


275
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享目录
一次写得很失败的oo作业,不管是优化还是实际debug,因为太懈怠了导致均没有做到很好,而且在阅读指导书时经常漏看,导致了hw1和hw2的大量同质bug。在框架上也没有很好的表现出面向对象的特点,更多的是使用了面向过程的方法,将接口与父类都统一到了同一个类里面,导致代码可读性不高。这次博客希望是对自己后续作业的提醒,应该写出更优质可读且具备拓展性、功能良好的代码。(所以这份博客仅能提供反面样例)
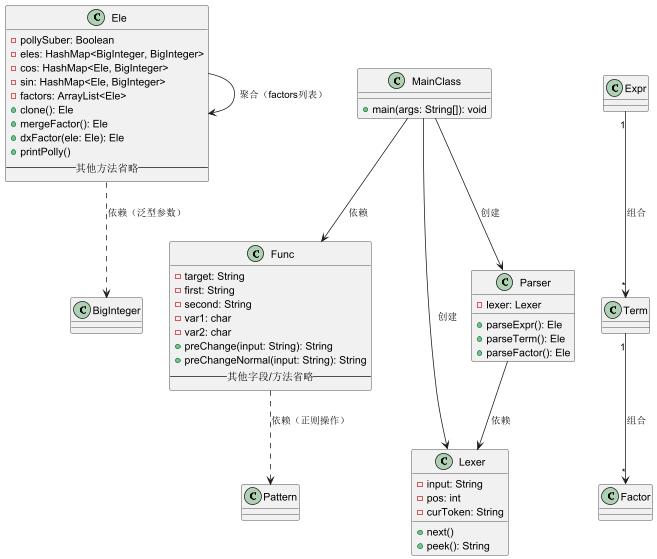
由于三次作业的架构大体均为如此(第二次迭代为Ele中的因子新加了两个Hashmap存储三角函数、并新建func类完成函数预处理,第三次作业架构与第二次完全一致,仅增加了额外操作和额外函数)。因此本文仅以第三次作业为例分析未能很好实现单一职责的代码的诸多不利之处。
1.各类的设计方法:
Ele类:作为存放各类型因子的类,其承担了包括存储、运算的多项功能。现在来看,应该把其中的功能进行更加明确的划分,如建立dx接口、三角函数类等,将不同的因子拆分出来保证单一职责原则,避免后面切实遇到的代码较难维护、拓展的问题。
lexer类:参照课程组实验的内容,用lexer类提前解析表达式,并传递给parser类进行后续分析。
parser类:进行递归下降解析文本的主体部分,实现了expr-term-factor解析逻辑。
mainClass:作为程序的入口。
2.架构存在的问题:
在处理对于多项式的读入、运算及化简时,通过第一次上机实验的启发,我设计了lexer、parser类,分别处理读入和递归下降解析式子。但在第一次作业中因为需要实现的功能比较少,实现相对容易,所以放弃了课程组提供的各种因子继承Factor的框架,自己搓了一个Ele类,完全完成对于多项式的存储、运算(由于没有三角函数,所以不需要区分mono和poly,仅有幂函数的情况下全部视为poly效果是一样的)但是这也是我后续迭代中的最大败笔:过于面向过程编程导致了方法间耦合度高,实现逻辑复杂,边界条件繁多。再回头看时,如果提前分好类的层次,能够更好地分析边界条件并且在加因子类型时也会更加方便,而不是往Ele里面又套入两个Hashmap来表达三角函数,让复杂度雪上加霜。
正确的操作应该是写poly,mono等类并划分好层次,这样的代码架构会清晰易读,迭代起来也很方便。但是我三次代码的架构大体没有变化,仅在第二次迭代时新加了func类对所有的函数进行预处理(第三次也沿用了这个设定),而其他所有的子类(factor中的sin、cos、多项式等),均被杂糅到了Ele一个类中,导致可读性很差。其中还有复杂的边界处理时就更加折磨,而边界条件也是bug的主要原因。
虽然很难读,但我的代码与优秀代码底层逻辑大抵一致,均是采用了分别处理多项式、单项式的方式,先对mono处理,再集中到poly层面进行求导等操作。因此在实现更多功能:
1.如实现exp、log等更多类型因子时,可以如同三角函数一样,对每个单项式因子额外加入一个Hashmap,来维护单个因子内部的所有乘积项。多项式层面则进行各种运算操作,变化较小。
2.增加更多的运算如除法。在我的架构中会把运算放到poly层面,再依次分配给其中的因子。不同的运算也不需要对架构进行较大变动。因此可拓展性还是较好的
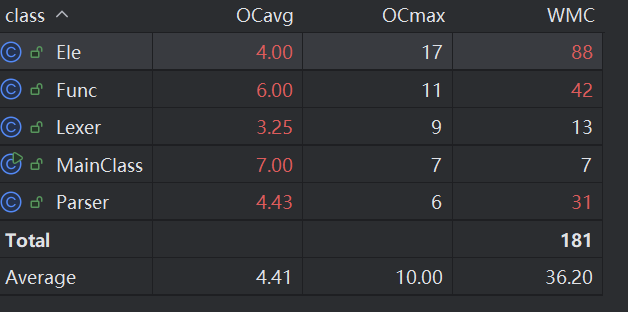
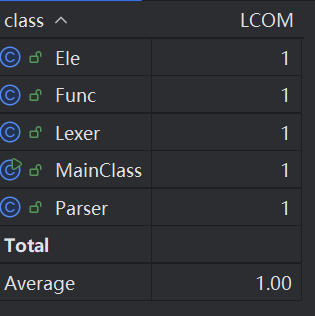
因为大量的杂糅,总共只有五个类,每个类承担职责都很多,因此不出意外的每个复杂度都很高。而类之间的耦合度可以见前面的uml图,知类之间耦合度较低。究其原因,在于我的大部分关于因子操作的实现全部堆积在了Ele类中,而不像大家普遍的建立mono类、poly类,因此我的耦合度主要体现在类中方法间的关系中 。此外我的代码内聚度较低,这也是意料之中的,因为我的代码未能保证单一职责原则,应当拆分类保证单一职责。
原因分析:
main函数没有能够仅作为入口呈现,在判断函数数目及是否要预处理时承载了部分逻辑。应该把这一部分提到相应的功能类里面,我的实现确实不妥。
Ele函数复合了poly、mono、sin、cos、dx等大量功能,因为hw2后代码比较难再修改框架,所以就变得越来越冗杂。
lexer和parser主要完成了文本解析和递归下降处理功能,有许多核心逻辑,所以复杂度偏高。
func类因为在实现递归函数时未想到抽象出函数的接口,导致一般函数与递归函数写了重复的两份代码。内部判断使用一部分正则表达式和替换,导致了较高复杂度。
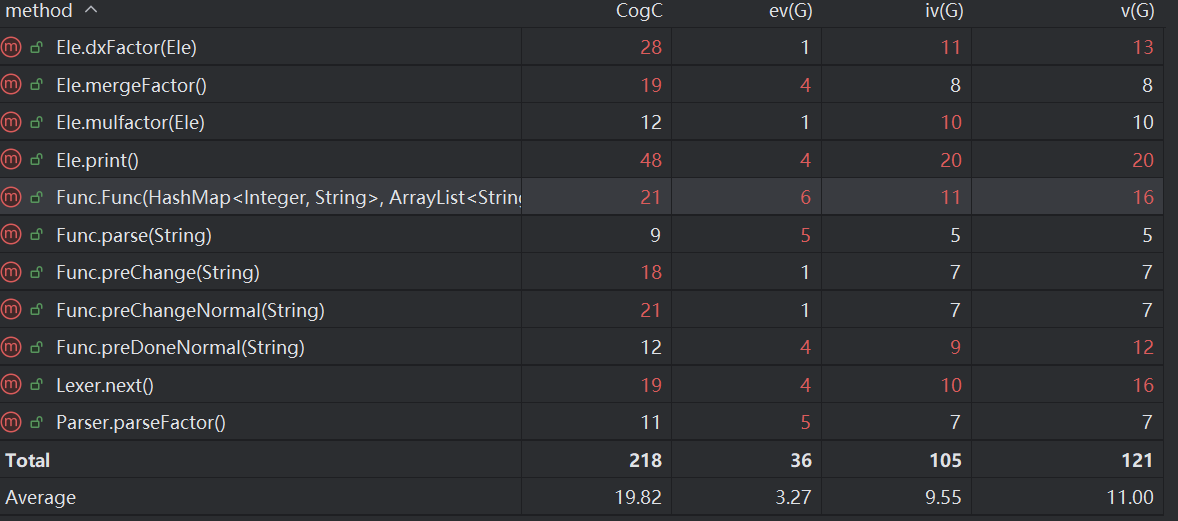
此处仅列出了复杂度较高的方法。可以发现复杂度高的方法主要为:
1.Ele中与factor有关的方法。我的factor混合了所有类型的因子,很杂乱难读,这会是我后续改进的重点。
2.Func类中与预处理有关的方法。在这类方法中,我是用了大量字符串操作以及正则表达式匹配,所以方法复杂度较高。
3.parse类型方法:在解析文本时方法复杂度较高,这一点比较符合预期,因为文本中待分析选择较多。
在这次作业中,出现的大部分bug(强测与互测)均来自于读题不慎。如第二次作业没发现可以没有x变量就在函数中直接出现y变量,导致re。此外便是对于边界条件的判定,容易出现问题,而这也导致我第三次强测爆炸。现在来看,对于零的处理不应该分散在各个子方法里,应该在对于因子处理时即时标记(在我的架构中一开始幂函数为空,和0混杂导致了bug)。鉴于0的特殊性,我的架构中一开始幂函数为零,加入三角后仅是特判的处理在第三次加入其他方法后忘记处理,狠狠给我上了一课。因此在设计方法时不能只想着眼前怎么完成,应该提前规划框架,设计普适的方案。如我本可以在乘三角函数时额外乘一个1来区分0,但我却选择了特判,导致逻辑复杂,最终出错。
现在来看我出错的方法圈复杂度反而不高,故不进行这方面比较。我出错原因主要是整体逻辑复杂(所以其他很多方法复杂度高)导致的未能统一底层逻辑,最终出错。以后的设计在处理基本问题时应该先设计好更普遍的框架再动手写代码。
最后还有一个很多同学也会出现bug的点:对于函数表达式的递归替换。在函数套函数上我没有出现较大的问题,这一部分代码逻辑与parser递归下降解析大体一致,只需要在分析函数内部表达式因子时,递归调用func中的替换函数算法即可完成。但是我在此处出现了另一种问题:虽然我考虑到了可能会出现不想出现的二次替换(如形参是y,x,实参是cos(x),x^2,y换为cos(x)后,再换x时会把cos(x)内部的x换为x^2,这显然是我们不希望的二次替换。)但还是因为没有考虑到可能实参里面y对应有x,x对应有y,这样顺序调换也不行的情况(所以一定不要写很多特判,要写出更有普遍性的解决方案)。为了解决这一问题,我最终采用了正则表达式匹配的方法,避免对已有匹配部分二次操作。具体方法如下:
public String compareAndChange(HashMap<String, String> replacements, String temp) {
List<String> sortedKeys = new ArrayList<>(replacements.keySet());
sortedKeys.sort((a, b) -> Integer.compare(b.length(), a.length()));
// 构建正则表达式(转义特殊字符)
String regexNew = String.join("|", sortedKeys.stream().map(Pattern::quote)
.toArray(String[]::new));
Pattern patternNew = Pattern.compile(regexNew);
Matcher matcherNew = patternNew.matcher(temp);
// 逐个替换匹配项
StringBuffer result = new StringBuffer();
while (matcherNew.find()) {
String matched = matcherNew.group();
String replacement = replacements.get(matched);
matcherNew.appendReplacement(result, replacement);
}
matcherNew.appendTail(result);
return result.toString();
}
在这种逻辑下可以保证匹配的正确性(hashmap存储了用于替换的string对,temp为待替换代码串。具体解析也可以部分使用正则表达式,但是无法完全依靠正则表达式,其无法处理无限深的问题(特指此处的递归调用),所以应该融合前面提到的递归下降解析)
通过读大家的代码、编写自己想到的边界条件,纯手动搓数据。但是由于我自己的架构问题,我在读其他人的代码架构时与自己写的其实差异很大,很多变量的理解很难一次到位,所以在结合他人架构分析潜在问题上做得不够到位。最后的结果当然是无法很好hack别人,即使房友也会有很多bug。现在来看,评测机的学习很有必要,不论是检查自己的问题、还是高效互测,都离不开评测机的辅助。
由于在我的框架下,对于单个项仍旧是poly->mono的处理逻辑,且每个项都用三个Hashmap完成了对于所有内部乘积项的存储,因此在优化时可以遵循:先提取公因式,再检查可否对两个项剩余部分化简的策略。接下来的化简步骤就是对于三角函数的额外处理,如平方和等,只需对三角函数内部的expr是否相等进行检查并操作即可,就不在此赘述了。
1.应该优化代码框架,实现清晰的逻辑结构
这次面向对象的作业我可以说是写得和面向对象没有什么关系了……在第一次作业中并未给后续拓展留下较好架构,导致了后续迭代过程中给我一种重构就要全推翻,不重构就成现在这样方法耦合度过高、类过于庞大的感觉。(不过当初还是应该及时重构)。在互测过程中,通过阅读其他同学的代码,以及在第二次实验课中阅读课程组的求导框架,我感觉在其中更好地理解了如何运用接口和继承。第一次oo作业没有重构很大一部分也是来源于对继承等方法运用的不熟练与不自信,最终导致了在一个ele上堆叠过多类型。
2.要多加学习评测机的搭建
这次作业中许多边界条件错误、语法错误,都源于没有进行完全覆盖性的测试。如果依据文法进行充分测试,那检查出bug也是很容易的,否则自己造数据只会陷在没看到的错误仍然测不出来的问题中。
总的来说,第一单元的oo虽然我的代码一直在错很简单的问题导致强测大范围出错,而且我的代码并未能很好达到预期展现出面向对象代码应有的良好结构,但是在学习的过程中,我了解了很多字符串处理方法,学习了他人优秀代码架构并将在之后的作业中尽量加以实践。最重要的是,我真切感受到代码复杂后评测机的重要性,收获还是比较大的。
感觉第二次作业强度上升很多(也有可能是我的思路问题,在第一次作业因为只有幂函数所以完全没有mono的体现,导致当时三角函数很难融入)但是第三次作业强度就下降了,因为大体架构在第一二次作业后不会有大的变动,第三次作业加入普通函数可以融入递推函数处理,求导操作和解析expr也不会差很多。建议调整第二次第三次作业强度。

