


275
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享目录
一、 第一次作业分析
1.1 架构分析
1.2 类图展示
1.3 化简表达式
二、 第二次作业分析
2.1 架构分析
2.2 类图展示
2.3 化简表达式
三、 第三次作业分析
3.1 架构分析
3.2 类图展示
3.3 化简表达式
四、 bug总结
4.1 第一次作业
4.2 第二次作业
4.3 第三次作业
五、 程序结构
5.1 类数以及方法数度量
5.2 类复杂度分析
5.3 方法复杂度分析
六、 心得体会
6.1 对于递归下降方法的体会
6.2 对于debug的体会
七、 未来方向
第一次作业在表达式解析方面沿用了OOpre当中的词法分析和语法分析的结构,首先阅读文法,可以得到最基础的token共有+ - * ^ ( ) x [0-9]*这八种,只需要让lexer去解析这八种token即可。在语法方面,阅读形式化表述之后,可以很简单地得出表达式-项-因子这一由上而下的层次结构,而因子这一层次又分为常数因子、幂函数因子、表达式因子,只需要在Parser当中写上这几种类的解析方法就可以得到表达式的表达式树形式。
当然,在进行上述的解析之前,还需要对于表达式当中的空白项、多重复符号等进行化简,所以我引入了Prosessor来对于表达式中的干扰项先进性化简,然后再进行解析。
最后就来到了难点——如何对于得到的表达式树进行计算,化简得到最终的结果。显然单纯的字符串不能进行计算,所以我新建了Poly、Mono两个类,他们是所有的其他数据类的一个数值表现,即其他所有的数据类的对象都可以用Poly类或者Mono类来表示进而参与计算,此时只需要在Calculator类当中写上Poly和Mono各自的计算方式即可将表达式树化为计算表达式,最后算出一个Poly作为最终的计算结果,然后重写他们的toString方法进行输出即可。
这样即可完成第一次作业的基础功能部分。
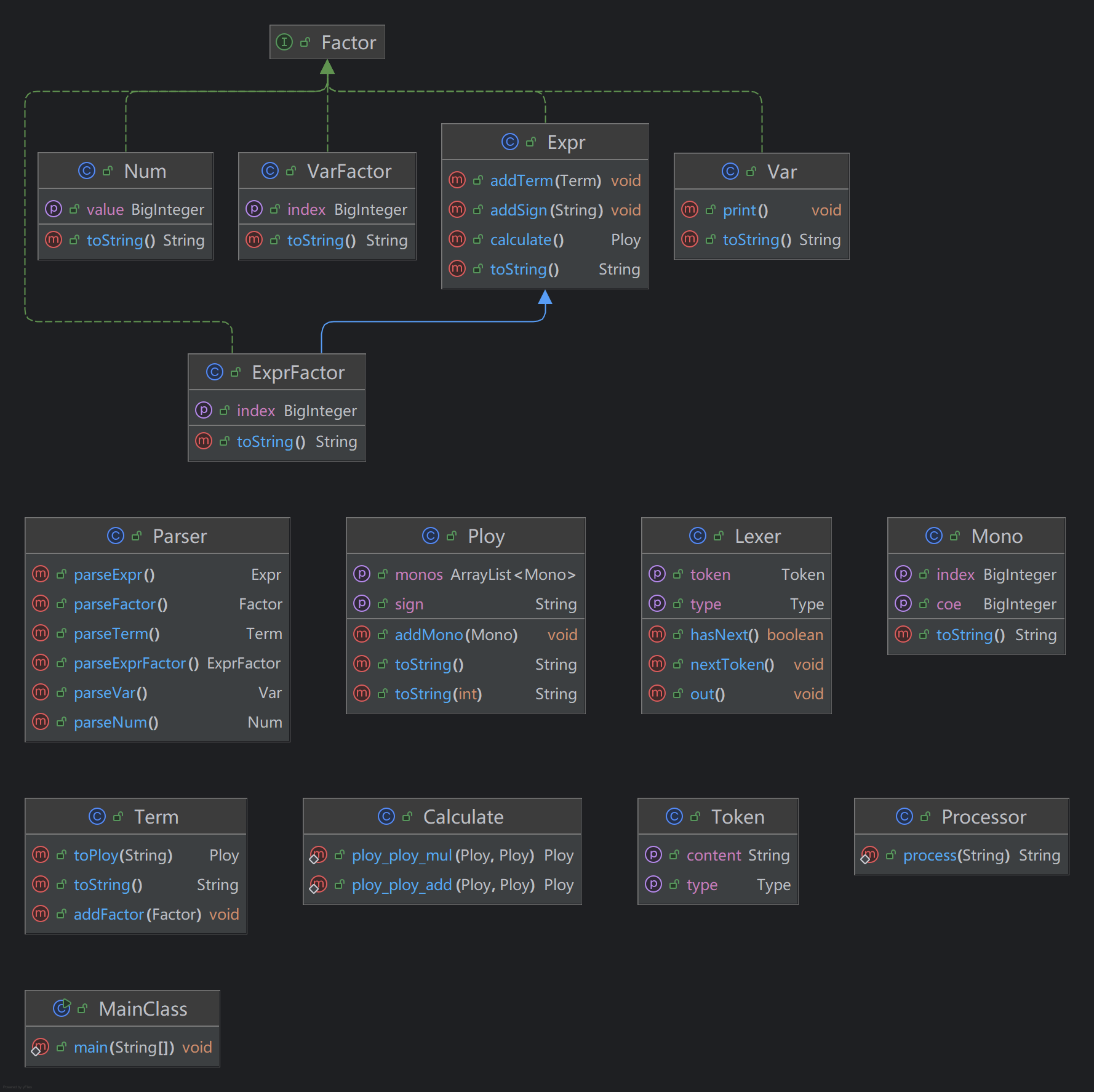
可以看到这一次作业共使用了14类和一个接口完成,其中表达式、表达式因子、常数因子、幂函数因子都实现了因子接口;表达式因子继承了表达式类的属性和方法,总共使用655行代码完成HW1。
其中的Expr、Term、ExprFactor、VarFactor、Var、Num类为记录表达式所用到的类;Parser、Lexer、Token为递归下降解析表达式用到的类;Ploy、Mono为把数据类转化为可计算的数据的载体;Calculator类用来进行Poly、Mono之间的计算;Prosessor类用来进行预处理,去除空格和化简连续符号。
hw1的化简比较有限(前提是你已经把多重的符号进行了化简),大概可以提高性能的地方就是如果最终表达式当中有正的项,就把他提到表达式的第一项,这样可能可以避免负的项放在第一个位置导致多一个负号,但总体来说就一个符号的差别,大家的性能都差不多。
注:三次作业的bug将会放到三次作业架构和思路分享完毕之后统一总结
第二次作业当中引入了三角函数的计算递推表达式的计算。
对于新引入的三角函数,我们不能够再使用原来简单的HashMap来存储单项式的信息,由于在一个单项式中这些三角函数之间都是用乘法连接,所以只需要在单项式中新增了一个存储Trim对象的ArrayList容器来管理单项式中的三角函数即可。剩下的计算过程修改都比较简单,值得注意的是如何判断三角函数内的因子是否相同,这里我新增了Comparator类来进行比较,具体原理是利用两个表达式化为字符串之后,再相减或相加查看结果是否为0来判断相等、相反还是无关。三角函数主要的工作都在化简优化部分,所以下面再谈。
而对于递推函数的处理是这一次作业的重难点,在这里我采取了完全基于字符串替换方法来处理函数,使得在预处理阶段就消除表达式中的所有函数,进而就可以把这个表达式送入我们原来只支持常数、x、三角函数计算的方法当中化简。具体的核心做法大概分为以下两步:
由于我们在对表达式进行字符串替换时可能需要多次对于同一个序号的函数进行代入不同实参的调用,所以我们可以预先制作出序号为0~5的函数的带有形参的模版,具体做法完全符合我们直观对于这种函数计算的处理方式。具体的图示如下所示:
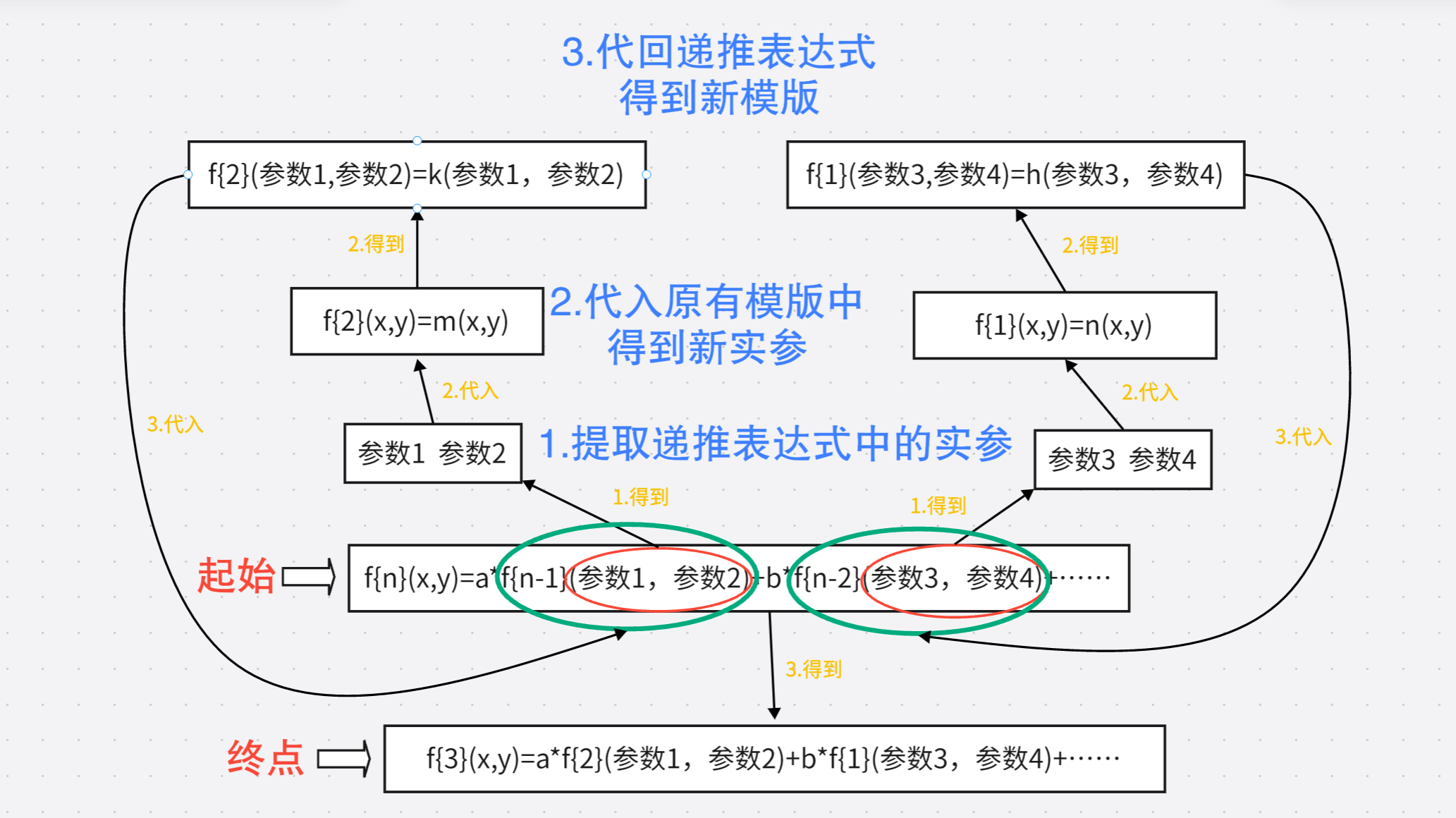
这个部分比较简单,只涉及到一个核心问题就是如何从表达式当中读取出正确的序号和实参,一开始我的想法是使用递归下降进行解析,但是理由同之前说过的,并不想引入函数作为因子;后来考虑使用正则匹配进行解析,但是很遗憾,D老师告诉我标准的正则表达式基于有限状态自动机,无法处理无限嵌套的结构,对于我们的嵌套括号和函数自调用并不适用;最后,我想到了大一下期数据结构大作业中使用的方法,遍历字符串,用栈去记录括号,根据栈的情况去读取字符串中的因子。通过这种方式我们就可以得到表达式中的函数序号和实参,代入到模板当中,就可以达到去掉当前外层函数的效果。只需要我们不断进行上述替换,直到表达式中不再存在f,那么我们就得到了一个“干净”的,可以处理的表达式了!
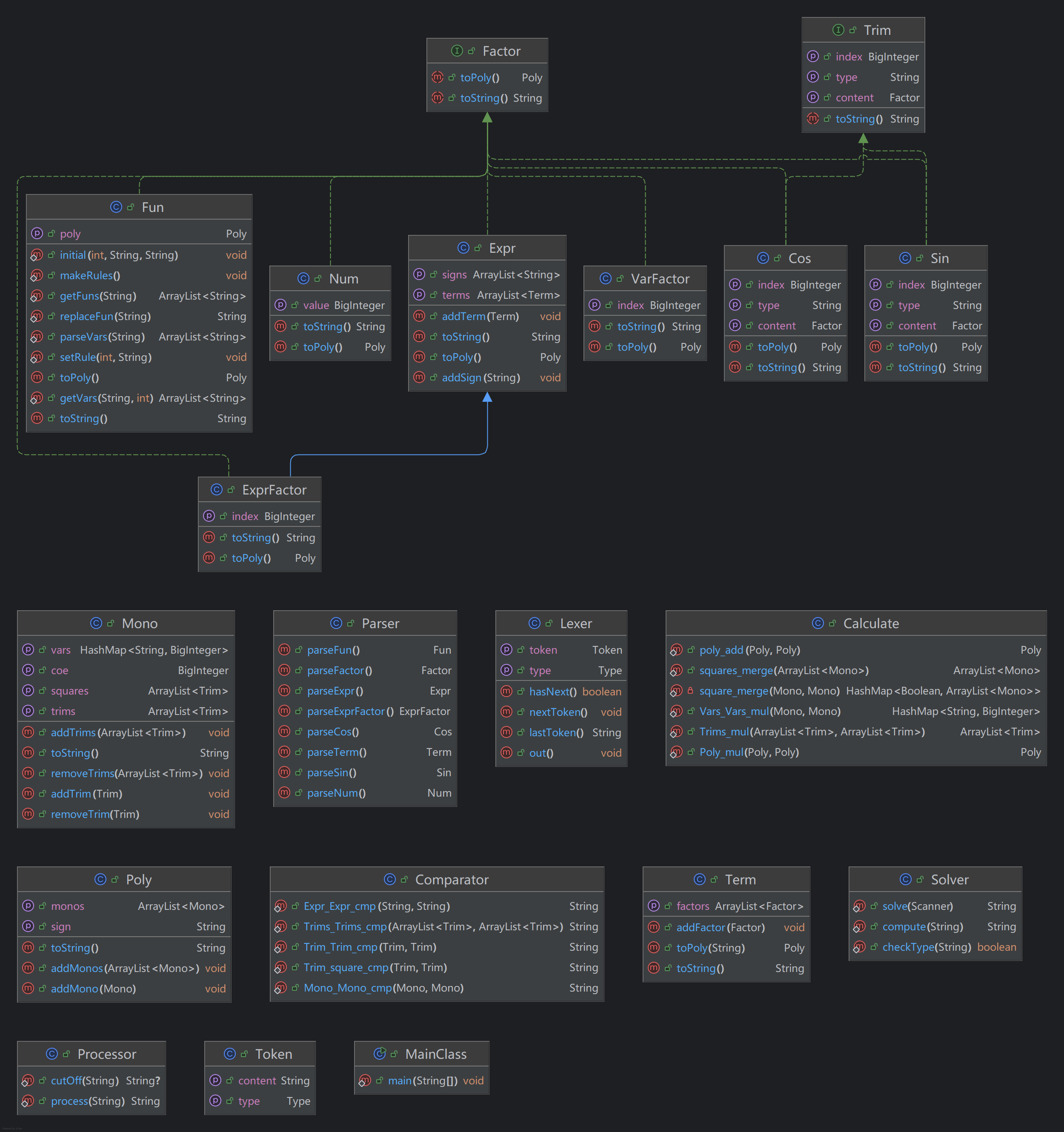
可以看出,第二次作业共使用了19个类和1个接口完成作业,相较于第一次作业新增了Trim、Sin、Cos、Comparator、Fun五个类,总计1499行完成第二次作业。
其中新增的Trim接口和Sin、Cos类用来记录三角函数因子;Fun用来生成递推函数的模板和替换表达式当中的递推函数;Comparator类用来比较三角函数,表达式等等各种数据是否相等(等同于重写.equals方法);Calculator类当中新增了计算三角函数的方法。
因为能力原因,我只做了几个个人认为比较常见的三角函数化简,包括平方和、平方和的逆用、三角函数特殊函数值、三角函数的奇偶性。
这两种化简的条件相似,是除开同因子但是类型相反的指数为2的三角函数以外,其他因子都相等或者互为相反数,具体来说就是如果可以把其他因子都变形为相等的形式,此时如果两项同号,那么就可以利用平方和为一进行化简;如果两项的符号相反,那么就可以利用平方和为一的逆用,把其中一个平方拆成1-另一类三角函数的平方的形式进行化简。
要实现的一个比较重要的操作就是比较两个三角函数的内部是否相等,这也是三角函数化简的基础,我采取的方式是通过把他们内部因子都化为字符串之后构造相减的表达式和相加的表达式进行计算,如果相减的表达式计算结果为0,那么内部因子相同,如果相加的表达式结果为0,那么内部因子互为相反数。
大多数人都知道sin(0)=1,cos(0)=1,进而可以进行一些优化,这里我分享一个比较“简便”的优化方法:在进行语法分析的时候,如果我们要解析一个三角函数,那么我们可以先计算一下解析出来的这个三角函数内部的因子,如果这个因子的值为0,那么我们在返回因子的时候,就不需要返回一个三角函数因子,而是直接返回一个0或者1的常数因子,当然,还要注意指数!注意指数!注意指数!说到这里,对于指数为0的表达式因子同样也可以采用这种方式。
其实对于这个奇偶性,我并不是真的去对一个三角函数因子进行了改变,而是在对三角函数计算(比如相乘或者相加)、比较等方面时,考虑了它的奇偶性,例如在上述平方和及其逆用的时候,需要比较其他因子,此时就可以考虑sin和cos的奇偶性。
第三次作业引入了自定义函数和求导因子,相对来说难度简单很多。
对于自定义函数的处理,我们只需要按照题意,把自定义函数因子当成自定义函数因子即可,它作为一种因子的属性也很简单,只需要包含它的参数即刻,可以认为是告知了函数表达式的递推函数,所以同理可以进行计算。
对于求导因子的处理同上,将它作为一种因子进行解析即可,它的属性只有内部表达式。主要的难度在于如何把求导因子化为多项式。这里我没有采用实验中代码给出的方式从表达式-项-因子一步一步去逐层求导,因为这种方式需要写过多的求导方法,并且可以注意到,在架构当中Poly和Mono是任何其他数据类的数值表现,所以我们只需要把其他数据类都化成Poly和Mono类,然后写他们的求导方法即可。观察Mono的构成,包含常数系数、幂函数、三角函数,所以我们只需要具体实现对于幂函数和三角函数的求导方法即可。
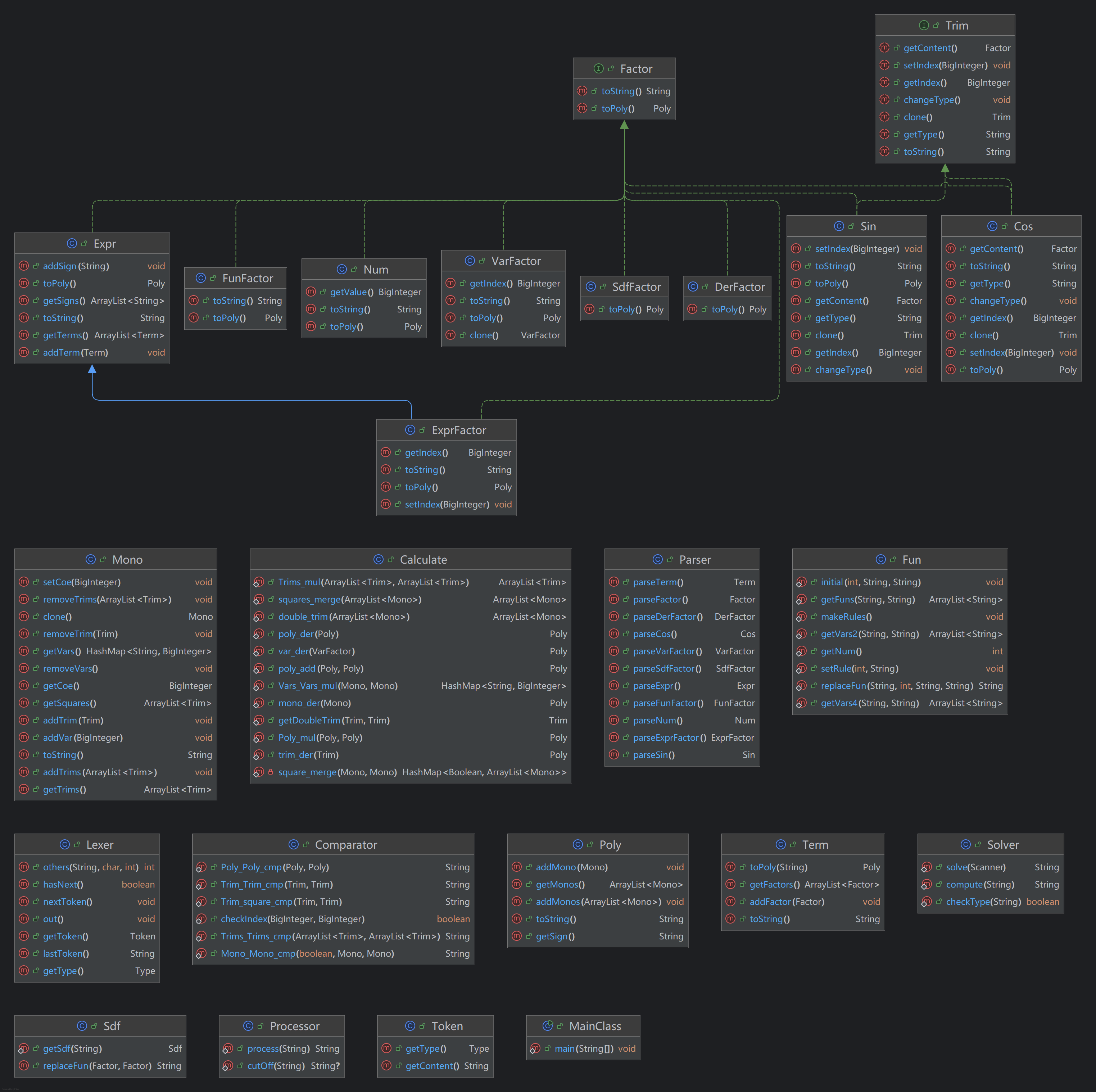
本次作业共使用22个类和2个接口完成,总计代码量为1913行。
其中新增的Sdf类用于记录自定义函数的模版和生成对应的自定义函数表达式;SdfFactor类即是语法分析当中的一类因子;DerFactor类是语法分析中的一类因子,用于记录求导因子;Calculator类当中新增了对于Poly、Mono、Trim、VarFactor类对象的求导方法。
本次新加入的内容没有什么可以化简的地方,所以我又对之前的三角函数部分新增了一个2*sin(x)*cos(x)=sin((2*x))的化简,具体思路和平方和、平方差的化简思路差不多。因为分析这次题目,凡是三角函数的次幂进行求导,就有可能可以进行这种化简,所以我毫不犹豫地加上了这个化简,但是最后却发现有不少情况下没有加入这个化简的结构却比化简之后的结果还要短,这个问题至今我还没有想出来是为什么。
至此,三次作业的基础部分和化简就全部完成了
第一次作业在语法和词法解析方面的错误应该比较少(毕竟有oop的代码和实验代码可供“参考”),在多项式和单项式的计算方面应该也不会有太大的问题,只要不再计算过程中忘了考虑项的符号即可。
1.我在本次强测和互测当中暴露出了一个bug,就是在预处理阶段,由于对于正则匹配极其不熟练,也没有用什么样例去进行测试,导致了我在化简连续符号的过程中出现了错误。具体 来说就是我在while(matcher.find)的每一次遍历都对原来的字符串进行了修改,但是正则匹配所匹配的字符串还是最开始的字符串并没有更新,导致两者状态不同,没有能够正确化简所有 的连续符号最终出错。
2.互测阶段我也测出来了两个别人的bug。一个是没有正确处理*后面紧跟带符号整数的情况,导致解析错误;另一个错误是对于(0)^0进行了错误的化简为0,。这两个bug还是较为常见。
第二次作业可以说是bug多多又多多,但是感谢zjy仙人的评测机帮助我在强测当中得到了所有的正确性得分。
1.首先是在三角函数方面的问题主要出现在化简方面,首先让我们回顾一下初中知识sin(0)=0,cos(0)=1,也许对于初中的我很简单,但是在一开始的作业当中我把sin(0)、cos(0)的值都 算成了0,这可能是特例吧。但是当大家引入了这个化简之后,就开始出现了sin(0)^0=0的错误,并且这个错误非常常见,可以说是(0)^0的进阶版。
2.同时在互测阶段,我发现部分同学对于三角函数内的因子的化简出现了问题,具体就是省去了必要的括号,即对于三角函数内部因子的性质没有进行正确的分析,一个比较常见的错误就是sin(-x),其中的符号决定了-x应该是一个表达式,所以应该再加上一层括号。当然对应的也有同学出现sin((-2))的情况,虽然并不是错误,但是显然也没有正确分析三角函数内因子的性质。
+ - *去进行判断,也有可能是直接使用了instanceof去进行判断,这些方法都不够全面,有一定的错误。本人采用了把内部因子化简后化为字符串之后重新进行解析的方法,这样就可以得知最终的因子化简之后的性质,从而做出正确的决断。3.同时,本次作业还出现了大量的CPU_TIME_LIMIT_EXCEED错误,每个人的架构不同导致了不同的错误,例如有的无法处理大量三角函数嵌套,有的无法处理复杂的递推函数等等架构上的性能差异。
tle的bug非常难以修复,可能大多数只能进行重构造,当然也可以利用一些技巧,比如设置cache缓存数据进而提高程序运行效率,或者替换掉原来一些冗余的方法,如果想要知道自己哪里出现了问题,也可以使用lzq大佬分享的IDEA Profiler工具分析自己程序运行过程中的耗时较长的地方。本次作业新增部分比较简单,出现的bug较少,不过发现还存在不少的历史问题以及新化简导致的问题。
1.本次作业互测阶段发现一个同学的bug是把类似sin(0)^0代入函数进行计算就会出现错误,而单独计算则结果正确,大抵是代入函数的时机和化简这种0次幂的时机之间发生了冲突。
2.很多情况下会出现求导法则错误的情况,比如我自己一开始对于三角函数带幂次的求导法则就使用有错,少了对于幂函数求导之后还要乘上的底数本身。
3.互测阶段又暴露出来一个bug,我在比较两个单项式的三角函数因子集合是否相等的时候,只要集合1当中的三角函数集合2当中都有我就会判定两个集合相等。但是这个时候就出现了一个问题,可能集合1中有三角1两个,三角2一个;集合2中有三角1一个,三角2两个,此时会会出现错误。
注:该结果为最终架构分析
最终共使用22个类和2个接口完成作业,其中有3个类的方法数超过10个,分别是Calculate、Mono、Parser。其中Calculate要处理很多不同数据结构的计算,所以方法数较多;Mono因为其中储存了很多数据结构,需要不断写入和读取,所以方法数较多;Parser要解析很多不同种类的因子,所以方法数较多。所以以上方法数多均比较合理。
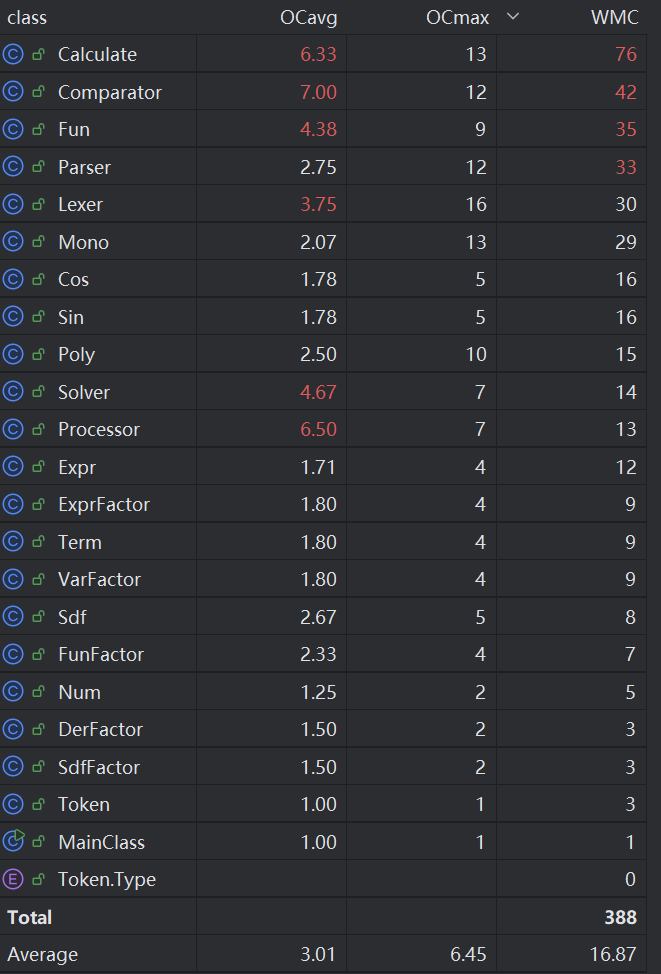
可以看出,圈复杂度较高的的是Calculate、Comparator、Fun、Parser四个工具类,其中Calculate、Comparator这两个类要进行多种数据结构的计算或者比较,要把所有的数据类转化为多项式或者单项式,所以圈复杂度很高;Fun函数是负责生成递推函数模版的类,其中用到了用栈去匹配括号读取字符串,字符串多次替换等非常复杂的方法,所以圈复杂度较高,我认为还是值得改进的,因为字符串处理带来了极大地性能降低和复杂度提高;Parser类中由于调用了很多内部方法和很多其他类的方法,并且判断语句较多,所以圈复杂度也较高,这个无可避免。
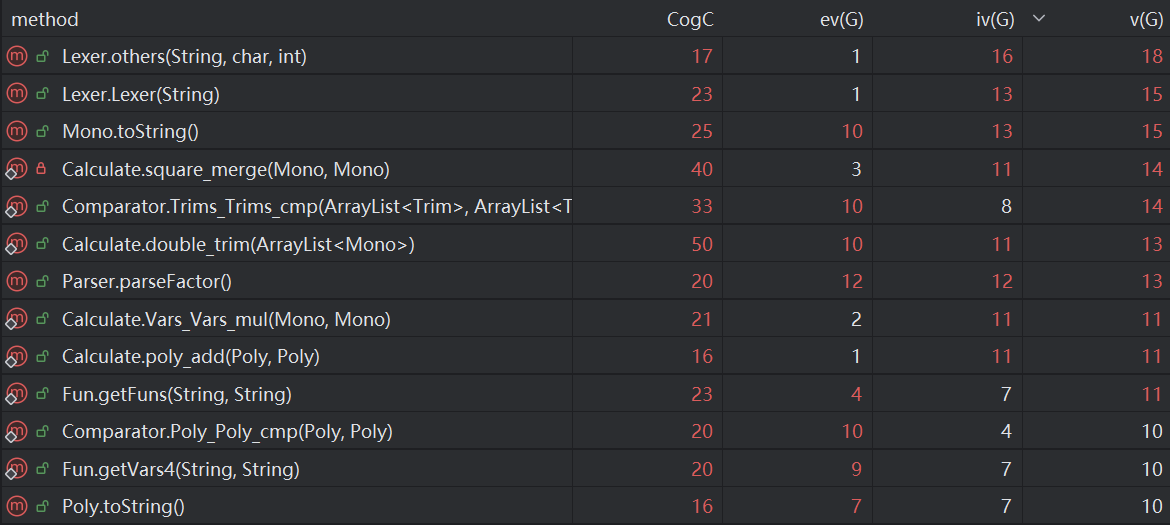
可以看到,由于Lexer在解析词的时候有非常多的判断语句,所以复杂度较高很合理;Mono.toString()方法的复杂度也很高,因为其中我为了优化输出,做了很多的特判,以及它还需要多次调用其他类的toString方法,所以复杂度较高;然后便是Calculate类当中的各种计算方法的复杂度都很高,这是因为我在很多计算中都使用了while循环嵌套迭代器遍历的方法来保证完全地合并同类项,这一点目前还没有想到其他的替换方式。
我觉得如果单独使用这种方法进行处理表达式可能感受没有那么深刻,但是如果同时和数据结构当时采用的用栈去匹配括号的方式相对比,我觉得就可以很明显的体会出递归下降方法的优越之处:总体来说就是让人感觉很简单,需要思考的东西很少,其根本原因就在于表达式-项-因子之间通过文法规定了每一类的职责,它只需要关注自身的组成,而不需要考虑其他类如何去组成,这样使得我们在解析每一类的时候,问题都得到了简化,因为我们不用去考虑其他复杂多变的情况而只需要专注于如何实现这一个类的解析。这种思考方式和我们人类的思考方式相同,大事化小、小事化了。同时递归下降方法自身就支持嵌套层次的解析,让我们在第一二次作业之间少了一层改变。递归这一思路,可以让写代码的人的思路更加简化,虽然会增加程序运行的代价,但是绝对是一种优秀的解决问题方式。
在这个单元的学习中,因为各种因素导致我没有搭评测机进行测试,那完全就是如履薄冰。因为人去进行测试的时候构造样例的思路和自己写代码的时候要解决哪些问题的思路是一致的,导致很难构造出错误样例,所以我觉得在进行测试的时候一定要摆脱自己写代码的时候的思维,完全专注于问题本身,去推导它各种可能的情况。同时,我觉得评测机实在是太重要了,因为它的数据是完全随机的,这样就可以量变引起质变,找出很多人无法找出的问题,因为这种代码量的作业,基本不可能再去重新阅读一遍源码查找错误,所以只能进行数据轰炸。
我感觉bug修复应该新增一个功能,就是即使没有成功修复bug,也可以提出申诉错误点为同质bug,不然的话对于一些太过难以修复的bug就会很亏(比如每人刚好砍你三道同质,那么这个bug就是二三十刀了)。当然,这种申诉会带来助教工作量的增加,所以一旦申诉失败,就会因为没有正确判断bug类型而额外扣分,这样就可以让大家也不敢随便地去糊弄bug修复。

