


272
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享本单元作业迭代中,我采用常见的递归下降方法解析了经过预处理的输入字符串,将其转化成Expr>Term>Factor的表达式树形式。引入Poly>Mono的归一化思路,将整个表达式化为Poly形式并输出。最终代码类图如下:
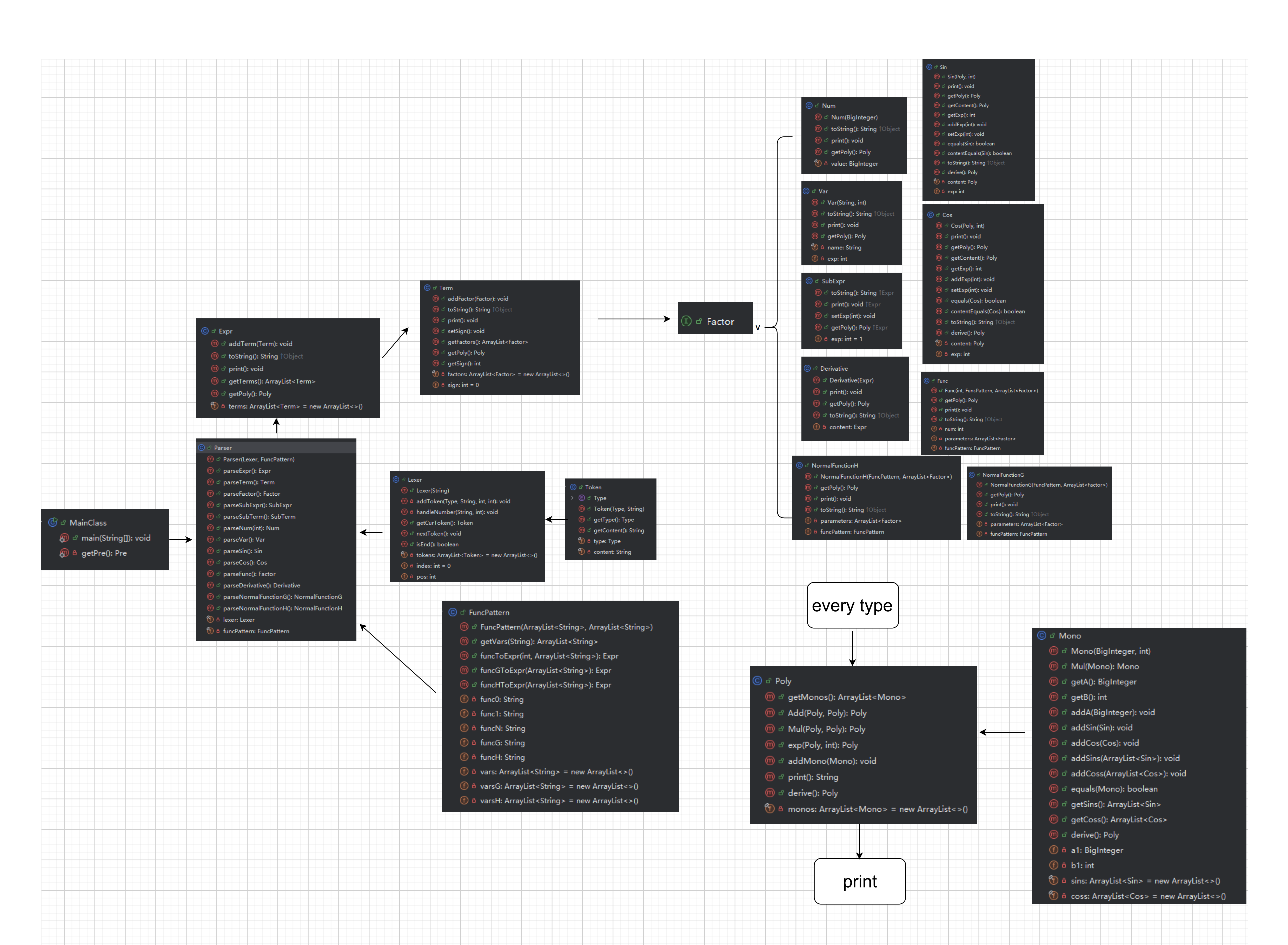
该结构中,通过Factor(因子)接口实现了多个具体因子,并均实现了向Poly的转化、重写了toString方法(会在函数部分参数替换时用到)等关键方法,新增支持的运算类型时,只需增加一个该接口的实现即可,层次化清晰。同时对各类内部实现的方法进行封装能有效保证架构的可迭代性,例如在Poly乘法中调用Mono乘法实现,这样新增因子需重构Mono时无需对Poly进行修改。
下图是类复杂度情况:
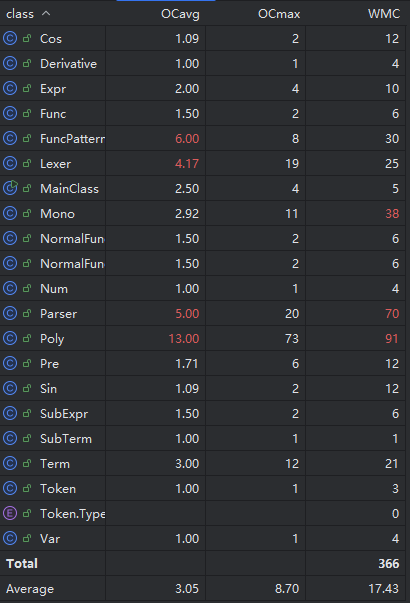 Poly类复杂度过高,考虑到是其中输出方法print()中,为了对输出进行化简(如-1*x^1化简为-x),而设置了过多的分支条件, 其实现思路有待优化。
Poly类复杂度过高,考虑到是其中输出方法print()中,为了对输出进行化简(如-1*x^1化简为-x),而设置了过多的分支条件, 其实现思路有待优化。
在三次作业迭代中,没有经历过大的重构。
新的迭代情景:
迭代过程中,我的程序出现bug的重灾区在于输出化简部分,和函数形参实参替换的部分。
反思改进:
出现这样的问题,我发觉化简的程度高,则不出现bug的难度就会大。一方面是因为分支情况难以第一时间考虑周全,二是本次作业中,输入的限制与输出限制不同,例如输出中-x合法,而输入中则不合法,这也导致我产生了许多因为调用输出函数进行“parse”而产生的bug。综上分析,最大的优化点在于print函数的设计,可以通过减少不必要化简、重构分支结构来降低复杂度。
本单元互测中,我通过手动构造数据测试,很少找到其他同学代码bug,也并未结合代码进行针对性分析。
本单元作业中实现的优化很少,尤其三角函数因子引入后为了输出的正确性舍弃了性能分,没有实现三角函数化简。唯一实现了对"+0"、"*0"和"*1"的输出省略。
经过几次改良最终还是保证了代码的正确性。
在面向对象课程的第一单元实践中,我对代码组织有了新的认识。最初编写表达式解析程序时,选择直接在表达式树的基础上化简计算,导致添加新功能异常困难。例如想增加三角函数时,发现解析、计算、输出的代码像乱麻般缠在一起,每处修改都可能引发连锁错误。
通过引入继承和多态,我尝试将代码分层管理:在表达式树的基础上,引入Poly和Mono两类,为原表达式每一层都实现向Poly转化的方法,实现了不同变量的归一化。这种结构带来了意想不到的便利。当需要添加求导因子时,我仅需新实现一个factor的接口,并实现其特定计算规则,原有解析和输出模块完全无需调整。递归下降法的运用也实现了意外之喜:第二次迭代时发现已经实现了嵌套括号的处理和化简。。
但这次作业也暴露了我的编码陋习:
希望oo课程在以后此单元的设计中,平均化每一次迭代的设计难度,避免出现此次作业第二次迭代难度过大而第三次过小的问题。

