


113,011
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
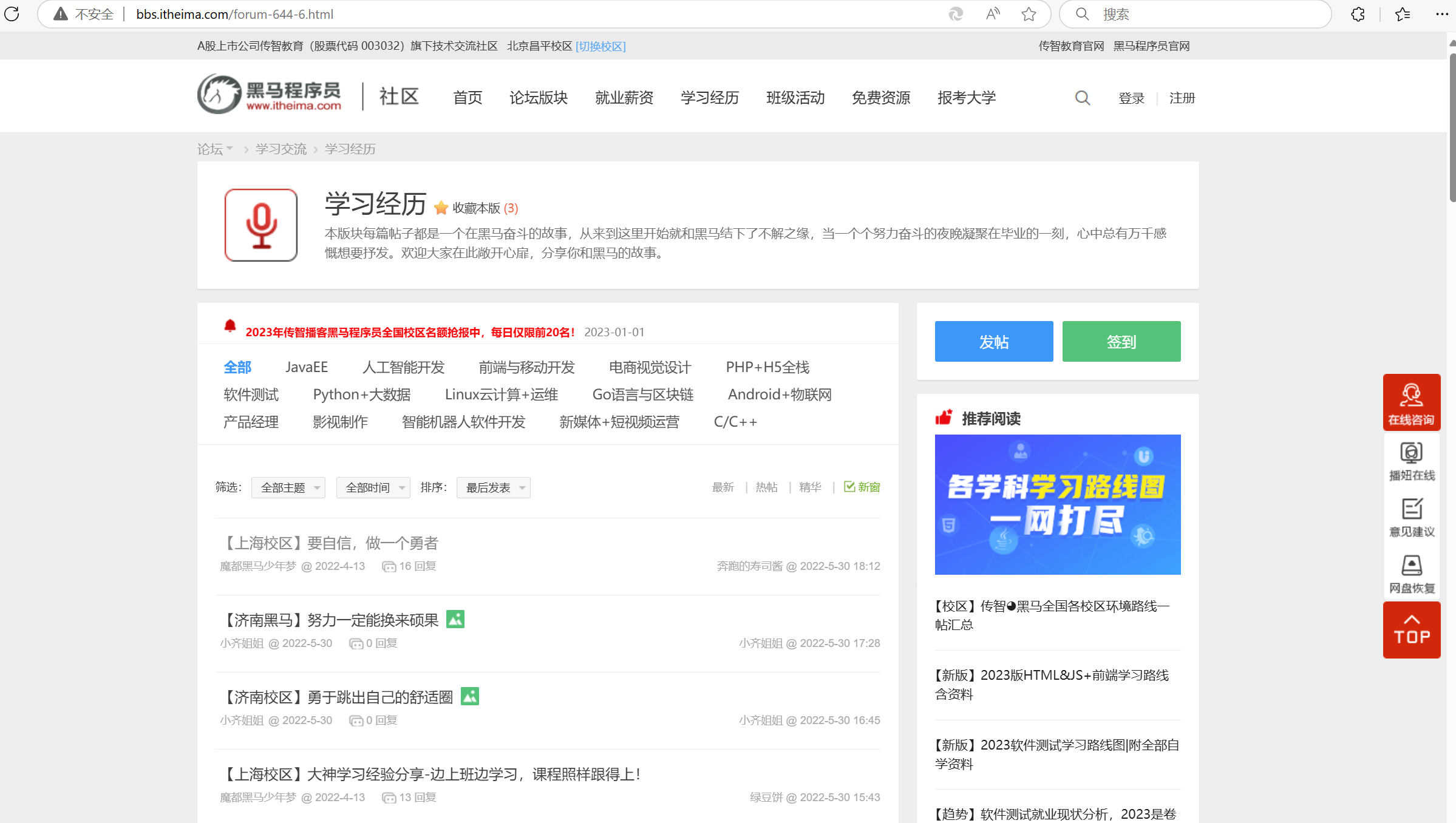
分享通过浏览器搜索黑马程序员论坛(http://bbs.itheima.com/forum-644-6.html),打开Python+人工智能技术交流板块页面(python技术交流论坛),每个帖子都以相同的布局方式显示了详细的信息,包括文章标题、发布时间、文章作者等。通过爬虫技术采集文章的标题、文章的链接、文章作者和发布时间。
Python+人工智能技术交流板块页面:python技术交流论坛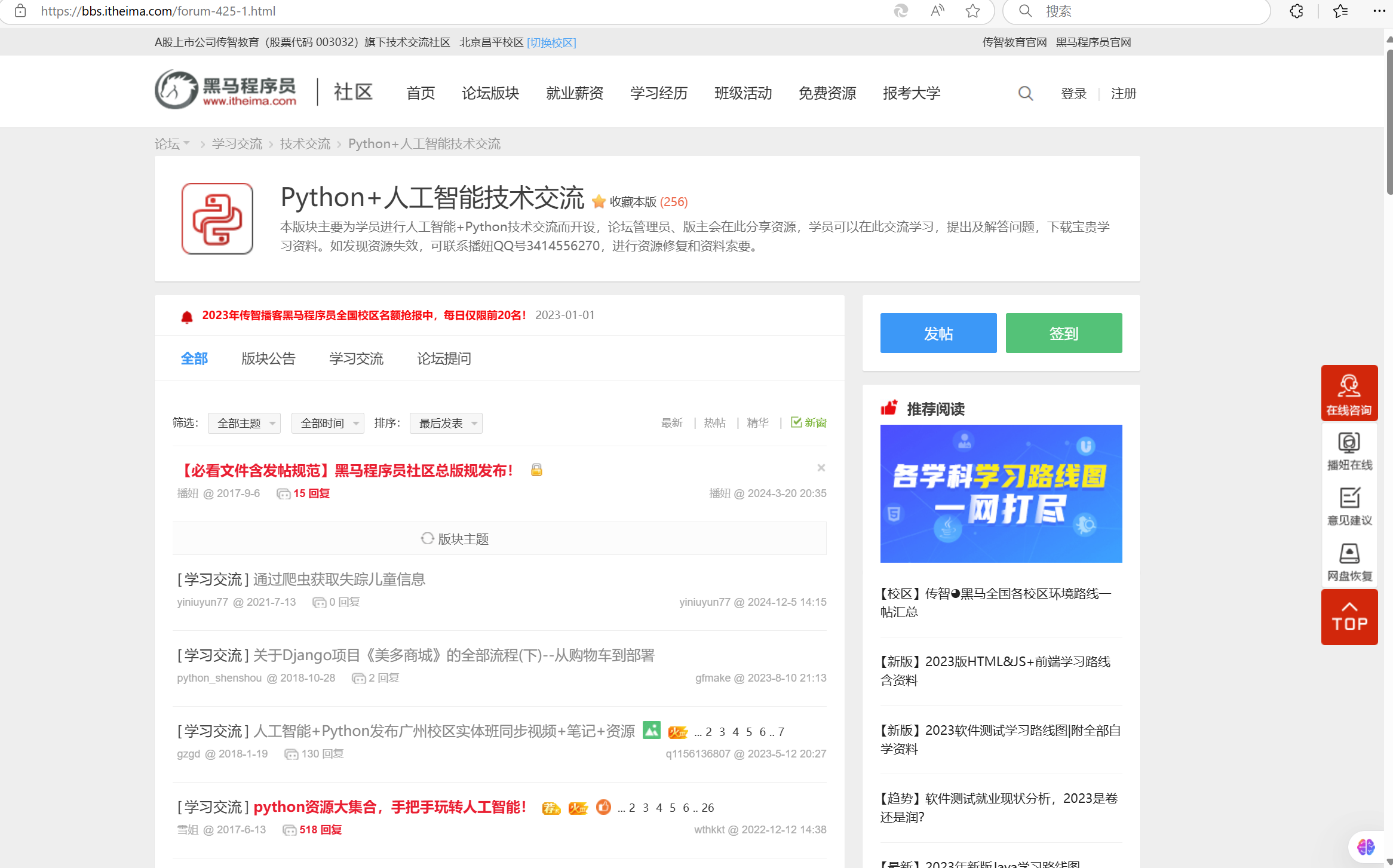
实验要求:
打开Python+人工智能技术交流板块页面,每个帖子都以相同的布局方式显示了详细的信息,包括文章标题、发布时间、文章作者等。通过爬虫技术采集文章的标题、文章的链接、文章作者和发布时间。
总体代码:
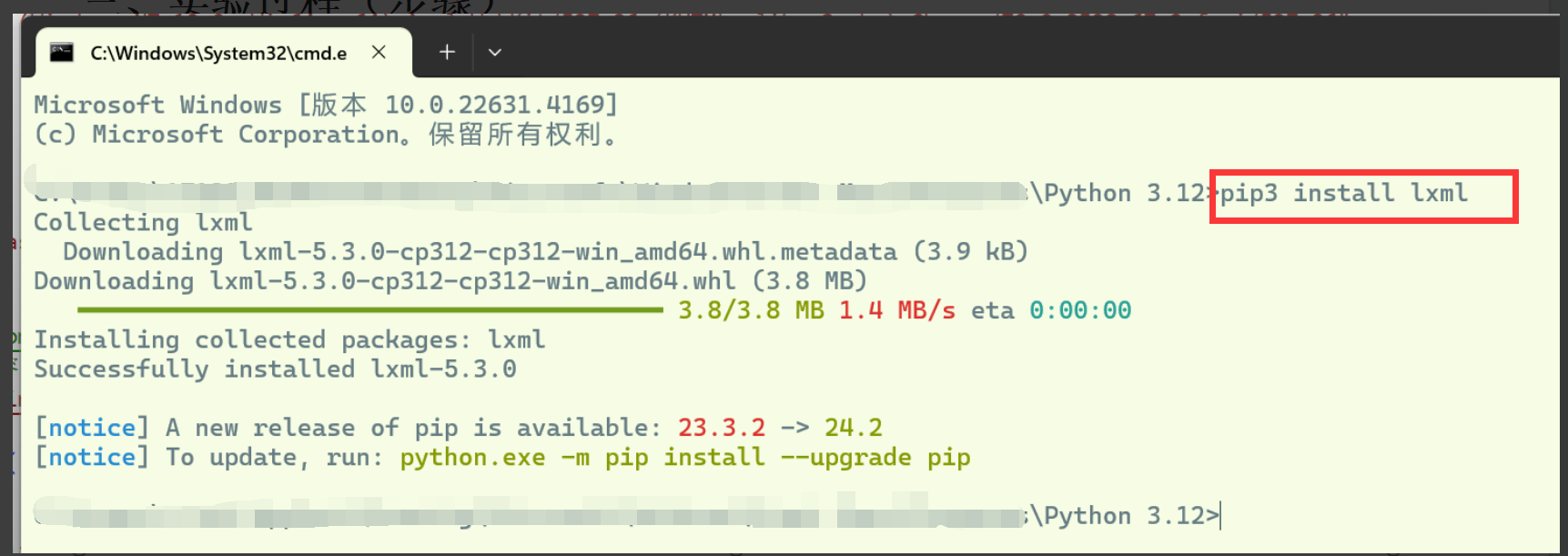
方法一:lxml库解析网页数据
import requests
import json
from lxml import etree
# 请求的 URL 和头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36 Edg/130.0.0.0',
}
def load_page(url):
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
print(f"访问失败: {response.status_code}")
return None
def parse_html(html):
items = []
if html:
# 使用 lxml 的 etree 解析 HTML
tree = etree.HTML(html)
# 使用 XPath 提取文章标题、链接、发布时间和作者
articles = tree.xpath('//a[@onclick="atarget(this)" and @class="s xst"]')
for article in articles:
link = article.get('href')
title = article.text.strip() # 去除标题前后的空格
# 找到发布时间和作者
parent = article.getparent()
time = parent.xpath('.//span[@style="margin-left: 0;"]/text()')
author = parent.xpath('.//span[@style="margin-left: 5px;"]/text()')
# 如果找不到时间或作者,打印调试信息
if not time:
print(f"未找到发布时间: {title}")
if not author:
print(f"未找到作者: {title}")
item = {
"文章链接": link,
"文章标题": title,
"发布时间": author[0].strip() if author else None,
"文章作者": time[0].strip() if time else None,
}
items.append(item)
return items
def save_file(items):
try:
with open('D:\\1.json', mode='w+', encoding='utf-8') as f:
f.write(json.dumps(items, ensure_ascii=False, indent=2))
except Exception as e:
print(e)
def heima_forum(begin_page, end_page):
li_data = []
for page in range(begin_page, end_page + 1):
url = f'https://bbs.itheima.com/forum-425-{page}.html'
print(f"正在请求第 {page} 页")
html = load_page(url)
if html: # 确保 HTML 内容存在
data = parse_html(html)
li_data += data
else:
print(f"第 {page} 页加载失败,跳过该页。")
save_file(li_data)
if __name__ == "__main__":
begin_page = int(input("请输入起始页:"))
end_page = int(input("请输入结束页:"))
heima_forum(begin_page, end_page)
采集到的文章的标题、文章的链接、文章作者和发布时间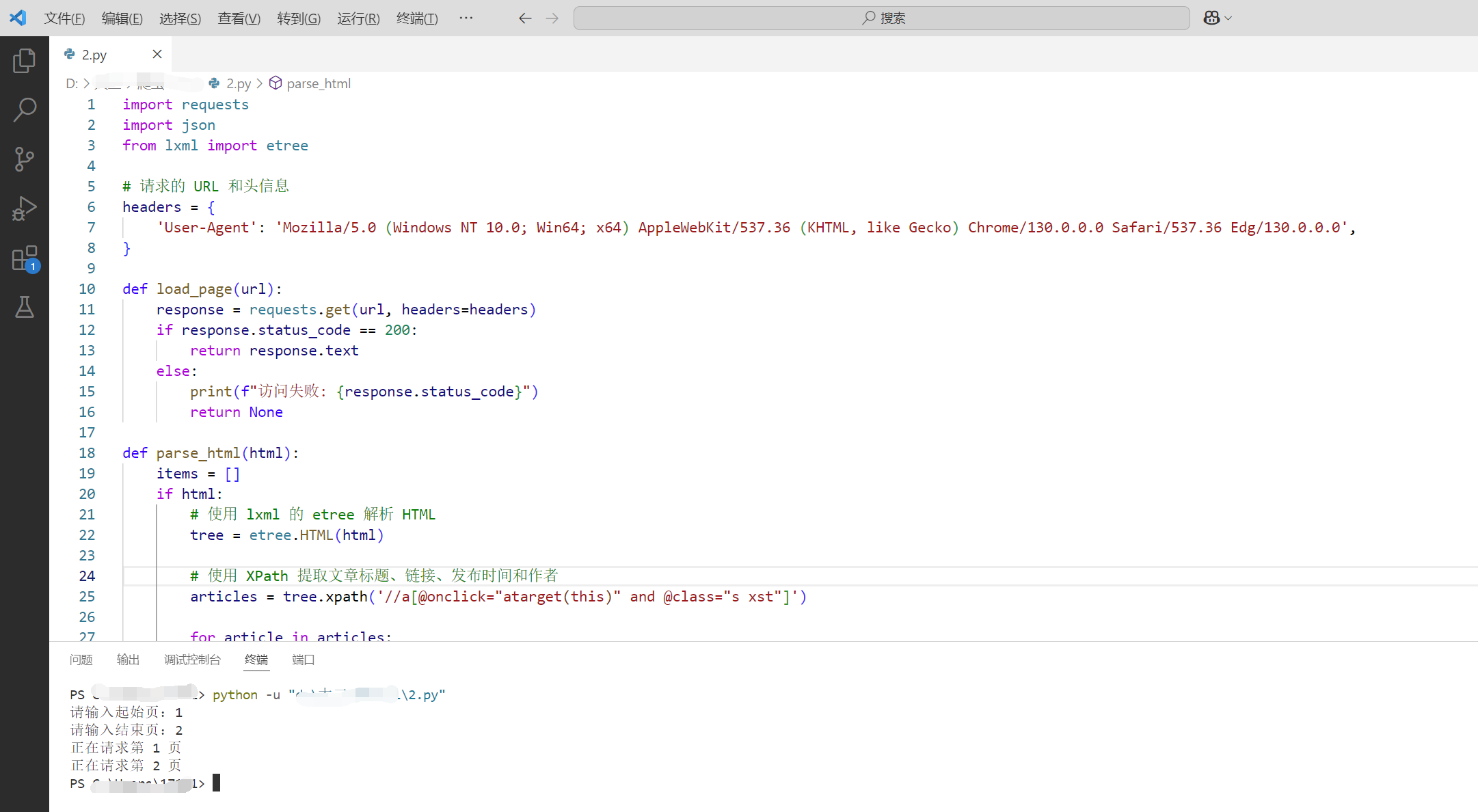
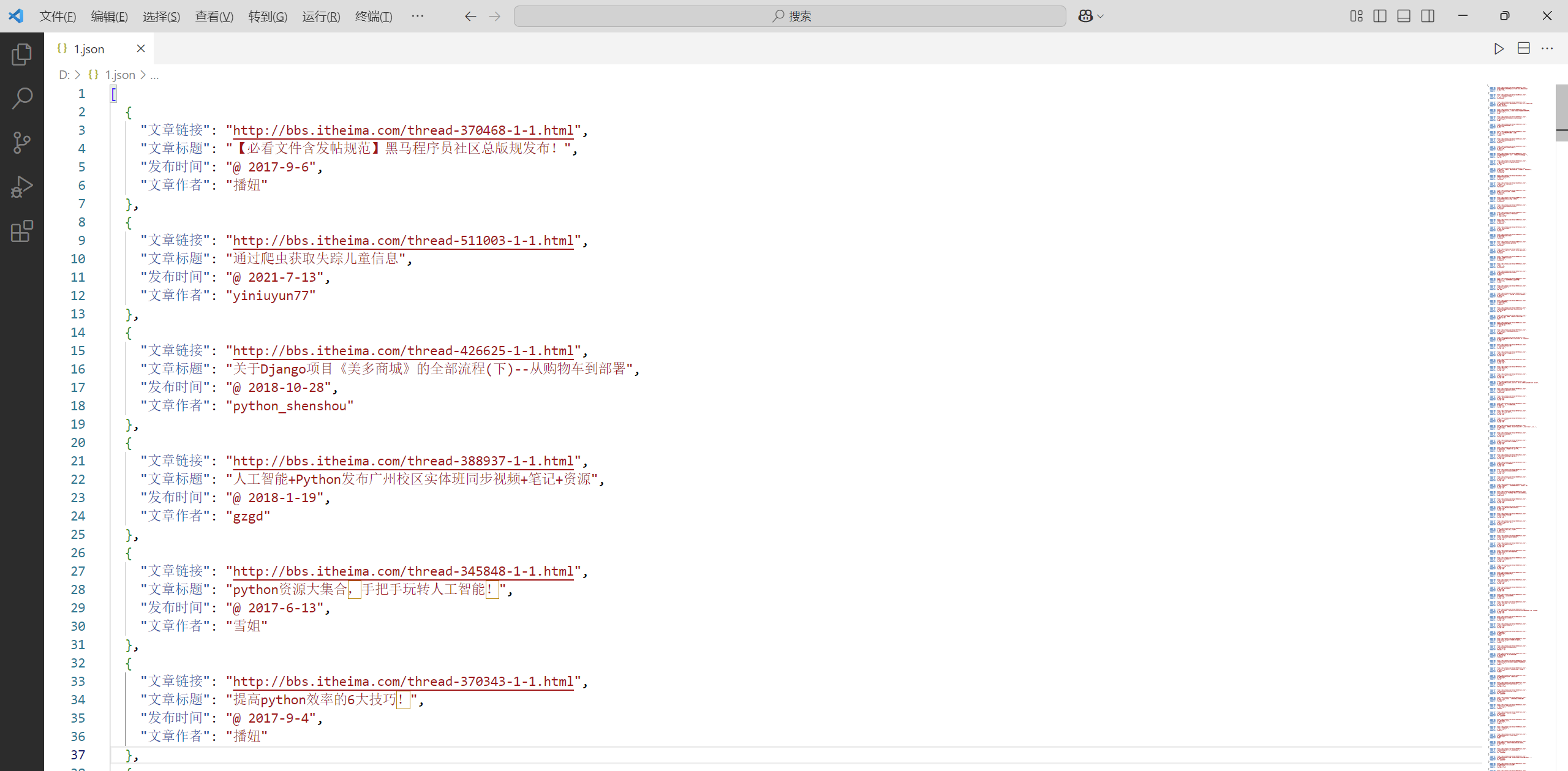
随机验证一下采集是否正确:
{
"文章链接": "http://bbs.itheima.com/thread-345848-1-1.html",
"文章标题": "python资源大集合,手把手玩转人工智能!",
"发布时间": "@ 2017-6-13",
"文章作者": "雪姐"
}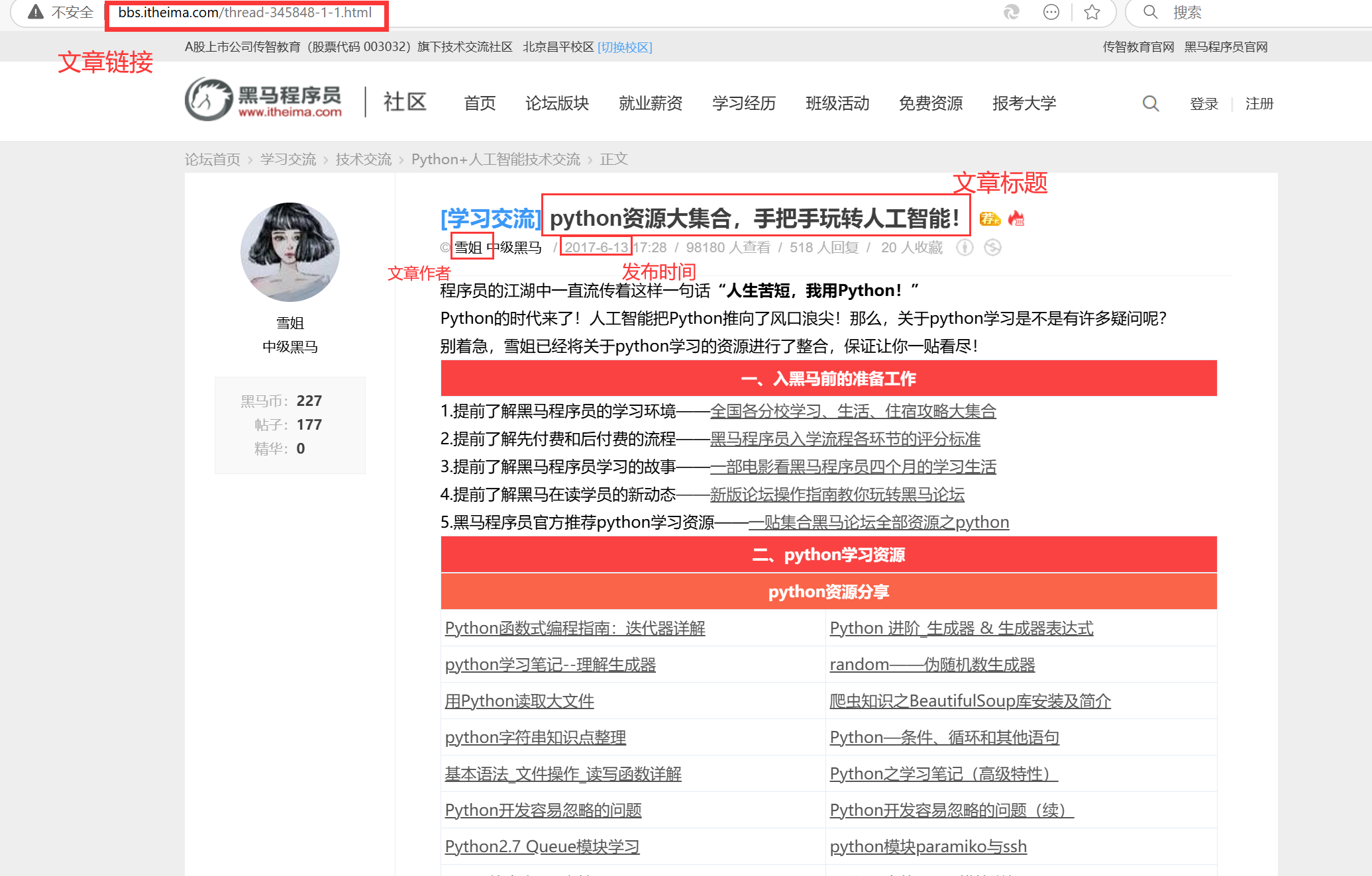 采集正确
采集正确
方法二:正则表达式
import requests
import re
import json
from lxml import etree
# 请求的 URL 和头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36 Edg/130.0.0.0',
}
def load_page(url):
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
print(f"访问失败: {response.status_code}")
return None
def parse_html(html):
items = []
if html:
# 使用正则表达式提取文章标题、链接、发布时间和作者
pattern = re.compile(
r'<a\s+href="([^"]+)"\s+onclick="atarget\(this\)"\s+class="s xst">([^<]+)</a>.*?'
r'<span style="margin-left: 0;">([^<]+)</span></a><span style="margin-left: 5px;">@ ([^<]+)</span>',
re.S
)
matches = pattern.findall(html)
for match in matches:
item = {
"文章链接": match[0],
"文章标题": match[1],
"文章作者": match[2],
"发布时间": match[3],
}
items.append(item)
return items
def save_file(items):
try:
with open('D:\\1.json', mode='w+', encoding='utf-8') as f:
f.write(json.dumps(items, ensure_ascii=False, indent=2))
except Exception as e:
print(e)
def heima_forum(begin_page, end_page):
li_data = []
for page in range(begin_page, end_page + 1):
url = f'https://bbs.itheima.com/forum-425-{page}.html'
print(f"正在请求第 {page} 页")
html = load_page(url)
data = parse_html(html)
li_data += data
save_file(li_data)
if __name__ == "__main__":
begin_page = int(input("请输入起始页:"))
end_page = int(input("请输入结束页:"))
heima_forum(begin_page, end_page)
采集到的文章的标题、文章的链接、文章作者和发布时间
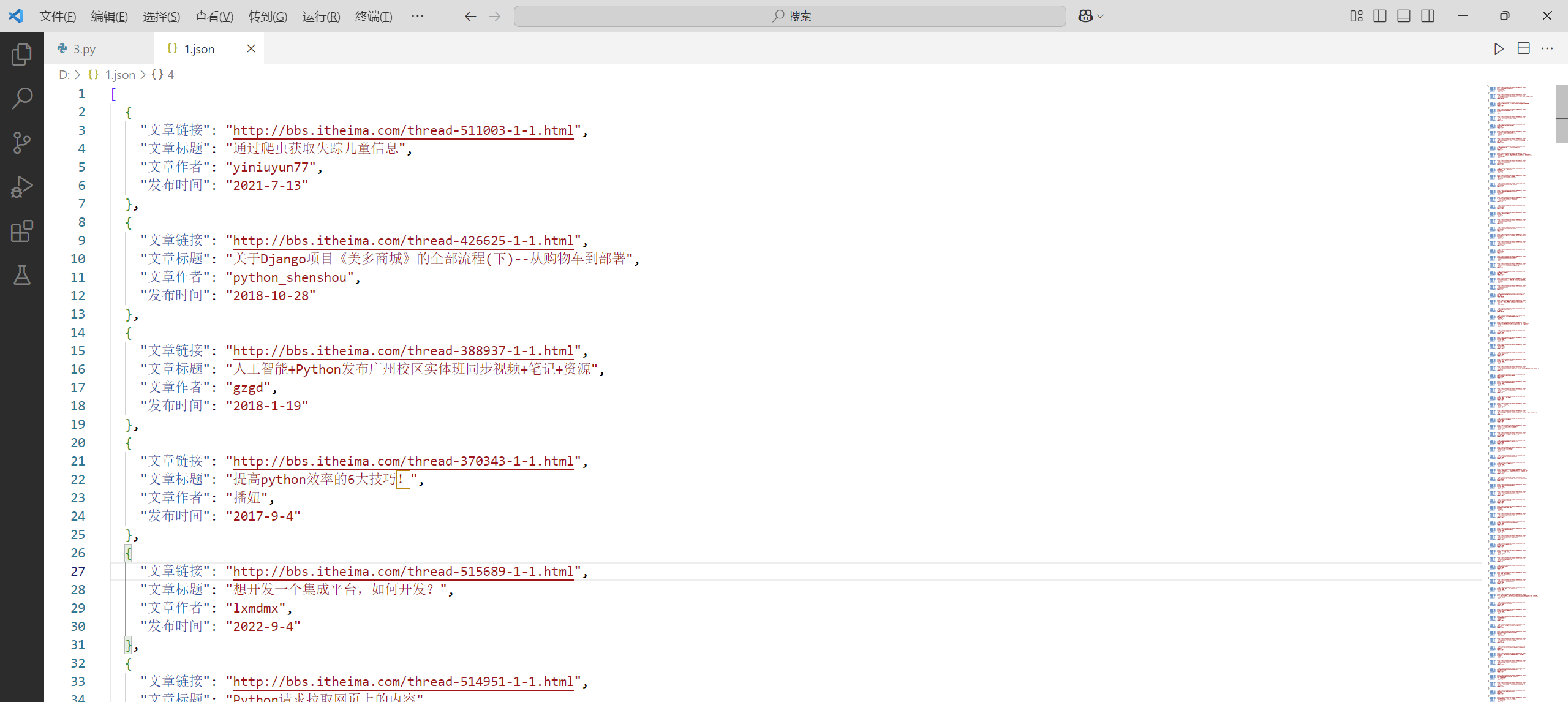
随机验证一下采集是否正确:
{
"文章链接": "http://bbs.itheima.com/thread-515689-1-1.html",
"文章标题": "想开发一个集成平台,如何开发?",
"文章作者": "lxmdmx",
"发布时间": "2022-9-4"
}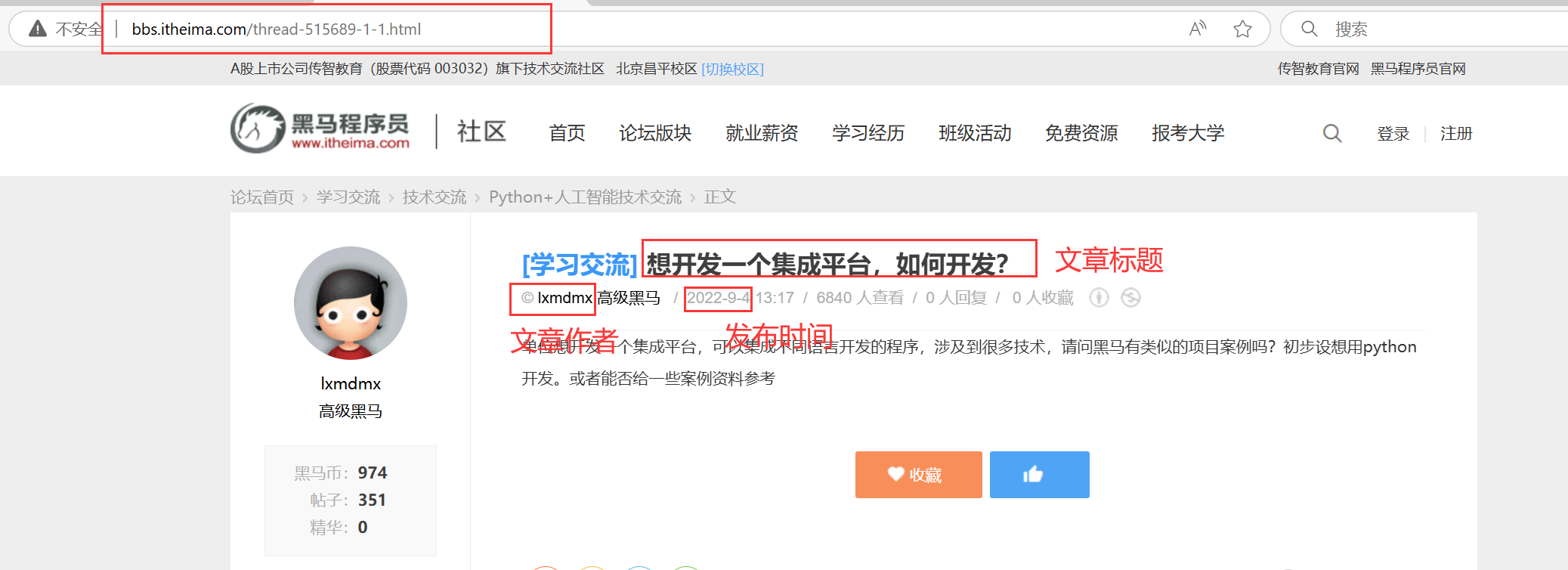 采集正确
采集正确




