


574
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享主讲老师:段普
学习链接:【隐私计算实训营 第4期】理论基础:匿踪查询PIR 第2讲哔哩哔哩bilibili
Private Information Retrieval (PIR) 是一种加密协议,旨在允许客户端从服务器的数据集中检索特定数据项,同时确保服务器无法得知客户端查询的具体内容。PIR 的核心目标是在保护用户隐私的同时,实现高效的数据访问。
首次引入 :PIR 概念最早由 [1] 提出,旨在解决在不泄露查询信息的情况下,从服务器获取所需数据的问题。
系统组成
服务器(Server): 持有一个大型数据集。
客户端(Client): 拥有一个查询请求,想要检索数据集中的特定项。
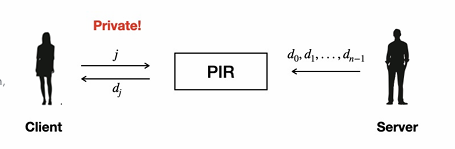
工作流程
查询发起: 客户端生成一个查询请求,旨在检索数据集中某个特定的数据项。
数据检索: 通过 PIR 协议,客户端能够从服务器检索到所需的数据项。
隐私保护: 在整个过程中,服务器无法识别出客户端具体查询的是哪一项数据。
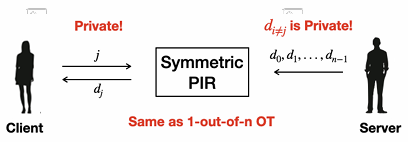
隐私属性
服务器端隐私保护: 服务器无法确定客户端检索了数据集中的哪一项。这意味着,服务器无法通过观察查询请求或通信模式来推断出客户端的兴趣点。
客户端隐私保护: 客户端只能获取到其查询的数据项,无法访问或推断出数据集中其他未查询的数据项。这确保了数据集的其他部分对客户端保持隐私。
信息理论安全(Information Theoretic Security)[1]
计算能力无限的对手(Computationally Unbounded Adversary):在这种模型下,对手拥有无限的计算资源,PIR协议必须在信息层面上保证隐私,不依赖于计算复杂性假设。
计算型PIR(Computational PIR)[2,3,4,5,6,7]
计算能力有限的对手(Computationally Bounded Adversary):假设对手的计算能力是有限的,PIR协议可以利用计算复杂性假设(如难以破解的数学问题)来保证隐私。
单服务器PIR(Single-server PIR)[3,4,5,6,7,8]
优点:更适合实际应用的实现,因为只需与一个服务器交互。
缺点:可能需要依赖较为复杂的加密原语,如全同态加密(FHE),这在计算和存储上可能较为昂贵。
双服务器PIR(Two-server PIR)[2,9,11]
优点:可以利用分布式点函数(DPF)等加密原语,提高效率。
缺点:在实际应用中实现较为困难,因为需要多个独立的服务器协作,且服务器之间需要严格的信任假设。
索引型PIR(Index PIR)[7]
特点:客户端知道所需数据的位置(索引),因此可以直接请求特定位置的数据。
应用场景:适用于客户端已知具体数据位置的情况,如数据库中已知记录的具体位置。
关键词型PIR(Keyword PIR)[8,10]
特点:客户端通过关键词请求数据,而不事先知道数据的位置。
应用场景:适用于需要基于关键词进行搜索的场景,如搜索引擎或数据库的关键词查询。
单服务器PIR的实现挑战:需要高效的加密技术,如全同态加密(FHE),这可能带来较高的计算和存储开销,限制了其在资源受限环境中的应用。
双服务器PIR的实现优势:通过分布式点函数(DPF)等技术,可以在保持隐私的同时提高效率,但需要多个独立且不互相通信的服务器,增加了实现的复杂性和成本。
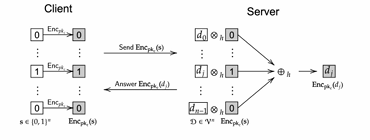
PHE算法(如Paillier加密):使用部分同态加密(PHE)方案,例如Paillier加密,来实现PIR。
优点:实现简单,因为PHE算法相对直接,开发和部署较为容易。
缺点:通信成本高,因为加密后的查询和响应数据量大,需要传输大量密文,导致带宽和延迟开销显著。

基于同态加密(Homomorphic Encryption, HE)的PIR利用同态加密的特性,实现了在加密数据上直接进行计算,从而增强了数据隐私保护。
同态加密(Homomorphic Encryption, HE)
同态加密是一种加密方法,允许在密文上直接执行特定的运算,而无需先将其解密。这意味着可以在保持数据加密状态下进行处理,确保数据在传输和计算过程中的隐私安全。其中,Fan-Vercauteren(FV)方案是一种广泛应用的同态加密方案,支持以下基本运算:
加法(Addition):允许对两个密文进行加法运算,结果仍为密文形式。
明文乘法(Plaintext Multiplication):允许将密文与明文相乘,结果仍为密文。
替换(Substitution):支持在加密数据上进行特定的替换操作。
基于HE的PIR流程
服务器端数据加密:服务器将数据库中的每条数据转换为HE明文(密文)形式,确保数据在存储和处理过程中的安全性。
客户端查询向量创建:客户端根据所需检索数据的索引,创建一个加密的查询向量。该向量设计使得服务器无法获知客户端具体查询了哪些数据。
服务器端计算内积:服务器接收到加密的查询向量后,计算查询向量与HE明文数据库的内积。由于使用同态加密,这一过程在加密状态下完成,保证了数据隐私。
客户端结果解密:服务器将计算结果返回给客户端,客户端使用其私钥解密得到所需的明文结果,实现数据的私密检索。
尽管HE-based PIR在隐私保护方面具有显著优势,但其计算和通信开销较大,限制了其在大规模数据库中的应用。这主要由于同态加密运算的复杂性和加密数据量的庞大所致。
SealPIR:优化的HE-based PIR方案
为了克服传统HE-based PIR的效率瓶颈,SealPIR方案引入了多项优化技术:
多数据包装入单一HE明文:将多个数据项打包到一个HE明文中,减少服务器需要处理的明文数量,优化计算效率。
压缩查询向量:客户端将查询向量压缩为单一密文,服务器接收后进行展开处理。这一方法显著减少了通信开销。
支持多维查询:SealPIR能够处理多维度的查询,允许更复杂的数据检索操作,提高了系统的灵活性和适用性。
利用布谷鸟哈希(Cuckoo Hashing):采用布谷鸟哈希技术,支持同时处理多个查询请求,提高了查询的并行处理能力和系统吞吐量。
通过上述优化,SealPIR能够在拥有百万级数据的数据库上实现秒级查询响应。这使得HE-based PIR在实际应用中变得更加可行,尤其适用于需要高隐私保护且数据量庞大的场景。
分布式点函数(Distributed Point Function, DPF)
分布式点函数是一种密码学工具,允许将一个点函数(在特定点处返回1,其他地方返回0)分解为多个子函数。每个子函数独立地携带部分信息,组合起来可以重构原始点函数,但单独来看无法获取完整信息。这一特性使得DPF非常适合用于构建安全且高效的PIR协议。

基于DPF的PIR流程

两服务器方案:基于DPF的PIR通常采用两服务器方案。客户端生成两个DPF密钥,每个密钥对应一个服务器。这样,两个服务器各自接收到部分查询信息,无法单独推断出完整的查询内容。
数据库复制与非协作服务器:数据库被复制到两台非协作的服务器上。即使其中一台服务器被攻击,另一台服务器的独立性仍然保证了查询的隐私性。
客户端生成查询:客户端根据所需数据的索引,使用DPF生成两个子查询,分别发送给两台服务器。这些子查询确保了每台服务器只能获取到部分查询信息,无法单独重构完整查询。
服务器处理查询:每台服务器根据接收到的子查询,在其数据库中执行局部检索操作,并将结果返回给客户端。
客户端合并结果:客户端接收来自两台服务器的部分结果,通过合并操作恢复出最终的查询结果,实现私密数据检索。
实现挑战
服务器要求: 需要两台非协作的服务器进行数据存储和查询处理,这在实际应用中可能增加了系统的部署和维护成本。
通过新DPF原语提升效率
[1] B. Chor, O. Goldreich, E. Kushilevitz, and M. Sudan. Private information retrieval. FOCS 1995.
[2] B. Chor and N. Gilboa. Computationally private information retrieval. In Proc. of 29th ACM Symposium on Theory of Computing, pages 304–313, 1997.
[3] Eyal Kushilevitz and Rafail Ostrovsky. Replication is not needed: Single database, computationally-private information retrieval. In FOCS, pages 364–373, 1997.
[4] Cachin, C., Micali, S., Stadler, M. Computationally private information retrieval with polylogarithmic communication. In: Stern, J. (ed.) EUROCRYPT 1999. LNCS, vol. 1592, pp. 402–414. Springer, Heidelberg (1999).
[5] X. Yi, M. G. Kaosar, R. Paulet, and E. Bertino, Single-database private information retrieval from fully homomorphic encryption, IEEE Trans. Knowl. Data Eng., vol. 25, no. 5, pp. 1125–1134, May 2013.
[6] C. A. Melchor, J. Barrier, L. Fousse, and M. Killijian. XPIR: Private information retrieval for everyone. PoPETs, 2016(2):155–174, 2016.
[7] Sebastian Angel, Hao Chen, Kim Laine, and Srinath Setty. PIR with Compressed Queries and Amortized Query Processing. In Proc. of S&P. IEEE, 2018, pp. 962–979.
[8] Asra Ali, Tancrède Lepoint, Sarvar Patel, Mariana Raykova, Phillipp Schoppmann, Karn Seth, and Kevin Yeo. Communication-Computation Trade-offs in PIR. IACR Cryptol. ePrint Arch., 2019:1483.
[9] H. Corrigan-Gibbs, D. Kogan, Private Information Retrieval with Sublinear Online Time, in: Proc. 39th Annual International Conference on the Theory and Applications of Cryptographic Techniques, EUROCRYPT, Zagreb, Croatia, 2020, pp. 1–69.
[10] Benny Chor, Niv Gilboa, and Moni Naor. Private information retrieval by keywords. Technical Report TR-CS0917, Dept. of Computer Science, Technion, 1997.
[11] E. Boyle, N. Gilboa, and Y. Ishai. “Function Secret Sharing: Improvements and Extensions”. In: CCS ’16.
secretflow/secretflow: A unified framework for privacy-preserving data analysis and machine learning
PSI
最新PSI
多方PSI
恶意安全PSI
交集可用不可见PSI
DP-PSI PIR
Single-server PIR
Two-server PIR Ø 应用:联合建模 、联邦学习 、 数据分析

