



34,467
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享也可以下载项目压缩包(链接:https://pan.quark.cn/s/cf705c9b6c91 提取码:CtWk)
台风是一种强烈的气象现象,常常对沿海地区造成严重的影响。准确预测台风的路径、强度和降水量,对于减少灾害损失、保护人民生命财产安全至关重要。本项目旨在利用机器学习技术,构建一个高效的台风预测模型,以提高台风预测的准确性和及时性。
2.1 数据来源
本项目使用的数据主要包括:
- 台风路径数据:涵盖1945年至2023年间的台风路径信息。
- 海洋温度数据:用于分析海洋温度对台风强度的影响。
- 降水量统计数据:用于研究降水量与台风强度之间的关系。
2.2 数据加载与预处理
在数据处理阶段,使用`pandas`和`xarray`库进行数据加载和预处理。主要步骤包括:
- 加载台风路径数据,并将时间列转换为`datetime`格式。
- 处理缺失值,使用均值填充气压和移动速度的缺失数据。
- 添加新的特征,例如台风持续时间,以增强模型的预测能力。
- 加载并处理海洋温度和降水量数据,确保数据的完整性和一致性。
开始处理台风数据...
台风数据统计分析:
每年台风数量:
年度台风数量统计:
平均数: 22.95 标准差: 4.55 最小值: 12 最大值: 34
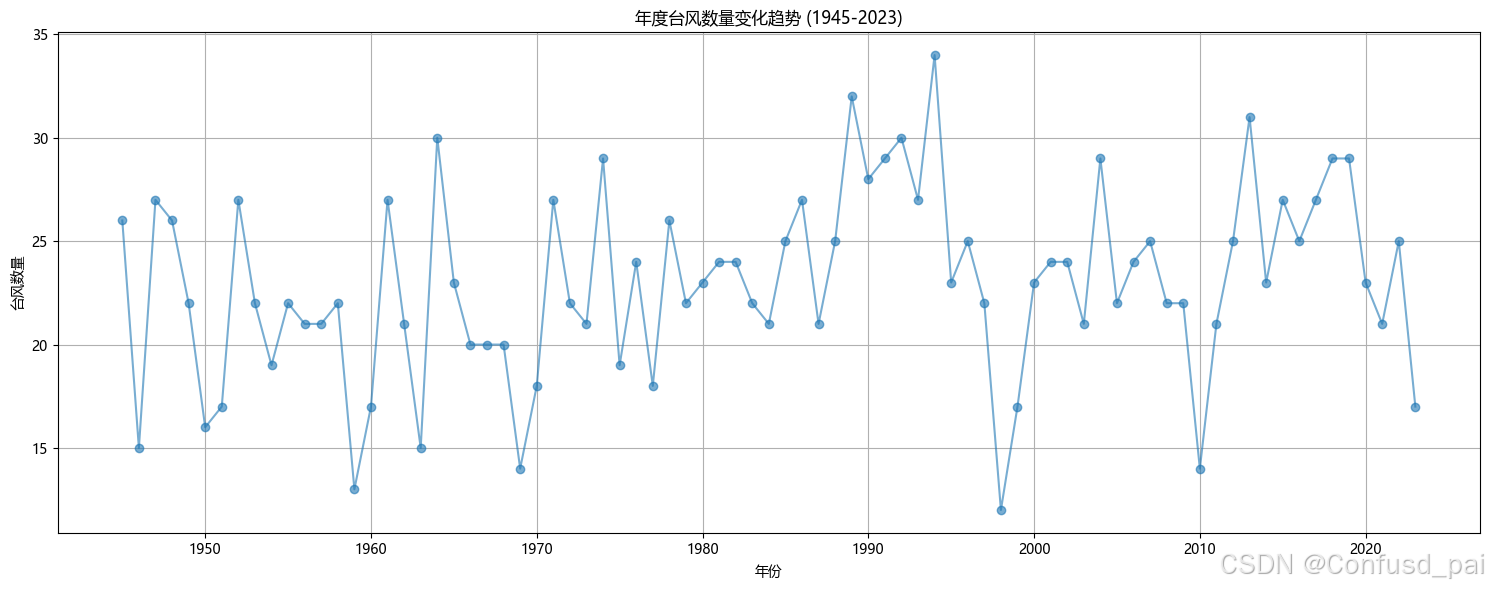
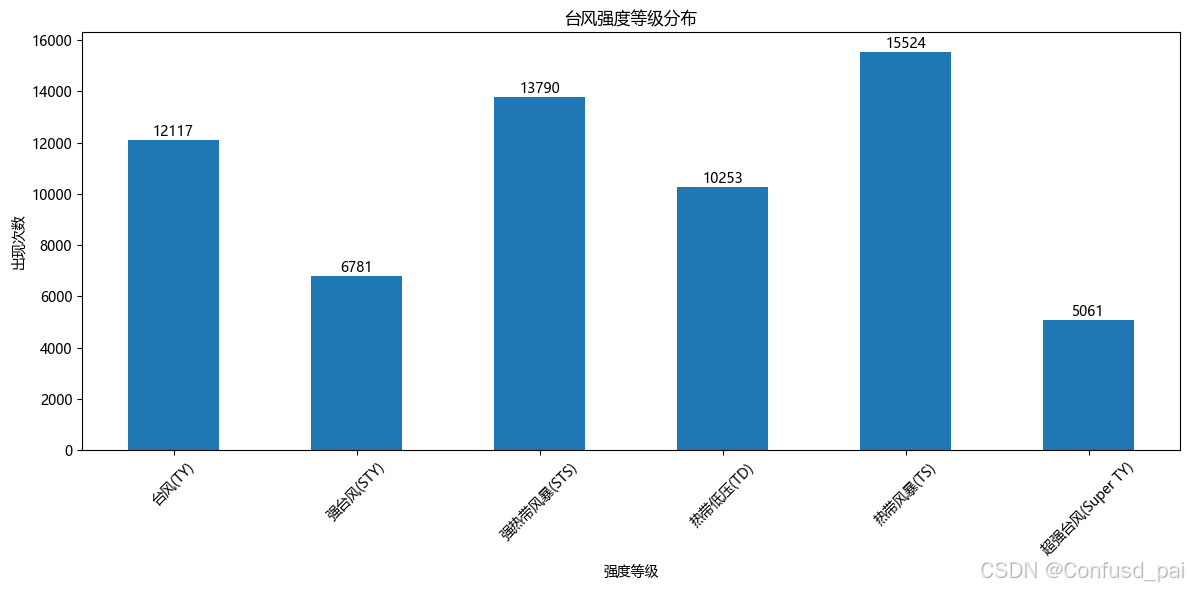
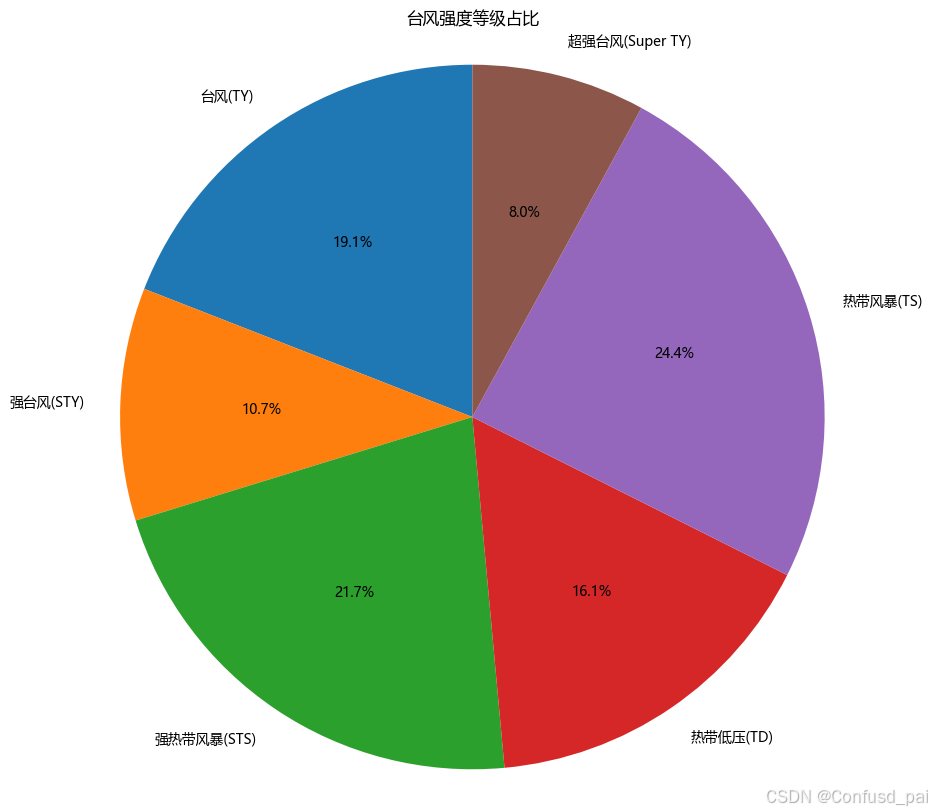
分析台风强度分布...
台风强度分布:
台风强度
台风(TY) 12117
强台风(STY) 6781
强热带风暴(STS) 13790
热带低压(TD) 10253
热带风暴(TS) 15524
超强台风(Super TY) 5061
Name: count, dtype: int64
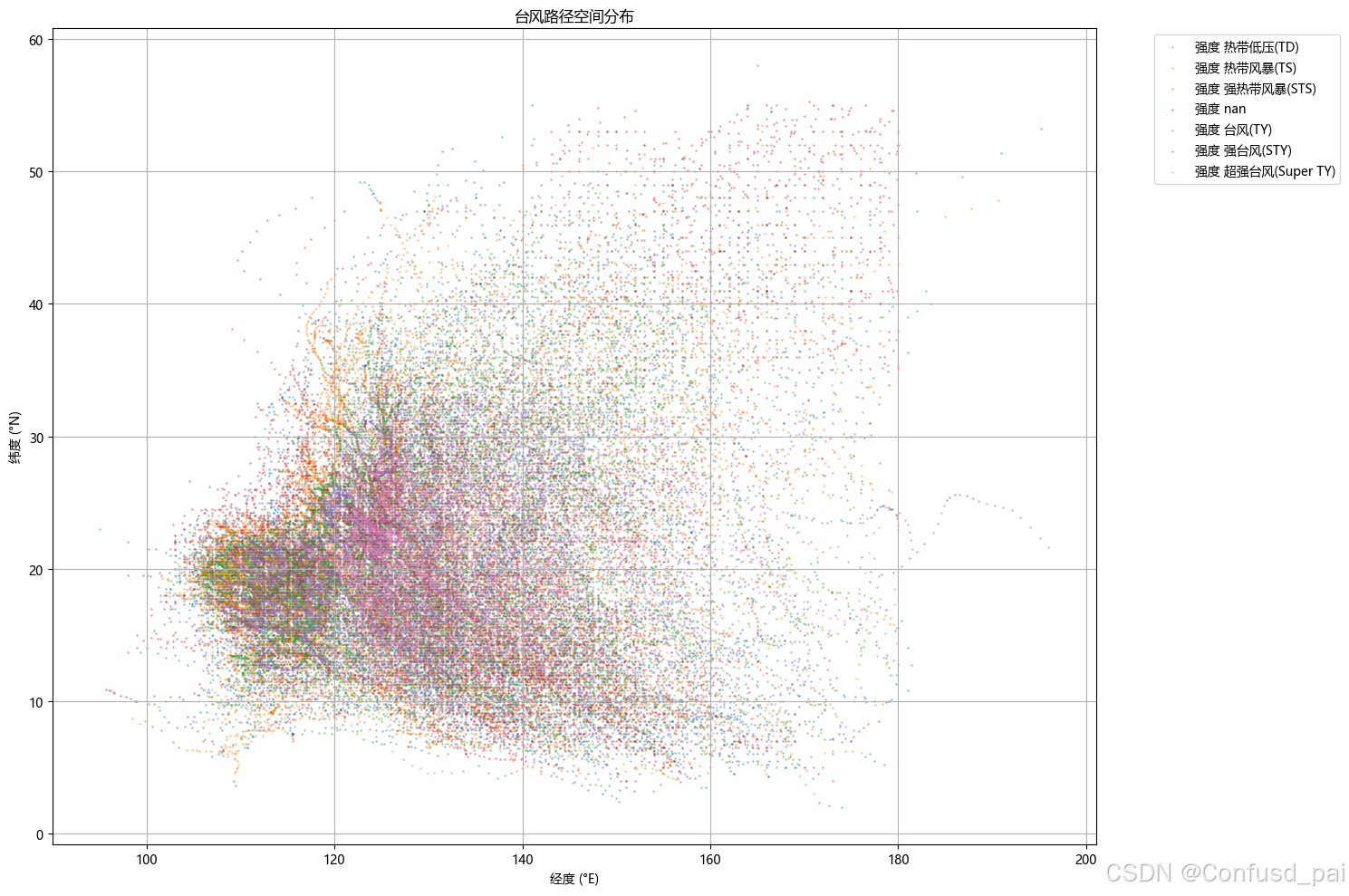
分析台风空间分布...
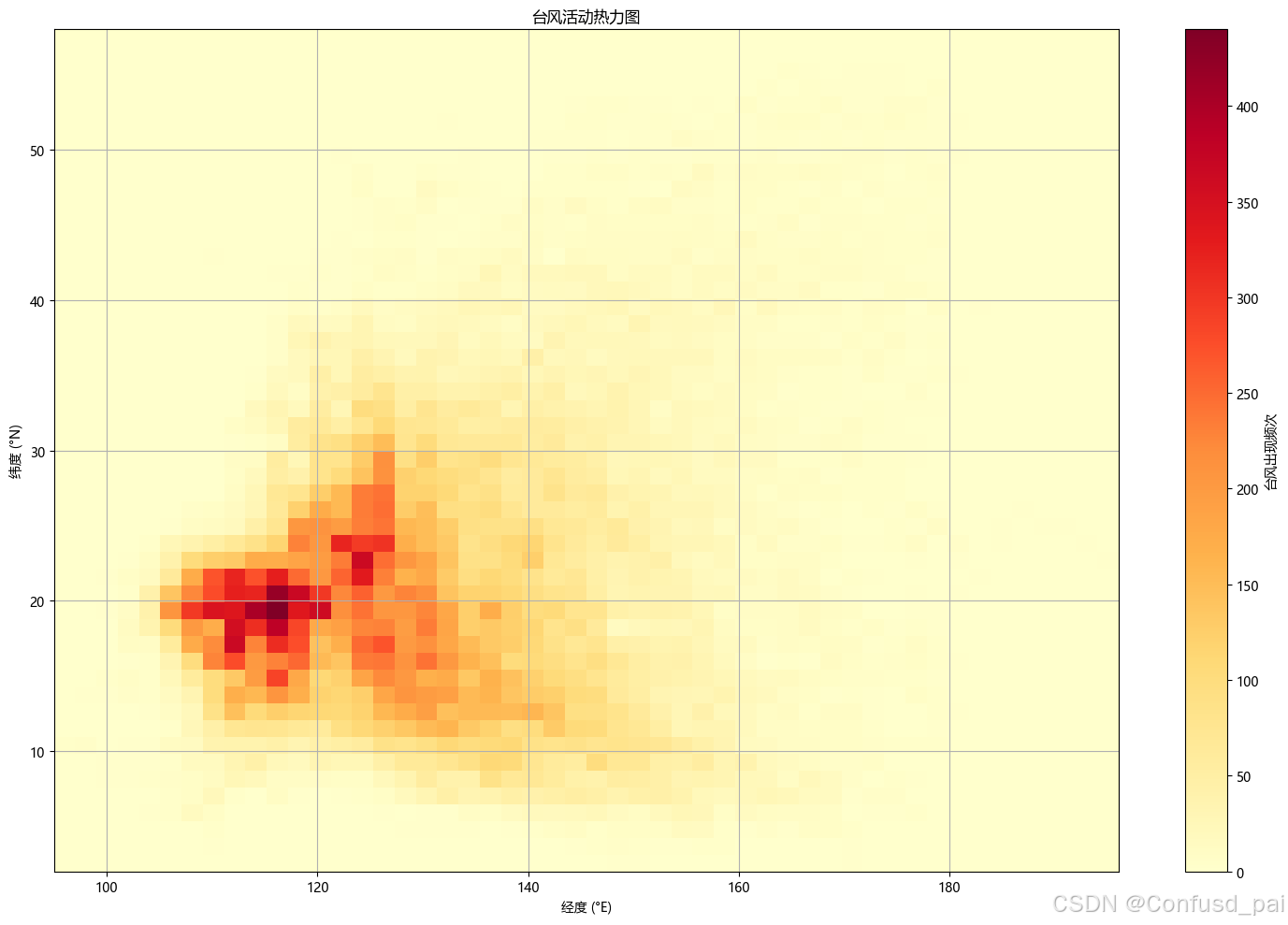
3.1 模型架构
本项目采用LSTM(长短期记忆网络)模型进行台风预测。LSTM是一种适合处理时间序列数据的递归神经网络,能够有效捕捉时间序列中的长期依赖关系。
3.1.1 LSTM模型结构
- 输入层:接收特征数据,包括经度、纬度、台风等级、风速、气压等。
- LSTM层:通过多层LSTM提取时间序列特征,增强模型对时间序列的理解。
- 注意力机制:通过注意力机制加权不同时间步的输出,提升模型对重要时间点的关注。
- 输出层:输出台风的预测结果,包括位置、强度、时间和降水量。
# 双向LSTM层
self.lstm = nn.LSTM(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
dropout=0.0 if num_layers == 1 else dropout,
bidirectional=True
)
# 注意力机制
self.attention = nn.Sequential(
nn.Linear(hidden_size * 2, hidden_size),
nn.Tanh(),
nn.Linear(hidden_size, 1)
)
def forward(self, x):
# 应用批标准化
batch_size, seq_len, features = x.size()
x = x.view(-1, features)
x = self.batch_norm(x)
x = x.view(batch_size, seq_len, features)
# LSTM前向传播
lstm_out, _ = self.lstm(x)
# 注意力机制
attention_weights = torch.softmax(self.attention(lstm_out), dim=1)
context_vector = torch.sum(attention_weights * lstm_out, dim=1)
# 分别处理不同类型的输出
position = self.fc_position(context_vector)
intensity = self.fc_intensity(context_vector)
time = self.fc_time(context_vector)
precip = self.fc_precip(context_vector)
# 合并所有输出
output = torch.cat([position, intensity, time, precip], dim=1)
return output
3.2 自定义损失函数
为了提高模型的预测性能,设计了自定义损失函数,结合了均方误差(MSE)和平均绝对误差(MAE),确保模型在不同特征上的表现均衡。
def custom_loss(self, outputs, targets, features_weights=None):
"""自定义损失函数"""
if features_weights is None:
features_weights = torch.ones(outputs.shape[1])
# 计算加权MSE损失
mse_loss = torch.mean(features_weights * (outputs - targets) ** 2)
# 计算MAE损失
mae_loss = torch.mean(torch.abs(outputs - targets))
# 对降水量添加额外的非负约束
precip_loss = torch.mean(torch.relu(-outputs[:, 7])) if outputs.shape[1] > 7 else 0
# 对时间特征添加周期性损失
time_loss = torch.mean(torch.abs(torch.sin(outputs[:, 5:7] * 2 * np.pi) -
torch.sin(targets[:, 5:7] * 2 * np.pi)))
return 0.4 * mse_loss + 0.3 * mae_loss + 0.2 * time_loss + 0.1 * precip_loss
4.1 数据加载器
使用`DataLoader`将数据分为训练集和验证集,设置批次大小和训练比例,以便于模型的训练和评估。
4.2 训练过程
在模型训练过程中,采用Adam优化器和学习率调度器,动态调整学习率以提高训练效率。通过监控训练损失和验证损失,采用早停策略防止过拟合。
for epoch in range(epochs):
# 训练阶段
model.train()
train_loss = 0
for sequences, targets in train_loader:
sequences = sequences.to(self.device)
targets = targets.to(self.device)
optimizer.zero_grad()
outputs = model(sequences)
loss = self.custom_loss(outputs, targets, features_weights)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
train_loss += loss.item()
# 验证阶段
model.eval()
val_loss = 0
with torch.no_grad():
for sequences, targets in val_loader:
sequences = sequences.to(self.device)
targets = targets.to(self.device)
outputs = model(sequences)
loss = self.custom_loss(outputs, targets, features_weights)
val_loss += loss.item()
train_loss /= len(train_loader)
val_loss /= len(val_loader)
train_losses.append(train_loss)
val_losses.append(val_loss)
# 更新学习率
scheduler.step(val_loss)
if val_loss < best_val_loss:
best_val_loss = val_loss
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'scheduler_state_dict': scheduler.state_dict(),
'train_loss': train_loss,
'val_loss': val_loss,
'scaler': self.scaler
}, 'best_typhoon_model.pth')
patience_counter = 0
else:
patience_counter += 1
if (epoch + 1) % 5 == 0:
print(f'轮次 [{epoch+1}/{epochs}]')
print(f'训练损失: {train_loss:.4f}, 验证损失: {val_loss:.4f}')
print(f'学习率: {optimizer.param_groups[0]["lr"]:.6f}\n')
if patience_counter >= patience:
print(f"\n在第 {epoch+1} 轮触发早停")
break
4.3 结果可视化
训练完成后,绘制训练损失和验证损失的变化曲线,直观展示模型的训练过程和效果。
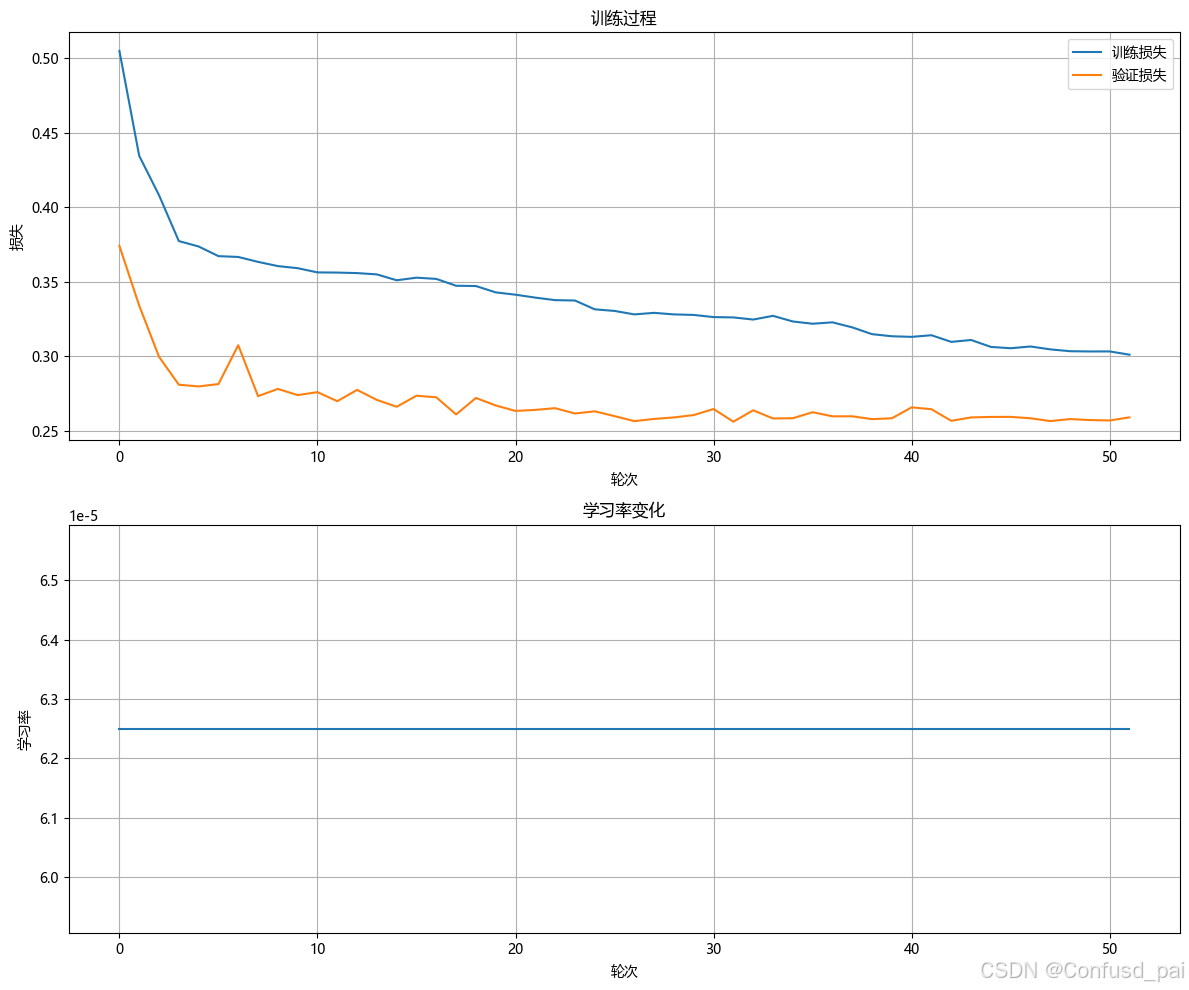
模型训练完成后,可以使用训练好的模型进行台风的状态预测。输入当前的台风特征数据,模型将输出下一个时间步的预测结果,包括位置、强度、时间和降水量。
本项目通过数据处理和LSTM模型的结合,建立了一个有效的台风预测模型。未来可以进一步优化模型结构,增加更多的特征数据,以提高预测的准确性和可靠性。通过不断的迭代和改进,期望能够为台风预测提供更为精准的支持,帮助相关部门更好地应对台风带来的挑战。

