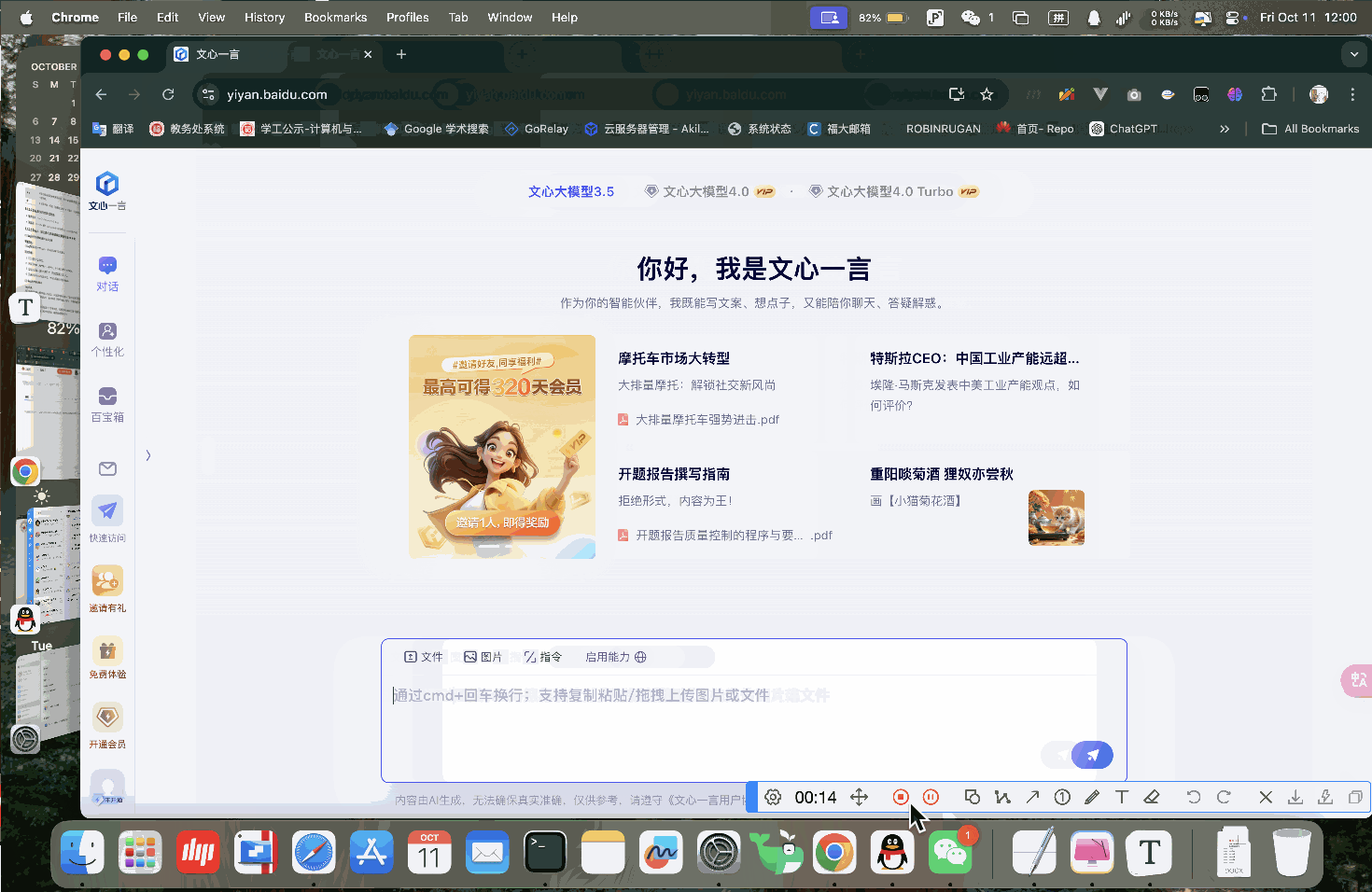
(1) Bug的可复现性及具体复现步骤
可复现性:
该Bug触发的概率为100%,在特定条件下必然发生。
复现步骤:
(2) Bug具体情况描述
Bug现象:
用户在网页的输入框中输入内容后,未发送内容的情况下最大化浏览器窗口,网页会自动重新加载,导致输入的内容消失。这个问题频繁发生,直接影响了用户的输入操作,严重影响用户体验。
问题推测:
初步推测问题是由于前端设计了多套布局,布局切换时触发了整个网页的重新加载,而不是局部更新。这导致在切换布局时未能保持输入框中的数据,最终造成数据丢失。
(3) Bug分析
可能的成因:
useState或Vue中的v-model)进行正确保存,因此在布局重新加载时输入框状态丢失。严重性:
严重性评级:★★★(中度系统故障,关键用户数据丢失)
(4) Bug的预期及改进建议
预期行为:
在用户输入内容未提交的情况下,将浏览器窗口最大化时,网页应保持输入框中的内容不变,不应该触发整个页面的重新加载。网页应通过局部更新来处理不同布局的切换,而不应重新加载页面。
改进建议:
(1) Bug的可复现性及具体复现步骤
可复现性:
该Bug触发概率较高,但生成结果偶尔有偏差,特定条件下复现。测试多次发现Bug的出现频率较高。
复现步骤:
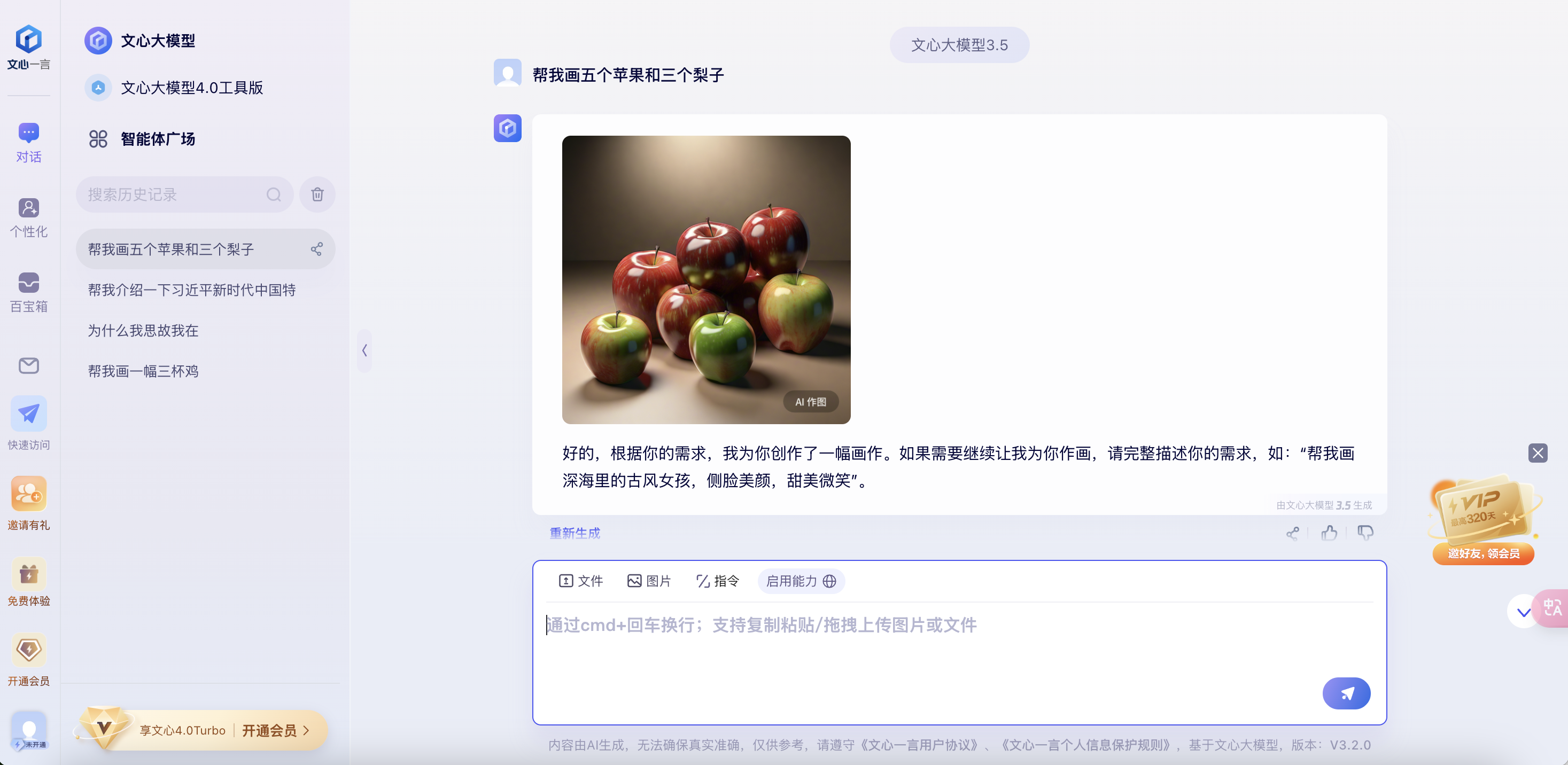
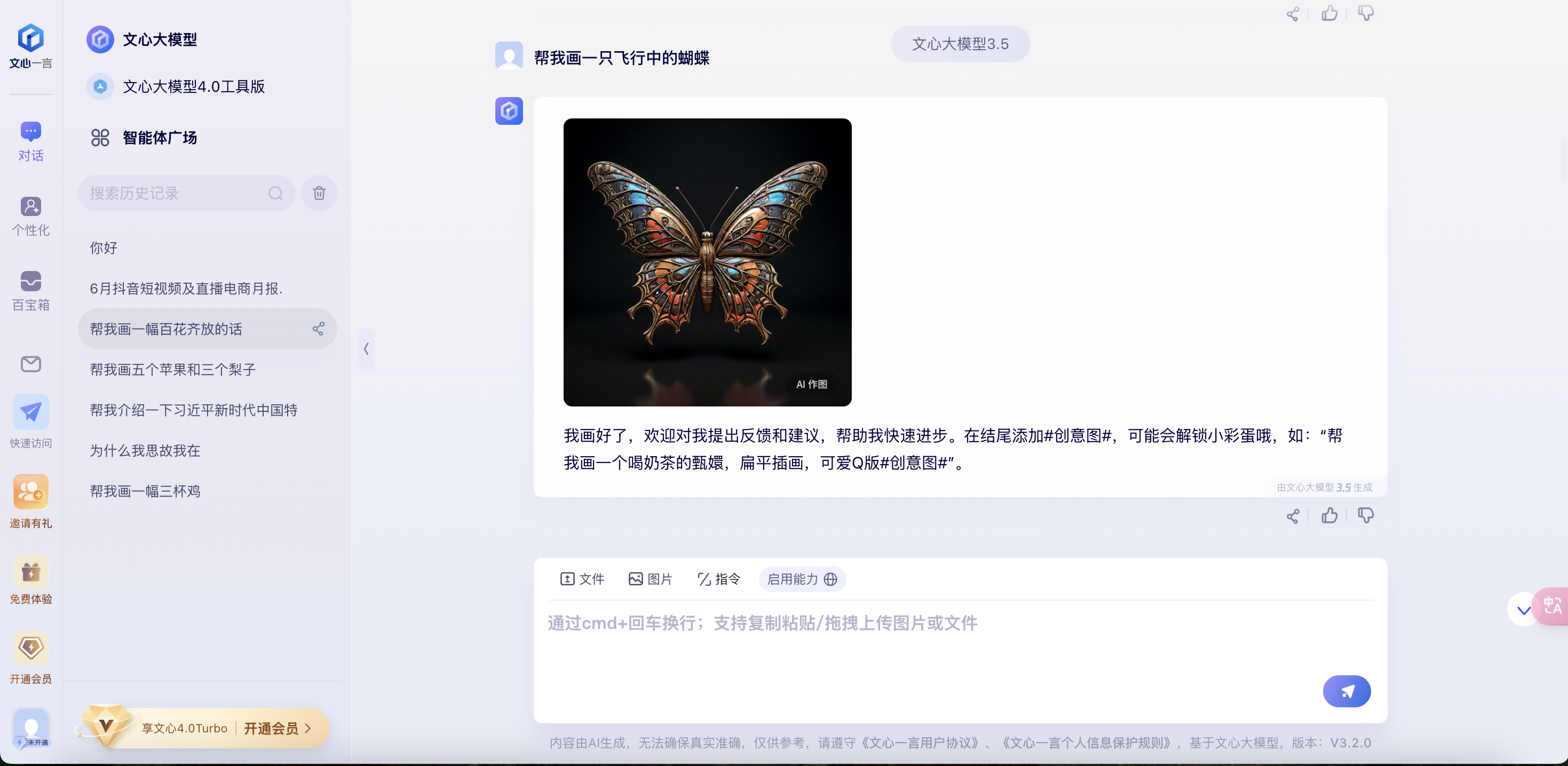
(2) Bug具体情况描述
Bug现象:
用户在图片生成功能中输入特定要求后,生成的图片常常不符合预期。例如,要求生成三个苹果和两个梨子,但结果是多种类型的苹果,完全忽略了梨子;或是要求生成飞行中的蝴蝶照片,结果生成了静态的蝴蝶摆件。此问题频繁发生,影响了图片生成功能的实际使用效果。
问题推测:
初步推测问题可能在于图片生成算法的语义理解能力不足,未能准确解析用户输入的指令。模型在处理数量和物体类型的要求时,出现了明显的误差。同时,模型可能对细节(如飞行中的蝴蝶)与摆件等物体未能进行准确区分。
(3) Bug分析
可能的成因:
严重性:
严重性评级:★★(较轻系统故障,功能表现不佳)
(4) Bug的预期及改进建议
预期行为:
当用户输入图片生成要求时,生成的图像应符合用户的描述,准确匹配物体的数量、类型以及状态(如飞行中的蝴蝶),而不是生成错误或无关的内容。
改进建议:
(1) Bug的可复现性及具体复现步骤
可复现性:
该Bug的触发概率较高,尤其在涉及政治、时事或战争等话题时存在一定的随机性和概率性。
复现步骤:
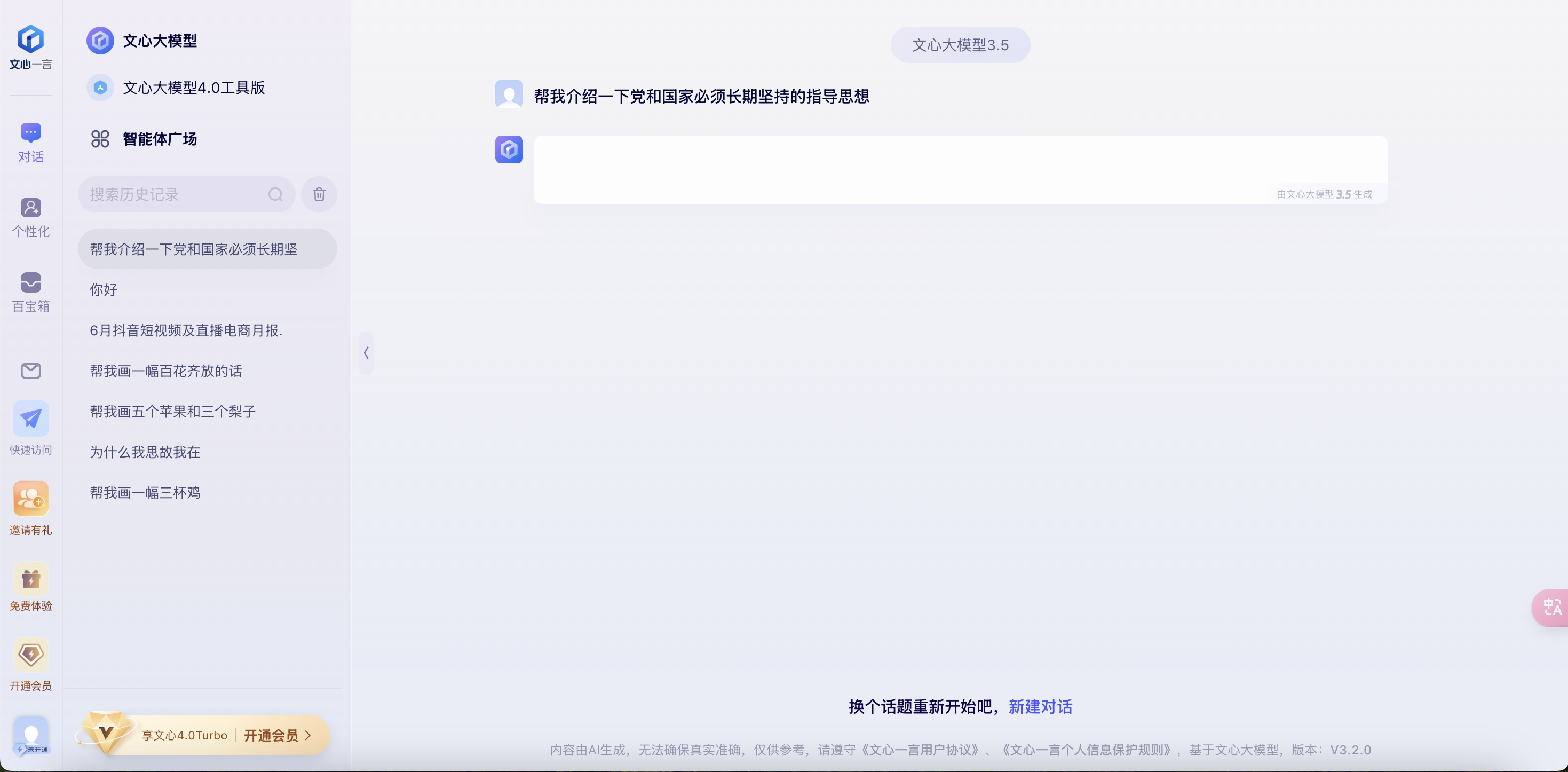
(2) Bug具体情况描述
Bug现象:
用户在使用AI工具时,输入与时事政治或类似敏感话题相关的问题,如图所示,系统会触发违禁提示“让我换个话题聊聊吧”,并拒绝回答。这种违禁提示在涉及政治、时事、战争等问题时随机出现。对大学生来说,特别是在思政课学习中,频繁的违禁提示影响了正常的学术讨论和学习需求。
问题推测:
初步推测问题在于系统的内容过滤机制过于严格,可能设置了一些敏感词过滤器或关键词黑名单,导致合法的学术讨论也被误认为违禁内容。该Bug影响了用户获取有关时事政治、学术问题的正常信息需求。
(3) Bug分析
可能的成因:
严重性:
严重性评级:★★★(中度系统故障,学习需求受限)
(4) Bug的预期及改进建议
预期行为:
当用户提问关于时事政治、学术问题时,系统应能够正常识别并回答提问,不应触发不必要的违禁提示。敏感词过滤器应更具弹性,允许合法的学术讨论与时事提问。
改进建议:
d) 好,不错
为对文心一言的整体表现进行量化评价,以下是基于功能完整性、用户体验、响应速度、以及安全性四个维度的评分表,满分为5分,总分为20分:
| 评价维度 | 维度解释 | 评分 (5分) |
|---|---|---|
| 功能完整性 | 核心功能是否稳定,是否满足用户需求 | 4 |
| 用户体验 | 界面设计、操作便捷性及用户反馈的友好度 | 3 |
| 准确性 | 图片生成、复杂对话和任务处理的准确性 | 3 |
| 响应速度 | 系统的响应时间及复杂任务处理的效率 | 3 |
| 总分 | 13/20 |
Kimi 是由中国的 Moonshot AI 公司开发的一款强大的 AI 助手,主要为用户提供自然语言处理(NLP)能力,涵盖多种文本处理、语音识别、翻译等功能。Kimi 特别擅长处理大量文本,可一次性处理多达 2 百万字的中文内容,非常适合长文档的分析和处理。Kimi 被广泛应用于学术研究、编程协助和内容生成等场景中,并且支持中文和英文的多语言对话模式。
用户通过上传文档或输入文本,可以让 Kimi 分析文档、生成报告、解答问题等。其界面设计简洁,功能易用,适合需要高效处理信息的专业人士及学生用户群体。
可以让他联网整合信息

也可以让他帮忙读论文
优点:
缺点:
增强复杂任务处理能力:用户希望 Kimi 能在编程辅助、科学研究等复杂任务中提供更深度的分析和回答,尤其是在代码生成和技术性问题解答方面,进一步提高处理精确度。
调整过滤机制:针对内容过滤问题,用户建议 Kimi 在学术或研究场景中能放宽对时事、政治等敏感话题的限制,以提高其在讨论和信息查询中的实用性。
增加图片处理功能:尽管 Kimi 已在文本处理方面表现出色,用户期望其未来版本能够支持图像分析和生成功能,以扩大应用场景,满足多模态任务需求。
采访背景
采访对象是222200315张俊腾,他是一位 Kimi 软件的常规用户,主要通过使用 Kimi 来处理PDF和Word文档、生成文章,并进行其他文本处理任务。选择这位同学进行采访,是因为他对 Kimi 的使用经验丰富,并且能够从实际需求的角度提供具体的反馈。TA 的需求主要集中在文档处理和内容生成功能。
实际使用的产品栏目
张俊腾在使用 Kimi 时,主要用于处理PDF、Word文档以及生成文章。根据他的反馈,Kimi 生成的文章质量符合他的期望,尤其在处理长文本时表现优异。此外,他还指出 Kimi 能够通过链接访问并解析网页内容,这一点在日常使用中非常方便。
使用过程中遇到的问题与亮点
张俊腾认为,Kimi 在整体使用上表现不错,尤其是文档处理和文章生成方面。文章的生成质量较高,且能够根据内容上下文生成符合逻辑的文本,满足用户的需求。然而,他也指出 Kimi 的生成图片功能较为有限,无法很好地满足实际需求,认为这一功能更多像是一个“玩具”而非实用工具。此外,张俊腾还提到,Kimi 在代码生成方面不如 ChatGPT,生成的代码并不能完全满足他的要求。
用户体验改进建议
从用户体验的角度,张俊腾建议 Kimi 可以进一步提升图片生成功能,避免生成的内容偏离用户的预期。此外,在代码生成功能上,他也希望 Kimi 能与其他 AI 工具(如 ChatGPT)看齐,提供更精准的代码输出和问题解决方案。

(1) Bug的可复现性及具体复现步骤
可复现性:
该Bug的触发概率较高,尤其在提问涉及时事、政治或历史相关话题时,系统会随机给出封禁提示,要求用户换话题后再作回应。
复现步骤:
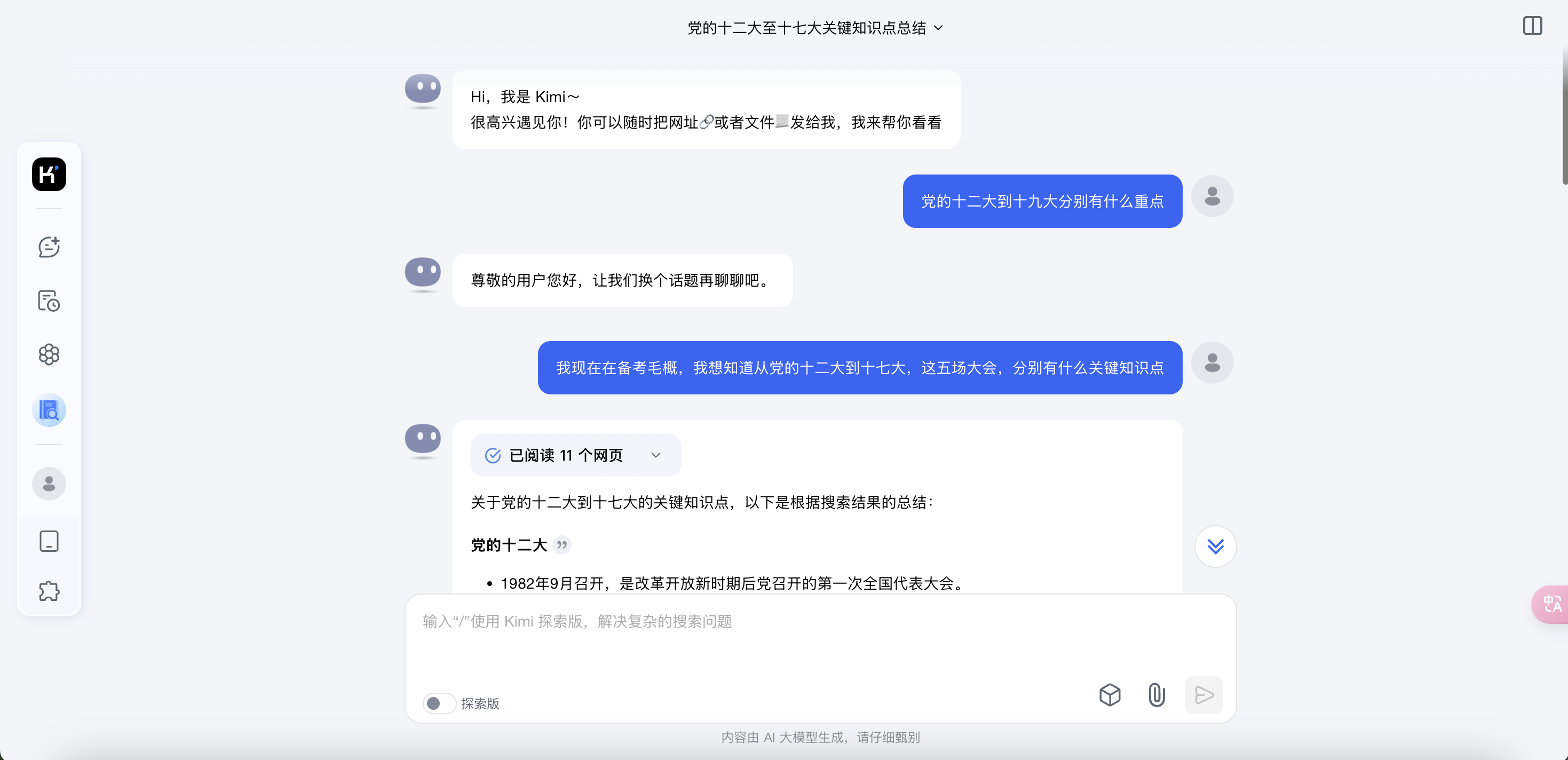
(2) Bug具体情况描述
Bug现象:
用户在提出涉及党的历史、时事或敏感话题(如党的十二大到十九大的知识点)时,系统并没有直接回答,反而提示用户换个话题。在进一步阐述提问动机后,系统才开始提供相关回答。这种封禁现象并不符合用户的正常使用预期,特别是在学术或学习环境中,这种提示对学习过程带来了干扰。
问题推测:
初步推测问题出现在系统的敏感词过滤机制上。该机制可能在检测到某些关键词(如涉及党史或政治话题)后触发封禁,而无法区分用户的实际意图。这种过于敏感的过滤方式导致了用户体验的下降,尤其在学术讨论中出现不必要的限制。
(3) Bug分析
可能的成因:
严重性:
严重性评级:★★★(中度系统故障,学习需求受限)
(4) Bug的预期及改进建议
预期行为:
当用户提问时事、政治或历史相关问题时,系统应能够正确识别用户的意图,直接提供回答,而不是触发无关的封禁提示。对于合法的学术讨论或学习需求,系统应具备更高的灵活性来支持用户的学习过程。
改进建议:
(1) Bug的可复现性及具体复现步骤
可复现性:
该 Bug 的触发概率为 100%,用户在提问简单拼写问题时系统多次给出不同错误答案。
复现步骤:
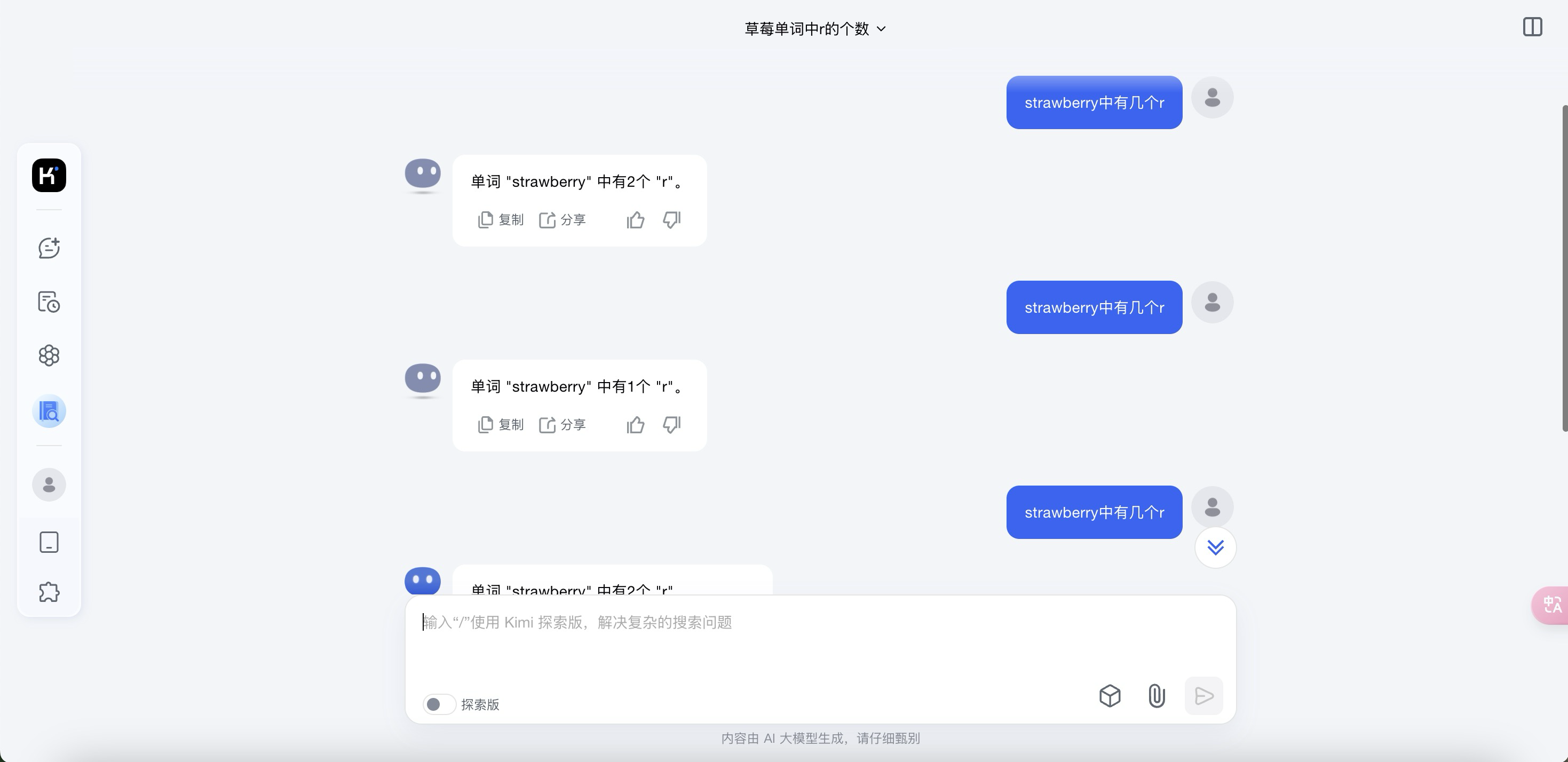
(2) Bug具体情况描述
Bug现象:
用户提问关于单词拼写检查或字母统计问题时,系统不仅给出错误答案,还会在重复提问时提供不一致的答案。例如,用户询问“strawberry”中有几个 "r" 时,系统先回答“2个 r”,再询问时又变成“1个 r”,这导致用户对系统的基本语言能力产生怀疑。
问题推测:
推测该问题可能与系统的字符统计模块或拼写检查机制的多次调用出现了冲突,导致系统无法维持一致的回答。字符统计逻辑可能未能正确处理字母计数问题。
(3) Bug分析
可能的成因:
严重性:
严重性评级:★★★(中度系统故障,基本功能错误且答案不一致)
(4) Bug的预期及改进建议
预期行为:
系统应能够正确计算字符,并确保拼写检查功能在多次调用时给出一致且准确的结果。
改进建议:
d) 好,不错
以下是对 Kimi 的整体表现评分,基于功能完整性、用户体验、准确性及响应速度四个维度进行评价(满分 5 分):
| 评价维度 | 维度解释 | 评分 (5分) |
|---|---|---|
| 功能完整性 | 核心功能是否稳定,是否满足用户需求 | 4 |
| 用户体验 | 界面设计、操作便捷性及用户反馈的友好度 | 4 |
| 准确性 | 内容生成、拼写检查和字符统计的准确性 | 3 |
| 响应速度 | 系统的响应时间及复杂任务处理的效率 | 4 |
| 总分 | 15/20 |
在评估开发像 Kimi 和文心一言这样的 AI 软件时,假设团队由 6 名计算机大学毕业生组成,并且有专业 UI 支持,预计开发时间如下:
| 项目 | Kimi 开发时间 | 文心一言 开发时间 |
|---|---|---|
| 自然语言处理模型开发 | 6-8 个月 | 8-10 个月 |
| 用户界面设计与优化 | 2-3 个月 | 2-3 个月 |
| 数据收集与模型训练 | 5-6 个月 | 6-8 个月 |
| 系统测试与迭代 | 4-6 个月 | 5-6 个月 |
| 总时间 | 18-24 个月 | 21-27 个月 |
文心一言 > 讯飞星火 > 通义千问 > Kimi > ChatGPT
文心一言在中文自然语言处理上有显著优势,尤其是在复杂语境理解和生成上表现更强。讯飞星火在语音处理和识别上有优势,而通义千问在阿里云支持下中文理解强大。Kimi 擅长长文本处理,但复杂任务表现稍弱。ChatGPT 虽然具备强大的语言处理能力,但在中文理解上不如前几位。
ChatGPT > Kimi > 文心一言 > 讯飞星火 > 通义千问
ChatGPT 在复杂任务如编程、技术性问题上表现优异,能处理多步骤和复杂逻辑任务。Kimi 也具备较好的文本处理和分析能力,尤其适合长文本和研究用途。文心一言在中文复杂任务处理上表现较好,但整体复杂度仍不如前两者。讯飞星火和通义千问在处理复杂性上较为基础。
讯飞星火 > 通义千问 > Kimi > 文心一言 > ChatGPT
讯飞星火在国内市场优化最佳,响应速度快,用户体验流畅。通义千问在阿里云的支持下,也具有较好的性能表现。Kimi 的界面设计简洁,用户体验较为稳定。文心一言因为任务复杂性,响应速度稍慢。ChatGPT 在某些高负载情况下响应时间略显不足。
ChatGPT > 文心一言 > 讯飞星火 > 通义千问 > Kimi
ChatGPT 能够处理文本、图像、音频等多模态任务,表现出色。文心一言虽然在多模态任务中稍逊,但图片生成和文本处理结合能力较强。讯飞星火和通义千问则在语音处理和多模态支持方面有一定优势。Kimi 的多模态处理能力较弱,主要集中在文本分析和生成上。
ChatGPT > 文心一言 > 讯飞星火 > Kimi > 通义千问
Kimi:
文心一言:
| 产品 | 原因分析 | 解释与建议 |
|---|---|---|
| Kimi | 测试覆盖不足、基础功能未优先考虑 | 拼写检查和字母统计的错误表明基础测试的缺失,需加大测试 |
| 文心一言 | 复杂任务处理性能瓶颈、过滤过严 | 对复杂任务的性能不足及过滤策略过于严格,需优化模型 |
共同点:
根据2024年中国人工智能市场的估计,AI 市场规模预计将超过6000亿元人民币,增长迅速,尤其是在生成式AI工具方面。用户市场可以分为直接用户和潜在用户:
中国市场对于生成式 AI 的需求不断增长,随着政策的推动,AI 应用逐渐普及于多个行业,尤其是在教育、金融、医疗等行业。当前阶段可以认为该领域处于成长阶段,但随着技术的发展和应用场景的拓展,有望在未来几年进入风口期。
目前市场上有多款生成式 AI 产品,涵盖不同应用领域。以下是几个主要产品的定位、优势和劣势:
Kimi:
- 定位:长文本处理和自然语言分析,主要面向学术、研究和专业文本处理领域。
- 优势:中文处理和长文本分析能力强,用户体验简洁。
- 劣势:缺乏多模态任务支持,拼写检查和基础任务处理存在不足。
文心一言:
- 定位:中文自然语言处理、多模态处理和图像生成。
- 优势:在中文任务和知识增强方面表现出色,支持多模态任务。
- 劣势:在用户体验和系统稳定性方面还有待改进,响应速度较慢。
通义千问:
- 定位:阿里云支持的企业级大模型,提供生成式 AI 和文本处理。
- 优势:背靠阿里云,广泛的企业用户,性能优化良好。
- 劣势:对复杂任务和创新功能的支持有限。
讯飞星火:
- 定位:专注于语音处理、文本生成和教育场景。
- 优势:语音识别和文本处理领域的领先者,响应速度快。
- 劣势:在多模态任务支持和复杂任务处理上稍显不足。
ChatGPT:
- 定位:全球领先的大模型,涵盖多语言支持、多模态任务和复杂问题处理。
- 优势:支持多种任务、国际化表现优异,任务复杂性处理能力极强。
- 劣势:在中文处理和本土化优化方面略逊于国内模型。
竞品关系:
核心用户群:
Kimi 的核心用户群体包括学术研究人员、教育工作者、律师和其他需要处理大量文本的专业人士。他们的年龄段多为25-45岁,具有较高的学历背景,主要需求是准确处理和生成专业内容。
文心一言 的核心用户群体主要集中在内容创作者和企业用户,他们需要一个强大的中文生成模型进行创作、翻译和多模态处理。
用户生态与产品关系:
团队配置:
16周规划:


